







1 传统强化学习的不足 & 为什么需要分层强化学习?
传统的强化学习方法会面临维度灾难的问题,即当环境较为复 杂或者任务较为困难时,agent的状态空间过大,会导致需要学习的参数以及所需的存储空间急速增长,强化学习难以取得理想的效果。
为了解决 维度灾难,研究者提出了分层强化学习(hierarchical reinforcement learning,HRL)。HRL的主要目标是将复杂的问题分解成多个小问题,分别解决小问题从而达到解决原问题的目的【有点类似于分治?】
2 复习:强化学习&马尔科夫决策过程
大多数关于强化学习的研究都是建立在马尔可夫决策过程MDP 的基础上,MDP可以表示为一 个五元组<S,A,P,R,γ> 。其中:
- S为状态state的有限集合,集合中某个状态表示为 s∈S;
- A 为动作 action 的有限集合, 集合中某个动作表示为a ∈ A,A 为状态s下可执行的动作集合;
- P为状态转移 方程,
表示在状态s执行动作 a后将以
的 概 率 跳 转 到 状 态 s′;
- R 为 奖 赏 函 数reward function ;
- γ 为折损系数discount factor, 0 ≤γ ≤ 1。
假设一个 agent观察到自己的状态s,此 时它选择一个动作a,它会得到一个即时的奖赏
,然后以
马尔可夫决策过程有马尔可夫性,即系统的下个状态只与当前状态有关,与之前的状态无关。当马尔可夫决策过程中作出决策时,只需要考虑当前的状态,而不需要历史数据, 这样大大降低了问题的复杂度。
强化学习需要agent学习一个策略
,通过
的值来指导 agent进行动 作的选择。
给定一个策略 π 和一个状态s,
表示 从s开始按照策略 π 进行选择可以得到的期望累积 奖赏。我们将V称作值函数value function ,其具体的数学定义为
强化学习的目标是学到一个最优的策略 π, 最大化每一个状态下的 V 值,此时的最优值函数记作 V∗。
除了值函数,动作-值函数(action-value function)也在强化学习中扮演着重要的角色,记作
, 表示给定一个策略 π,在状态s上执行动作a可以得到的期望累积奖赏。其具体的数学定义表示为
同样的,我们也希望通过学习到一个最优的 Q 函数 Q∗,使agent可以直接通过Q函数来选择当前状态下应该执行的动作。
3 半马尔可夫决策过程 semi-markov decision process SMDP
马尔可夫决策过程中,选择一个动作后,agent会立刻根据状态转移方程P跳转到下一个状态,而 在半马尔可夫决策过程中,当前状态到下一个状态的步数是一个随机变量 τ, 即在某个状态s下选择一个动作a后,经过 τ 步才会以一个概率转移到下一个状态s′(多次和环境发生交互之后,状态才会改变【在之后可以知道,这一系列action我们可以看成一个option】)。

此时的状态转移概率是s和τ的联合概率![]() 。根据 τ 的定义域不同,SMDP所定义的系统也有所不同。
。根据 τ 的定义域不同,SMDP所定义的系统也有所不同。
- 当 τ 的取值为实数值,则SMDP构建了一个连续时间 - 离散事件系统
- 当 τ 的取值为正整数,则是一个离散时间SMDP
出于简单考虑,绝大部分分层强化学习都是在离散时间 SMDP 上进行讨论。
4 封建等级式学习 Feudal Learning
论文笔记: Feudal Reinforcement Learning_UQI-LIUWJ的博客-CSDN博客

Feudal Reinforcement Learning NIPS 1992
feudal learning受中世纪欧洲封建制度的启发。其主要思路是:将整个要解决的问题分为多个层级,上层调用下层来解决任务,下层执行上层的命令(也就是reward设计其实是根据上层的需求实现的)。
封建学习主要的特征有两个:
- 奖赏隐藏(reward hiding):每层只知道本层的奖赏,而每层的目标(由上层指定)就编码到reward函数中;【每层只要满足该层的奖励最大化,不用满足上面层级的奖励最大化(因为也不知道)】
- 信息隐层:每层只关注其应该关注到的信息,而不是真实的环境信息(全局信息)。【底下干活的人无需知道大领导给小领导安排的事儿】

论文中给出的是迷宫导航问题,由于文章是92年发的,DRL还远远不成熟,因此是使用Q-learning表格型解法来做.
不过,封建学习算法主要针对特定类型的问题,并没有收敛到任何明确定义的最优策略。但它为许多其他贡献铺平了道路。
5 基于选项(option)的强化学习
5.1 option
option 可以看作是一种对动作的抽象。
一般来说,option可以表示为一个三元组
,其中:
是这个option的策略(决定option内部的action)【inner-option policy】
表示终止条件,β(s)表示状态s有β(s)的概率终止并退出此option
表示option的初始状态集合
option
当option开始执行时,agent 通过该option的 π 进行动作选择直到终止。
值得注意的是,一个单独的动作a也可以是一个option,通常被称作 one-step option,其中:
- 对任意的状态s,都有β(s)=1
5.2 基于option的分层强化学习
分层强化学习:基于选项(option)的强化学习/论文笔记 The Option-Critic Architecture 2017 AAAI_UQI-LIUWJ的博客-CSDN博客
6 基于分层抽象机(hierarchies of abstract machines,HAMs)的分层强化学习
Reinforcement Learning with Hierarchies of Machines NIPS 1997
每个状态机都有4种类型的状态,即动作(action)、调用(call)、选择(choice)以及停止(stop)。
- action类型的状态会根据状态机的具体状态执行一个MDP中的动作(与环境进行交互)
- 在call类型的状态时,当前状态机Hi将被挂起,开始初始化下一个状态机Hj,(将另一个状态机作为子程序进行)
- 把状态机Hj的状态设置为
,
- j的值根据
得出,
- choice类型的状态则是非确定性地选择当前状态机的下一个状态。(需要学习的部分)
- stop状态则是停止当前状态机的活动,恢复调用它的状态机的活动,同时agent根据之前action类型状态选择的动作进行状态转移,并得到相应奖赏。
如果在某一个状态机中没有选择出动作,例如某个状态机Hi刚被调用就被随机函数fi初始化到了一个stop状态,以至于返回时并没有选出要执行的动作,则环境保持当前的状态(agent不进行任何动作)。
具体的学习算法也是Q-learning,不同的是将环境状态和状态机状态二者结合,作为新的状态空间,来学习使用当前状态机的哪种做法可以获得更好的reward。
· 只有当状态机的状态是choice类型的状态时,HAM才需要进行决策,其他状态下都可以根据状态机的状态自动进行状态转移,所以实际上HAM是个SMDP。
我们记此时环境的状态为Sc,状态机的状态为Mc,需要进行的动作为ac(状态机在choice类型状态出需要选择哪个状态作为后续状态)【c表示HAM中需要做出选择的状态的下标】,于是我们需要维护的Q函数为:
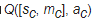
于是此时Q-learning的更新公式为(τ为这一个状态机经过的action类型的数量【动作步数】)

在马尔可夫决策过程中,每个状态处都需要进行动作的学习,即学习直接发生在 MDP 中。而在 HAM 框架中,学习只发生在选择状态。因此,学习存在的状态空间可以小于实际状态空间。
在上述示例中,每次遇到障碍物时,机器进入选择状态,其中要么选择跟随墙壁机器(沿着某个方向持续地跟随墙),要么选择退避机器(向后移动)。
因此,学习机器的策略是决定choice状态后要选择哪个状态,以及以什么概率选择。

这种方法的局限就是需要人工设计状态机,而这需要大量的先验领域知识,导致状态机设计十分复杂困难,在面对复杂问题时更是如此。
简言之,可以将一个状态机理解成一个option,一个状态机执行完之后,其先后经过的action状态拼起来,就是这个option过程中总共执行的action,然后根据action对environment进行环境状态的转移。
然后怎么确定状态机中状态的转移方向呢?一部分是确定的,一部分需要通过Q-learning 学习得到。
7 基于MaxQ值函数分解的分层强化学习
首先将一个马尔可夫决策过程M分解成多个子任务{M0, M1, …, Mn},M0为根子任务,解决了M0就意味着解决了原问题M。
对于每一个子任务Mi,都有一个终止断言(termination predicate) Ti和一个动作集合Ai。这个动作集合中的元素既可以是其他的子任务,也可以是一个MDP中的action。
一个子任务的目标是转移到一个状态,可以满足终止断言,使得此子任务完成并终止。
我们需要学到一个高层次的策略π={π0, …, πn},其中πi为子任务Mi的策略。(换言之,我们此时每一步的action,可以是原来MDP的一个action,也可以是解决一个子问题的一连串action)
令Q(i, s, j)为子任务i在状态s执行动作j之后按照某个策略执行直到达到终止状态的期望累计奖赏,可以表示为
假设在子任务i中,我们一共执行了τ步,才满足终止断言,那么我们可以将Q函数改写成:
右边的第1项实际上是V(j s)【在子任务中,状态s执行动作j的累计奖励】
后一项我们称之为完成函数completion function,C(i, s, j)。记后续父任务的总期望奖励

所以,我们有:Q(i,s,j)=V(j,s)+C(i,s,j)
对于C函数,我们同一样可以写出他的更新方程
(上述公式出自分层强化学习综述 (rhhz.net)
但个人觉得第二行应该是V(a',s),欢迎评论区批评指正!)

MaxQ问题的瓶颈也是很明显的:就是子任务需要人为去划分
7.1 举例:出租车问题
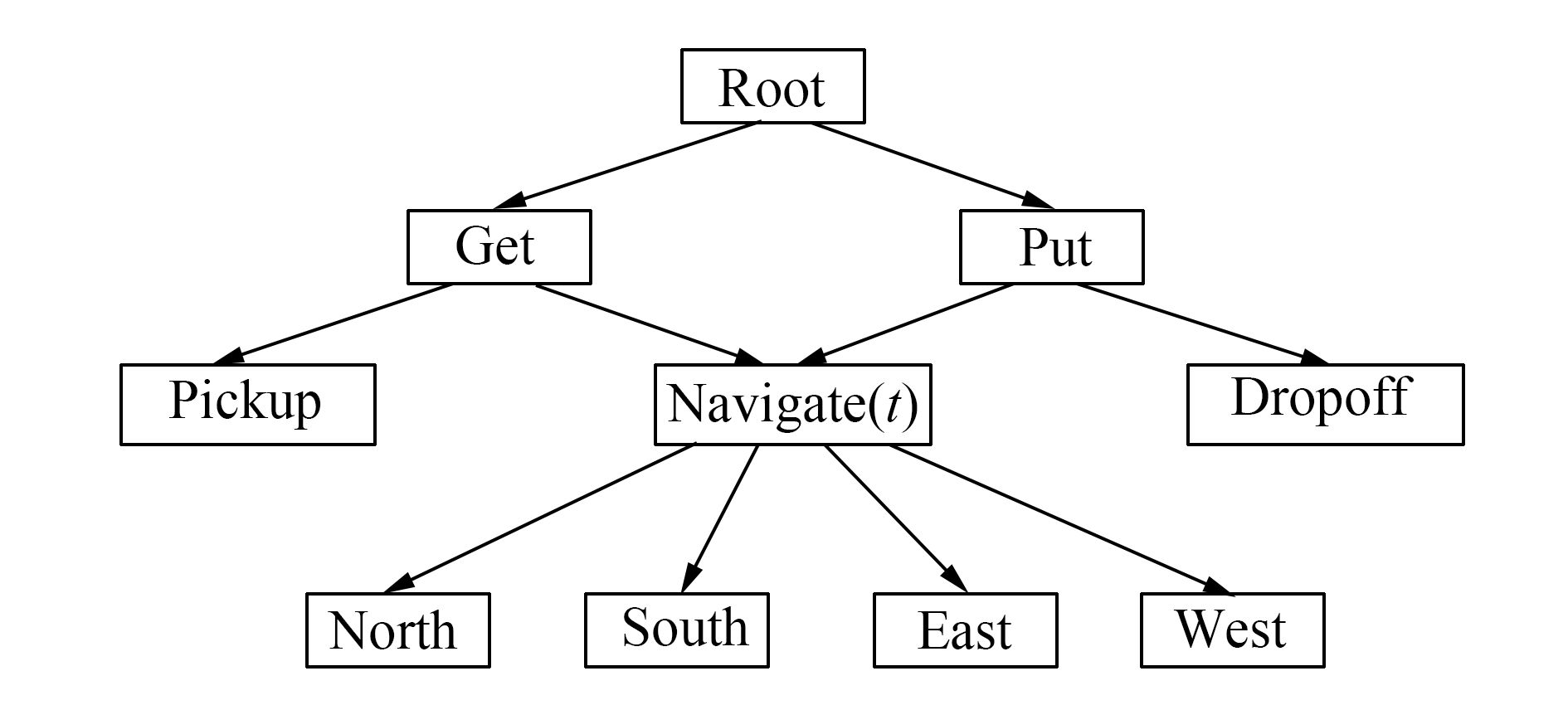
出租车问题是指一个出租车agent需要到特定位置接一位乘客并且把他送到特定的位置让其下车。一共有6个动作,分别是上车(pick up)、下车(drop off),以及向东南西北四个方向开车的动作。
这里使用MaxQ方法,将原问题分解成了get和put两个子任务。(root任务,他的策略只是什么时候应该get,什么时候应该put,至于get和put里面是怎么搞的,root不管)
这两个子任务又进行分解,get分解成一个基本动作pick up和一个子任务navigate,而put也分解成了一个基本动作drop off和一个子任务navigate。子任务navigate(t)表示t时刻应该开车的方向。(同样地,get子任务的策略只是什么时候pickup,什么时候navigate;put子任务的策略只是什么时候pickup,什么时候navigate)
对于这个强化学习问题,agent首先选择get,然后get子问题navigate,直到到达乘客所在地,然后get选择pick up动作,乘客上车。之后agent选择put子任务,put子任务选择navigate,直到到达乘客目的地,之后put子任务选择drop off动作,乘客下车,任务完成。
8分类
近几年的分层强化学习,大体上可以分成两类
- 上层策略(manager)选择让哪一个下层策略(worker)来执行策略
- 上册策略(manager)指定一个目标,下层策略(worker)执行这个目标
参考内容
















 485
485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











