







引言:强化学习的"圣杯"突破
在人工智能领域,开发无需调整超参数即可适应多样化任务的通用强化学习(RL)算法,长期以来被视为该领域的"圣杯"。传统RL算法如PPO需要针对每个新任务进行繁琐调参,而专用算法如MuZero虽性能卓越却难以迁移。2025年4月,Google DeepMind在《Nature》发表的第三代Dreamer算法(DreamerV3),以单一固定配置在8大领域、150余项任务中超越专用算法,更首次实现AI从零开始通关《我的世界》钻石收集任务,标志着通用RL向现实应用迈出关键一步。
核心架构:世界模型驱动的想象式学习
DreamerV3的突破性源于其"世界模型-评论者-行动者"三模块架构,通过构建虚拟环境模型实现"想象式学习",彻底改变传统RL的试错范式:
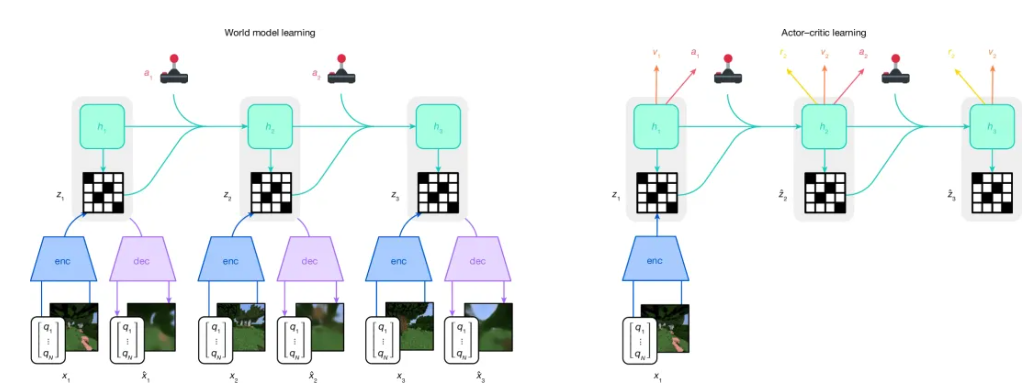
世界模型(World Model)
- 将高维感官输入(如像素图像)压缩为低维潜在表征(Latent Representation)
- 通过编码器、序列模型和动态预测器组成的混合架构,预测潜在行动的未来状态和奖励
- 关键创新:采用KL平衡与自由比特技术动态调整模型权重,防止表征崩塌
评论者(Critic)
- 评估想象轨迹的长期价值,采用双热分布回归处理多模态奖励分布
- 引入百分位回报归一化技术,将回报缩放至[0,1]区间,平衡探索与利用
行动者(Actor)
- 基于归一化回报和熵正则化技术选择最优行动
- 完全依赖世界模型的抽象轨迹进行决策,显著降低计算成本
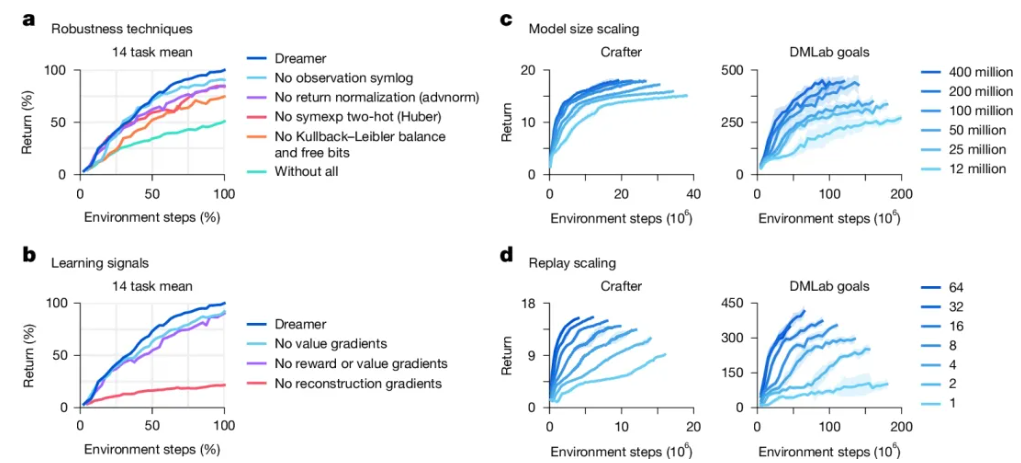
关键技术:跨领域稳定的四重保障
为实现从Atari游戏到机器人控制的跨领域鲁棒性,DreamerV3集成四大核心技术:
| 技术名称 | 核心机制 | 应用效果 |
|---|---|---|
| Symlog-Symexp变换 | 对输入/奖励进行双对称对数压缩,抑制极端值干扰 | 解决奖励尺度差异问题 |
| KL平衡与自由比特 | 动态调整世界模型损失权重,维持表征稳定性 | 防止模型坍塌 |
| 百分位回报归一化 | 基于历史回报分布动态调整缩放区间 | 平衡探索-利用矛盾 |
| 双热损失(Two-hot Loss) | 将连续值预测转化为分类问题,捕获多模态分布特征 | 提升稀疏奖励场景下的学习效率 |
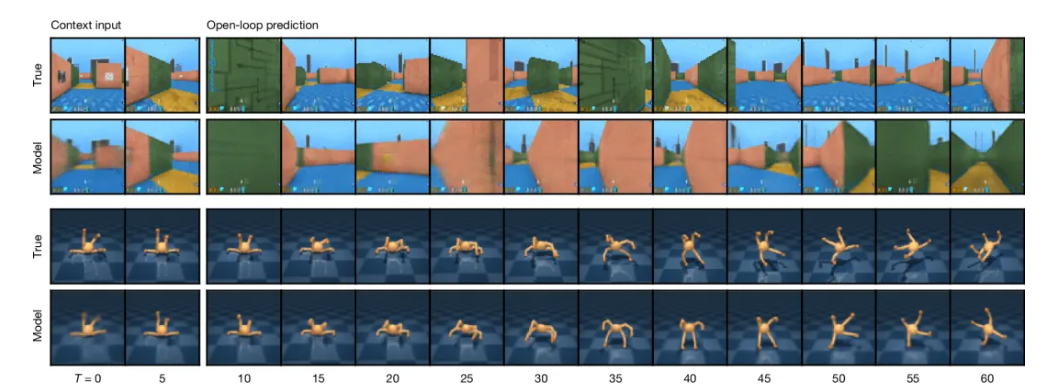
这些技术使DreamerV3在从Atari游戏到机器人控制的跨越中保持超参数不变。如下是世界模型的视频预测。
性能验证:突破性实验结果
1. 跨领域基准测试(8大领域/150+任务)
在涵盖连续控制、离散动作、视觉输入等多样化场景的测试中,DreamerV3展现出惊人的泛化能力:
- Atari游戏:无需调整即超越Rainbow等专用算法
- 机器人控制:在DMLab三维导航任务中达到人类专家水平
- 程序生成环境:在ProcGen的30项随机生成任务中保持稳定表现
在Atari游戏和机器人控制任务中基准测试分数如下:

2. 《我的世界》钻石挑战
这一里程碑任务需要智能体完成"采集木材→制作木镐→开采铁矿→锻造铁镐→寻找钻石"的复杂行为链:
- 零先验知识:无需人类示范视频(VPT)或课程学习
- 纯像素输入:仅依赖屏幕像素和稀疏奖励信号
- 突破性效率:仅1亿环境步数(约10小时)完成目标
《我的世界》钻石挑战的表现如下所示。

3. 模型扩展性验证
在参数规模从1200万到4亿的测试中,发现:
- 正相关定律:模型规模与任务性能呈显著正相关
- 数据效率提升:4亿参数模型所需训练步数减少60%
- 梯度更新优化:增加重放比例可加速收敛
未来方向:通向通用人工智能之路
DreamerV3的成功为AI研究开辟新路径:
- 跨模态世界模型:训练单一模型掌握多领域物理规律
- 无监督预训练:利用YouTube视频等海量无标签数据增强初始表征
- 机器人应用迁移:将虚拟环境中的鲁棒性延伸至实体机器人控制
- 终身学习框架:实现持续累积知识而不遗忘旧任务
总结与启示
DeepMind此项突破不仅解决了RL的"脆性"问题,更揭示了通向通用人工智能的可能路径。其核心启示在于:
- 模型驱动 > 数据驱动:通过构建可解释的世界模型,降低对试错数据的依赖
- 归一化即泛化:跨领域稳定的关键在于动态适应不同信号尺度
- 规模定律延续:大模型+多梯度更新仍是提升性能的有效路径
随着计算资源的持续增长,这种基于世界模型的通用学习框架,或将成为打开AGI之门的核心钥匙。对于AI从业者而言,理解Dreamer的架构思想,将有助于把握下一代RL技术的发展脉搏。
论文信息
- 题目:Mastering diverse control tasks through world models
- 作者:Danijar Hafner等
- 期刊:Nature (2025)
- DOI:10.1038/s41586-025-08744-2

















 466
466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









