







论文快速跳转
0、 摘要
经典方法:给出kG在向量空间的表示,用预定义的打分函数补全图谱。
inductive : 归纳式,从特殊到一半,在训练的时候只用到了训练集的数据
transductive:直推式,在训练的时候用到了训练集和测试集的数据,但是不知道测试集的标签,每当有新的数据进来的时候,都需要重新进行训练。相当于是给了一些测试数据的情况下,结合已有的训练数据,看能不能推广到测试数据上。
预测的三元组可以直接在GNN的最后一层读出来,无需额外的组件活打分函数。
Attention:文中提到的意思正好与上述想法
1、引言
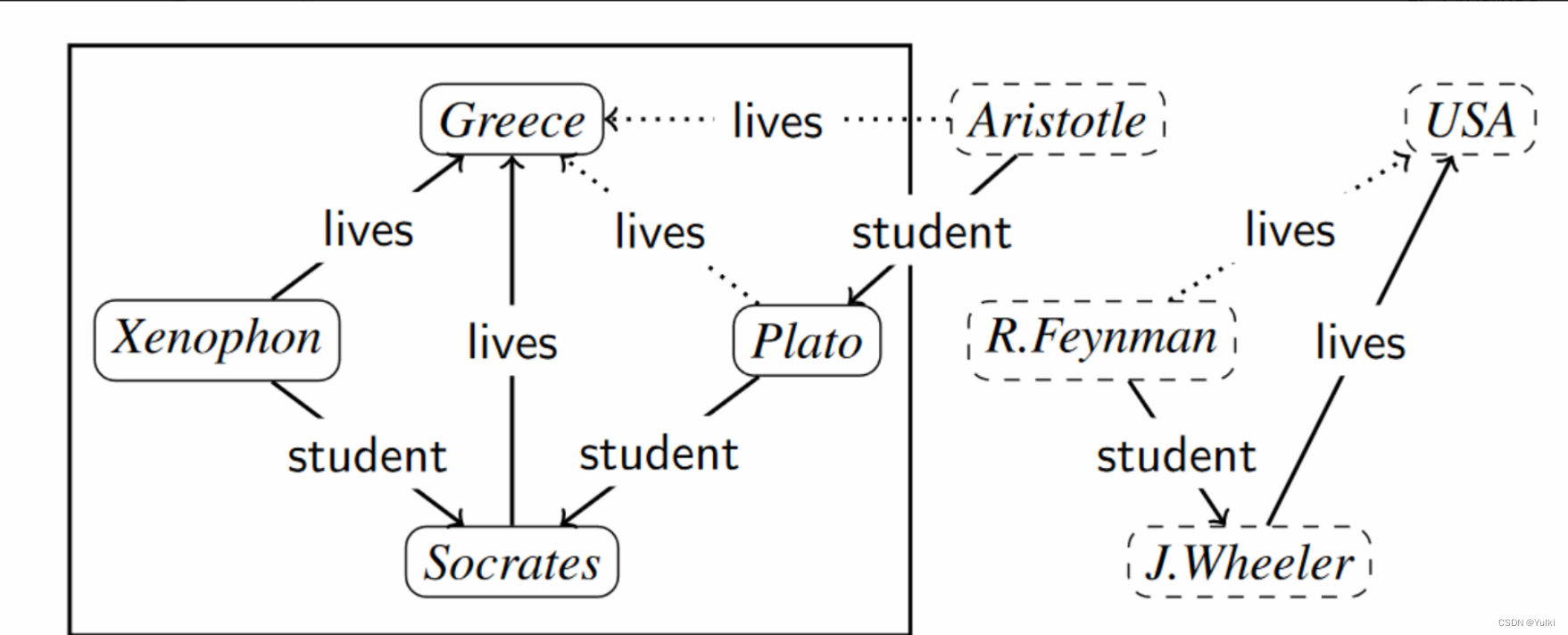
KGs常用RDF表示,KGC也叫做link prediction
常用KGC方法:TransE,DistMult,RotatE。假设缺失的三元组都被提及到了
局限性,他们不适用于inductive settings。因为缺失的三元组在训练的时候可能没看见过,
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qXHqay25-1681202461570)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/9eb38b5d-f8c6-450c-b536-5e003e4ab7cb/Untitled.png)]](https://img-blog.csdnimg.cn/0234cb8715fe48e185b9cb67b4c32925.png)
传统的方法(Transductive settings)都需要再加新图之后,重新进行训练。
已有一些inductive方法:
- Rule-based methods:但需要提起那知道规则的形状
- 利用不可见的实体的属性信息或文本描述
- 最新的方法GNN:直接适用于用特征向量注释的图。GNN倾向于图对称结构(有同样邻居的节点接收到的值应该是一样的),拥有归纳能力
GNN-based KGC 分为三个步骤
- encode阶段:把KG表示成图,节点由特征向量注释
- 图被送入GNN中
- decode阶段:预测的三元组从GNN的输出向量中解码出来
一些方法:
- R-GCN:用随机向量初始化节点的特征向量,三元组政委一个有颜色的边,GNN单独聚集有相同颜色的边,兵器设计一个针对颜色的打分函数,最外层GNN进行解码预测
缺点:R-GCN及其类似的方法对于三元组的预测只考虑这个实体周围孤立的一些邻居节点,没有考虑这些领域的公共部分
GraIL system by Teru解决了这个缺点,它采用了KG子图的方法,然后以类似R-GCN的形式进行编码。此后,应用GNN并使用全局应用于其专用子图中所有节点的输出向量的打分函数对三元组进行预测。缺陷:生成子图很浪费时间
本文
- 与现有的方法相比,我们的编码方法在GNN最内层和最外层的特征向量元素和KG签名上的三元组之间建立了一对一的对应关系,因此可以直接从最外层读出预测三元组,而不需要外部评分函数
- 一次可以预测好几个三元组,在INDIGO系统实现
2、归纳式KGC
signature:有成对的不相交的类型集(一元谓词)、关系集(二元谓词)。和常量
type实在是实体的类型
3、GNN-Based 结构的KGC
这个方法与R-GCN以及GraIL不同的地方在于编码和解码的步骤
- 一方面,已有的方法对每个节点进编码,节点的特征向量随机初始化。作为对比,本方法为图中的每一个节点编码一对常数,并且节点的初始特征向量直接捕获KG中设计的事实。
- 已有的方法利用启发式规则打分GNN的输出,本方法在最后一层直接预测。
- 本方法一次能预测一个集合的三元组
δ:注释维度 就是特征向量的维度
Types :实体的类型
Rels:关系的类型
δ = |Types| + 2 · |Rels|. 目的是将相反关系也考虑进来了
可以看到的,不依赖于实体。而是依赖于实体和关系的类型,因此一旦训练,便适用于各种实体。
3.2 Encoding kGs
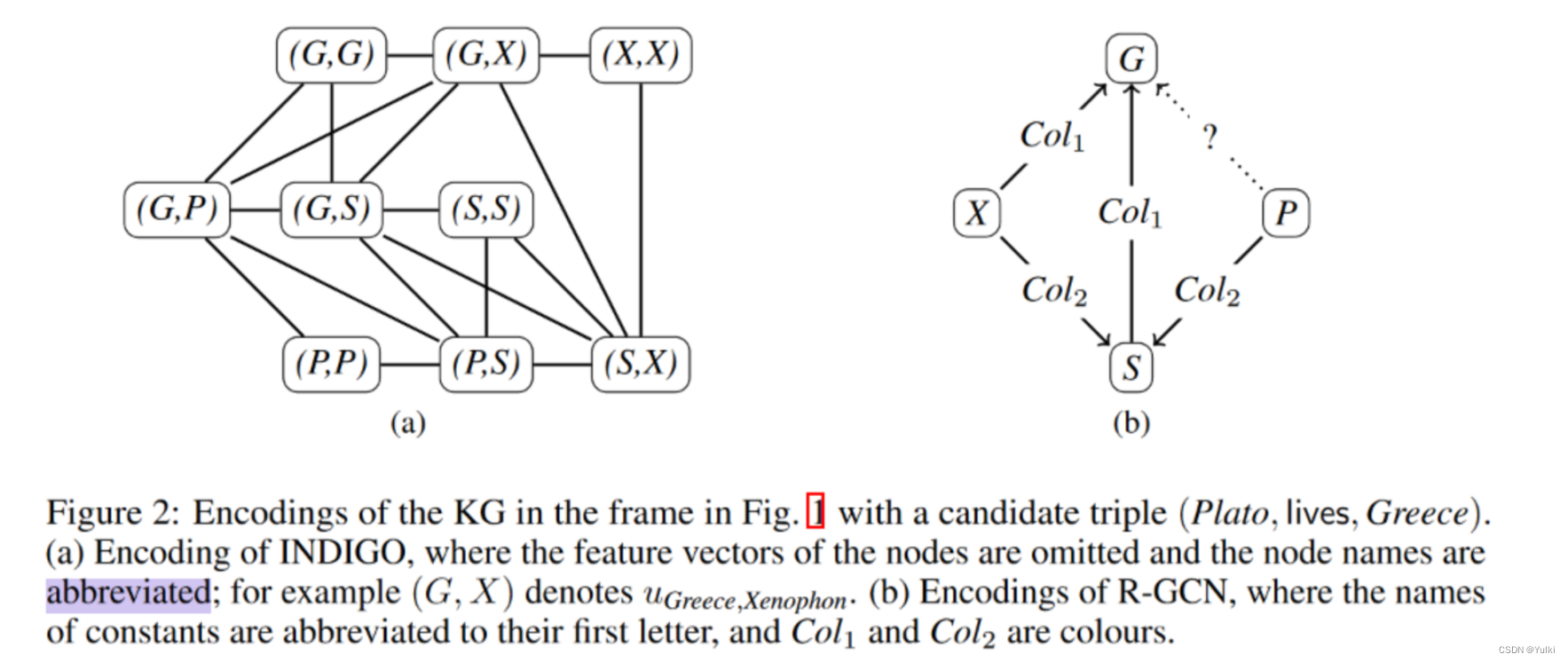
每个关系都有一个自连接的节点,这个与R-GCN差距挺大的,R-GCN跟图谱长得一样,只是针对不同类型的边进行了颜色标注,而INDGIO边的信息更多。并且R-GCN节点的特征向量都是随机初始化的,而INDGIO有一定的逻辑
3.3 The GNN Model
GNN分为aggregation阶段和combination阶段
aggregation阶段:通过邻居节点的信息更新特征向量
combination阶段:通过自身以前的特征向量与上述结果更新
最后一层的向量就是GNN的输出
‼️注意
本文不依赖于GNN的结构,本文采取的式GCN。
3.4 Decoding
3.5 Capturing Logical Rules
4、Evaluation
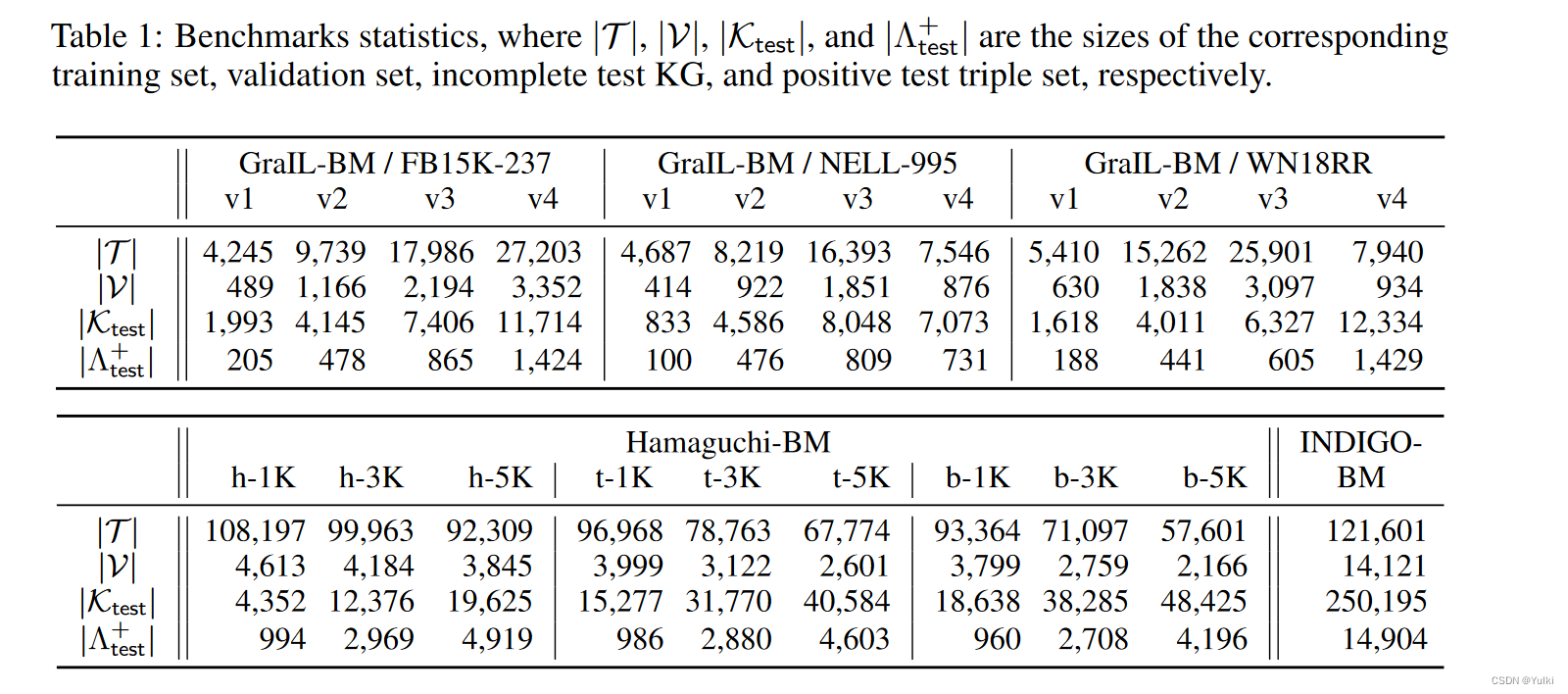
transductive KGC benchmarks:FB15K-237,NELL-995,WN18RR
每个都有四个版本
GraIL-BM / NELL-995.v3 基于NELL-995的第三个版本
- 训练集和验证集没有交集
- 测试三元组用作候选集
出现在数据集中的都为真,没出现的不知道,但假定为伪假的(等可能性为假)。原因在于开放世界已有的KGs的不完全性。
已有数据集有一定的局限性。
- GraIL-BM 基准中,训练集和测试集常量集完全不相交,因此不能捕捉到同时提到现有常数和新常数的三元组被添加到KG的情况。
- Hamaguchi-BM中,测试集每个三元组总是同时使用训练集提到的和没提到的常数,因此无法捕捉kg被拓展为仅仅提到不可见的常数的三元组的境况
- INDIGOBM基准,基于FB15K-237,在测试及中不可见常数的使用不受到任何限制
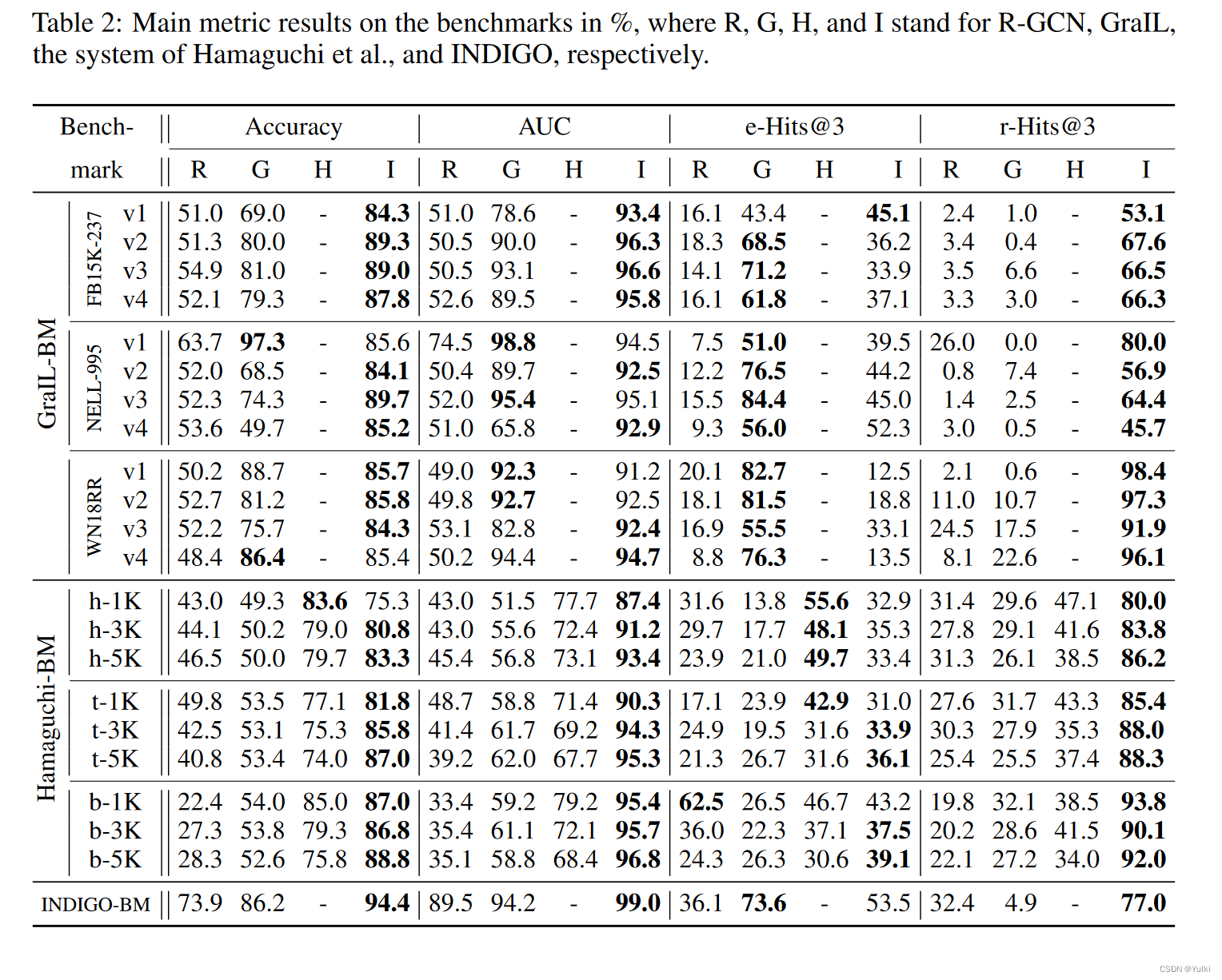
4.2 性能指标
注意采样,因为N是很大的。
4.3 Training
训练集T以9:1的比例随机分割成不完整的KG和Λ候选集。
一个正例,九个负例。
5、总结和未来工作
本文的局限性在于无法拓展到未知的关系和类型的上面。KGC用于KG-改上的推荐系统















 2563
2563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









