






论文名称:ChatLaw: Open-Source Legal Large Language Model
with Integrated External Knowledge Bases
github地址:GitHub - PKU-YuanGroup/ChatLaw: 中文法律大模型![]() https://github.com/PKU-YuanGroup/ChatLaw
https://github.com/PKU-YuanGroup/ChatLaw
- 解决幻觉和不可靠输出问题
- 方法:在OpenLLAMA的基础上建立了一个商业上可行的模型,通过扩展中文词汇并结合来自MOSS等来源的训练数据,创建一个基本的汉语模型。随后,我们将法律特定数据纳入我们的法律模型——ChatLaw。
- 主要贡献:
- 解决幻觉:推理过程增加4个模块——"consult," "reference", "self-suggestion" and "response." 利用知识库将特定领域知识注入到模型中
- 基于LLM的法律特征词提取模型
- 基于BERT的法律文本相似度计算模型:测量用户日常语言和由93万个相关法律案件语言组成的数据集之间的相似性。有助于建立矢量知识库,便于检索类似法律文本
- 构建中文法律考试测试数据集:一个专门为中文法律领域知识测试设计的数据集。此外,设计ELO竞技场评分机制来比较不同模型在法律选择题中的表现
- 任务规划:单个通用法律LLM可能无法在该领域的所有任务中执行最佳性能。因此,针对不同的场景训练了不同的模型,如选择题、关键词提取和问答。为了处理这些模型的选择和部署,我们使用HuggingGPT[6]提供的方法,使用一个大型LLM作为控制器。这个控制器模型根据每个用户的请求动态地决定调用哪个特定的模型,确保为给定的任务使用最合适的模型。
- 数据集:要全面且多样
- 收集大量的原始法律数据:包括收集法律新闻、社交媒体内容和法律行业论坛的讨论。这些来源提供了一个多样化的现实世界的法律文本,提供见解到各种法律主题和讨论。
- 基于法律法规和司法解释的构建:为确保法律知识的全面覆盖,我们将相关法律法规和司法解释纳入数据集。这确保数据集反映法律框架,并提供准确和最新的信息。
- 抓取真实法律咨询数据:我们检索真实的法律咨询数据,利用现有的法律咨询数据集。这允许包含用户经常遇到的现实世界的法律场景和问题,用实际的法律示例丰富数据集。
- 律师资格考试多项选择题的构建:我们创建了一套专门为律师资格考试设计的多项选择题。这些问题涵盖各种法律主题,测试用户对法律原则的理解和应用。
过滤掉简短和不连贯的回复,确保只包含高质量和有意义的文本。此外,为了增强数据集,我们利用ChatGPT API进行辅助构建,使我们能够基于现有数据集生成补充数据。
- 训练过程:①关键词LLM;②法律LLM;③法律问答LLM
- 关键词LLM是从用户提出的抽象咨询问题中提取关键词的语言模型;
- 法律LLM摘录了用户咨询中可能涉及的法律术语;
- ChatLaw LLM是向用户输出响应的终极语言模型。它参考相关法律条款,并利用自身的摘要和问答功能,为用户提供咨询建议。
ChatLAW:Ziya-LLaMA-13B[11]的基础上使用低秩自适应(Low-Rank Adaptation, LoRA)[3]对其进行了微调。此外,引入自我暗示角色,进一步缓解模型幻觉问题。训练过程在多个A100 gpu上进行,并借助deepspeed进一步降低了训练成本。
关键词LLM:通过将特定于垂直领域的LLM与知识库相结合来创建ChatLaw产品,根据用户查询从知识库中检索相关信息至关重要。最初尝试了传统的软件开发方法,如MySQL和Elasticsearch进行检索,但结果并不令人满意。因此,尝试使用预训练的BERT模型进行嵌入,其次是Faiss[4]等方法,计算余弦相似度,提取与用户查询相关的前k个法律法规。然而,当用户的问题很模糊时,这种方法通常会产生次优结果。因此,我们的目标是从用户查询中提取关键信息,并利用这些信息的向量嵌入设计算法来提高匹配精度。
Law LLM:我们使用937k个国家案例的数据集训练BERT模型,从用户查询中提取相应的法律条款和司法解释。Law LLM模型构成了ChatLaw产品的重要组成部分。
由于大型模型在理解用户查询方面具有显著优势,我们对LLM进行了微调,以便从用户查询中提取关键字。在获得多个关键词后,我们采用算法1(基于大模型关键字提取的法律检索)检索相关法律规定。

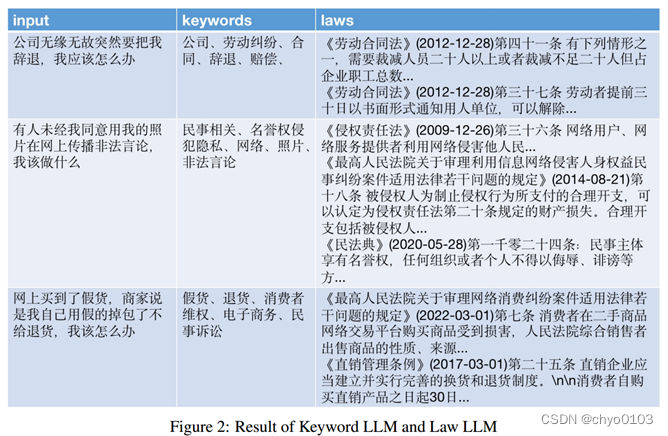
(可见关键词提取做的相对较好)
- 实验和分析(比较单薄不具体):
- 如何评估LLM?由于各模型准确率普遍比较低,因此采用Elo积分的模型竞赛评估机制(受电子竞技中的配对机制和Chatbot Arena的设计[13]的启发,)。
- 测试数据集:编制了一个包含2000个问题及其标准答案的测试数据集,以衡量模型处理法律选择题的能力。
- 实验结论:(1)引入法律相关问答和法规数据可以在一定程度上提高模型在选择题上的表现;(2)增加特定的训练任务类型,显著提高了模型在这些任务上的性能。例如,ChatLaw模型优于GPT-4的原因是我们使用了大量的选择题作为训练数据;(3)法律选择题需要复杂的逻辑推理,因此参数数量较多的模型通常表现更好。
- 结论:
用向量知识库缓解幻觉问题
构建了法律选择题测试数据集并建立了ELO评分机制
在逻辑推理和演绎等任务中的表现并不理想——通用任务泛化能力有待提高
| 架构 | ChatLaw=ChatLaw LLM + keyword LLM + laws LLM |
| 关键词抽取 | keyword LLM利用大模型生成关键词,不仅可以找到文本中的重点内容,还可以总结并释义出一些词。 |
| 微调方式 | 姜子牙 Lora (Low-Rank Adaptation) |
下一篇阅读《A Survey on Evaluation of Large Language Models》
LLM领域小白,欢迎大家批评指正以及推荐相关论文~















 1718
1718











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









