







论文链接:LLaMA: Open and Efficient Foundation Language Models
代码链接:GitHub - meta-llama/llama: Inference code for Llama models
作者:Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample
发表单位:Meta AI
会议/期刊:无
一、研究背景
1.1 现有方法的局限性
-
大部分现有的大规模语言模型(LLMs)如GPT-3和PaLM等,依赖于私有和不可访问的数据集进行训练,使得研究社区难以复现和改进这些模型。
-
Hoffmann等人(2022年)的研究表明,在给定的计算预算下,最大的模型并不总是表现最好的(过去很多人假设参数越多,性能越好),相反,较小的模型在更多数据上进行训练可以达到更好的性能。
-
然而,Hoffmann的缩放定律目的是为了确定怎么在特定的训练预算下最佳缩放数据集和模型大小。但是这个目标忽略了推理预算,作者认为训练时间更长的小模型可以让推理方面更加省钱。
1.2 论文贡献
这项工作的重点是训练一系列语言模型,通过训练比通常情况下更多的词块,在各种推理预算下实现最佳性能。由此产生的模型称为 LLaMA(7B-65B)。本文有如下贡献:
-
训练一系列在不同推理预算下性能最佳的语言模型,例如,LLaMA-13B 在大多数基准测试中都优于 GPT-3,尽管其体积小了 10 倍,65B 参数模型也能与 Chinchilla 或 PaLM-540B 等最好的大型语言模型相媲美。
-
完全使用公开可用的数据进行训练,确保模型能够开源,模型可以在单个GPU上运行,促进研究社区的进步和模型的改进。
二、核心方法
2.1 数据集组成和处理
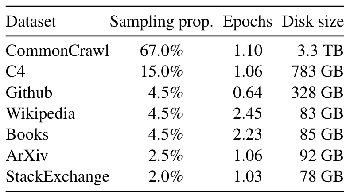
数据集组成
LLaMA的训练数据集由多个公开的数据源组成,包括CommonCrawl(67%)、C4(15%)、Github(4.5%)、Wikipedia(4.5%)、Gutenberg和Books3(4.5%)、ArXiv(2.5%)、StackExchange(2%)。
-
CommonCrawl:使用CCNet管道对2017至2020年的五个CommonCrawl数据集进行处理,包括逐行去重、语言识别和质量过滤。过滤低质量内容,确保只保留高质量页面。
-
C4:使用C4数据集进行额外的预处理,包括去重和语言识别。质量过滤依赖于启发式规则,如标点符号的存在、网页中的单词和句子数量等。
-
Github:使用Google BigQuery中公开的GitHub数据集,仅保留在Apache、BSD和MIT许可证下发布的项目。过滤低质量文件,去除样板代码和重复内容。
-
Wikipedia:使用2022年6月至8月期间的Wikipedia数据,覆盖20种语言。处理步骤包括去除超链接、评论和其他格式化样板。
-
Gutenberg和Books3:包含Gutenberg项目和Books3部分。进行书籍层面的去重,移除重复度超过90%书籍。
-
ArXiv:处理arXiv的LaTeX文件,去除文献前的内容和参考文献部分。删除.tex文件中的注释,并展开定义和宏以增加一致性。
-
Stack Exchange:使用Stack Exchange网站的高质量问答数据,保留28个最大网站的数据,去除HTML标签并按得分排序。
2.2 数据处理步骤
-
去重:在多个数据源中进行逐行去重和文件级别的去重,确保数据集的独特性。
-
语言识别:使用fastText线性分类器进行语言识别,去除非英语页面。
-
质量过滤:通过n-gram语言模型和线性模型进行质量过滤,确保只保留高质量内容。
-
数据混合:根据每个数据源的比例将数据混合,确保训练数据的多样性和质量。
总体而言,经过标记化处理后,整个训练数据集包含约 1.4T 个标记(token,指在进行标记化处理后的基本单元,比如"model","language","?")。对于大部分训练数据,每个标记在训练过程中只使用一次,但维基百科和图书领域,进行了大约两次训练。
2.3 模型架构
论文在Transformer架构的基础上进行了多项改进,以提升模型的性能和训练稳定性。主要改进包括:
预归一化(Pre-normalization):
-
改进点:在每个Transformer子层的输入进行归一化,而不是输出。
-
灵感来源:GPT-3。
-
具体实现:使用RMSNorm归一化函数。
SwiGLU激活函数(SwiGLU Activation Function):
-
改进点:将ReLU非线性激活函数替换为SwiGLU激活函数。
-
灵感来源:PaLM。
旋转嵌入(Rotary Embeddings):
-
改进点:去除绝对位置嵌入,改用旋转位置嵌入(RoPE)。
-
灵感来源:GPTNeo。
-
具体实现:在网络的每一层添加旋转位置嵌入。
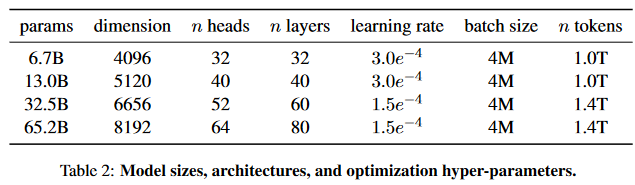
模型大小、结构和优化超参数
2.4 模型优化
优化器:
-
使用AdamW优化器,β1 = 0.9,β2 = 0.95。
-
采用余弦学习率调度,最终学习率为最大学习率的10%。
-
使用0.1的权重衰减和1.0的梯度裁剪。
训练效率提升:
-
使用高效的因果多头注意力实现(xformers 库,只关注输入序列中当前时间步之前的部分,以确保模型不会"看到"未来的信息),通过不存储注意力权重以及不计算因果掩码下的键/查询分数,减少了内存使用和运行时间,减少内存使用和运行时间。
-
通过检查点机制减少反向传播期间重新计算的激活数量。
模型和序列并行:
-
采用模型和序列并行技术,最大限度地减少内存使用。
-
重叠计算激活和GPU之间的通信,以提高训练效率。
在2048个80GB RAM的A100 GPU上,65B参数模型的代码处理速度约为每秒每GPU 380个token。训练包含1.4万亿个token的数据集大约需要21天。
三、实验结果
考虑了Zero-shot和Few-shot任务,并报告了总共 20 个基准的结果:
-
Zero-shot:提供了任务的文字描述和测试示例。模型要么通过开放式生成提供答案,要么对提出的答案进行排名。
-
Few-shot:提供几个任务示例(1 到 64 个之间)和一个测试示例。模型将这些文本作为输入,生成答案或对不同选项进行排序。

8个基准的常识推理
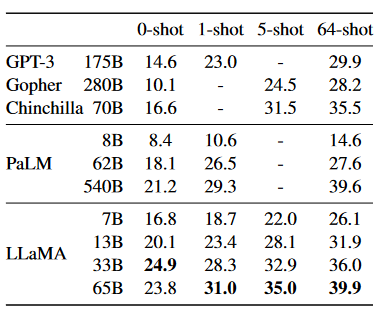
多项选择题NaturalQuestions上的精确匹配性能
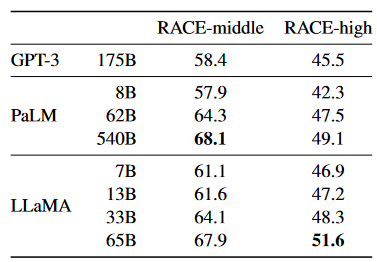
阅读理解
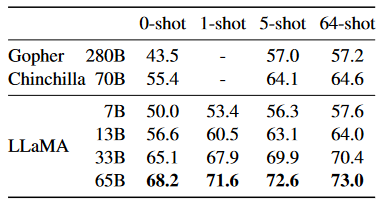
TriviaQA问答
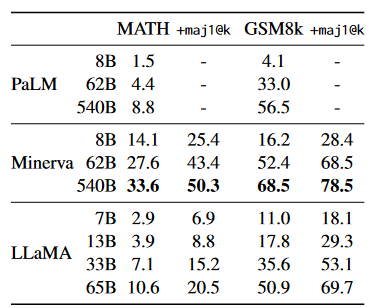
数学推理
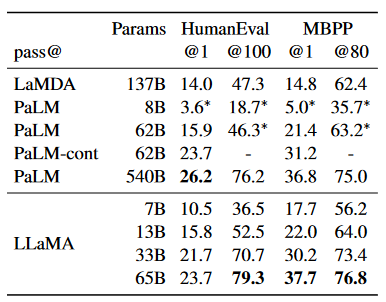
代码生成
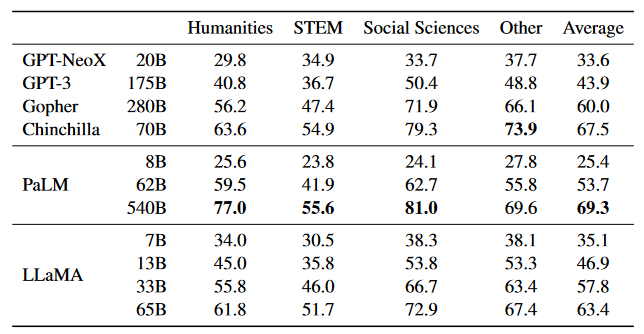
多任务语言理解
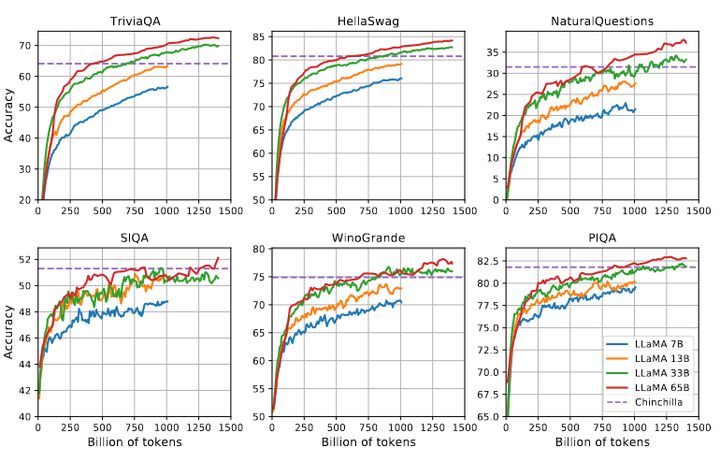
训练过程中模型性能的进化情况,说明了随着训练数据量的增加,模型在多个基准测试上的性能稳步提高。















 768
768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









