







 本文对比了传统Socket通信与RDMA(Remote Direct Memory Access)的区别。传统Socket通信因CPU占用高、数据传输过程复杂而限制了性能。而RDMA通过网络直接在两端点应用间传递buffer,实现低延时、高吞吐且几乎不占用CPU资源的通信。RDMA的三大特性包括CPU offload、kernel bypass和zero-copy,简化了应用间的直接通信,降低了网络数据处理的成本。
本文对比了传统Socket通信与RDMA(Remote Direct Memory Access)的区别。传统Socket通信因CPU占用高、数据传输过程复杂而限制了性能。而RDMA通过网络直接在两端点应用间传递buffer,实现低延时、高吞吐且几乎不占用CPU资源的通信。RDMA的三大特性包括CPU offload、kernel bypass和zero-copy,简化了应用间的直接通信,降低了网络数据处理的成本。
传统网络通信(Socket)
在本地可以通过进程PID来唯一标识一个进程,但是在网络中这是行不通的。其实TCP/IP协议族已经帮我们解决了这个问题,网络层的“ip地址”可以唯一标识网络中的主机,而传输层的“协议+端口”可以唯一标识主机中的应用程序(进程)。这样利用三元组(ip地址,协议,端口)就可以标识网络的进程了,网络中的进程通信就可以利用这个标志与其它进程进行交互。
使用TCP/IP协议的应用程序通常采用应用编程接口:UNIX BSD的套接字(socket),来实现网络进程之间的通信。就目前而言,几乎所有的应用程序都是采用socket。无论编写客户端程序还是服务端程序,系统都要为每个TCP连接都要创建一个socket句柄。这样导致了每次传输通信,都要经过OS和协议栈的管理,因此不管是Socket同步通信还是异步通信,都会存在CPU占用过高的现象。
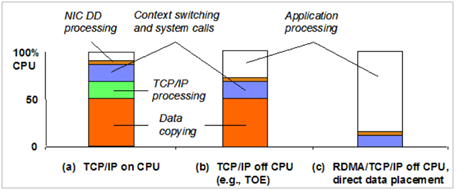
传统网络通信过程如下:发送端首先按照TCP/IP协议包装数据,将要发送的数据包缓存到网卡上等待传输。传输完成后,先把收到的数据包缓存到系统上,数据包经过处理后,相应数据被分配到一个TCP 连接。然后接收系统再把主动提供的TCP 数据同相应的应用程序联系起来,并将数据从系统缓冲区拷贝到目标存储地址。这样,制约网络速率的因素就出现了:应用通信强度不断增加和主机CPU 在内核与应用存储器间处理数据的任务繁重使系统要不断追加主机CPU 资源,配置高效的软件并增强系统负荷管理。所以想要提升性
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 203
203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









