






区块链的性能问题
VISA是目前世界上广泛使用的信用卡品牌,区块链要达到实用水平,性能上至少需要能跟VISA之类的支付系统作比较。根据VISA在2015年的记录,全年共产生92,064百万笔支付交易,平均2920tps,按平均每笔交易512字节左右计算,全年交易数据量约47TB。
而目前主流区块链性能情况是,比特币每秒只能进行大约7笔交易;以太坊每秒10-20笔。目前这些区块链的交易性能都无法与VISA相比。更严重的是,目前比特币和以太坊的矿机都需要存储全量数据,而单个机器的存储容量是有限的,若无法解决这个问题,即使交易性能提升了,若按每年新增数据量47 TB算,那么这些数据很快就会超过单机的容量,到时候整个区块链网络都无法继续运行。
那么,比特币和以太坊这种拥有海量节点的区块链系统,为什么性能却这么低呢?为什么区块链的可扩展性这么差呢?
原因分析
区块链是去中心化的账本技术,需要保证开放性、自治性、不可篡改等特性。去中心化是指使用分布式核算和存储,不存在中心化的硬件或管理机构,任意节点的权利和义务都是均等的,系统中的数据块由整个系统中具有维护功能的节点来共同维护。也就是说,系统中任意节点都需要对交易数据进行全量计算和存储。因此,区块链是没有可扩展性的,即系统的总体性能受限于单个节点的性能上限,即使加入了大量节点,系统的总体性能也无法提升。
可扩展性是传统分布式系统的基本特性,但区块链由于去中心化的要求,可扩展性却难以满足。业界总结了一个三元悖论描述去中心化与可扩展性之间的矛盾,它尚未被严格证明,只能被称为猜想,但实际系统设计过程中却能感觉到时时受其挑战:
去中心化(Decentralization),安全性(Security)和可扩展性(Scalability)这三个属性,区块链系统无法同时满足,最多只能三选其二。
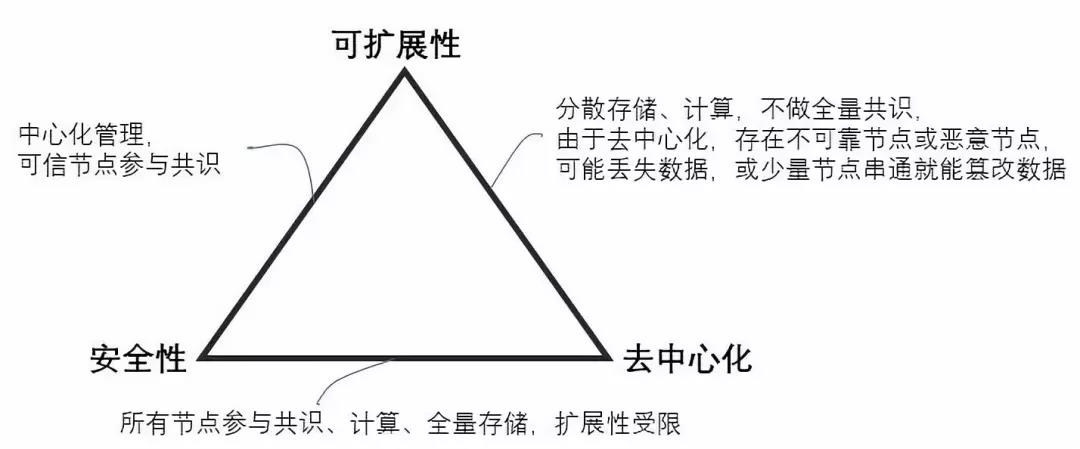
上图演示了区块链如何在这三个因素之间作选择及对应的策略,例如若若要满足安全性与去中心化,则需要所有节点参与共识、计算、全量存储,但由此带来的问题是失去可扩展性,也就是系统的总体性能无法随着节点的增多而提升;若要满足可扩展性与安全性,则需要中心化管理,需要保证参与共识的节点是可信的;若要满足可扩展性与去中心化,则采用分散存储、计算的策略,不做全量共识,则攻击网络的难度降低,安全性难以保证。
提升区块链系统性能的方案
我们知道,影响区块链交易性能的主要因素包括共识机制、交易验证、广播通信、信息加解密等几个环节。从这些环节入手,我们可以得到一些提升性能的方法。
- 共识机制
从PoW到PoS再到DPoS和各种BFT类算法,共识机制不断创新,区块链平台性能也得到大幅提升。
- 交易验证
从交易验证机制角度出发,目前有几种优化处理方式:
1)闪电网络(Lightning Network)和状态通道(State Channels),这两种策略是保持底层的区块链协议不变,将交易放到链下执行,通过改变协议用法的方式来解决扩展性问题。链下的部分可以用传统的中心化的分布式系统实现,性能具有可扩展性。在这种策略下,分布式账本上只是记录粗粒度的账本,而真正细粒度的双边或有限多边交易明细,则不作为交易记录在分布式账本上。缺点是存在中心化的系统。
2)分片处理(sharding),以太坊项目正在研发中的分片(shard)方案的总体思路是每个节点只处理一部分交易,比如一部分账户发起的交易,从而减轻节点的计算和存储负担。
3)多链架构(Multi-chain)的思路则是将原本的一条链分成多条链,每条链都负责部分计算和存储业务,并且有可扩展性,即链的数量可以随着业务量和数据的增加而增加,系统的总体性能随着链的数量的增加而提升,系统的存储空间也能随着链的数量的增加而扩大。
- 广播通信
P2P网络是区块链的核心技术之一,因此P2P网络通信的效率对性能的影响非常重要。为了能改善广播通信性能,需要提高节点机器的物理配置,提供高速网络连接,并采用减少广播的共识算法,如DPoS等。
- 信息的加解密
信息的加解密是区块链的关键环节,主要是哈希函数和非对称加密两类算法。区块链系统中可以采用更高性能的加密算法以提升交易验证的性能。
方案对比
上述优化方法中,共识机制、广播通信、信息加解密是算法层面的优化,尽管这些方案也是重要的优化,但其没有解决根本性的问题,其性能提升仍然受限于单机性能,不是可扩展的,因此性能提升有限,本文不再详述;交易验证的几个优化方案则是可扩展的方案,其中闪电网络和状态通道是链下执行的方案,采用中心化的系统提升区块链性能,与区块链去中心化的理念相悖,而且使用复杂、用户体验差(例如闪电网络要求交易中的双方以及中间人都必须同时在线、线下系统开发复杂因为要寻找可用的支付通道、不适用于大额交易等),无法得到广泛使用。因此EOS、以太坊、Cosmos及迅雷链等高性能区块链项目均采用分片或多链方案。
分片或多链方案的思路是一样的,都是让每个分片或分链进行部分交易数据的处理和存储,每个分片和分链可以并行处理不同的交易数据,这样分片或分链的数量越多,系统的总体性能就越高,这两者都是可扩展性很强的方案。
- EOS的多链实现方案
EOS的技术白皮书中并没有描述多链的实现方案,只描述了支持跨链通信的IBC(Inter Blockchain Communication)协议,跨链交互通过简化生成消息存在的证明和消息序列的证明来实现。EOSIO声称主链可以支持3000以上的TPS,通过IBC可达到100万TPS。
EOS的多链架构其实是侧链方案。开发者可以单独部署一条EOS侧链(公链、私链都可以),运行自己的Dapp,这些侧链有可以有自己的委员会,见证人以及计算资源,有自己的代币,这些代币有自己的增发方式,而且代币可以和EOS通过接口进行锚定去实现包括锁定在内的某种操作。侧链最大的特征双向锚定(two-way-peg)技术,它使得在侧链流通的Token价格总是与EOS价格保持一定比例或者直接采用EOS。
因此EOS的多链架构并不是对主链本身进行可扩展性改造,只是期望通过子链来分担主链的压力。
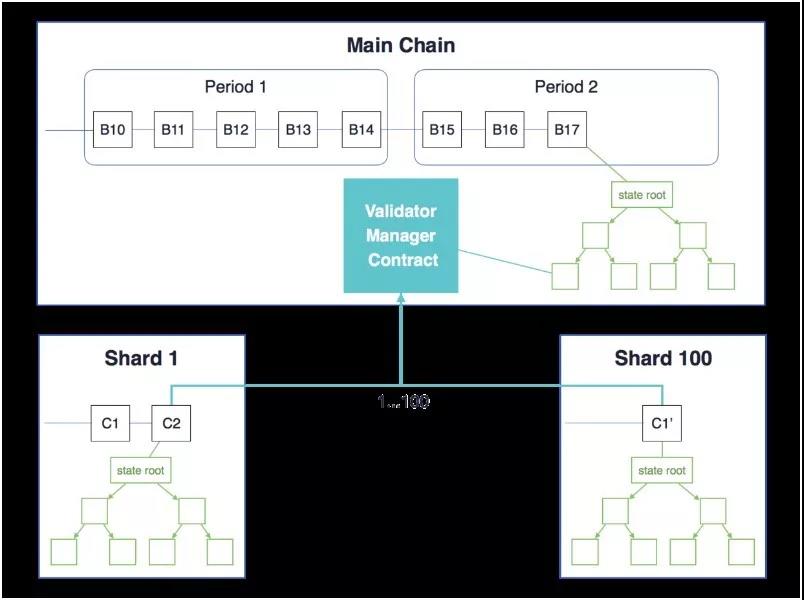
- 以太坊的分片技术(Sharding)
分片(Sharding)是以太坊正在开发中的技术,其大致设计思路是:将区块链网络中的每个区块变为一个子区块链,子区块链中可以容纳若干(目前为100个)打包了交易数据的Collation(大概可以称为“校验块”,为了在分片的情景中将其与区块的概念区分开),这些Collation最终组成一个在主链上区块;因为这些Collation是整体作为区块存在的,所以其数据必定是全部由某个特定的矿工所打包生成,本质上和现有协议中的区块没有区别,所以不再需要增加额外的网络确认。这样,每个区块的交易容量就大概扩大了100倍;而且这种设计还有利于未来的继续扩展。
跨分片通信: 利用 UTXO 模型,并通过在主链上进行交易和创建一个 receipt(带有 receipt ID),用户可以将以太存入一个指定分片。分片链上的用户可以给定 receipt ID 创建一个消费 receipt(receipt-consuming)的交易,来花费该 receipt。但UTXO适用于交易,对于合约状态数据存储不适用。
 3
3
- Cosmos的多链技术
Cosmos项目的目的是解决区块链交互操作和可扩展性问题,其区块链间通讯协议可以实现区块链的互联,支持不同区块链之间的资产转移。
网络主要由两部分组成,Cosmos Hub和若干个Zone。
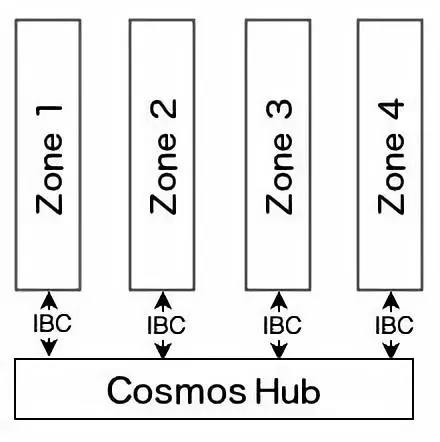
Cosmos网络里第一条链是Hub,从名字和功能上都可以把它理解为Cosmos的中心链或者管理员链,所有其它区块链的交易都会在Hub记录,一条区块链上的token可以通过Hub转移到另一条区块链。Hub是Cosmos网络的核心,和其余的Zone是不平等的,从严格意义上讲Cosmos网络不是真正的分布式系统,如果Hub发生了单点故障(当然Hub本身是分布式的,发生问题的机率很小),Cosmos网络的很多特性会不可用。关于这点,白皮书中强调Hub必须得到严格保护。
每个Zone可以看做是单独的区块链空间。每个Zone会和Hub保持状态同步。Hub通过去中心化的验证人组来保证安全性。Zone1向Zone2做跨链消息时,Zone1先生成消息包,并将其证明发布在Hub上,接下来Hub会生成Zone1的跨链消息包已在Hub上的存在证明的证明发布于Zone2,接下来Zone2收妥消息包,并给出证明发布于Hub上,最后,Hub再给出Zone2的收妥证明的证明发布于Zone2。完成整个跨链消息传递。
- 迅雷链同构多链架构
迅雷链是同构多链的架构,即每条链的结构相同、地位平等。即系统由一条条相对独立(独立进行共识)的链组成,每条链有多个节点,每个节点被分配到其中一条链上,不同的账户数据被锚定在不同的同构链上,然后接入层将交易路由到发送方所在的链上进行区块打包与共识。系统中链的数量能够按业务需求动态增加。因此同构多链的架构首先保证了系统的可扩展性。
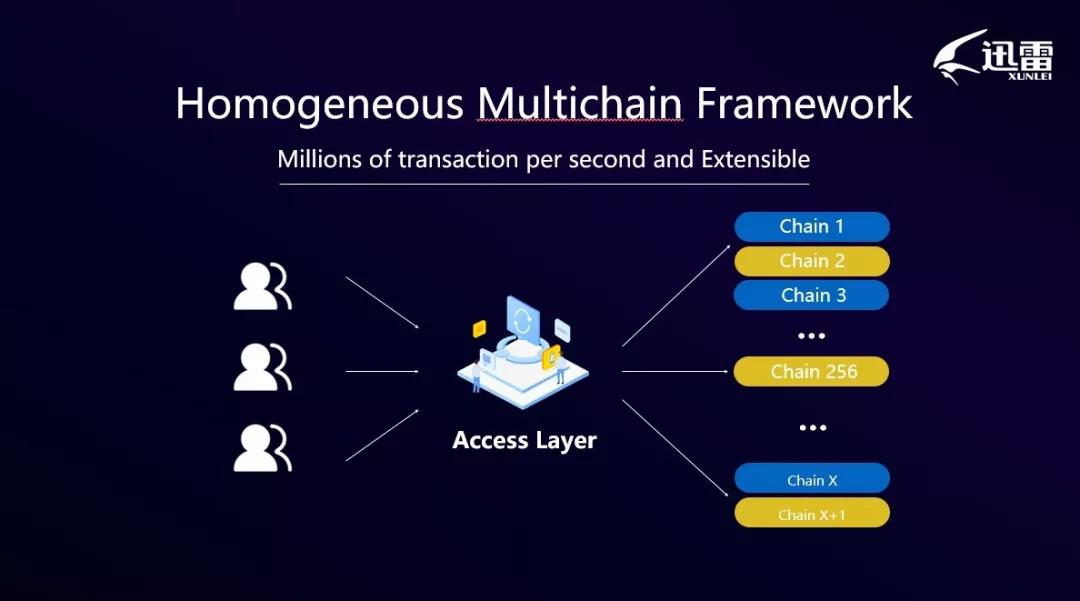
不同于EOS等区块链系统需要昂贵的高性能服务器作为记账节点,迅雷链使用廉价省电的玩客云设备作为记账节点,构建了自己的大规模共享计算平台。目前玩客云节点数量已超过150万个节点数,如此庞大的节点数量,对区块链系统的可扩展性提出了严峻的挑战。挑战主要来自两个方面:
1)玩客云设备廉价省电,性能也低,这就要求共识算法必须使用绿色环保、适应家庭用户的网络环境的算法。针对这个挑战,迅雷链在改进的PBFT的基础上,还融合了DPoS的思想,在每条链上,都会周期性地(例如每隔5000个区块)选举出验证人节点参与共识。与传统的DPoS不同之处在于,迅雷链并不是根据矿工持有的代币数量或币龄作为选举标准投票权重,而是按玩客云节点的存储容量、网络稳定性、带宽、时延等标准作为衡量标准,以获得更好的公平性和网络效率。
2)玩客云节点数量庞大,家庭网络环境复杂,要求区块链系统必须设计成可扩展性高、自治能力强的架构。得益于同构多链的架构非常强大的可扩展性,迅雷链能够充分利用海量玩客云节点,可以将链数“无限”扩展,从而具备百万级的并发处理能力。
综上所述,迅雷链采用多链架构实现了可扩展性 + 使用PBFT实现了强一致性 + 使用更绿色环保和公平的DPoS进一步提升了共识效率、也得到了更高的可用性。从去中心化(Decentralization),安全性(Security)和可扩展性(Scalability)三要素的角度看,由海量的广泛分布的玩客云设备支撑了去中心化和安全性,采用多链架构以实现可扩展性。
总结
共识机制、广播通信、信息加解密等算法层面的优化,无法解决大规模去中心化系统的可扩展性问题;而闪电网络和状态通道是链下执行的方案,则与区块链去中心化的理念相悖,而且使用复杂、用户体验差,无法得到广泛使用。因此前沿的区块链项目均采用可扩展性强的分片或多链方案。
其中,EOS目前是多线程的架构,总体性能还是受到单台机器的性能所限,需要昂贵的服务器来运行区块链节点,可扩展性并不算强;以太坊正在开发中的分片技术则需要主链负责验证子链的区块,由于主链会存在性能瓶颈,因此子链数量受到限制(100个子链);Cosmos也是同样的问题,Hub必须得到严格保护;迅雷链采用的同构多链架构则避免了上述缺点,适用于大规则廉价节点的部署, 可以将链数“无限”扩展,从而具备百万级的并发处理能力。















 1142
1142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









