






1. 全连接层
经过前面若干次卷积+激励+池化后,终于来到了输出层,模型会将学到的一个高质量的特征图片全连接层。其实在全连接层之前,如果神经元数目过大,学习能力强,有可能出现过拟合。因此,可以引入dropout操作,来随机删除神经网络中的部分神经元,来解决此问题。还可以进行局部归一化、数据增强等操作,来增加鲁棒性。
当来到了全连接层之后,可以理解为一个简单的多分类神经网络(如:BP神经网络),通过softmax函数得到最终的输出。整个模型训练完毕。
两层之间所有神经元都有权重连接,通常全连接层在卷积神经网络尾部。也就是跟传统的神经网络神经元的连接方式是一样的:
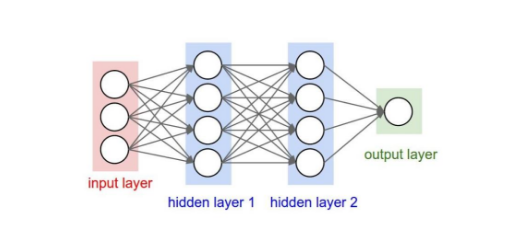
全连接层(fully connected layers,FC)在整个卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。
全连接的核心操作就是矩阵向量乘积:
y=W*x
本质就是由一个特征空间线性变换到另一个特征空间。目标空间的任一维——也就是隐层的一个 cell——都认为会受到源空间的每一维的影响。不考虑严谨,可以说,目标向量是源向量的加权和。
2.激活函数
所谓激活函数(Activation Function),就是在人工神经网络的神经元上运行的函数,负责将神经元的输入映射到输出端。
激活函数(Activation functions)对于人工神经网络 [1] 模型去学习、理解非常复杂和非线性的函数来说具有十分重要的作用。它们将非线性特性引入到我们的网络中。如图1,在神经元中,输入的 inputs 通过加权,求和后,还被作用了一个函数,这个函数就是激活函数。引入激活函数是为了增加神经网络模型的非线性。没有激活函数的每层都相当于矩阵相乘。就算你叠加了若干层之后,无非还是个矩阵相乘罢了。
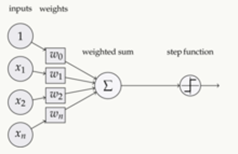
如果不用激活函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合,这种情况就是最原始的感知机(Perceptron)。
如果使用的话,激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。
2.1 常用的激活函数
2.1.1 Sigmoid函数
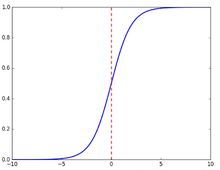
Sigmoid函数是一个在生物学中常见的S型函数,也称为S型生长曲线。在信息科学中,由于其单增以及反函数单增等性质,Sigmoid函数常被用作神经网络的阈值函数,将变量映射到0,1之间 [2] 。公式如下

函数图像如下
2.1.2 Tanh函数
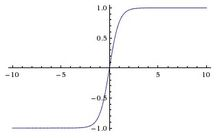
Tanh是双曲函数中的一个,Tanh()为双曲正切。在数学中,双曲正切“Tanh”是由基本双曲函数双曲正弦和双曲余弦推导而来。公式如下

函数图像如下
2.1.3 ReLU函数
Relu激活函数(The Rectified Linear Unit),用于隐层神经元输出。公式如下
![]()
函数图像如下

这里要着重提一下Relu激活函数,它与其他激活函数最大的不同在于它是线性的,因而不存在梯度爆炸的问题,在多层网络结构下梯度会线性传递。
在深度学习中Relu是用的最广泛的一种激活函数。

















 1133
1133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









