







 本文探讨了自然语言处理中的两个关键任务:词性标注和命名实体识别,阐述了它们的挑战,包括歧义性和低频词处理,并提供了统计和上下文信息在标注中的作用。
本文探讨了自然语言处理中的两个关键任务:词性标注和命名实体识别,阐述了它们的挑战,包括歧义性和低频词处理,并提供了统计和上下文信息在标注中的作用。
该系列将描述一些自然语言处理方面的技术,完整目录请点击这里。
在 NLP 问题中,有两个问题是比较重要的标记问题:词性标注和命名实体识别。
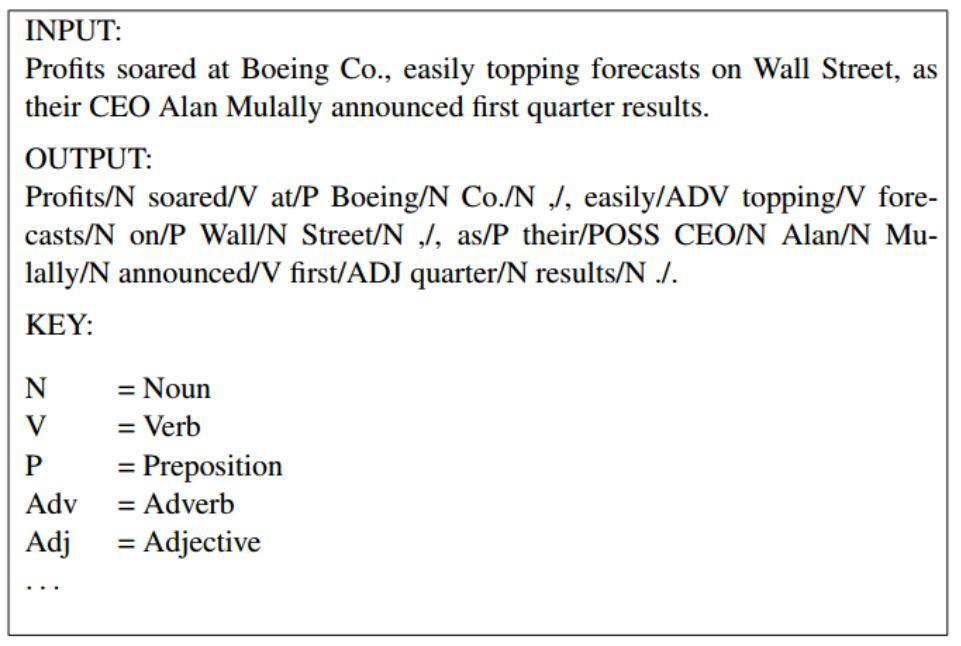
比如上图我们介绍了一个简单的词性标注问题。模型输入的是一个句子,输出是一个标记序列,模型会为每个词都产生一个标记。我们的目标是构建一个高精度的词性标注模型。词性标注问题是 NLP 中最基础的问题之一,在很多的应用中都有用。
我们假设我们有一个标记训练集,也就是每个句子都带有标记序列。比如,Penn WSJ 包含 100万字(包含 40000 句子),并且已经被标记。类似的数据集还有很多。
词性标注的一个最大的挑战是歧义。很多的英文单词可能有多种不同的划分,别的语言也同样存在这个问题。比如上图中,就有几个比较含糊的单词。比如,句子中第一个单词 “profits”,在这个上下文语境中,它是一个名词,但是在别的语境中它可能是一个动词(例如,句子 “in the company profits from its endeavors”)。单词 “topping” 在这个句子中是一个动词,但是它也可以作为一个名词,比如 “the to
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 196
196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









