







强化学习
强化学习需要一个合适的reward函数去求解最优行动策略,但很多情况下不容易设以一个足够全面和优秀的reward函数,特别是在一些复杂的应用场景中,例如自动驾驶中撞人、撞车和闯红绿灯三者的reward值很难有一个合理的比例和设定,当面对的周围环境更加复杂就更难去定量。
模仿学习
模仿学习希望机器能够通过观察并模仿专家的行为策略进行学习,不需要提前设计好任务的reward函数,专家的行为策略相当于引入了带标签的数据,转化为了有监督学习。
模仿学习的三种方法
行为克隆
如下图所示,专家做什么,机器跟着做,通过离散的数据学习离散的分布,专家的行为轨迹给定的数据集有限,只能通过不断增加训练集去覆盖所有可能发生的状态来保证学习的效果,但一般都不能获得足够完整的数据集,特别是有些数据集中可能存在的危险状态在实际中的采集成本非常高,比如无人驾驶在雨天的山路、热闹的市场等危险地带的数据采集。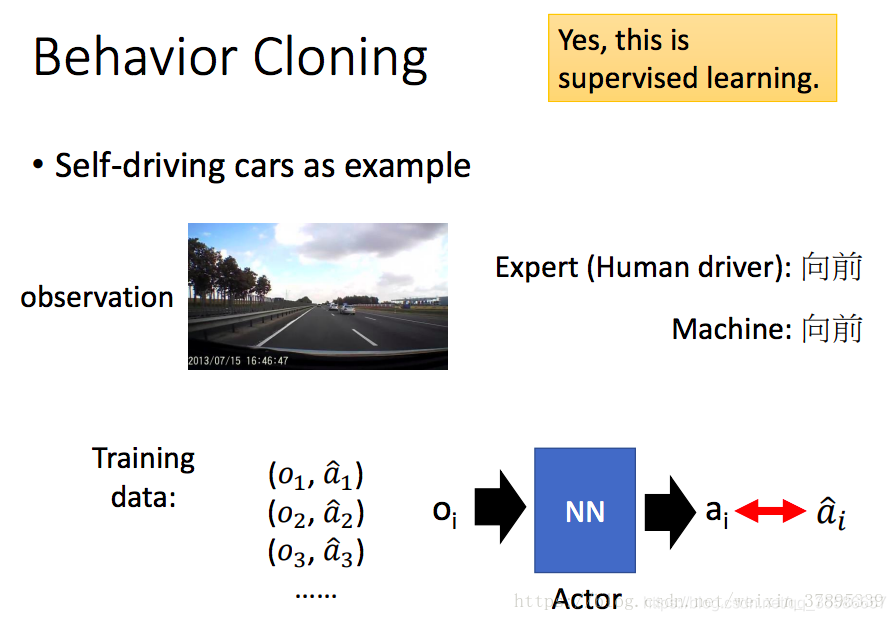
逆向强化学习
假设专家的策略是完美的,即最优reward函数下的最优解。逆向强化学习希望通过学习得到一个reward函数去解释专家的行为,在这个过程中,不断对当前得到的reward函数进行优化,最终从专家的行为中反推出一个最合理的结果。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









