







论文链接:MonoCD: Monocular 3D Object Detection with Complementary Depths
代码链接:https://github.com/elvintanhust/MonoCD
作者:Longfei Yan, Pei Yan, Shengzhou Xiong, Xuanyu Xiang, Yihua Tan
发表单位:华中科技大学人工智能与自动化学院
会议/期刊:CVPR2024
一、研究背景
单目 3D 物体检测旨在预测准确的3D 边界框。根据是否使用额外数据,单目 3D目标检测算法可主要分为两类。第一种方法仅使用单个图像作为输入,没有任何额外信息(这种一般指标都很低)。第二种方法使用额外的数据,例如多视图、深度图、LIDAR点云和CAD模型,来获取附加信息并增强检测。
由于将2D图像映射到3D空间的过程本质上是不确定的。该论文旨在通过提高深度估计的准确性来提高单目三维物体检测的精度。现在主流的 CenterNet 范式,一般结合多个局部深度线索,将深度估计制定为多个深度预测的集合,以缓解单深度信息的不足。比如MonoFlex算法通过直接估计和物体高度这两个局部深度线索,并通过加权平均的方式将它们结合成一个深度值。
为了让读者清楚文章的背景,这里引用了【论文解读】单目3D目标检测 MonoFlex(CVPR 2021)中的解读内容,简洁说明一下MonoFlex算法的方法。
-
深度信息1:模型直接归回的深度信息。
-
深度信息2:通过关键点和几何约束,计算出来的深度信息。估计一共10个关键点:3D框8个顶点和上框面、下框面在图片中的投影到x_r的offset;然后通过相机模型计算深度。
-
深度信息融合,把几何深度、直接回归深度,然后两者做加权结合。
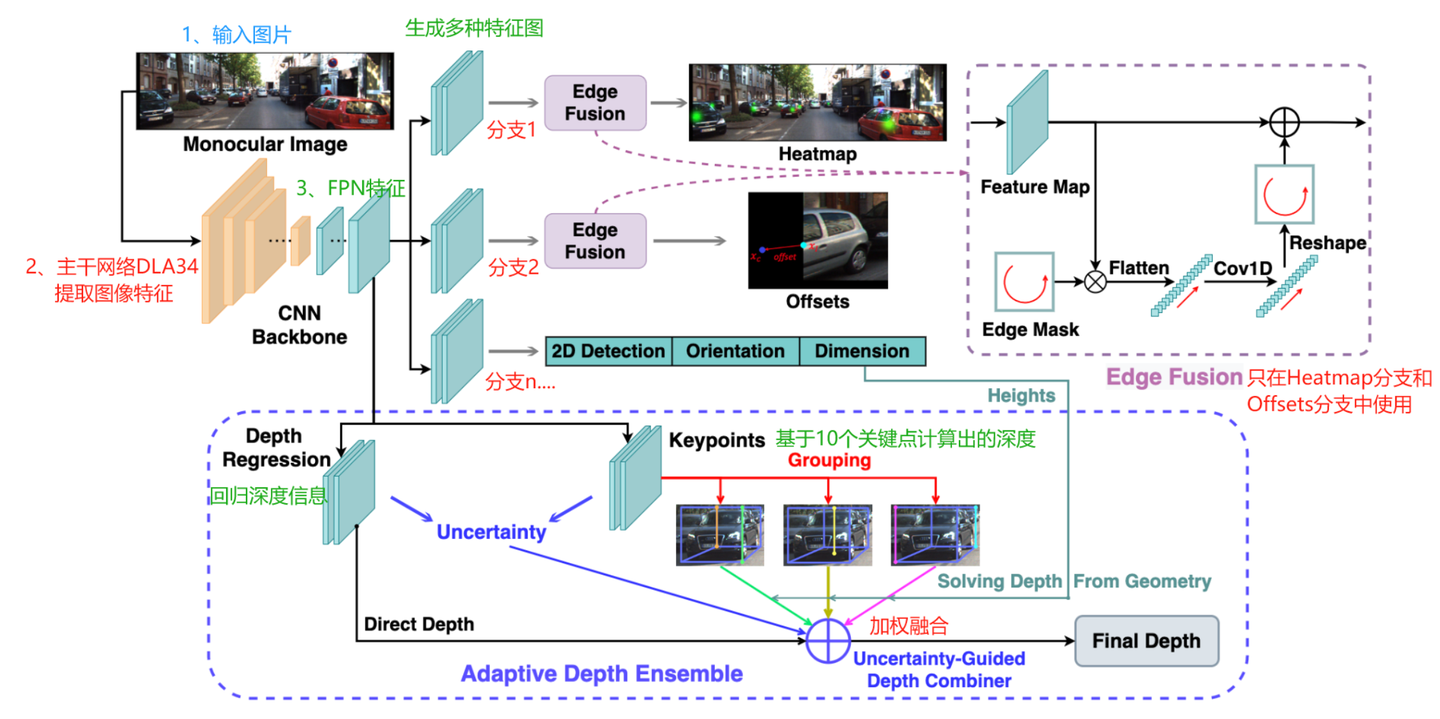
MonoFlex模型的示意图
问题提出:KITTI数据集上的实验表明,现有的多深度预测集成中95%具有相同的误差符号,即多个预测深度通常分布在地面实况的同一侧,导致深度误差无法相互抵消,阻碍了组合深度精度的提高。

具有两个深度分支Z1 和Z2 的耦合(coup)和互补(comp)多深度比较。其中Z*和Zsoft分别表示深度的groundtruth和最终的组合深度,现有的局部线索生成的深度容易在同一测。
这样的耦合现象作者认为归因于使用的局部深度线索都源自 CenterNet 范式中对象周围的相同局部特征。
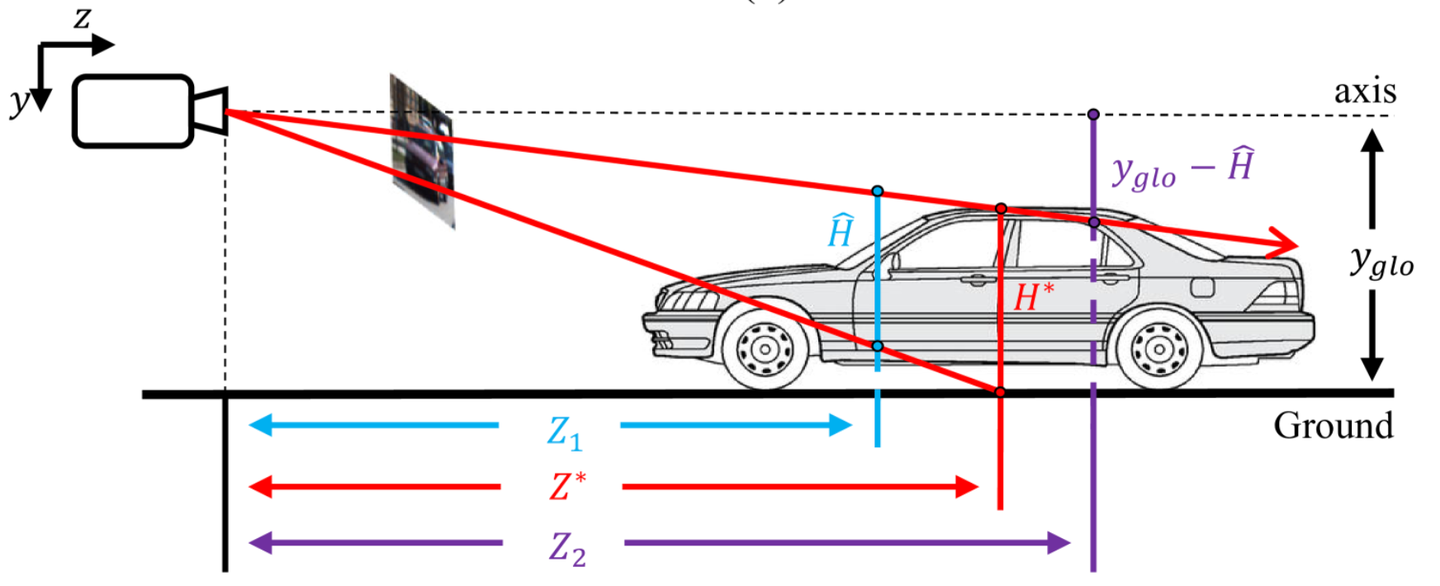
考虑物体3D高度H的不准确估计时,借助几何关系对2个深度分支进行演示。由局部线索生成的Z1和本文提出的全局线索yglo生成Z2都和H相关,H*和H^表示H的GT以及低估的H
在本文中,作者建议增加深度的互补性来缓解该问题。这里的互补性是指这些预测不仅以高精度为目标,而且具有不同的误差标志。为此,提出了两种新颖的设计。
首先,考虑到上述耦合现象,添加了一个新的深度预测分支,该分支利用来自整个图像的全局且有效的深度线索而不是局部线索来降低深度预测的相似性。它依赖于一幅图像中的所有对象大致位于同一平面上的全局信息。
其次,为了进一步提高互补性,作者建议充分利用多个深度线索之间的几何关系来实现形式上的互补,利用同一几何量的错误可能对不同分支产生相反影响的事实(达到一个负负为正的效果~)。
例如,在图2中,Z1 具有负误差,因为相关线索 3D 高度 H 被低估,而在本例子中, Z2 具有正误差,因为H 对 Z2 结合新线索 yglo的效果与 Z1 相反。因此,基于 H 的几何关系与 Z1 和 Z2 在形式上具有互补性。
本文贡献:
(1)指出现有单目物体深度预测的耦合,这限制了组合深度的准确性。因此建议提高深度互补性来缓解这个问题。
(2)提出了一种具有互补深度的新型单目 3D 探测器,名为 MonoCD,它补偿了之前多深度预测中忽略的互补性。
(3)提出一个新的深度预测分支,称为互补深度,它利用全局有效的深度线索,充分利用多个深度线索之间的几何关系来实现形式上的互补。
(4)对KITTI 基准进行评估,所提出的方法无需引入额外数据即可实现最先进的性能。此外,互补深度可以是一个轻量级的即插即用模块,可以增强多个现有探测器的性能。
二、整体框架
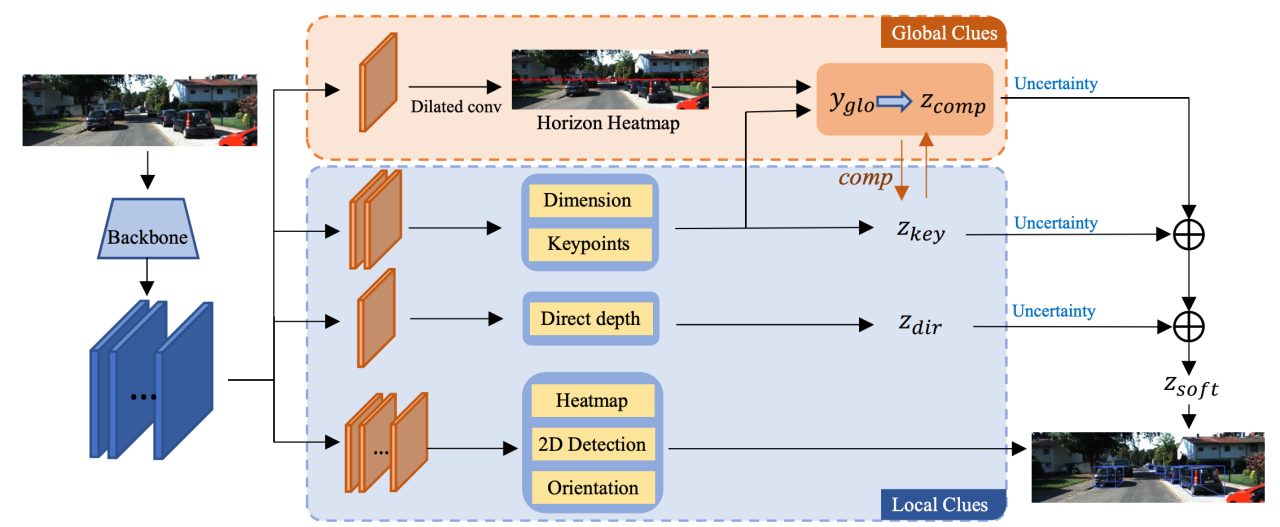
方法概述
输入图像首先经过特征提取网络的处理,然后导入多个预测头。预测头分为两部分。上面的橙色部分用于预测图像的全局地平线热图,作为生成互补深度预测的全局线索( Yglo,论文这里似乎写错了,写成了Zcomp)。下方的蓝色部分,在预测每个兴趣点的局部信息后,进一步生成关键点深度( Zkey )和直接深度( Zdir )。最后,使用同时预测的不确定性对三个深度预测分支进行加权和组合,以获得最终的深度估计。
解释一下全文一直在说的clue(线索)到底是什么意思?
线索指的是从图像中可以提取出来用于深度估计的信息或数据特征。当谈论全局线索时,这指的是可以反映整个图像深度分布情况的特征,例如地平线的位置。这样的全局信息可以帮助系统理解场景的远近关系,从而辅助深度的预测。在单目深度估计中,全局线索和局部线索分别提供了不同尺度上的视觉信息:
-
全局线索(如地平线热图——heatmap,centernet范式的方法)提供关于整个场景布局的信息,如天空和地面的分界线,这些信息可以用来帮助估计物体相对于地面的位置。
-
局部线索则关注于图像中特定兴趣点或物体的详细特征,如物体的大小、形状或者其他局部特征,这些信息用来估计物体的具体位置和深度。
三、核心方法
3.1 问题定义
单目 3D 对象检测的任务是仅从 2D 图像中识别感兴趣的对象并预测其相应的 3D 属性,包括 3D 位置(x,y,z),尺寸(h,w,l)和方向θ换为2.5D信息(uc,vc,c)进行预测,物体三维空间中的 x 和 y 坐标的恢复可以通过下面的公式进行计算:
其中, 是图像中的投影3D中心,
是相机光学中心,
和
分别代表水平和垂直焦距。
现在很多工作都认识到了,深度z是限制单目3D检测器性能的主要原因,并利用多深度来提高深度预测的准确性,通过下面的公式:
其中, 表示n个预测深度,
表示由预测的不确定性确定的权重,
用作输出的最终深度。
3.2 互补深度的影响
作者在这节用了大量公式去论证深度预测互补的必要性,其实整体就是说要一个正、一个负,不在同一侧(以真实深度为原点)
为了证明互补深度的有效性,作者从数学角度展示了它的优越性。
定义两个不同的深度预测分支和
如下
其中, 是深度的GT。 e1 和 e2 分别是单个预测中两个深度分支的误差。注意 e1 和 e2 的正负对应于误差的符号。定义 e1e2>0 来模拟多深度耦合的情况,如图1所示。将多个耦合深度的最终组合误差称为耦合深度误差。因此,参考方程,
和
的耦合深度误差 E1 可表示为:
其中w1和w2满足w1,w2 > 0和w1+w2=1,然后沿着z*对称翻转 ,而不改变预测的准确性:
翻转后, 和
误差符号相反,人为地实现了它们之间更高的互补性,将多个互补深度的最终组合误差称为互补深度误差,类似地,
′ 和
的互补深度误差E2可以表示为:
通过数学变化,进一步表达方程(感觉这里数学推导花里胡哨,也可能是我太菜~):
显然,由于条件 e1e2>0 ,互补深度误差 E2 始终小于耦合深度误差 E1 。无论权重或误差大小如何变化,这种关系都保持不变。类似地,在 z2 翻转期间保持 z1 不变,结论是等效的。
因此可以得出结论:实现两个深度分支之间的互补关系有助于减少整体深度误差,即使不提高单个分支的准确性。
为了证明互补深度在实践中的有效性,作者还选择经典的多深度预测基线在 KITTI val 集中进行评估。它包含4个深度预测分支(1个直接估计深度和3个几何深度),
经测试任意两个分支的耦合率在95%左右。
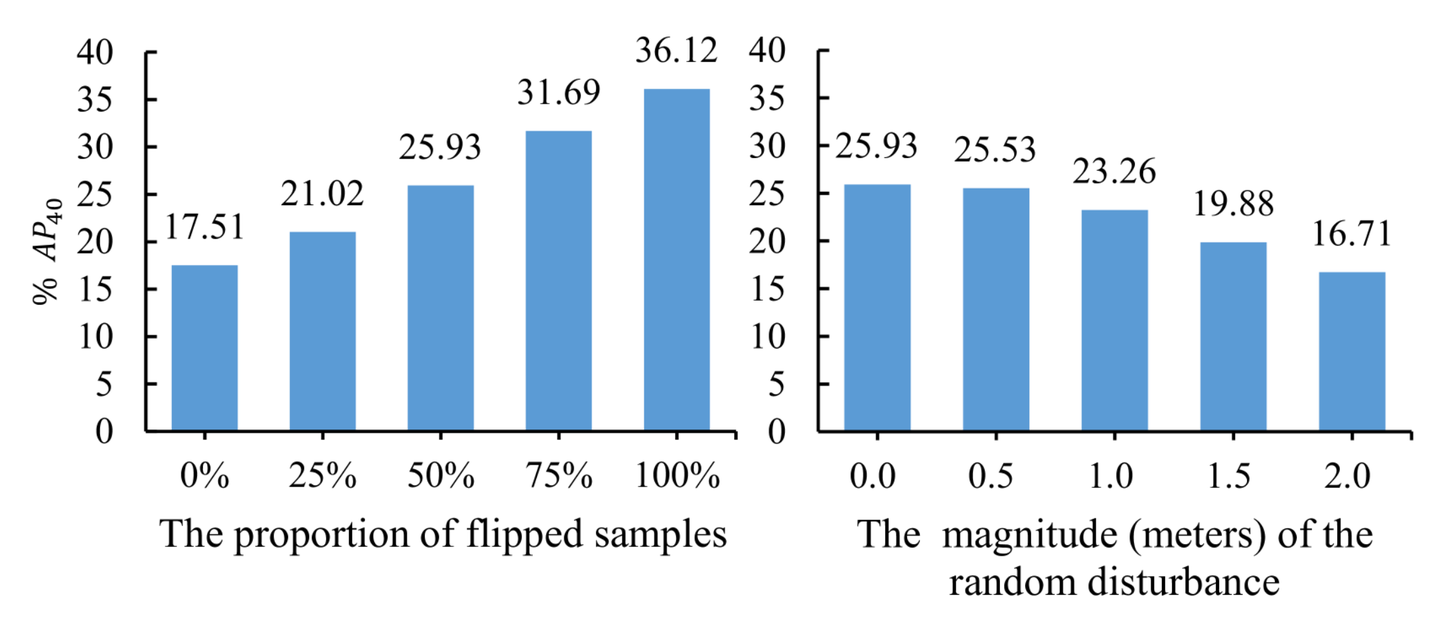
KITTI验证集上的互补效果评估,左图是变换符号;右图是随机扰动
如图左侧所示,沿着地面实况对称地翻转其中的直接深度估计分支。 在 0% 到 100% 的样本范围内实现不同级别的深度互补。此外,考虑到在实践中获得具有相反误差符号的深度预测同时保持相同精度的困难,通过翻转深度分支同时在其上应用不同幅度的随机扰动进行了另一项实验。结果图右侧所示。通过执行与上述相同的操作,在其他分支中观察到类似的结果。基于此,有以下三点观察:
观察1:图左侧,检测精度随着翻转样本比例的增加而增加。它表明,增加多个深度预测分支之间的互补性可以不断提高检测精度。
观察2:对于两个独立的深度预测分支,理想情况下,它们的预测在所有样本中符号相反的比例应该为50%。由于基线中多个分支的耦合,情况类似于图左侧的50%翻转比例。因此,降低多个深度预测分支的相似度也可以增加它们的互补性(这里右图要去跟左图的0%去看,也就是17.51,会发现25.93是大于它的,但是当等于2的时候,16.71其实是小于25.93的)。
观察3:在翻转比例固定为50%的情况下,如图右侧所示,直到施加幅度为2米的随机扰动(对于汽车在KITTI)认为互补效应消失了(16.71小于17.51)。这表明即使损失一些深度估计精度,互补效应仍然可以对整体性能做出贡献,并且最终整体性能能否得到改善取决于相反符号的比例和深度估计精度。
实验中,作者发现随着翻转分支的数量接近未翻转分支的数量,整体性能相应提高。
3.3 3D Detector with Complementary Depths
整体基于CenterNet,DLA-34 是网络的backbone,回归头分为两部分:局部线索和全局线索。局部线索根据预测的热图估计每个局部峰值点的维度、关键点、直接深度、方向和2D检测,参考MonoFlex。由于这些几何量的预测与图像中局部峰值点的位置高度相关,因此它们被称为局部线索,生成z dir和z key。
全局线索分支根据提取的所有像素特征预测整个图像的Horizon Heatmap。用于获取场景中y glo趋势,然后输出互补深度z comp全局线索。
3.3.1 Depth Prediction with Global Clues
利用全局线索进行深度预测,神经网络通过以下方式查看单个图像的深度:
其中 y 表示物体在相机坐标系中的 y 轴坐标, vb 表示投影底部中心在像素坐标中的垂直坐标系统。考虑到 y 也表示物体所在平面的高度,并且所有物体大致位于一个平面内, y包含这样一个全局特征,并且可以与其他深度线索区分开来。与之前隐式利用方程的神经网络不同,作者建议明确预测 y 。
为了避免陷入耦合,不使用基于中心的方法预测 y 。而是建议首先通过地平面方程获得场景中 y 的倾斜趋势。地平面方程的预测基于Horizon Heatmap分支,省略了边缘预测,得到预测结果为:
其中, ,kh和bh 表示地平线热图拟合的地平线的斜率和截距。之后,再考虑前面关于恢复y的等式和物体的投影底部中心 (ub,vb) ,具有全局信息的 y 可以导出为:
得到一个新的具有全局线索的深度预测分支:
此外,为了更好地利用全局特征并扩大感受野,使用膨胀卷积来预测地平线热图。
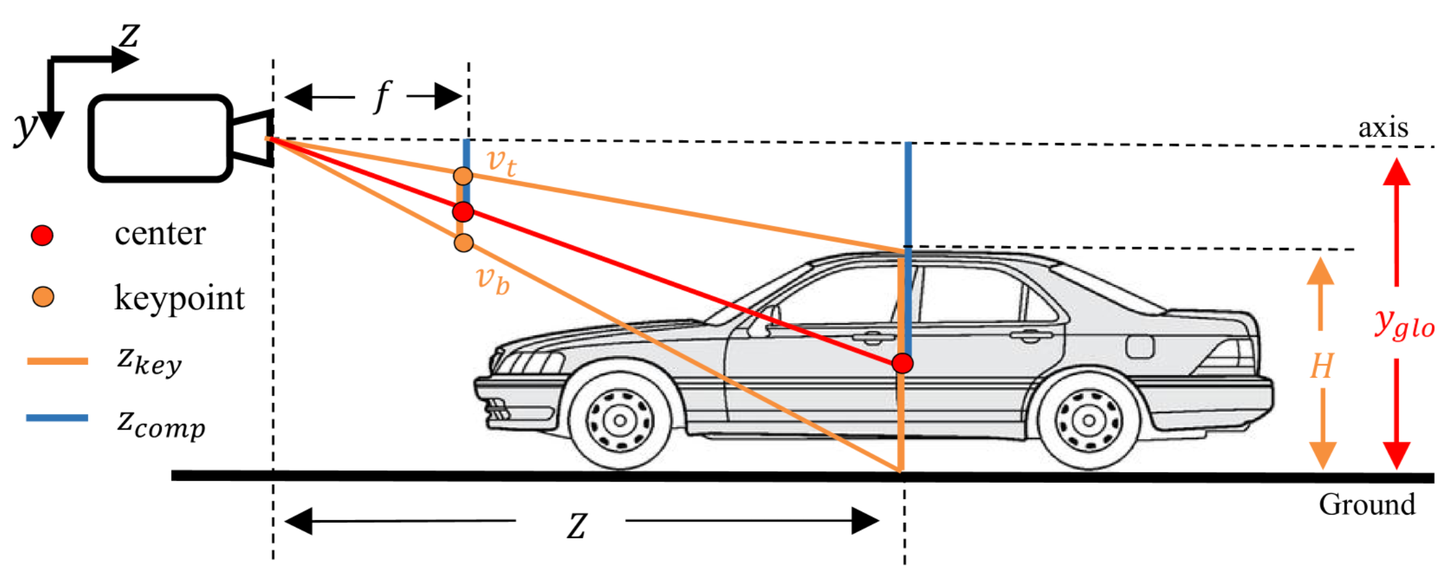
不同深度的几何对应关系。为了避免重叠, zkey和 zcomp 的几何对应分别用橙色和蓝色线标记。
3.3.2 Complementary Form in Solving
仅仅实现更独立的深度预测是不够的,希望充分利用多个深度预测分支之间的几何关系来进一步提高互补性。考虑到投影的底部中心 (ub,vb) 和顶部中心 (ut,vt) ,如上图的橙色部分所示,关键点和高度导出的深度可以重写为:
其中 H 表示对象的 3D 高度。结合等式获得的全局 yglo 信息。通过上述公式进一步提出了与 zkey 形式互补的深度预测:
几何对应关系如上图蓝色部分所示。可以看出,设计的方程中 H 和 vt 的符号为正好相反。 这意味着在预测每个模型的 3D 信息时, H 和 vt 的误差对 zkey 和 zcomp 具有相反的影响。虽然等式并不严格对称,这进一步增加了 zkey 和 zcomp的误差 ekey * ecomp 满足<0 。正如所证明的,最终深度误差的一部分在方程的加权平均中被抵消。
四、实验结果
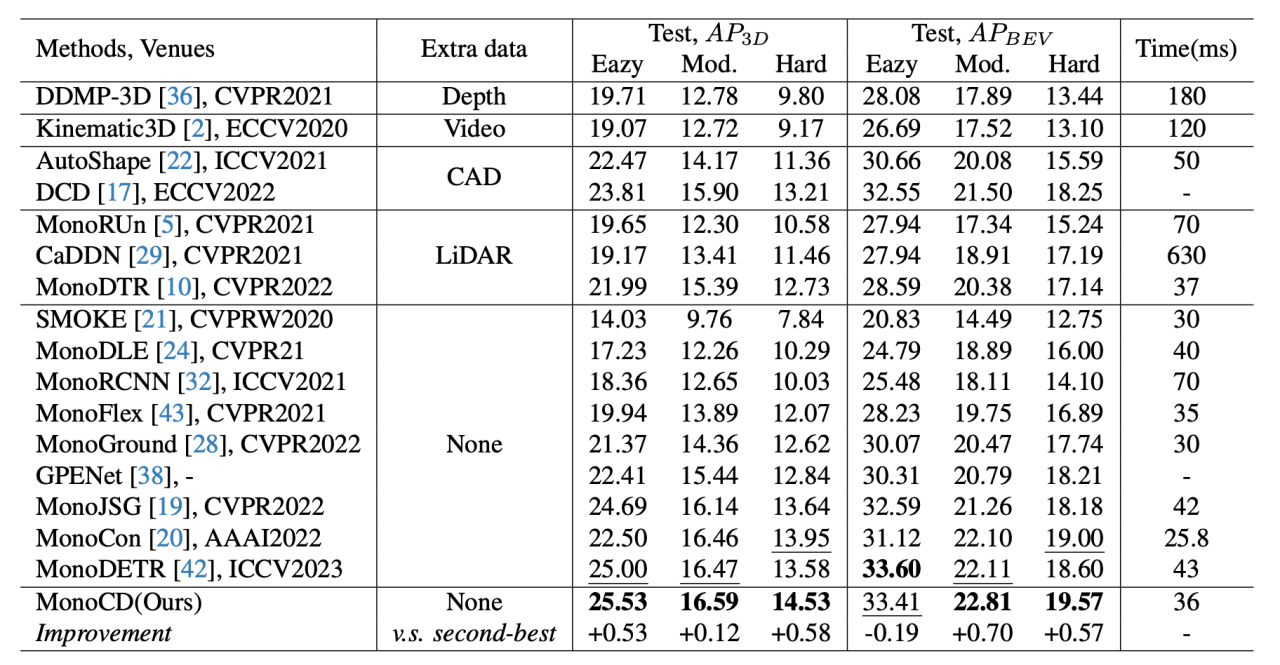
在 KITTI 测试集上与当前最先进的汽车类别方法进行比较
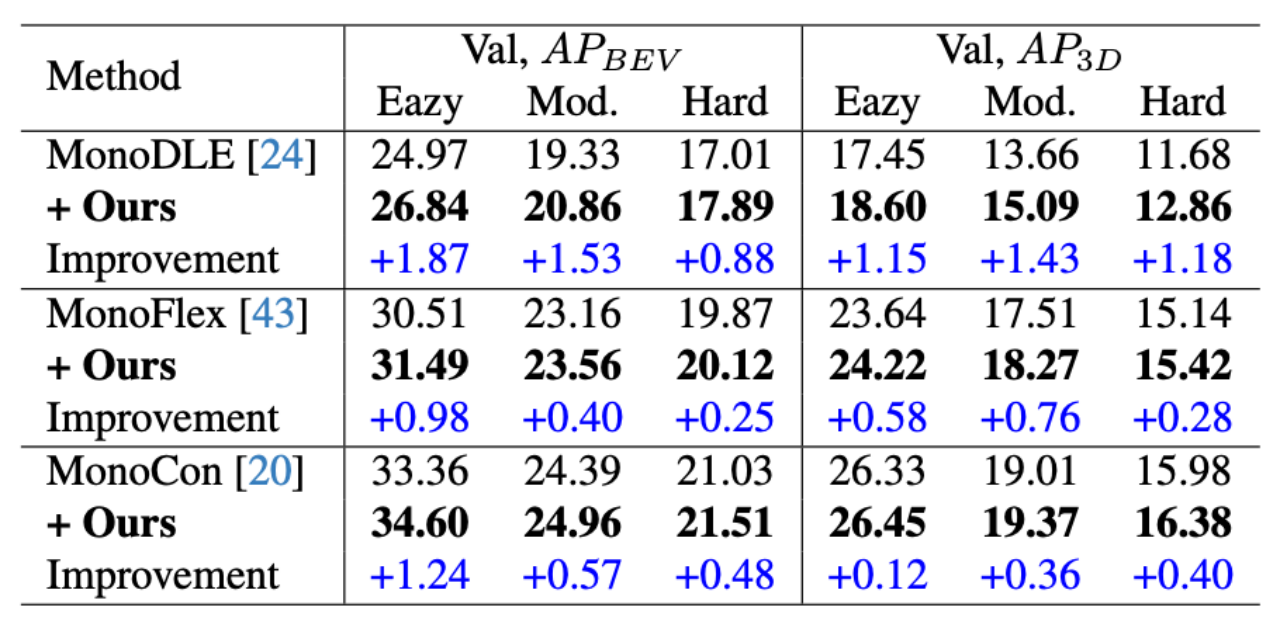
将互补深度扩展到三个基于centernet的单目 3D 探测器
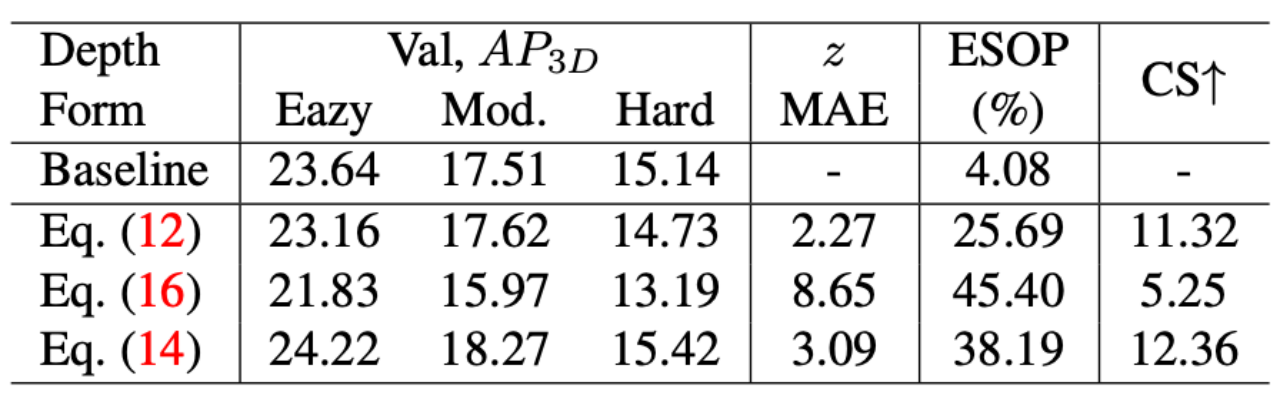
互补形式的消融研究
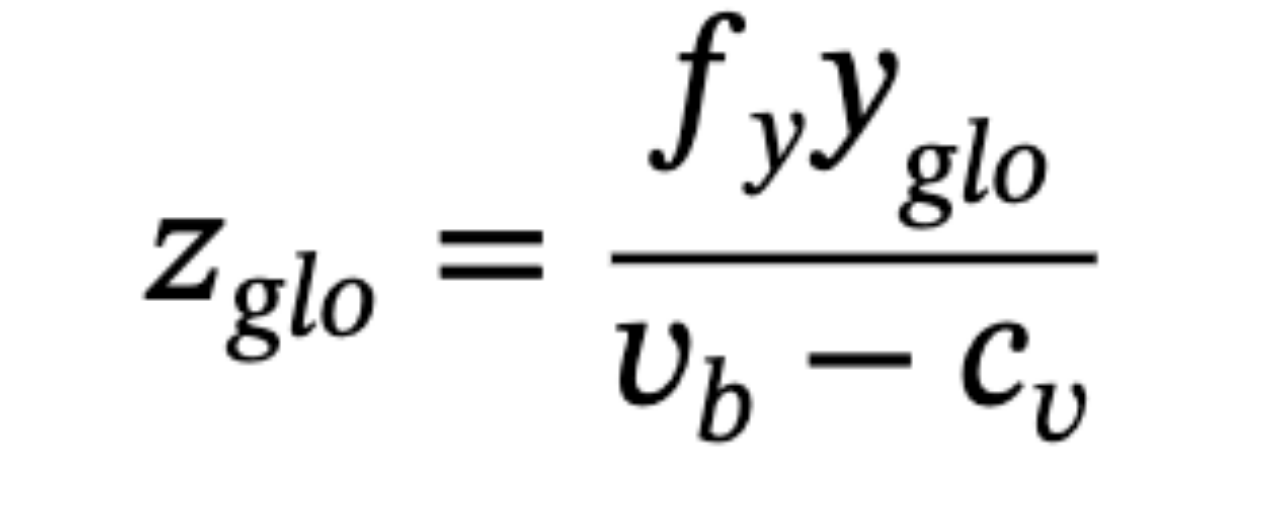
Eq.(12)

Eq.(16)
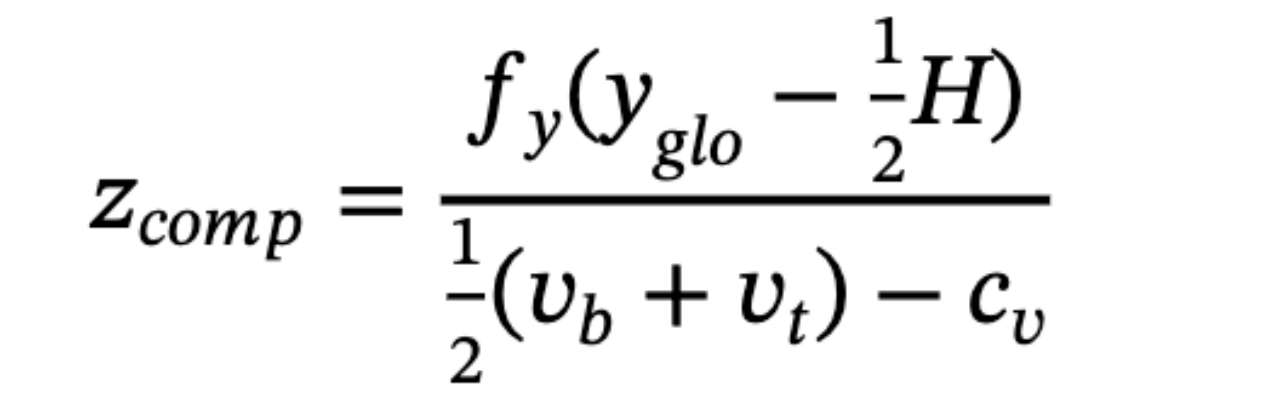
Eq.(14)
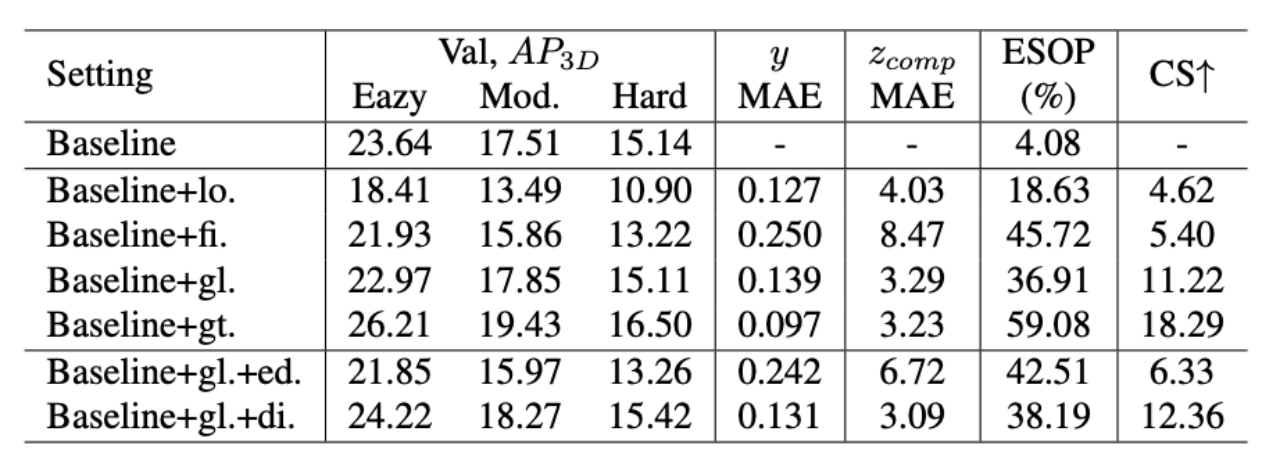
消融实验:lo使用局部线索分支;固定距离(1.65米);gl使用全局线索分支;gt直接使用由val集的groundtruth生成的地平面方程;ed使用边缘检测来获取全局线索分支中的水平斜率;di意味着使用扩张卷积
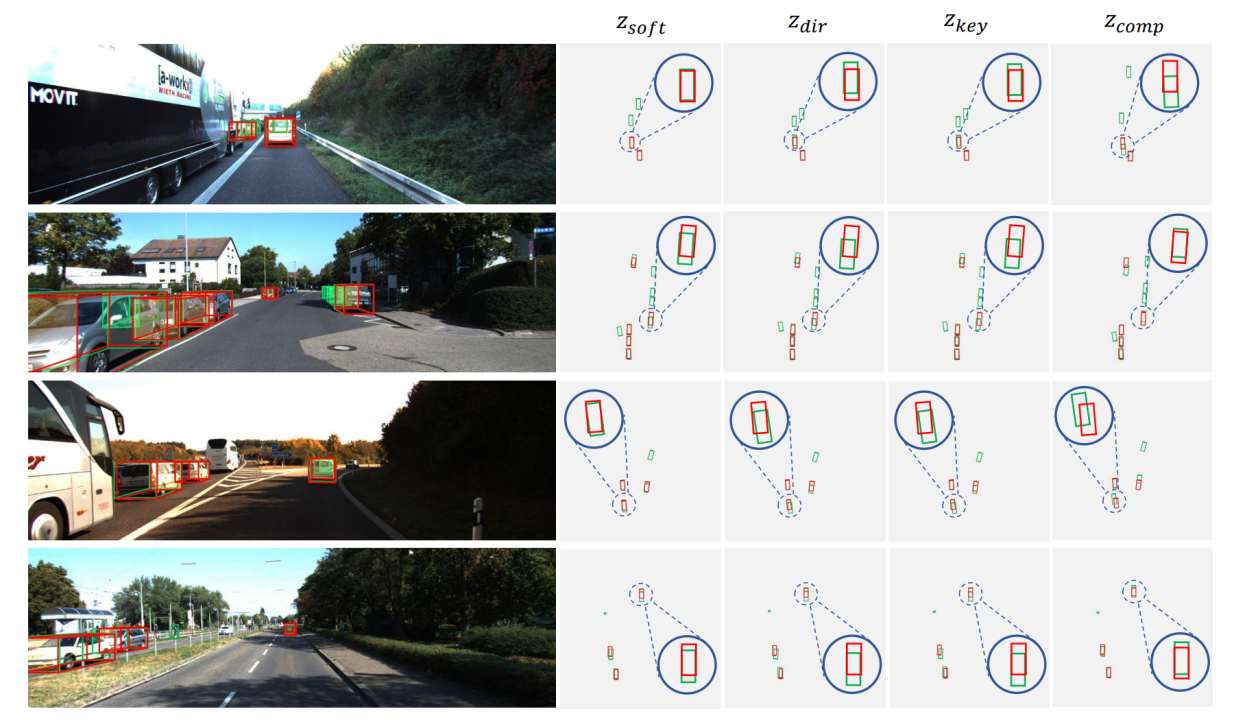
KITTI 验证集的定性示例















 1229
1229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









