







随着 DeepSeek-R1 模型在全球范围内的流行,越来越多的用户开始在本地尝试部署该模型。然而,高昂的硬件需求和成本让许多公司望而却步。本文将深入探讨 DeepSeek-R1 部署中的挑战,并介绍一款创新框架 KTransformers,它能够显著降低大规模模型部署的成本并提高推理效率,从而帮助更多中小企业有效部署此类高级AI模型。本地部署“成本骤降32倍”,助力R1真正落地「中小企业」中!
1. DeepSeek-R1 部署痛点分析
近年来,DeepSeek-R1 在AI界掀起了一股部署热潮,尤其是对于需要强大推理能力的大型企业来说,部署高性能版本的 DeepSeek-R1 逐渐成为趋势。然而,由于模型庞大且需求计算资源巨大,DeepSeek-R1 在本地部署时面临着如下挑战:
-
硬件需求巨大:部署一个完整版本的 DeepSeek-R1 需要 16张 A800 GPU,其硬件成本高达 200百万人民币,这一成本让大多数中小企业望而却步。
-
小模型性能差异:许多用户表示,70B及以下的小模型虽然能够提供一定性能,但与完整的 DeepSeek-R1 相比,其性能差距较大,且微调这些模型的成本也同样较高。
-
需求低成本解决方案:产业界对 671B 大模型的需求强烈,但许多企业和开发者都希望能够以较低的成本实现 DeepSeek-R1 的部署。
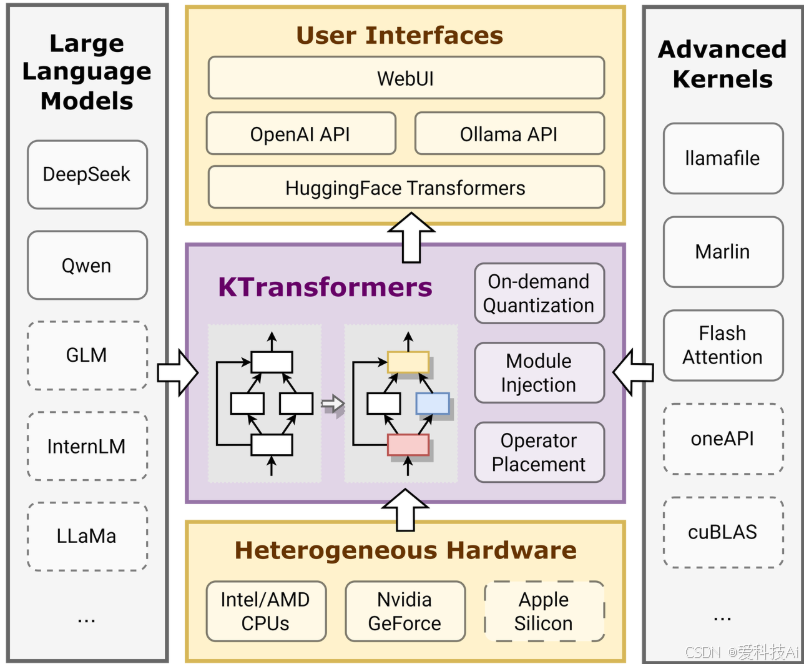
2. KTransformers 框架介绍
为了解决上述痛点,KTransformers 框架应运而生。KTransformers 是一个灵活、以 Python 为中心的框架,旨在通过高级内核优化和并行处理来提升 Transformers 模型的性能,支持 DeepSeek-R1 和 DeepSeek-V3 等大规模模型的高效部署。其核心优势包括:
- 可扩展性:通过简化的接口和优化模块,用户可以轻松集成到现有的 Transformers 环境中,支持与 OpenAI 和 Ollama 兼容的 RESTful API。
- 易于部署:支持单台 24GB VRAM / 多 GPU 和 382GB DRAM 的部署,优化了硬件资源的使用效率。
- Web UI 支持:框架提供了简化的 Web UI,类似于 ChatGPT,使得用户可以便捷地进行交互式部署和测试。
3. KTransformers 框架的关键里程碑
KTransformers 取得了以下显著进展,提升了大规模模型的部署能力:
-
2025年2月10日:支持单台 24GB VRAM / 多 GPU 和 382GB DRAM 上运行 DeepSeek-R1 和 DeepSeek-V3,推理速度提升 3~28倍。
-
2024年8月28日:在 InternLM2.5-7B-Chat-1M 模型下,支持 1M 上下文,使用 24GB VRAM 和 150GB DRAM。
-
2024年8月28日:将 DeepSeekV2 的 VRAM 需求从 21GB 降低至 11GB。
-
2024年8月9日:支持 Windows 原生操作系统。
4. KTransformers 框架的硬件配置
本地671B DeepSeek-Coder-V3/R1:KTransformers 框架在以下硬件配置下提供最佳性能:
- CPU型号:Intel Xeon Gold 6454S,1TB DRAM(2 NUMA 节点)
- GPU型号:RTX 4090,24GB VRAM
- 内存:DDR5-4800 Server DRAM,1TB
- 模型:DeepSeekV3-q4km(int4)
这个硬件配置的成本仅需6-7万,却能支撑DeepSeek满血模型。
5. KTransformers 框架性能指标
本地671B DeepSeek-Coder-V3/R1:仅使用14GB VRAM和382GB DRAM运行其Q4_K_M版本。
预填充速度(令牌/秒):KTransformr:54.21(32核)→74.362(双插槽,2×32核)>255.26(基于AMX的优化MoE内核,仅V0.3)→ 286.55 (有选择地使用6位专家,仅V0.3)与2×32核的llama.cpp中的10.31个令牌/秒相比,速度提高了27.79倍。
解码速度(令牌/秒):KTransformr:8.73(32个内核)→11.26(双插槽,2×32核)→13.69(选择性使用6个专家,仅V0.3)与2×32内核的llama.cpp中的4.51令牌/秒相比,速度提高了3.03倍。
除此之外,作者还提供了即将推出的优化预览,包括英特尔AMX加速内核和选择性专家激活方法,这将显著提高性能。使用V0.3-preview,作者实现了高达286个令牌/秒的预填充,使其比llama.cpp的局部推理快28倍。具体的wheel文件-。
6. KTransformers 上手指南
部署 KTransformers 非常简便,用户只需几个步骤即可开始:
-
下载 .whl 文件: 使用
wget命令下载 KTransformers 的.whl文件。wget https://github.com/kvcache-ai/ktransformers/releases/download/v0.1.4/ktransformers-0.3.0rc0+cu126torch26fancy-cp311-cp311-linux_x86_64.whl -
安装 .whl 文件: 使用
pip安装下载的文件。pip install ktransformers-0.3.0rc0+cu126torch26fancy-cp311-cp311-linux_x86_64.whl -
执行推理: 启动推理,指定模型路径、gguf路径和提示文件。
python -m ktransformers.local_chat --model_path <your model path> --gguf_path <your gguf path> --prompt_file <your prompt txt file> --cpu_infer 65 --max_new_tokens 1000
更多细节请参考 DeepseekR1_V3 教程。
7. KTransformers 优化细节
KTransformers 采用了多种优化策略,确保高效使用硬件资源:
-
MoE架构的稀疏性: 使用 MoE(混合专家)架构,通过动态选择性激活专家模块,降低计算复杂度,提升计算资源的利用率。基于这一策略,模型只激活部分专家,减少显存需求。
-
高效的 CPU 与 GPU 算子: 使用 Marlin算子 充分利用 GPU 性能,提供 3.87倍 的加速。并且通过 llamafile 实现 CPU 算子的推理,结合专家模块等技术进一步优化推理速度。
-
基于计算强度的 offload 策略: 通过计算强度动态划分计算任务,将计算强度较高的部分放在 GPU 中进行处理,从而优化 GPU 利用率。
-
优化 CUDA Graph: 为了减少 Python 接口调用的开销,KTransformers 将 CPU 算子交叉式放入 CUDA 图中,优化 GPU 与 CPU 之间的通信,进一步提升推理效率。
项目主页-https://github.com/kvcache-ai/ktransformers/tree/main
代码链接-https://github.com/kvcache-ai/ktransformers/tree/main

















 1882
1882

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









