






代码以及视频讲解
本文所涉及所有资源均在传知代码平台可获取
摘要
现实世界视频分辨率的提高对于深度视频质量评估(VQA)在效率与准确性之间提出了一个难题。一方面,保持原始分辨率将导致不可接受的计算成本。另一方面,现有的实践方法,如图像缩放和裁剪,会因为细节和内容的丢失而改变原始视频的质量,因此对质量评估是有害的。通过对人类视觉系统中的时空冗余以及视觉编码理论的研究,我们观察到,一个邻域周围的质量信息通常是相似的,这促使我们研究一种有效的、对质量敏感的邻域表征方案用于VQA。在这项工作中,我们提出了一种统一的方案,即时空网格小立方体采样(St-GMS),以获得一种新型样本,我们称之为片段。首先将全分辨率视频按照预设的时空网格划分为小型立方体,然后对齐时间上的质量代表进行采样,以组成用于VQA的片段。此外,我们设计了一个专门为片段量身定制的网络架构,即片段注意力网络(FANet)。利用片段和FANet,所提出的效率端到端的FAST-VQA和FasterVQA在所有VQA基准测试上的性能显著优于现有方法,同时仅需要1/1612的FLOPs,相较于当前最先进技术大幅降低。
介绍
随着高清拍摄设备的普及和视频压缩等技术的进步,大多数用户拍摄的视频分辨率大大提高,例如1080P、4K,甚至是8K,这极大地丰富了人类的感知和娱乐方式。然而,视频大小的增加也给视频质量评估(VQA)算法带来了挑战。传统的基于手工特征的VQA算法在处理具有多样内容和降质类型的野外视频时存在困难。而最近基于深度神经网络的VQA方法虽然有效,但其计算复杂度通常与视频大小成正比,即与分辨率的平方成正比,这使得它们在高分辨率视频上难以承受。
本文提出了一种新的采样方案——质量敏感邻域代表,以及基于此的时空网格小型立方体采样(St-GMS)方案,以获取一种新型样本——片段。片段可以有效保留视频中的质量信息,同时降低计算复杂度。
此外,我们还设计了一种专门为片段量身定制的网络架构——片段注意力网络(FANet),以更好地处理片段输入。
实验结果表明,所提出的端到端的FAST-VQA和FasterVQA在所有VQA基准测试上的性能显著优于现有方法,同时计算效率提高了1612倍。这使得深度VQA算法可以应用于任何分辨率的视频,无论视频长度如何。
模型介绍
-
框图
-
邻域采样表征(Sampling Representatives from Neighbourhoods)
在视觉任务中,采样的应用非常广泛。具体而言,均匀采样方案,如空间最近邻/双三次降采样和时间均匀采样,广泛应用于高级识别任务。一般来说,这些方法可以通过两个步骤来总结:1)将图像/视频分割成不同的局部区域(称为邻域),2)从每个邻域中采样一个代表。我们将整体统一范式归纳为邻域表征(R),可以指定为空间或时间维度。
由于邻域冗余也存在于质量相关信息中,邻域表征也可以应用于质量任务。然而,根据许多被广泛认可的研究中,在评估视频质量时,连续的局部纹理和局部时间变化是重要的,如果我们采用调整大小或均匀帧采样(Sr = 1),这些纹理和局部时间变化将被破坏。我们建议采样质量敏感的邻居代表(Rq),它应该满足: 1)它们应该在视频中包含原始像素,而不是汇总或平均的结果; 2)一个表征r(ni)中的原始像素应形成一个连续的小块或片段,该小块或片段的大小足以区分空间或时间的局部质量信息。因此,这些表征Rq既可以表示无偏的全局质量信息,也可以表示对VQA至关重要的敏感的局部质量信息(例如,空间局部纹理,相邻帧之间的时间变化)。 -
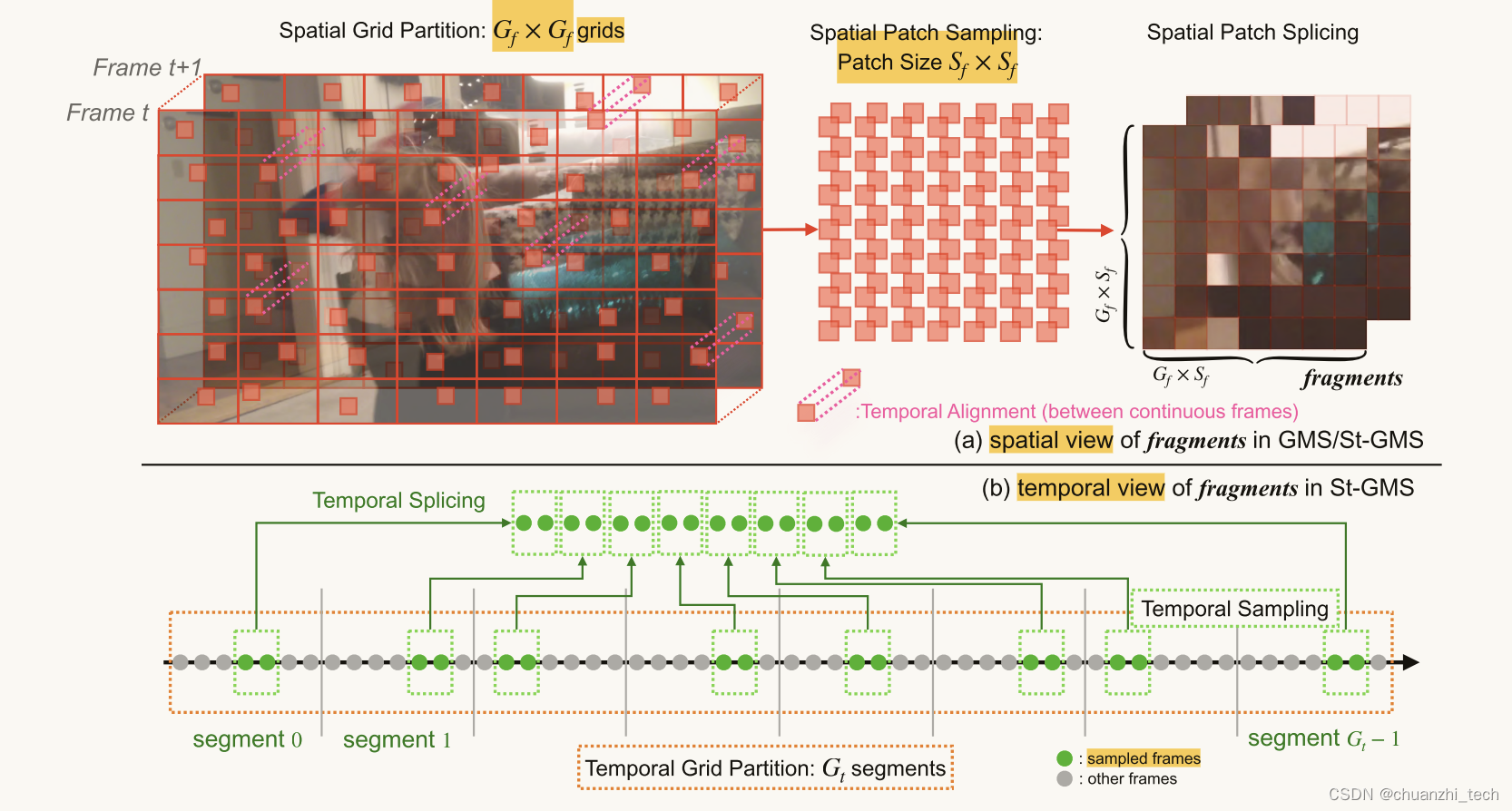
时空小立方体采样(Spatial-temporal Grid Mini-cube Sampling)
为了包括每个区域进行质量评估,并统一评估不同区域的质量,我们设计网格分区,将每个视频帧切割成均匀的网格,每个网格的大小相同(如框图(a)所示)。然后再从每个网格中随机选取一个小块(patch),通过将小补丁拼接在一起来保留它们之间的上下文关系。 -
片段质量回归网络(Quality Regression Network for fragments)
使用提出的片段作为输入来构建网络是很重要的。像大多数质量评估网络一样,它应该能够有效地提取保存在碎片中的质量信息,包括小立方体内部的局部纹理和它们之间的上下文关系。此外,它应该特别避免误读局部纹理的小立方体之间的不连续(由人工拼接导致),这需要更仔细的网络设计,特别是对于池化层,它决定了后续特征像素的值,并且不可学习。因此,我们施加了匹配约束,这约束了每个池化内核在每个小立方体最终被下采样为单个像素之前,应该只包括单个小立方体内部的像素(如图(a)中的绿色框),而不包括小立方体部分之间的像素(红色框)。
-
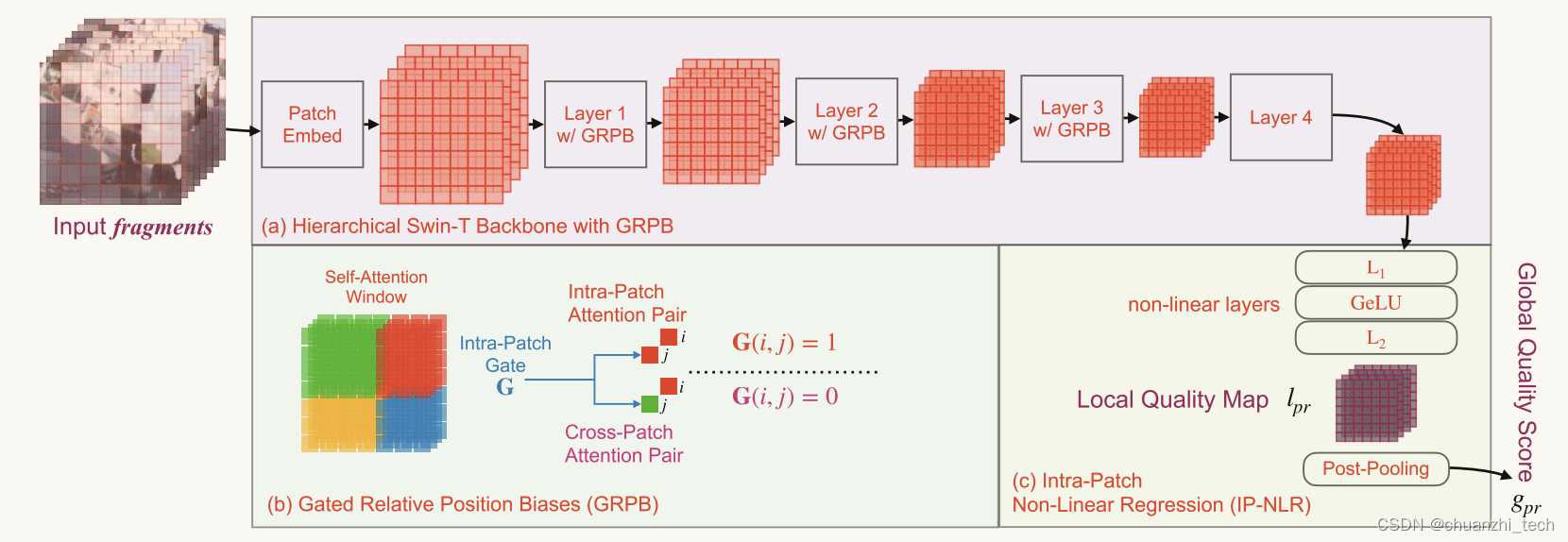
片段注意力网络(Fragment Attention Network (FANet))
片段端到端质量回归网络。它包括一个四层的swwin - t,前三个窗口自关注层被GRPB修改为骨干(缩写为swwin -GRPB),和一个IP-NLR质量回归头。门控相对位置偏差(GRPB)。在swing - t中,窗口自关注层是跨多维数据集构建的,以理解它们之间的上下文关系。然而,在这些窗口自关注层中,表示碎片像素的位置与正常输入的位置不同。最初的swing -T提出了相对位置偏差(relative position bias, RPB),使用可学习的相对偏差表(relative bias Table, T)来表示注意对(attention pairs, QKT)中像素的相对位置,但它们不能很好地表示片段中不同像素的相对位置。具体而言,考虑到同一注意窗口中的某些对可能具有相同的相对位置(例如图(b) A-C, D-E, A-B),但跨补丁注意对(A-C, D-E,来自不同小立方体的两个像素)实际距离较远,而补丁内注意对(A-B,来自同一小立方体的两个像素)实际距离较远。因此,我们区分了两种类型的注意对,并提出了门控相对位置偏差(GRPB),如图(b)所示,它使用两个可学习的真实位置偏差表(Treal)和伪位置偏差表(Tpseudo)来代替t。
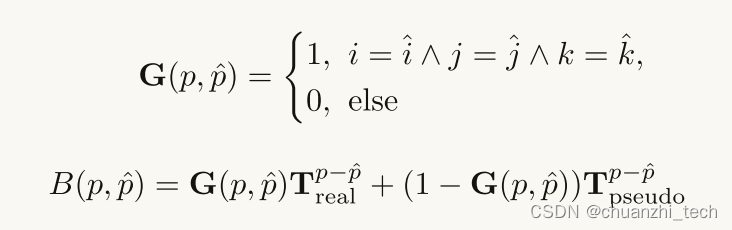
-
块内非线性回归头(Intra-Patch Non-Linear Regression (IP-NLR) Head)
特征像素与迷你立方体对齐,因此也可以对每个迷你立方体的质量进行回归,以获得局部质量地图。此外,如图©所示,即使在同一视频中,不同迷你立方体的质量相关特征也应该是不同的,因为它们的原始位置相距很远。因此,在视频识别中,通常在回归之前对它们进行平均,可能会有失去对不同质量信息敏感性的潜在风险,而单独对它们进行回归可以避免这个问题。基于上述两个原因,我们设计了Intra-Patch非线性回归(IP-NLR,图C)),首先通过双层MLP对特征进行回归,并对回归的局部质量分数进行池化。将最终主干特征记为final,局部质量图记为lpr,全局质量分数(FANet的最终输出)记为gpr,线性层记为L1, L2,则IP-NLR可表示为:

-
目标函数(Objective Functions)
许多现有的文章都指出,在质量评估任务中,质量预测对ground truth的线性和单调性是比预测本身更重要的目标。因此,我们将融合损失函数定义为单调损失L2与线性损失Llin的加权和,如下:
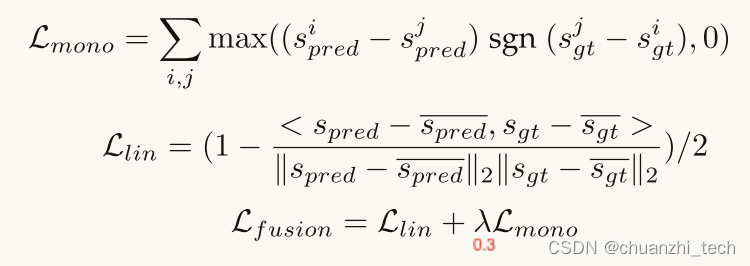
复现过程
代码目录:
1.时空小立方体采样代码
在FusionDataset类中get_spatial_and_temporal_samples方法是采样核心代码.
def get_spatial_fragments(
video,
fragments_h=7,
fragments_w=7,
fsize_h=32,
fsize_w=32,
aligned=32, # 8
nfrags=1,
random=False,
random_upsample=False,
fallback_type="upsample",
**kwargs,
):
size_h = fragments_h * fsize_h # 224 fragment的长*fragment长的个数
size_w = fragments_w * fsize_w # 224 fragment的宽*fragment宽的个数 用于表示最后裁取出来的patch拼接在一起的图片的大小
## video: [C,T,H,W]
## situation for images
if video.shape[1] == 1:
aligned = 1
dur_t, res_h, res_w = video.shape[-3:]
ratio = min(res_h / size_h, res_w / size_w)
if fallback_type == "upsample" and ratio < 1: # 如果是上采样并且 fragments_h * fsize_h(即图片的原大小小于 段数*每个patch的大小, 就要进行插值操作进行填充)
ovideo = video
video = torch.nn.functional.interpolate( # 用于执行插值操作
video / 255.0, scale_factor=1 / ratio, mode="bilinear"
)
video = (video * 255.0).type_as(ovideo)
if random_upsample:
randratio = random.random() * 0.5 + 1
video = torch.nn.functional.interpolate(
video / 255.0, scale_factor=randratio, mode="bilinear"
)
video = (video * 255.0).type_as(ovideo)
assert dur_t % aligned == 0, "Please provide match vclip and align index"
size = size_h, size_w # (224, 224) 用于表示最后裁取出来的patch拼接在一起的图片的大小
## make sure that sampling will not run out of the picture
hgrids = torch.LongTensor(
[min(res_h // fragments_h * i, res_h - fsize_h) for i in range(fragments_h)] # 每个fragment H开始的像素位置
)
wgrids = torch.LongTensor(
[min(res_w // fragments_w * i, res_w - fsize_w) for i in range(fragments_w)] # 每个fragment W开始的像素位置
)
hlength, wlength = res_h // fragments_h, res_w // fragments_w # 每个网格的H,W
if random:
print("This part is deprecated. Please remind that.")
if res_h > fsize_h:
rnd_h = torch.randint(
res_h - fsize_h, (len(hgrids), len(wgrids), dur_t // aligned)
)
else:
rnd_h = torch.zeros((len(hgrids), len(wgrids), dur_t // aligned)).int()
if res_w > fsize_w:
rnd_w = torch.randint(
res_w - fsize_w, (len(hgrids), len(wgrids), dur_t // aligned)
)
else:
rnd_w = torch.zeros((len(hgrids), len(wgrids), dur_t // aligned)).int()
else:
if hlength > fsize_h:
rnd_h = torch.randint(
# 生成一个形状为 (len(hgrids), len(wgrids), dur_t // aligned) 的随机整数张量,其中每个整数都大于等于 hlength - fsize_h
# 存储在每个fragment中要裁取的patch的H的随机位置 (7, 7, 视频帧数 // 间隔)
hlength - fsize_h, (len(hgrids), len(wgrids), dur_t // aligned)
)
else:
rnd_h = torch.zeros((len(hgrids), len(wgrids), dur_t // aligned)).int()
if wlength > fsize_w:
rnd_w = torch.randint(
# 存储在每个fragment中要裁取的patch的W的随机位置
wlength - fsize_w, (len(hgrids), len(wgrids), dur_t // aligned)
)
else:
rnd_w = torch.zeros((len(hgrids), len(wgrids), dur_t // aligned)).int()
target_video = torch.zeros(video.shape[:-2] + size).to(video.device) # 最后拼接在一起的图片大小是size
# target_videos = []
for i, hs in enumerate(hgrids):
for j, ws in enumerate(wgrids):
for t in range(dur_t // aligned):
t_s, t_e = t * aligned, (t + 1) * aligned # start, end
h_s, h_e = i * fsize_h, (i + 1) * fsize_h
w_s, w_e = j * fsize_w, (j + 1) * fsize_w
if random:
h_so, h_eo = rnd_h[i][j][t], rnd_h[i][j][t] + fsize_h
w_so, w_eo = rnd_w[i][j][t], rnd_w[i][j][t] + fsize_w
else:
# todo 裁取patch和align维度
# start: 每个fragment H开始的像素 + 每个fragment H随机生成的H
# end: 每个fragment开始的像素 + 每个fragment随机生成的H + 每个patch的大小
h_so, h_eo = hs + rnd_h[i][j][t], hs + rnd_h[i][j][t] + fsize_h
w_so, w_eo = ws + rnd_w[i][j][t], ws + rnd_w[i][j][t] + fsize_w
target_video[:, t_s:t_e, h_s:h_e, w_s:w_e] = video[
:, t_s:t_e, h_so:h_eo, w_so:w_eo
]
# target_videos.append(video[:,t_s:t_e,h_so:h_eo,w_so:w_eo])
# target_video = torch.stack(target_videos, 0).reshape((dur_t // aligned, fragments, fragments,) + target_videos[0].shape).permute(3,0,4,1,5,2,6)
# target_video = target_video.reshape((-1, dur_t,) + size) ## Splicing Fragments
return target_video
2.预训练模型下载
下载Kinetics-400数据集上预训练模型链接
3.修改数据集以及一些默认参数
4.运行new_train.py
核心代码
# 网络架构
self.pretrained = pretrained # None
self.pretrained2d = pretrained2d # False
self.num_layers = len(depths) # [2, 2, 6, 2]
self.embed_dim = embed_dim # 96
self.patch_norm = patch_norm # True
self.frozen_stages = frozen_stages # -1
self.window_size = window_size # (8, 7, 7)
self.patch_size = patch_size # (2, 4, 4)
self.base_x_size = base_x_size # (32, 224, 224)
# split image into non-overlapping patches
self.patch_embed = PatchEmbed3D(
patch_size=patch_size,
in_chans=in_chans,
embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None,
)
self.pos_drop = nn.Dropout(p=drop_rate)
# stochastic depth
dpr = [
x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))
] # stochastic depth decay rule
# build layers
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
layer = BasicLayer(
dim=int(embed_dim * 2 ** i_layer),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size[i_layer] if isinstance(window_size, list) else window_size,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]): sum(depths[: i_layer + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if i_layer < self.num_layers - 1 else None,
use_checkpoint=use_checkpoint,
jump_attention=jump_attention[i_layer],
frag_bias=frag_biases[i_layer],
)
self.layers.append(layer)
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
# add a norm layer for each output
self.norm = norm_layer(self.num_features)
self._freeze_stages()
self.init_weights()
# Head
class VQAHead(nn.Module):
"""MLP Regression Head for VQA.
Args:
in_channels: input channels for MLP
hidden_channels: hidden channels for MLP
dropout_ratio: the dropout ratio for features before the MLP (default 0.5)
"""
def __init__(
self, in_channels=768, hidden_channels=64, dropout_ratio=0.5, **kwargs
):
super().__init__()
self.dropout_ratio = dropout_ratio # 0.5
self.in_channels = in_channels # 768
self.hidden_channels = hidden_channels # 64
if self.dropout_ratio != 0:
self.dropout = nn.Dropout(p=self.dropout_ratio)
else:
self.dropout = None
self.fc_hid = nn.Conv3d(self.in_channels, self.hidden_channels, (1, 1, 1)) # 768->64
self.fc_last = nn.Conv3d(self.hidden_channels, 1, (1, 1, 1)) # 64->1
self.gelu = nn.GELU()
self.avg_pool = nn.AdaptiveAvgPool3d((1, 1, 1))
def forward(self, x, rois=None):
x = self.dropout(x)
qlt_score = self.fc_last(self.dropout(self.gelu(self.fc_hid(x))))
return qlt_score
WindowAttention3D:
class WindowAttention3D(nn.Module):
def __init__(
self,
dim,
window_size,
num_heads,
qkv_bias=False,
qk_scale=None,
attn_drop=0.0,
proj_drop=0.0,
frag_bias=False,
):
super().__init__()
self.dim = dim
self.window_size = window_size # Wd, Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
# define a parameter table of relative position bias 初始化,值是通过学习得来的
self.relative_position_bias_table = nn.Parameter(
torch.zeros(
(2 * window_size[0] - 1)
* (2 * window_size[1] - 1)
* (2 * window_size[2] - 1),
num_heads,
)
) # 2*Wd-1 * 2*Wh-1 * 2*Ww-1, nH (2*8-1)*(2*7-1)*(2*7-1)=2535, nH
if frag_bias: # todo fragment_position_bias_table
self.fragment_position_bias_table = nn.Parameter(
torch.zeros(
(2 * window_size[0] - 1)
* (2 * window_size[1] - 1)
* (2 * window_size[2] - 1),
num_heads,
)
)
# get pair-wise relative position index for each token inside the window
coords_d = torch.arange(self.window_size[0])
coords_h = torch.arange(self.window_size[1])
coords_w = torch.arange(self.window_size[2])
coords = torch.stack(
torch.meshgrid(coords_d, coords_h, coords_w)
) # 3, Wd, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 3, Wd*Wh*Ww
relative_coords = (
coords_flatten[:, :, None] - coords_flatten[:, None, :]
) # 3, Wd*Wh*Ww, Wd*Wh*Ww
relative_coords = relative_coords.permute(
1, 2, 0
).contiguous() # Wd*Wh*Ww, Wd*Wh*Ww, 3
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 2] += self.window_size[2] - 1
relative_coords[:, :, 0] *= (2 * self.window_size[1] - 1) * (
2 * self.window_size[2] - 1
)
relative_coords[:, :, 1] *= 2 * self.window_size[2] - 1
relative_position_index = relative_coords.sum(-1) # Wd*Wh*Ww, Wd*Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
trunc_normal_(self.relative_position_bias_table, std=0.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask=None, fmask=None, resized_window_size=None):
"""Forward function.
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, N, N) or None
"""
# print(x.shape)
B_, N, C = x.shape
qkv = (
self.qkv(x)
.reshape(B_, N, 3, self.num_heads, C // self.num_heads)
.permute(2, 0, 3, 1, 4)
)
q, k, v = qkv[0], qkv[1], qkv[2] # B_, nH, N, C
q = q * self.scale
attn = q @ k.transpose(-2, -1)
if resized_window_size is None:
rpi = self.relative_position_index[:N, :N]
else:
relative_position_index = self.relative_position_index.reshape(*self.window_size, *self.window_size)
d, h, w = resized_window_size
rpi = relative_position_index[:d, :h, :w, :d, :h, :w]
relative_position_bias = self.relative_position_bias_table[
rpi.reshape(-1)
].reshape(
N, N, -1
) # Wd*Wh*Ww,Wd*Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(
2, 0, 1
).contiguous() # nH, Wd*Wh*Ww, Wd*Wh*Ww
if hasattr(self, "fragment_position_bias_table"):
fragment_position_bias = self.fragment_position_bias_table[
rpi.reshape(-1)
].reshape(
N, N, -1
) # Wd*Wh*Ww,Wd*Wh*Ww,nH
fragment_position_bias = fragment_position_bias.permute(
2, 0, 1
).contiguous() # nH, Wd*Wh*Ww, Wd*Wh*Ww
### Mask Position Bias
if fmask is not None: # todo fmask
# fgate = torch.where(fmask - fmask.transpose(-1, -2) == 0, 1, 0).float()
fgate = fmask.abs().sum(-1)
nW = fmask.shape[0]
relative_position_bias = relative_position_bias.unsqueeze(0)
fgate = fgate.unsqueeze(1)
# print(fgate.shape, relative_position_bias.shape)
if hasattr(self, "fragment_position_bias_table"):
relative_position_bias = (
relative_position_bias * fgate # todo grpb
+ fragment_position_bias * (1 - fgate)
)
attn = attn.view(
B_ // nW, nW, self.num_heads, N, N
) + relative_position_bias.unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
else:
attn = attn + relative_position_bias.unsqueeze(0) # B_, nH, N, N
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
首先会打印一些基本信息,可以看到随机采样了哪些帧
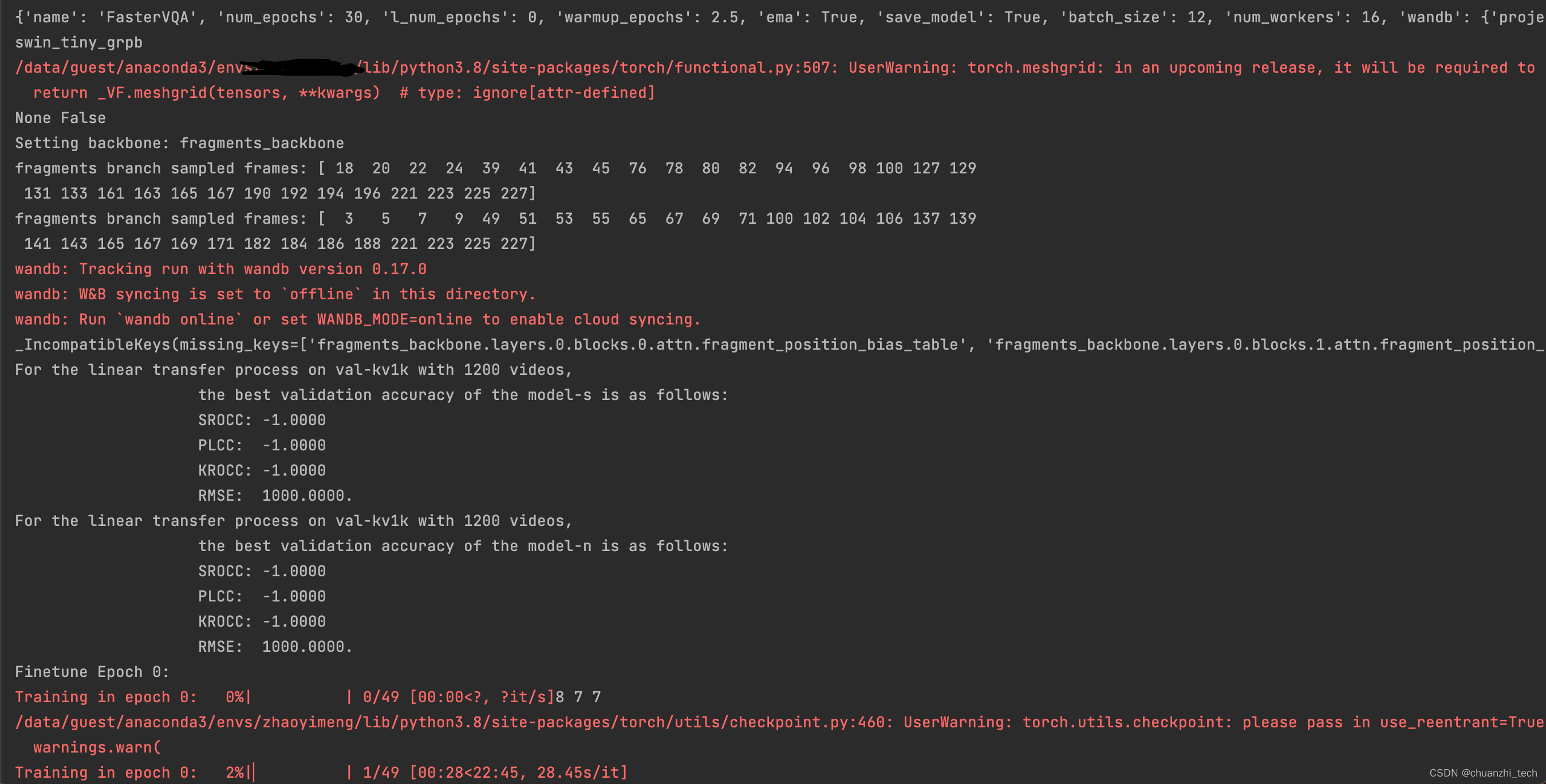
5.结果
结果是要保存到wandb网站上,首先你需要配置你的wandb权限,可以参考文章链接
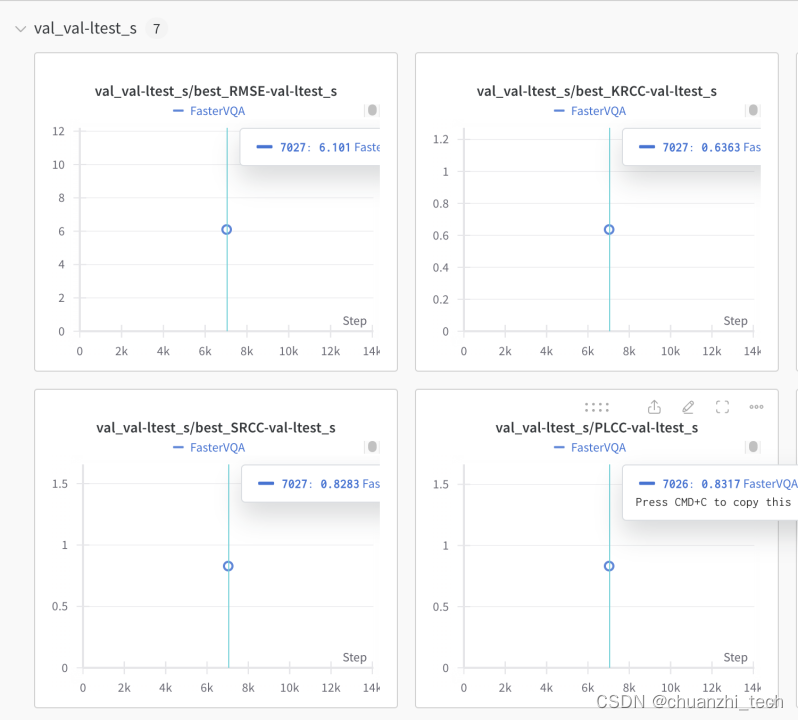
一部分运行结果展示:
在LSVQ_test数据集上结果:
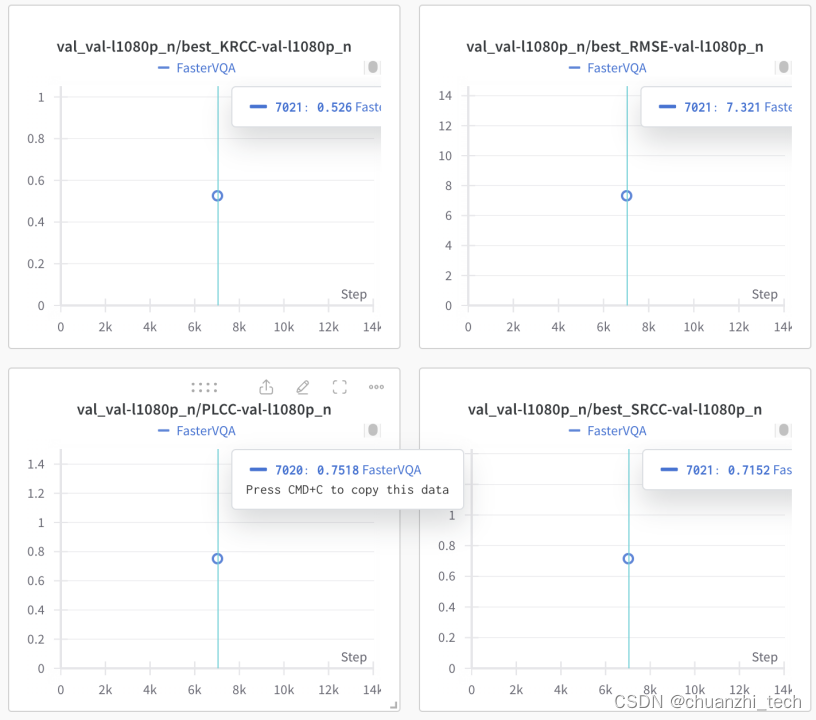
在LSVQ_1080P数据集上结果:
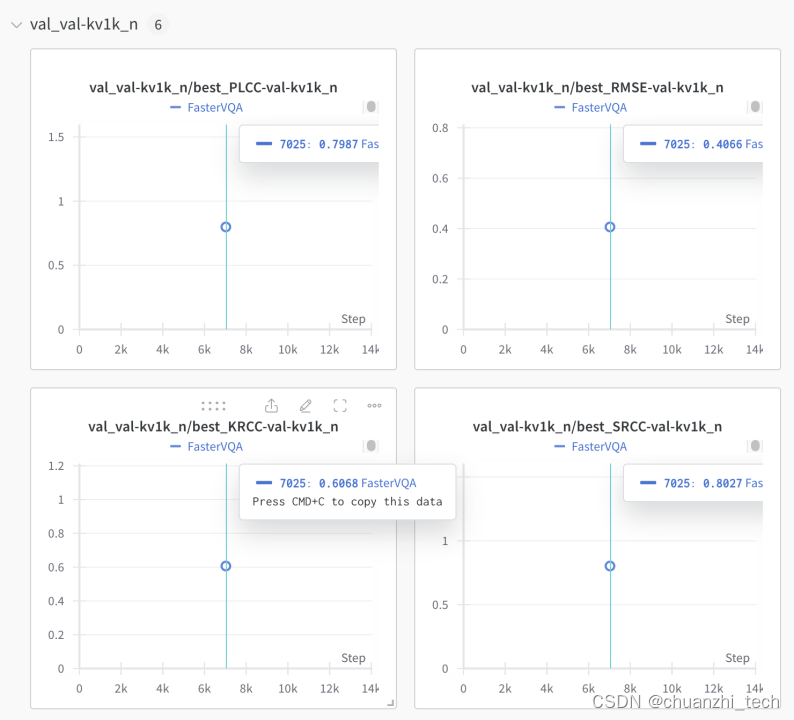
在Konvid-1K数据集上结果:
在LIVE-VQC数据集上结果:
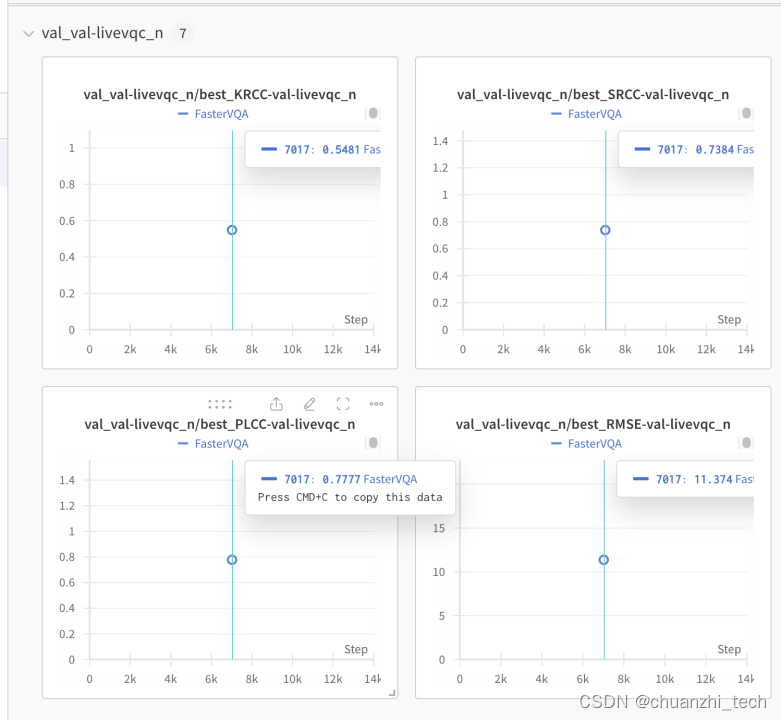
使用方式
python=3.8.8
torch=1.10.2
torchvision=0.11.3
编译器采用Pycharm,拿到代码之后,结合ReadMe以及“requirements.txt”配置好环境之后,可以直接使用预训练的模型进行复现论文;也可以根据自己的需求修改配置文件,在自己想要的库上进行库内或者跨库训练。















 632
632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









