







深度学习中数据传递的机制
在pytorch深度学习训练过程中, 数据流程如下:
- 创建数据集 train_data_set, 通常自定义子类用来继承父类 Dataset ;
- 将数据集 train_data_set 传递给 DataLoader
- DataLoader 迭代产生训练数据,提供给模型.
上述过程对应的代码:
# 1. create dataset, CustomDataset(Dataset), inherit from the class Dataset;
train_data_set = CustomDataset
# 2. pass the dataset to the DataLoader
train_loader = torch.utils.data.DataLoader(dataset, bt=64, shuffle=False, sampler=None, num_workers=8)
# 3. DataLoader 在训练过程中, 迭代产生训练集提供给模型
for i in range(epoch):
for index, (data, label) in enumerate(train_loader):
pass
由此可知, Dataset 负责建立索引到样本的映射,
DataLoader() 负责以特定的方式,从数据集中迭代产生一个个 batch 的样本集合。
在 enumerate() 过程中,实际上是 dataloader()按照其参数sampler 规定的策略调用了其 dataset 中的 __getitem()__方法。
1. Dataloader() 类
初始化函数
class DataLoader(Generic[T_co]):
dataset: Dataset[T_co]
batch_size: Optional[int]
num_workers: int
pin_memory: bool
drop_last: bool
timeout: float
sampler: Sampler
prefetch_factor: int
_iterator : Optional['_BaseDataLoaderIter']
__initialized = False
def __init__(self, dataset: Dataset[T_co], batch_size: Optional[int] = 1,
shuffle: bool = False, sampler: Optional[Sampler[int]] = None,
batch_sampler: Optional[Sampler[Sequence[int]]] = None,
num_workers: int = 0, collate_fn: _collate_fn_t = None,
pin_memory: bool = False, drop_last: bool = False,
timeout: float = 0, worker_init_fn: _worker_init_fn_t = None,
multiprocessing_context=None, generator=None,
*, prefetch_factor: int = 2,
persistent_workers: bool = False):
torch._C._log_api_usage_once("python.data_loader") # type: ignore
1.1 初始化函数中的参数说明
dataset – 之前设置好的数据集。
batch_size – 每个batch 要加载多少样本(默认:“1”)。shuffle – 设置为“True”,在每个epoch开始的时候,对数据进行重新排序 。默认:“False”)。
sampler – 自定义从数据集中取样本的策略,如果指定这个参数,那么shuffle必须为False。
batch_sampler– 与sampler类似,但是一次只返回一个batch的indices(索引),需要注意的是,一旦指定了这个参数,那么batch_size,shuffle,sampler,drop_last就不能再制定了(互斥——Mutually exclusive)
num_workers(int, optional)– 这个参数决定了有几个进程来处理data loading。0意味着所有的数据都会被load进主进程。(默认值:“0”)
collate_fn(callable, optional): – 将一个list的sample组成一个mini-batch的函数。 在从Map (key -value )映射样式数据集使用批量加载时使用。
pin_memory(bool, optional): – 如果设置为True,那么data loader将会在返回它们之前,将tensors拷贝到CUDA中的固定内存(CUDA pinned memory)中.或者 :attr:‘collate_fn’ 返回的批是自定义类型.
drop_last(bool, optional): – 设置为 “True” , 当数据集大小不能被批大小整除,以删除最后一个未完成的批次。
这个是对最后的未完成的batch来说的,比如你的batch_size设置为64,而一个epoch只有100个样本,那么训练的时候后面的36个就被扔掉了
如果“False”并且数据集的大小不能被批大小整除,则最后一个批将更小。(默认值:“False”)
timeout– 这个numeric应总是大于等于0, 表明等待从worker进程中收集一个batch等待的时间,若超出设定的时间还没有收集到,那就不收集这个内容了。应始终为非负数。(默认值:“0”)
worker_init_fn – 如果不是“None”,则将在每个工作子进程上调用此函数,并在种子设定后和数据加载之前,以工作线程 ID(“[0, num_workers - 1]”中的整数)作为输入。(默认值:“无”)
prefetch_factor – 每个worker预先装载的样品数量。“2”表示所有工作线程总共预取 2 * num_workers 个样本。(默认值:“2”)
persistent_workers – 如果为“True”,则数据加载程序不会在数据集使用一次后关闭工作进程。这允许维护工作线程“数据集”实例处于活动状态。(默认值:“False”)
其中几个常用的参数
- dataset 数据集,map-style and iterable-style 可以用index取值的对象、
- batch_size 大小
- shuffle 取batch是否随机取, 默认为False
- sampler 定义取batch的方法,是一个迭代器, 每次生成一个key 用于读取dataset中的值,如果你自定义了sampler,那么shuffle需要设置为False。
- batch_sampler 也是一个迭代器, 每次生次一个batch_size的key
- num_workers 参与工作的线程数
- collate_fn 对取出的batch进行处理
- drop_last 对最后不足batchsize的数据的处理方法
下面看两段取自DataLoader中的__init__代码, 帮助我们理解几个常用参数之间的关系
1.2 DataLoader类的作用
数据加载器。将 dataset 和 sampler 这两个属性结合起来,
结合数据集和采样器,并提供对给定数据集的可迭代对象。
~torch.utils.data.DataLoader 支持映射样式和迭代样式的数据集,具有单进程或多进程加载、自定义加载顺序以及可选的自动批处理(排序规则)和内存固定。
2. 参数sampler
sampler 重点参数 —采样器,是一个迭代器。
这里sampler, 它定义了如何从数据集中取数据的规则。
返回的为一个迭代器,迭代器中可以是数据集中各个样本的位置索引值。
有了smapler, 我们就可以通过batch, 从而在数据集中按照Sampler的定义的取法,一次取出多个数据。
2.0 父类 Sampler()
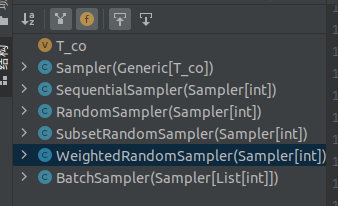
仔细查看源代码其实可以发现,所有采样器其实都继承自同一个父类,即Sampler,其代码定义如下:
class Sampler(object):
# """Base class for all Samplers.
# Every Sampler subclass has to provide an __iter__ method, providing a way
# to iterate over indices of dataset elements, and a __len__ method that
# returns the length of the returned iterators.
# """
# 一个 迭代器 基类
def __init__(self, data_source):
pass
def __iter__(self):
raise NotImplementedError
def __len__(self):
return len(self.data_source)
所以要做的就是定义好__iter__(self)函数,不过要注意的是该函数的返回值需要是可迭代的。
例如SequentialSampler返回的是iter(range(len(self.data_source)))。
所有sampler都是继承 torch.utils.data.sampler.Sampler这个抽象类。
抽象类的特点是,只能被继承,不能被实例化
PyTorch提供了多种采样器,用户也可以自定义采样器。
Pytorch 已经实现的Sampler 有如下几种方式:
- SequentialSampler
- RandomSampler
- SubsetRandomSampler
- WeightedSampler
- WeightedRandomSampler weightedRandomSampler函数的介绍
- SubsetRandomSampler
2.1 子类SequentialSampler()
SequentialSampler 很好理解就是顺序采样器。
原理:在初始化的时候,拿到数据集 data_source, 之后在 __iter__ 魔法函数中,得到一个和 data_source 一样长度的 range 可迭代器。 每次只返回一个索引值;
class SequentialSampler(Sampler):
# r"""Samples elements sequentially, always in the same order.
# Arguments:
# data_source (Dataset): dataset to sample from
# """
# 产生顺序 迭代器
def __init__(self, data_source):
self.data_source = data_source
def __iter__(self):
return iter(range(len(self.data_source)))
def __len__(self):
return len(self.data_source)
2.2 子类RandomSampler()
我们可以看下自带的RandomSampler类中最重要的iter函数
class RandomSampler(Sampler):
# r"""Samples elements randomly. If without replacement, then sample from a shuffled dataset.
# If with replacement, then user can specify ``num_samples`` to draw.
# Arguments:
# data_source (Dataset): dataset to sample from
# num_samples (int): number of samples to draw, default=len(dataset)
# replacement (bool): samples are drawn with replacement if ``True``, default=False
# """
def __init__(self, data_source, replacement=False, num_samples=None):
self.data_source = data_source
self.replacement = replacement
self.num_samples = num_samples
if self.num_samples is not None and replacement is False:
raise ValueError("With replacement=False, num_samples should not be specified, "
"since a random permute will be performed.")
if self.num_samples is None:
self.num_samples = len(self.data_source)
if not isinstance(self.num_samples, int) or self.num_samples <= 0:
raise ValueError("num_samples should be a positive integeral "
"value, but got num_samples={}".format(self.num_samples))
if not isinstance(self.replacement, bool):
raise ValueError("replacement should be a boolean value, but got "
"replacement={}".format(self.replacement))
def __iter__(self):
n = len(self.data_source)
# dataset的长度, 按顺序索引
if self.replacement:# 对应的replace参数
return iter(torch.randint(high=n, size=(self.num_samples,), dtype=torch.int64).tolist())
return iter(torch.randperm(n).tolist())
可以看出,其实就是生成样本的位置索引,然后随机的取值, 然后再迭代。
- data_source: 同上
- num_samples: 指定采样的数量,默认是所有。
- replacement: 若为True,则表示可以重复采样,即同一个样本可以重复采样,这样可能导致有的样本采样不到。所以此时我们可以设置num_samples来增加采样数量使得每个样本都可能被采样到。
2.3 子类 SubsetRandomSampler()
该子类常见的用法,是将数据集划分为训练集和验证集
class SubsetRandomSampler(Sampler):
# r"""Samples elements randomly from a given list of indices, without replacement.
# Arguments:
# indices (sequence): a sequence of indices
# """
def __init__(self, indices):
self.indices = indices
def __iter__(self):
return (self.indices[i] for i in torch.randperm(len(self.indices)))
def __len__(self):
return len(self.indices)
2.4 子类WeightedRandomSampler()
sampler 可以通过如下可以有多个类中的__init__() 函数实现:
sampler = torch.utils.data.sampler.WeightedRandomSampler(weights, len(train_dataset))
2.5 子类BatchSampler()
BatchSampler的生成过程。
-
前面的采样器每次都只返回一个索引,但是我们在训练时是对批量的数据进行训练,而这个工作就需要BatchSampler来做。
-
也就是说BatchSampler的作用就是将前面的Sampler采样得到的索引值进行合并,当数量等于一个batch大小后就将这一批的索引值返回
BatchSampler与其他Sampler的主要区别是它需要将Sampler作为参数进行打包,进而每次迭代返回以batch size为大小的index列表。
- 也就是说在后面的读取数据过程中使用的都是batch sampler。
class BatchSampler(Sampler):
# Wraps another sampler to yield a mini-batch of indices.
# Args:
# sampler (Sampler): Base sampler.
# batch_size (int): Size of mini-batch.
# drop_last (bool): If ``True``, the sampler will drop the last batch if
# its size would be less than ``batch_size``
# Example:
# >>> list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=False))
# [[0, 1, 2], [3, 4, 5], [6, 7, 8], [9]]
# >>> list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=True))
# [[0, 1, 2], [3, 4, 5], [6, 7, 8]]
# 批次采样
def __init__(self, sampler, batch_size, drop_last):
if not isinstance(sampler, Sampler):
raise ValueError("sampler should be an instance of "
"torch.utils.data.Sampler, but got sampler={}"
.format(sampler))
if not isinstance(batch_size, _int_classes) or isinstance(batch_size, bool) or \
batch_size <= 0:
raise ValueError("batch_size should be a positive integeral value, "
"but got batch_size={}".format(batch_size))
if not isinstance(drop_last, bool):
raise ValueError("drop_last should be a boolean value, but got "
"drop_last={}".format(drop_last))
self.sampler = sampler
self.batch_size = batch_size
self.drop_last = drop_last
def __iter__(self):
batch = []
for idx in self.sampler:
batch.append(idx)
if len(batch) == self.batch_size:
yield batch
batch = []
if len(batch) > 0 and not self.drop_last:
yield batch
就是按batch_size从sampler中读取索引, 并形成生成器返回。
3.参数batch_sampler
自带的注释中对batch_sampler有一句话: Mutually exclusive with :
attr:batch_size :
attr:shuffle, :
attr:sampler,
and :attr:drop_last.
-
意思就是batch_sampler 与这些参数互斥 ,
-
即如果你定义了batch_sampler, 其他参数(bt, sampler, 上面的参数)都不需要有. 所以,一般情况下,
batch_sampler不要定义。 -
如果batch_sampler没有定义的话且batch_size有定义, 会根据sampler, batch_size, drop_last生成一个batch_sampler。
-
如果自定义了 batch_sampler , 则一次返回一批索引。 并且定义了batch_sampler 之后,attr:‘batch_size’、:attr:‘shuffle’、:attr:‘sampler’ 和 :attr:‘drop_last’ 这些参数都要使用默认值,不要定义。
3.1 参数sampler与 与参数shuffle 之间的关系
当我们sampler有输入时,shuffle的值就没有意义,
if sampler is None: # give default samplers
if self._dataset_kind == _DatasetKind.Iterable:
# See NOTE [ Custom Samplers and IterableDataset ]
sampler = _InfiniteConstantSampler()
else: # map-style
if shuffle:
sampler = RandomSampler(dataset)
else:
sampler = SequentialSampler(dataset)
当dataset类型是map style时, shuffle其实就是改变sampler的取值
3.2 参数sampler与参数batchsampler之间的关系
如果sampler和batch_sampler都为None,
那么batch_sampler使用Pytorch已经实现好的BatchSampler,
而sampler分两种情况:
若shuffle=True,则sampler=RandomSampler(dataset)
若shuffle=False,则sampler=SequentialSampler(dataset)
- shuffle为默认值 False时,sampler是SequentialSampler,就是按顺序取样。
- shuffle为True时,sampler是RandomSampler, 就是按随机取样。
4. 参数 dataset
假设dataset 通过实例化类Dataset() 实现:
test_dataset = image_loader_TGT4channel(self.args.data_dir,self.args.split_method, self.args.folds_file, self.args.test_fold,
False, self.input_transform, self.args.aug_scale, self.args.stetho_id,)
上面的子类image_loader_TGT4channel, 继承于父类Dataset, 主要是实现了其中的__getitem()__ 方法:
4.1 父类 Dataset
class Dataset(object):
def __init__(self):
...
def __getitem__(self, index):
return ...
def __len__(self):
return ...
上面三个方法是最基本的,其中__getitem__是最主要的方法,它规定了如何读取数据。
但是它又不同于一般的方法,
因为它是python built-in方法,其主要作用是能让该类可以像list一样通过索引值对数据进行访问。
现在如果你想对__getitem__方法进行调试,你可以写一个for循环遍历dataset来进行调试了,而不用构建dataloader等一大堆东西了,
建议学会使用ipdb这个库,非常实用!!!
在此之前我一直没弄清楚__getitem__是什么作用,所以一直不知道该怎么进入到这个函数进行调试。
4.2 dataset 与DataLoader 之间的关系
文章最开始已经说过,将dataset 准备好的数据集,输入到 DataLoader 中,方便在训练的过程中,一次性取出 batch 个数据
假如定义好了一个dataset,那么可以直接通过dataset[0]来访问第一个数据。
通过最前面的Dataloader的__next__函数可以看到DataLoader对数据的读取其实就是用了for循环来遍历数据,如下:
这里注意,不同的pytorch 版本实现方式不一样,有的是将其放在 _BaseDataLoaderIter()该私有类中实现魔法函数__next__(), 或者在其子类中(单线程或多线程)实现:
class DataLoader(object):
def __next__(self):
if self.num_workers == 0:
indices = next(self.sample_iter)
batch = self.collate_fn([self.dataset[i] for i in indices]) # this line
if self.pin_memory:
batch = _utils.pin_memory.pin_memory_batch(batch)
return batch
仔细看可以发现,前面还有一个self.collate_fn方法,这个是干嘛用的呢?在介绍前我们需要知道每个参数的意义:
indices: 表示每一个iteration,sampler返回的indices,即一个batch size大小的索引列表;
self.dataset[i]: 前面已经介绍了,这里就是对第i个数据进行读取操作,一般来说self.dataset[i]=(img, label)
看到这不难猜出collate_fn的作用就是将一个batch的数据进行合并操作。
默认的collate_fn是将img和label分别合并成imgs和labels,所以如果你的__getitem__方法只是返回 img, label,那么你可以使用默认的collate_fn方法,但是如果你每次读取的数据有img, box, label等等,那么你就需要自定义collate_fn来将对应的数据合并成一个batch数据,这样方便后续的训练步骤。
5. pin_memory 与 num_worker参数
5.1 pin_memory
所谓的 pin_memory 就是锁页内存的意思。
计算机为了运行进程会先将进程和数据读到内存里。一般来说,计算机的内存都是比较小的,很难存的下太多的数据。但是,某个进程在某个时间段所需的进程和数据往往是比较少的,也就是说在某个时间点我们不需要将一个进程所需要的所有资源都放在内存里。我们可以将这些暂时用不到的数据或进程存放在硬盘一个被称为虚拟内存的地方。在进程运行的时候,我们可以不断交换内存和虚拟内存的数据以减少内存所需存储的数据。而且这些交换往往是通过某些规律预测下个时刻进程会用到的数据和代码并提前交换至内存的,这些规律的使用以及预测的准确性将会影响到进程的速度。
所谓的锁页内存就是说,我们不允许系统将某些内存里的数据交换至虚拟内存,毋庸置疑这将会提升进程的运行速度。但是也会是内存的存储占用消耗很多。
pin_memory 为 true 的时候速度的提升会有多大
5.2 num_workers
Dataloader 多进程读取数据的参数是通过num_workers指定的,num_workers 为 0 的话就用主进程去读取数据,num_workers 为 N 的话就会多开 N 个进程去读取数据。这里的多进程是通过 python 的 multiprocessing module 实现的(其实 pytorch 在 multiprocessing 又加了一个 wraper 以实现shared memory)。
关于 num_workers的工作原理:
-
开启num_workers个子进程(worker)。
-
每个worker通过主进程获得自己需要采集的ids。
ids的顺序由采样器(sampler)或shuffle得到。然后每个worker开始采集一个batch的数据。(因此增大num_workers的数量,内存占用也会增加。因为每个worker都需要缓存一个batch的数据) -
在第一个worker数据采集完成后,会卡在这里,等着主进程把该batch取走,然后采集下一个batch。
-
主进程运算完成,从第二个worker里采集第二个batch,以此类推。
-
主进程采集完最后一个worker的batch。此时需要回去采集第一个worker产生的第二个batch。如果第一个worker此时没有采集完,主线程会卡在这里等。(这也是为什么在数据加载比较耗时的情况下,每隔num_workers个batch,主进程都会在这里卡一下。)
所以:
-
如果内存有限,过大的num_workers会很容易导致内存溢出。
-
可以通过观察是否每隔num_workers个batch后出现长时间等待来判断是否需要继续增大num_workers。如果没有明显延时,说明读取速度已经饱和,不需要继续增大。反之,可以通过增大num_workers来缓解。
-
如果性能瓶颈是在io上,那么num_workers超过(cpu核数*2)是有加速作用的。但如果性能瓶颈在cpu计算上,继续增大num_workers反而会降低性能。(因为现在cpu大多数是每个核可以硬件级别支持2个线程。超过后,每个进程都是操作系统调度的,所用时间更长)
Dataloader 读数据的整个流程:
-
首先每个 worker 的进程会拥有一个 index_queue,dataloader 初始化的时候,每个 worker 的 index_queue 会放入两个batch 的 index。index 的放入是根据 worker 的 id顺序放入的。
-
每个 worker 的进程会不断检查自己的 index_queue 里有没有值,没有的话就继续检查。有的话,就去读一个 batch(这个读的过程是通过调用 dataset 的get_item()实现的,并通过collate_fn 函数将数据合并为一个 batch)。放入所有 worker 共享的 data_queue(如果指定了 pin_memory,这个新加的 batch 是会被放入 pin_memory 的)
-
Dataloader 会返回一个迭代器,每迭代一次,首先进程会检查这次要 load 的 idx 数据是不是之前已经 load 过了(已经从共享的 data_queue 里取出来了),并事先放在一个字典里存起来了(为什么会 load 过,下面会解释),如果是的话,就直接拿来用。 如果没有 load 过,就从 data_queue 获取下一个 batch 和相应的 idx,但是这里从 data_queue 获得的 batch 可能不是按顺序的,因为有的 worker 可能比较快提前将它的数据读好放到 data_queue 里了。这时候我们将这个提前来的 batch 先保存到 self.reorder_dict 这个字典里面,这就解释了上面为什么会出现 load 过的问题。如果一直等不到我们就会一直将提前来的 batch 放入 self.reorder_dict 暂存,直至我们等到那个按顺序来的 batch。
-
在每次迭代成功的时候,dataloader 会放入一个新的 batch_index 到特定 worker 的 index_queue 里面
可以看出,dataloader 只会在每次迭代成功的时候才会放入新的 index 到 index_queue 里面。因为上面写了在初始化 dataloader 的时候,我们一共放了 2 x self.num_workers 个 batch 的 index 到 index_queue。读了一个 batch 才会放新的 batch,所以这所有的 worker 进程最多缓存的 batch 数量就是 2 x self.num_workers 个。
参考:
https://zhuanlan.zhihu.com/p/76893455;
https://blog.csdn.net/ytusdc/article/details/128517308;
https://zhuanlan.zhihu.com/p/105578087















 2498
2498











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









