







本文希望阐述堆排序O(nlogn)的一些关键细节,摘录一篇博文O(n^2)进行比较。
用作比较的原文 版权声明:为者常成,行者常至
堆排序的特点是优化后的选择排序,其时间复杂度为O(nlogn),下面第一段代码的做法比这个复杂度要高。原因在下文阐述。
堆排序将要排序的对象看做一颗完全二叉树,数据结构可以用数组来实现。
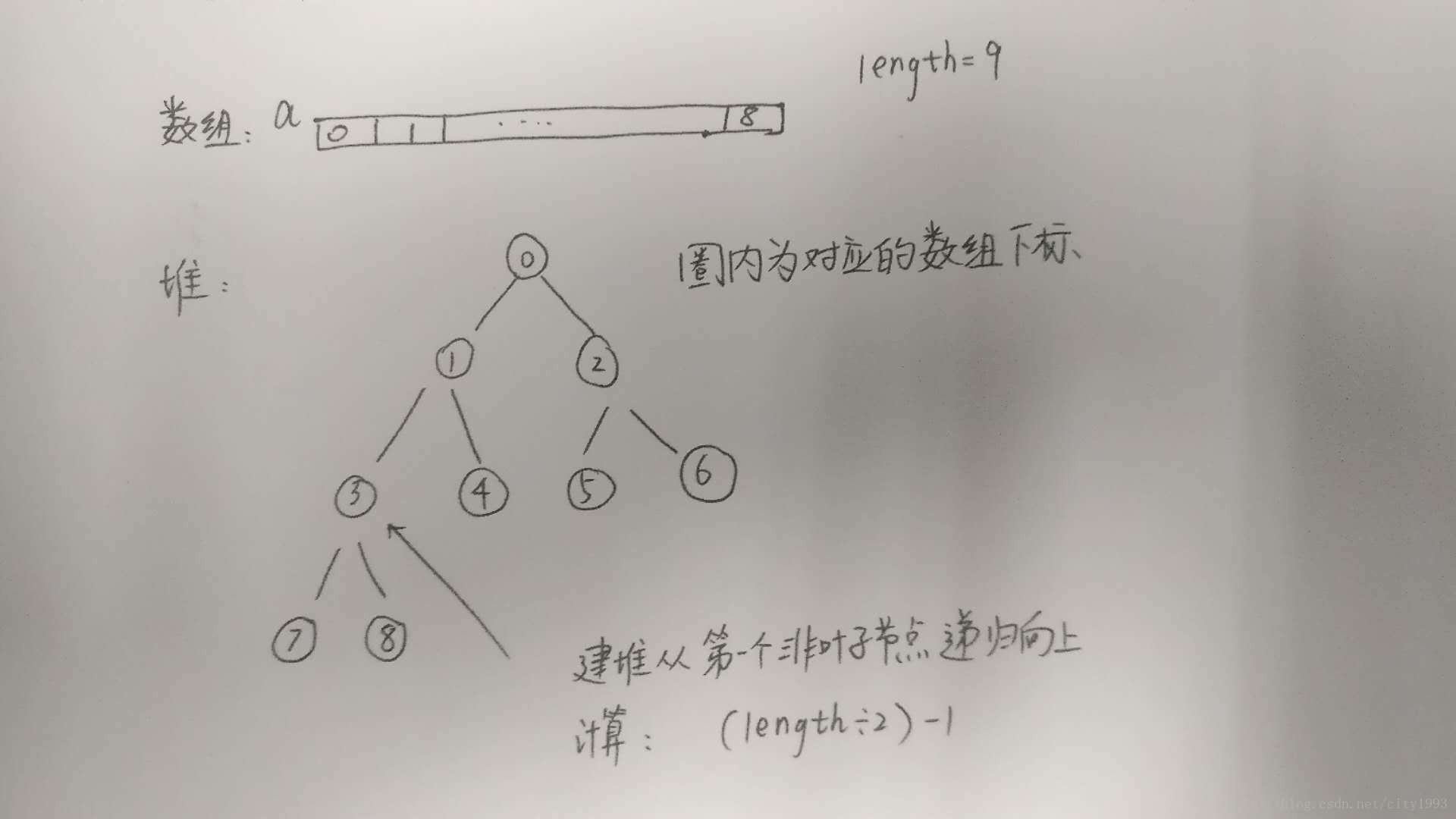
初始化建堆过程时间:O(n) 更改堆元素后重建堆时间:O(nlogn)
具体证明可见:http://blog.csdn.net/yuzhihui_no1/article/details/44258297
下面的做法是在建好堆之后,交换堆顶和堆底之后,又执行了重建堆的过程。复杂度应该为O(n^2)。
待比较程序代码如下:
改进的重建堆的过程
public class HeapSorter implements Sorter{
/* (non-Javadoc)
* @see A4.Sorter#sort(java.lang.Comparable[])
*/
@Override
public void sort(Comparable[] data) {
buildMaxHeap(data,data.length);
}
int parent(int i)
{
return (i-1)/2;
}
int left(int i)
{
return 2*i+1;
}
int right(int i)
{
return 2*i+2;
}
/**
* 将堆排序选出的最大的元素放到数组的最后位置。
* 下午10:38:26
* 2017年11月29日
* @author city
*/
private void buildMaxHeap(Comparable[] data, int heapSize) {
// First Step build Max-heap
for(int i = heapSize/2-1;i>=0;i--)
{
maxHeapfy(data,i,heapSize);
}
for(int i = data.length-1;i>0;i--)
{
Comparable tmp = data[i];
data[i] = data[0];
data[0] = tmp;
maxHeapfy(data, 0, i);
}
}
/**
* 堆排序算法核心,建立最大堆。
* 下午10:39:54
* 2017年11月29日
* @author city
*/
private void maxHeapfy(Comparable[] data, int i, int heapSize) {
// TODO Auto-generated method stub
int left = left(i);
int right = right(i);
int largest = i;
if(left<heapSize && data[left].compareTo(data[largest])>0)
{
largest = left;
}
if(right<heapSize && data[right].compareTo(data[largest])>0)
{
largest = right;
}
if(largest!=i)
{
Comparable tmp = data[largest];
data[largest] = data[i];
data[i] = tmp;
maxHeapfy(data, largest, heapSize);
}
}
}如有错误,请指正
比较原文转载自http://blog.csdn.net/qq_35178267/article/details/78313306#insertcode
如有侵权请联系















 7372
7372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









