






1 模仿学习的两种方法:
为了达到模仿学习的目的,目前主要有2种方法,一是Behavior cloning,即行为克隆方法;二是Inverse Reinforcement Learning(IRL),即逆向强化学习方法。
2 Behavior Cloning
2.1 算法步骤
把训练数据分成训练集合与验证集合,然后再把训练集合的误差最小化,训练到验证集合的误差一直不收敛为止。接下来将训练好的神经网络在环境中测试。首先从环境中取得当前时刻状态state,利用训练好的神经网络决定相对应的动作action,然后作用于环境,这样子一直重复到游戏结束,看训练效果。
2.2 算法特性
(1)算法的优点是实际操作简单。算法训练是很有效率的,但是缺点是当训练数据少的时候,无法训练出完整的策略分布。
(2)机器唯一做的事情是复制expert所有的行为,他并不知道哪些行为是重要的,是对接下来情况会产生影响,哪些行为不重要,对接下来的事情没有影响。
3 Inverse Reinforcement Learning
3.1 算法思路
算法思路是,从数据里面还原出专家当时学出策略的reward函数,根据某一个reward函数来学到一个最优的策略。即,在强化学习中,我们给定环境(状态转移)和奖励函数,我们需要通过收集的数据来对自身的策略函数和值函数进行优化。在逆强化学习中,提供环境(状态转移),也提供策略函数或是示教数据,我们希望从这些数据中反推奖励函数。即给定状态和动作,建立模型输出对应奖励。在奖励函数建立好后,我们就能新训练一个智能体来模仿给定策略(示教数据)的行为。
3.2 算法步骤
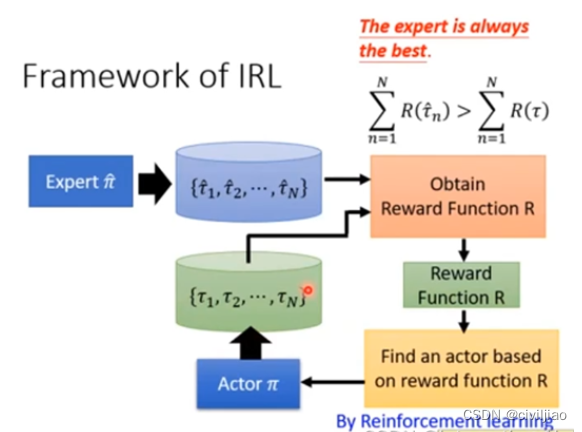
逆强化学习(Inverse Reinforcement Learning,IRL)是一种用于从专家示范中学习任务的回报函数的机器学习技术。这个技术通常用于确定任务中的隐含回报函数,以便智能代理可以在没有显式奖励信号的情况下执行任务。以下是逆强化学习的一般算法步骤:
- 问题建模:首先,您需要定义问题并明确您希望智能代理执行的任务。这通常包括定义状态空间、动作空间以及与任务相关的其他要素。
- 数据收集:您需要从一个或多个专家示范者那里收集示范数据,这些数据包括专家在执行任务时的状态-动作轨迹。
- 特征提取:将示范数据中的状态和动作序列转化为有意义的特征表示。这通常涉及到将原始状态信息转化为更有用的表示,以便后续学习算法能够处理。
- 定义奖励函数:IRL的目标是学习一个奖励函数,该函数可以解释示范数据中的专家行为。奖励函数通常表示为一个权重向量,它线性组合了特征。这个过程通常涉及到求解奖励函数的权重。
- 逆强化学习算法:选择适当的逆强化学习算法,例如最大熵IRL、线性规划IRL、或GAN-based IRL等。这些算法用于学习奖励函数的权重,以便智能代理能够在模型中优化该奖励函数。
- 生成新策略:使用学到的奖励函数,智能代理可以在学习过程中生成新策略,以最大化奖励函数。这通常涉及到使用强化学习算法,例如强化学习中的策略迭代或价值迭代方法。
- 评估学习的策略:评估学到的策略,通常使用模拟或实际环境中的实验。这有助于确定学到的策略在执行任务时的性能。
- 微调和改进:根据评估结果,可以进行策略的微调和改进,以获得更好的性能。
需要注意的是,逆强化学习是一个复杂的领域,不同的算法和技术可以用于不同的任务和问题。此外,一些IRL方法可能涉及迭代过程,因此可以多次执行上述步骤以改进性能。
3.3 IRL典型算法Generative Adversarial Imitation Learning(GAIL)
3.3.1 介绍
在IRL领域有名的算法是GAIL,这种算法模仿了生成对抗网络GANs。把Actor当成Generator,把Reward Funciton当成Discriminator。我们要训练一个策略网络去尽量拟合提供的示教数据,那么我们可以让需要训练的reward函数来进行评价,Reward函数通过输出评分来分辨哪个是示教数据的轨迹,哪个是自己生成的虚假轨迹;而策略网络负责生成虚假的轨迹,尽可能骗过Reward函数,让其难辨真假。两者是对抗关系,双方的Loss函数是对立的,两者在相互对抗中一起成长,最后训练出一个较好的reward函数和一个较好的策略网络。
在这个框架里面,它的整个学习的过程和GAN的框架的学习过程,比如说我们一步步来学习Discriminator,来把专家的样本和我们策略跑出来的样本,要尽可能把它分开。第二步就是以discriminator给出来的分值,我们把它当成是reward,把他交给强化学习去最大化reward。所以不断的进行学习以后,我们强化学习生成出来的数据,最后会比较接近于专家的数据,这个就是最基本的生成对抗的模仿学习的方法,那么刚才提到的一样,GAN之前的一些不足的地方,GAIL 框架也把它继承了过来,所以后面也会对于GAIL提出了各种各样的一个变形,一些改进。包括WGAIL,就是说我们这里用的是JS散度,为这边的度量来做一些改进,这个都是有一系列的改进的方法就诞生了
接着具体介绍一下对抗生成模仿学习,它主要是利用discriminator神经网络当作奖励函数给agent学习的方向。在学习神经网络过程中,我们需要最大化专家给予的标准动作奖励,并且最小化agent输出的动作的奖励值。
3.3.2 GAIL算法步骤
GAIL(Generative Adversarial Imitation Learning)是一种用于模仿学习的深度强化学习算法,它使用生成对抗网络(GAN)的思想来训练智能代理以从专家示范中学习任务。以下是GAIL算法的一般步骤:
- 问题建模:首先,您需要明确定义问题,包括任务、状态空间、动作空间和其他相关要素。
- 专家示范数据收集:从一个或多个专家示范者那里收集示范数据,包括专家在执行任务时的状态-动作轨迹。
- 特征提取:将示范数据中的状态和动作序列转化为有意义的特征表示。这通常包括将原始状态信息转化为适合深度学习模型的表示。
- 构建GAN:GAIL使用生成对抗网络 (GAN) 结构来训练智能代理。GAN由两个神经网络组成:生成器和判别器。
- 生成器:生成器接受状态作为输入,试图生成与专家示范数据相似的状态-动作对。它的目标是生成能够欺骗判别器的样本。
- 判别器:判别器接受专家示范数据和生成器生成的数据,它的任务是区分哪些数据来自专家,哪些来自生成器。
- 训练GAN:训练GAN以使生成器生成越来越接近专家示范数据的状态-动作对,同时使判别器难以区分生成器的输出和专家示范数据。这通常涉及到最小化GAN的损失函数。
- 策略提取:一旦GAN训练完成,可以使用生成器的输出作为学到的策略。这意味着智能代理可以使用生成器生成的动作来执行任务。
- 策略评估:评估学到的策略,通常在模拟环境或真实环境中进行实验。这有助于确定学到的策略在执行任务时的性能。
- 微调和改进:根据评估结果,可以进行策略的微调和改进,以获得更好的性能。
GAIL是一种强大的算法,它允许智能代理从专家示范中学习任务,并且不需要显式的奖励信号。然而,训练GAN和调整参数通常需要一些经验和仔细的实验,以确保算法的成功应用。
4 推荐的资料
模仿学习 :http://www.lamda.nju.edu.cn/xut/Imitation_Learning.pdf
这个是南大和港中文大学教授编写的一份材料,个人觉得深入浅出,非常适合用来学习。关键不仅介绍了模仿学习,而且也讲述了在offline RL中如何用模仿学习学习环境的方法。
主要参考文章:















 6052
6052











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









