







工作简介
最近有关知识图谱补全的工作都集中在使用图神经网络来学习实体、关系的嵌入。
基于 GNN 的模型带来的改进归因于增强的信息聚合过程。因此目前关于为 KGs 开发更好的 GNN 的研究仍然主要集中在推进信息聚合过程。
作者发现:基于 GNN 的模型中的信息聚合过程并不是所报告的KGC性能改进的最关键原因。
具体来说,作者用简单的多层感知器(MLPs)替换了几个最先进的以 KGC 为重点的GNN模型中的信息聚合过程,并在各种数据集和实现中实现了与其相应的基于 GNN 的模型相当的性能。
结果表明,评分和损失函数确实有更强的影响,而信息聚合过程几乎没有贡献。
与基于GNN的模型相比,基于MLP的方法在训练和推理过程中具有更高效的优势,因为它们不涉及昂贵的聚合操作。
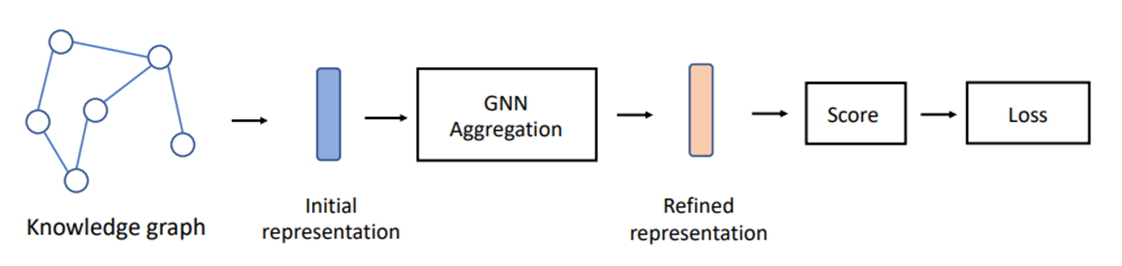
相关工作 – KGC中的聚合过程与评分函数
本文研究了三种具有代表性的基于 GNN 的 KGC 模型,即 CompGCN[1]、RGCN[2]和 KBGAT[3]。
与传统 GNN 模型一样,这些模型堆叠多层以迭代地聚合整个 KG 中的信息。每个中间层将前一层的输出作为输入,最后一层的最终输出作为学习到的嵌入。除了实体嵌入,一些基于 GNN 的模型也学习关系嵌入。
RGCN 用特定关系的转换矩阵聚合邻域信息。
CompGCN 定义了基于方向的变换矩阵,并引入关系嵌入来聚合邻域信息。引入组合算子来组合嵌入以利用实体-关系信息。
KBGAT 通过同时考虑实体嵌入和关系嵌入,提出了基于注意力的聚合过程。
从GNN聚合层获得最终的嵌入后,相应的实体关系嵌入被用作评分函数的输入。可以采用各种评分函数。
两种广泛使用的评分函数是 DistMult[4] 和 ConvE[5]。
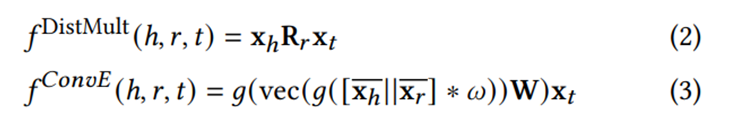
𝑓DistMultf_"DistMult" 中的Rr是关系R的对角阵。
ConvE将头嵌入与关系嵌入馈送到卷积层中,然后他们被重塑回一个向量,该向量用尾部嵌入来生成一个分数。
相关工作 – KGC中的损失函数
为了训练GNN模型,KGC任务通常被认为是一个二分类任务。损失函数使用二进制交叉熵(Binary cross-entropy, BCE)。
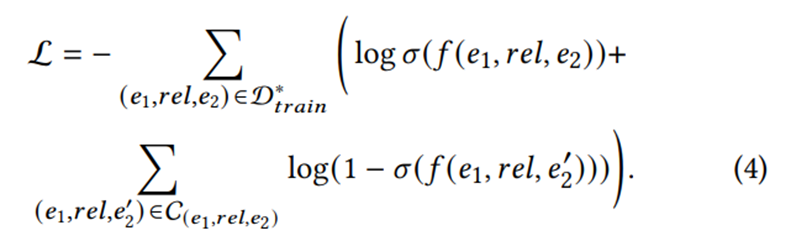
RGCN、 CompGCN和KBGAT之间在三个主要组件方面的主要差异如下:
1.聚合。它们的信息聚合过程是不同的。
2.得分函数。他们采用不同的评分功能。RGCN采用DistMult评分函数,而CompGCN、KBGAT采用ConvE取得了最好的性能。
3.损失函数。CompGCN利用KG中的所有实体作为负样本进行训练,而RGCN采用负采样策略,仅选择一部分实体作为真负样本进行训练。对于KBGAT,我们也利用所有实体来构造负样本,类似于CompGCN。
实验-聚合真的对KGC有帮助吗
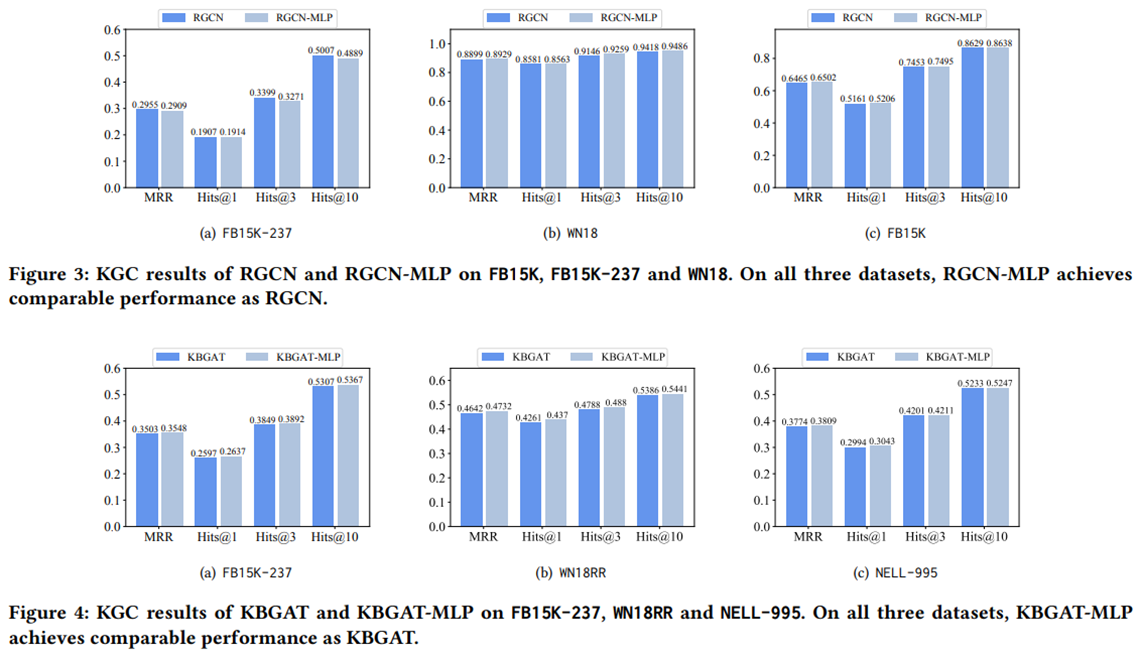
实验一:保持其他组件不动,用一个简单的MLP替换它们的聚合组件(?),该MLP与相应的基于GCN的模型具有相同的层数和隐藏维度。
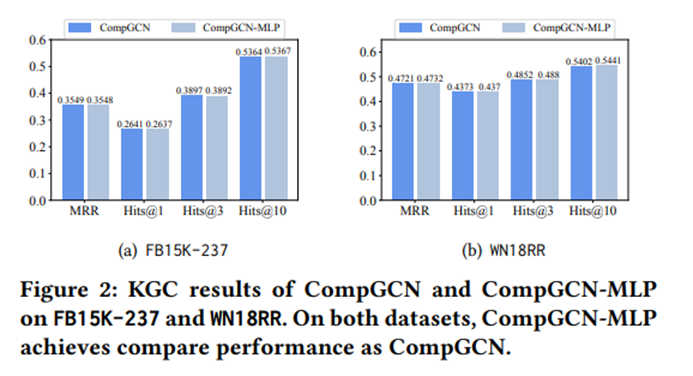
实验-评分函数的影响
实验二:在原始设置中,CompGCN和KBGAT使用ConvE作为评分函数,而RGCN采用DistMult。在表1中,我们进一步展示了CompGCN和KBGAT使用DistMult和RGCN使用ConvE的结果。(不更改其他设置)
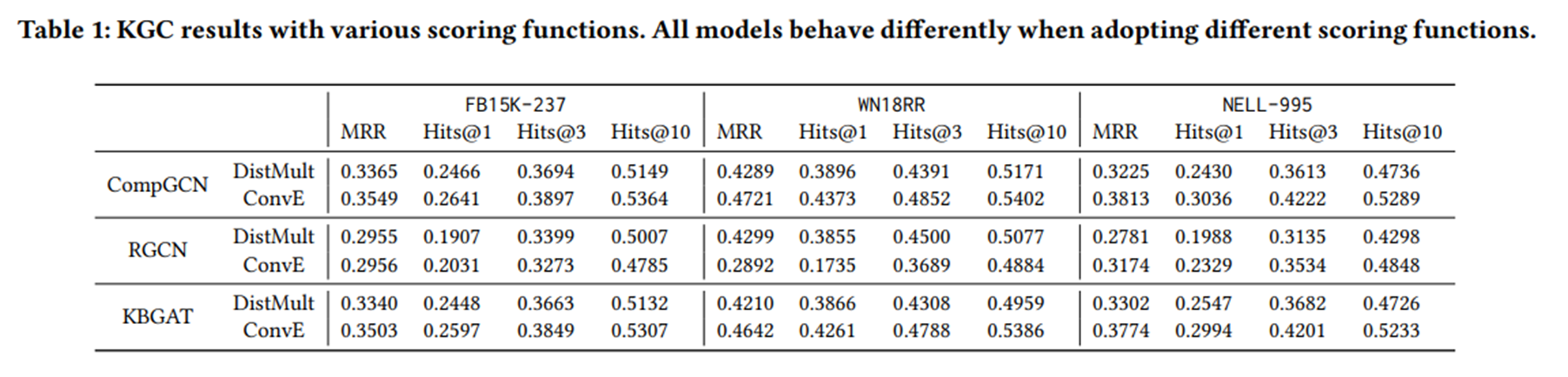
评分函数的选择对模型性能有很强的影响。此外,这种影响取决于这些方法应用到的特定数据集。
评分函数并不是影响模型性能的唯一因素。
实验-损失函数的影响
实验三:在原始设置中,CompGCN, RGCN和KBGAT采用了BCE损失。损失函数的主要区别在于,CompGCN和KBGAT利用了所有负样本,而RGCN采用了抽样策略,随机选择10个负样本进行训练。为了方便起见,我们使用w/o采样和with采样来表示这两种设置,并研究这两种设置如何影响模型性能。
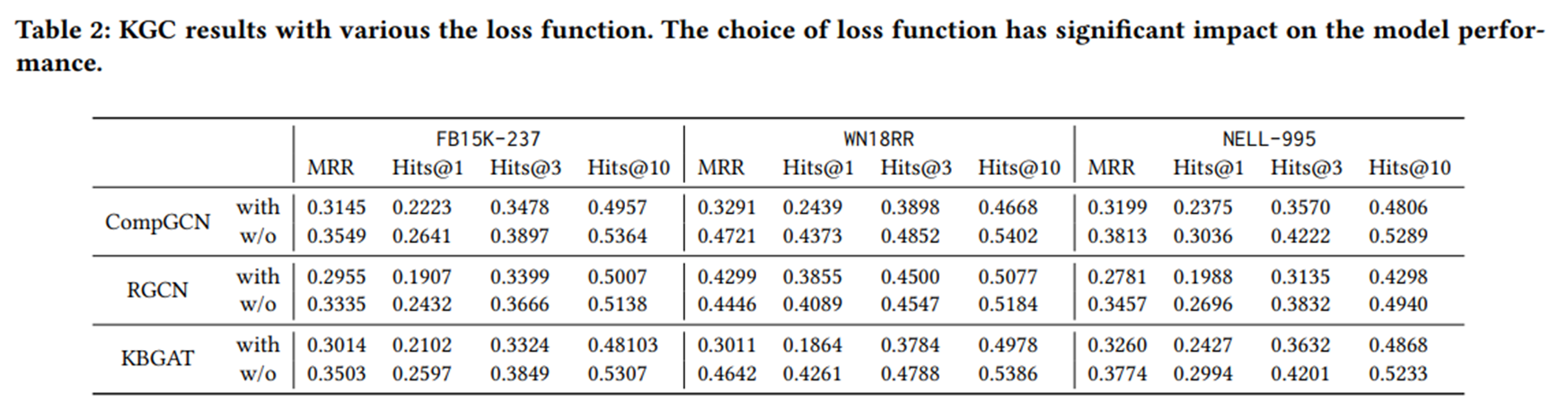
不可否认,仅使用10个负样本被证明是不够的。
实验-损失函数的影响
实验四:研究负样本数量如何影响模型性能。
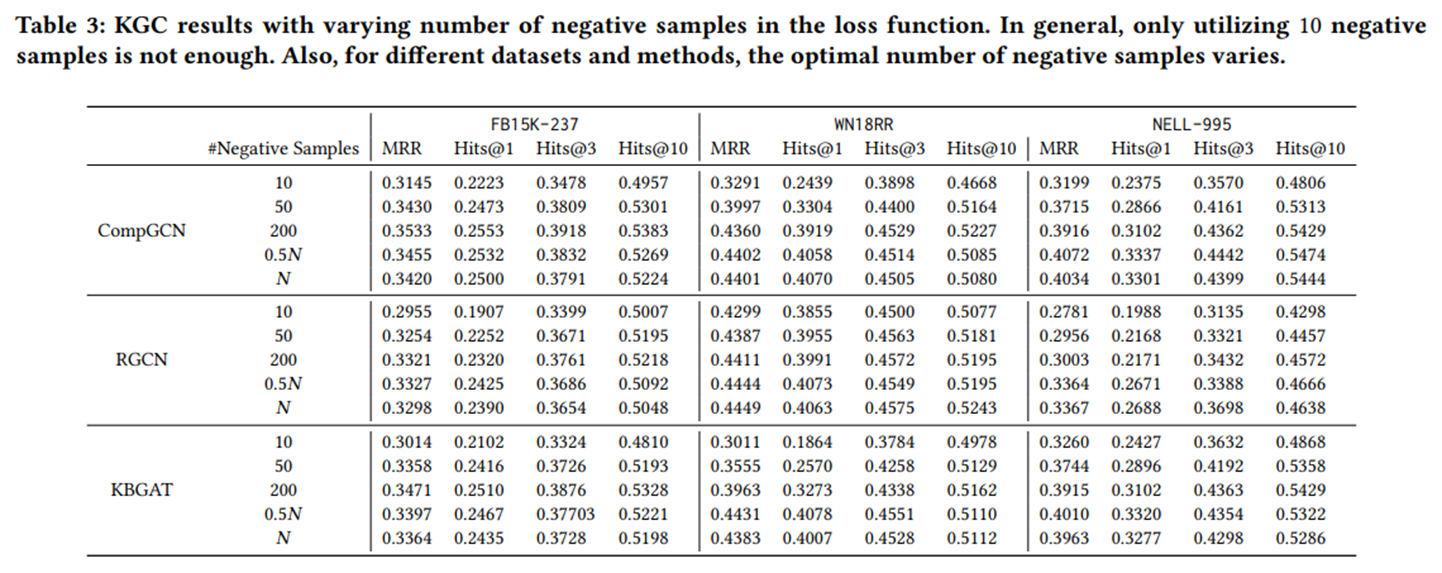
将负样本的数量从10增加到一个更大的数字,对所有方法都是有帮助的。
为了获得强大的性能,没有必要利用尽可能多的负样本。
实验- MLP-ensemble模型
实验五:研究了具有不同评分和损失函数组合的基于mlp的模型的性能。具体来说,采用DistMult和ConvE作为评分函数。对于每个评分函数,尝试了损失函数的with采样和w/o采样设置。
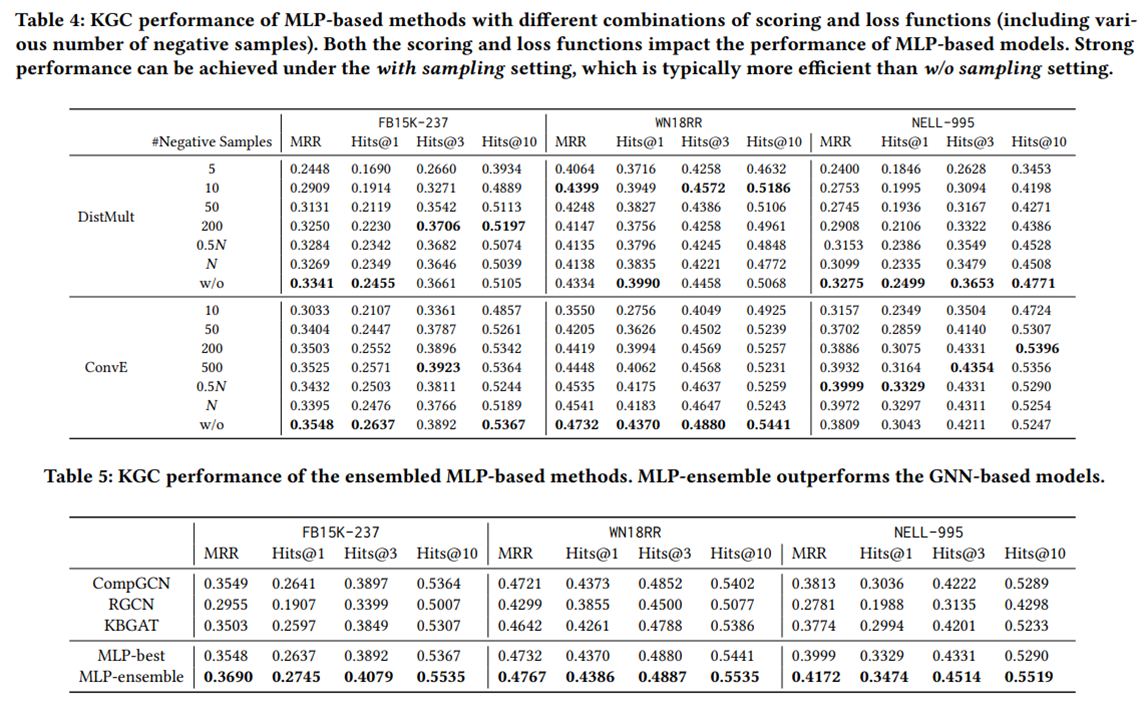
结果:
1.聚合组件对于KGC来说可能是不 必要的。基于mlp的模型可以达到与GNN模型相当甚至更强的性能。
2.评分和损失函数在基于mlp的方法的KGC性能中发挥着至关重要的作用。同时,它们的影响因数据而异。
3.表中的MLP-best表示表4中基于mlp的单个方法的最佳性能。从表中,可以清楚地观察到,MLP-best可以取得与基于GNN的方法相当甚至略好的性能。此外MLP-ensemble可以获得比基于MLP的最佳个体方法和基于GNN的模型更好的性能。这表明,这些评分和损失函数是潜在互补的,因此,即使是简单的集成方法也可以产生更好的性能。
引用:
[1] Vashishth S, Sanyal S, Nitin V, et al. Composition-based multi-relational graph convolutional networks[J]. arXiv preprint arXiv:1911.03082, 2019.
[2] Schlichtkrull M, Kipf T N, Bloem P, et al. Modeling relational data with graph convolutional networks[C]//The Semantic Web: 15th International Conference, ESWC 2018, Heraklion, Crete, Greece, June 3–7, 2018, Proceedings 15. Springer International Publishing, 2018: 593-607.
[3] Nathani D, Chauhan J, Sharma C, et al. Learning attention-based embeddings for relation prediction in knowledge graphs[J]. arXiv preprint arXiv:1906.01195, 2019.
[4]Yang B, Yih W, He X, et al. Embedding entities and relations for learning and inference in knowledge bases[J]. arXiv preprint arXiv:1412.6575, 2014.
[5] Dettmers T, Minervini P, Stenetorp P, et al.Convolutional 2d knowledge graph embeddings[C]//Pro -ceedings of the AAAI conference on artificial intelligence. 2018, 32(1).
















 1033
1033











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











