






LLaMA: Open and Efficient Foundation Language Models
基本信息
博客贡献人
柴进
作者
Hugo Touvron∗, Thibaut Lavril∗, Gautier Izacard∗, Xavier Martinet, et al.
标签
摘要
本文介绍了LLaMA,是一个从7B到65B参数的基础语言模型集合。作者在数万亿计的token上训练该模型,证明了仅使用公开数据集也可以训练出SOTA级别的模型,而无需专有或未公开的数据集。
最终实验结果显示,LLaMA-13B在大多数基准测试中要优于GPT-3(175B),同时LLaMA-65B与最好的模型Chinchilla-70B、PaLM-540B相比具有竞争力。
问题定义
基于更多的参数会带来更好的性能这一假设,前人将模型越做越大。然而,Hoffmann等人(2022)最近的工作表明,在给定的计算预算下,最好的性能不是由最大的模型实现的,而是由在更多数据上训练的小模型实现的。此外,以往的LLMs模型还存在着某些限制:
- 私有化。这限制了更广泛的研究社区基于这些模型进行再研究的能力
- 计算成本高。对于资源有限的研究人员而言,训练和部署这些大语言模型所需计算资源过大
因此,本文认为一个小的、训练时间较长的模型在推理预算下有更好的性能。最终所得模型为LLaMA,只使用了公开可用的数据,并且可以在单个GPU上运行,这将有助于一般研究人员对LLM的访问和研究。
方法
方法描述
模型整体框架基于Transformer的解码器(Decoder)模块,本文对其做了部分改进,主要有三点。
原始Transformer的架构如下:
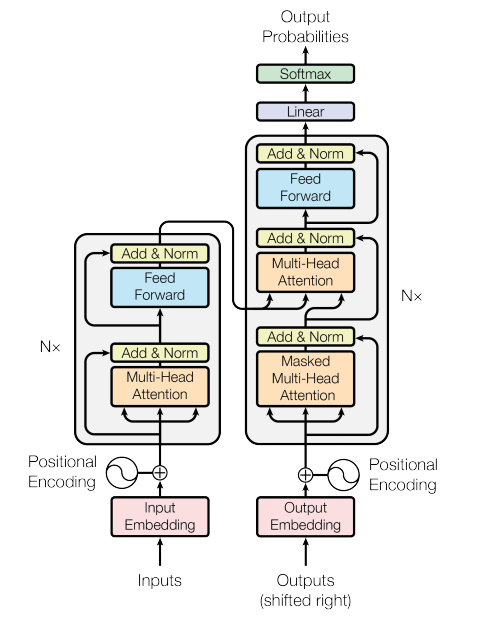
1、预归一化[GPT-3]
为了提高训练的稳定性,本文对每个transformer子层的输入进行归一化,而不是对输出进行归一化,并使用了Zhang和Sennrich(2019)介绍的RMSNorm作为归一化函数。
RMSNorm(Root Mean Square Layer Normalization)是Layer Normalization的一种变体,针对同一样本的不同特征做归一化处理,可以在梯度下降时令损失更加平滑。
原文中提出的RMSNorm归一化函数去掉了减去均值的部分,只保留方差部分,具体表达式为:
a
i
ˉ
=
a
i
R
M
S
(
a
)
g
i
\bar{a_i} = \frac{a_i}{RMS(a)}g_i
aiˉ=RMS(a)aigi
其中,
R
M
S
(
a
)
=
1
n
∑
i
=
1
n
a
i
2
+
ϵ
RMS(a) = \sqrt{\frac{1}{n}\sum_{i=1}^{n}a_i^{2}+\epsilon}
RMS(a)=n1i=1∑nai2+ϵ
对应代码如下:

其中,x是输入向量,weight是末尾乘的可训练参数,eps是防止取倒数之后分母为0,torch.rsqrt是开平方并取倒数。
2、SwiGLU激活函数[PaLM]
本文采用了由Shazeer(2020)介绍的SwiGLU激活函数,替换了原始Transformer中前馈神经网络FFN模块的激活函数ReLU,使得收敛速度更快,效果更好,达到提高性能的作用。
原始的FFN层以如下公式表述:
F
F
N
(
X
)
=
m
a
x
(
0
,
x
W
1
+
b
1
)
W
2
+
b
2
FFN(X) = max(0,xW_1+b_1)W_2+b_2
FFN(X)=max(0,xW1+b1)W2+b2
采用SwiGLU激活函数后,FFN层以如下公式进行表述:
F
F
N
s
w
i
s
h
G
L
U
(
x
,
W
,
V
,
W
2
)
=
(
S
w
i
s
h
1
(
x
W
)
⊗
x
V
)
W
2
FFN_{swishGLU}(x,W,V,W_2) = (Swish_1(xW)\otimes xV)W_2
FFNswishGLU(x,W,V,W2)=(Swish1(xW)⊗xV)W2
其中,
S
w
i
s
h
β
(
x
)
=
x
∗
s
i
g
m
o
i
d
(
β
x
)
Swish_{\beta}(x) = x*sigmoid(\beta x)
Swishβ(x)=x∗sigmoid(βx)
LLaMA选择
β
=
1
\beta = 1
β=1 时的SiLU函数,相较于ReLU,SiLU在0附近进行平滑;但同时引入了指数运算,增加了计算量。
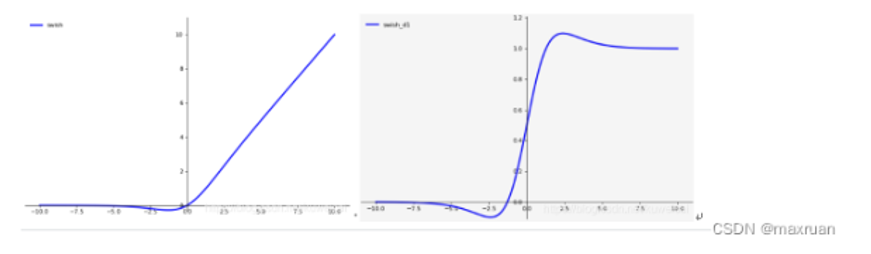
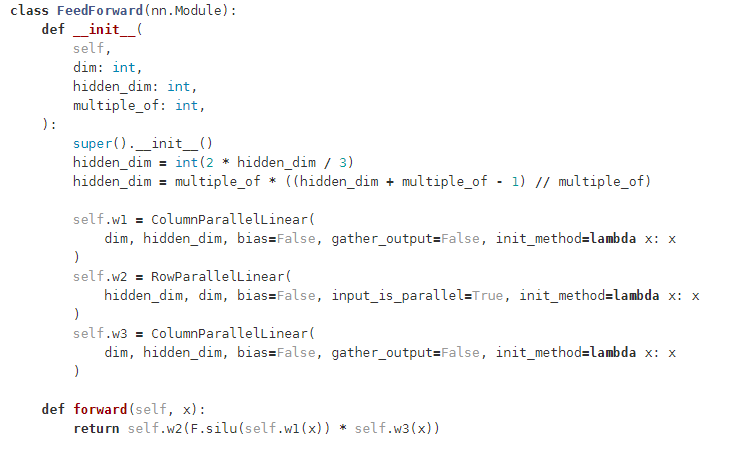
原始的FFN只有两个权重矩阵 W 1 , W 2 W_1, W_2 W1,W2,对应两层全连接; 采用了SwiGLU激活函数后,有三个权重矩阵 W 1 , W 2 , V W_1, W_2, V W1,W2,V,为了保持参数相对相等,维度少了三分之一 。
代码实现如下:
3、RoPE旋转位置编码[GPTNeo]
本文删除了绝对位置编码,取而代之的是在网络的每一层添加Su等人(2021)介绍的旋转位置嵌入RoPE(Rotary Position Embedding),更好的处理序列中的旋转对称性。RoPE既保留了绝对位置编码中的绝对位置信息,又保留了在内积运算下,对位置信息的相对性。
RoPE旋转式位置编码使用乘法实现偏置,具体思想是将位置信息编码为一个旋转矩阵,然后将该矩阵与输入向量进行相乘,从而得到一个新的向量表示。由于旋转矩阵的稀疏性,可以通过下述方式实现:
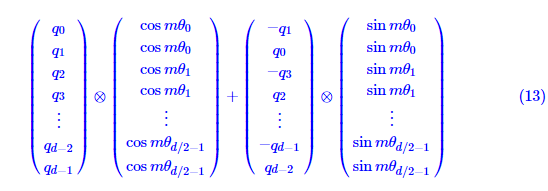
综合以上,LLaMA对Transformer做了部分改进后的总体架构如下:
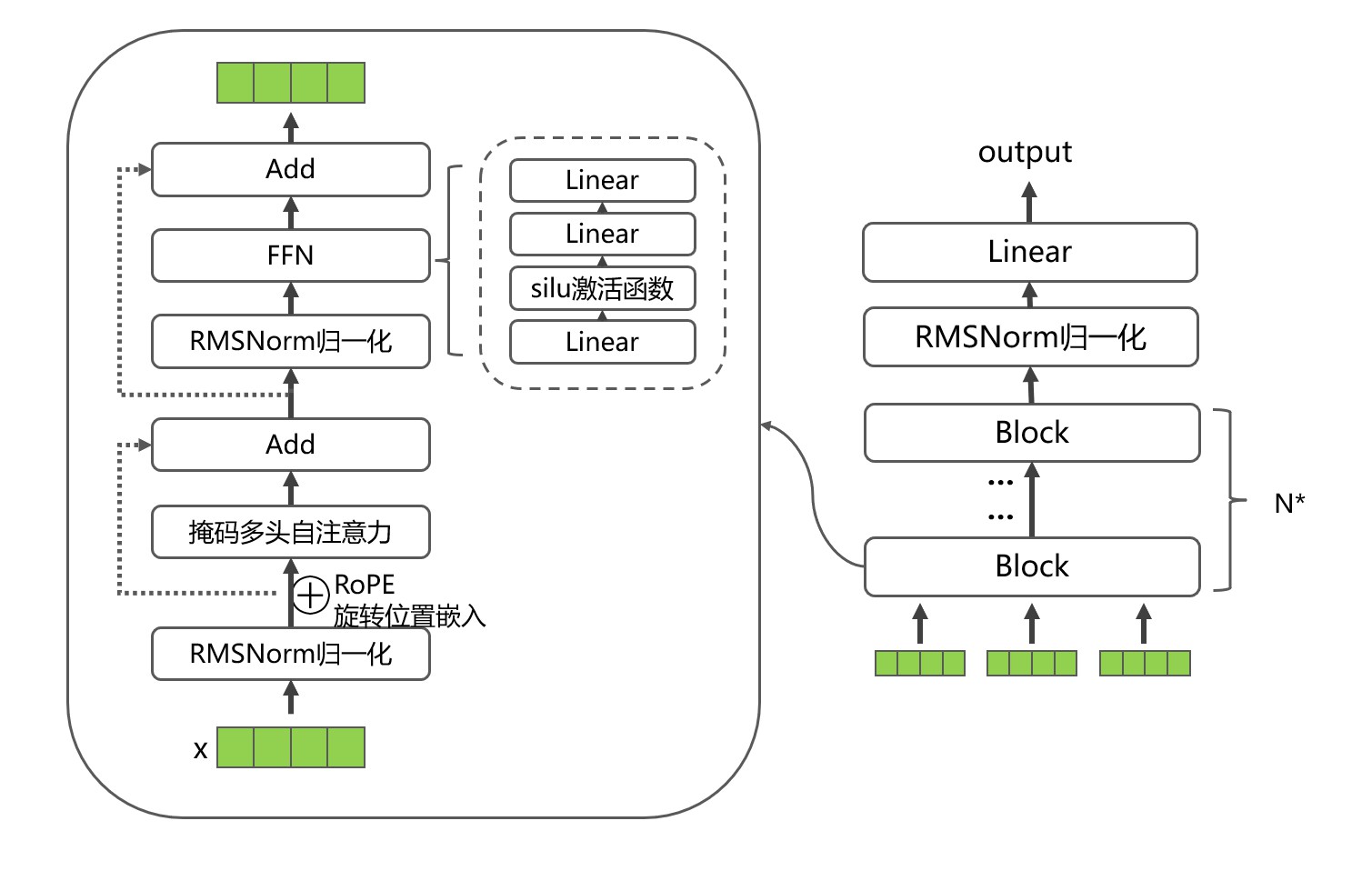
- 输入 x x x,分别经过三个Linear得到 x q , x k , x v x_q,x_k,x_v xq,xk,xv;
- 在 x q x_q xq和 x k x_k xk中加入旋转位置编码;
- 缓存 x k x_k xk和 x v x_v xv;缓存是为了在generate时减少token的重复计算,即在计算第n个token特征时,需要用到第1,…,n-1个token,所以缓存下来能够避免计算浪费;
- 计算 s o f t m a x ( Q K T d k ) V softmax(\frac{QK^T}{\sqrt{d_k}})V softmax(dkQKT)V。

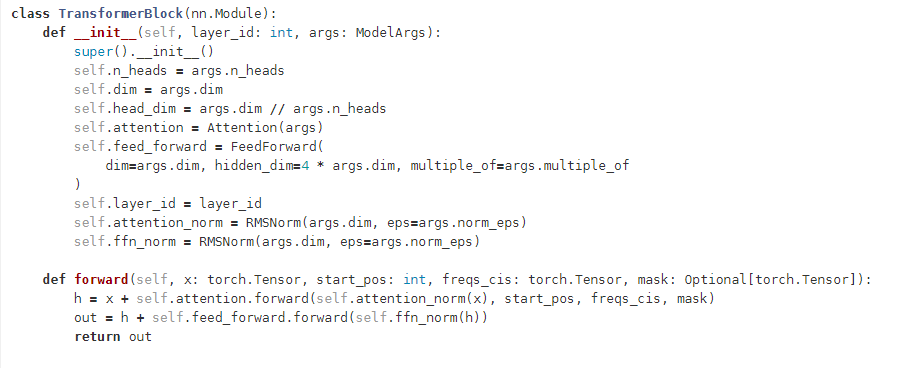
将Attention模块和上述的FFN模块结合,就组成一个transformer block,实现代码如下:
实验
实验设置
数据集
本文的数据集由几个来源混合而成,涵盖了不同的领域,并且只使用公开可用的数据。预训练数据的占比如下表所示:
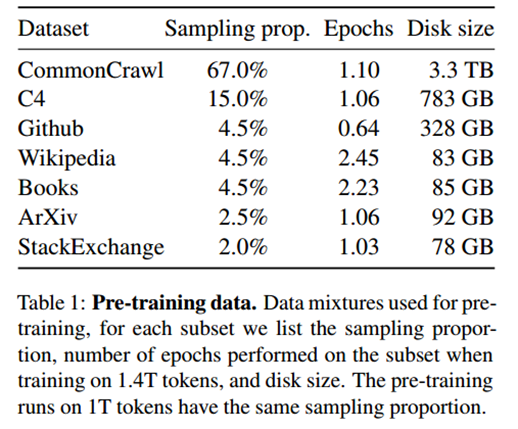
CommonCrawl[67.0%]
CommonCrawl是一个海量的、非结构化的、多语言的公开网页数据集,LLaMA选取了2017-2020年的数据,并对数据进行了预处理:
运用fastText线性分类器进行语言识别,去除非英语页面
运用n-gram语言模型过滤低质量内容
训练了一个线性模型,把没有在维基百科中引用的随机内容页面过滤掉
C4[15.0%]
C4数据集是一个巨大的、预处理过的Common Crawl网络爬取语料库的版本。
C4的预处理也包含重复数据删除和语言识别步骤,在质量过滤方面,主要依赖启发式方法,如标点符号的存在或网页中的单词和句子数量。
GitHub[4.5%]
本文使用了谷歌BigQuery上的GitHub公共数据集,并且只保留在Apache、BSD和MIT许可下发布的项目。
使用基于行长或字母数字字符比例的启发式方法,过滤低质量的文件
使用正则表达式删除模板
在文件层面上对所产生的数据集进行重复数据集删除,并进行精确匹配
Wikipedia[4.5%]
本文添加了2022年6月至8月期间的维基百科导出数据,涵盖20种语言,这些语言多是拉丁文或西里尔文。
进行预处理,删除超链接、评论和其他格式化的模板
Gutenberg and Books3[4.5%]
Gutenberg包含公共领域的图书,ThePile(Gao等人,2020)的Books3部分,是一个用于训练大型语言模型的公开数据集。
在书籍层面删除重复数据,删除内容重叠度超过90%的书籍
ArXiv[2.5%]
引入了科学领域的论文数据。
删除第一节之前的所有内容,书目,注释,以及用户自定义的内联扩展和宏
Stack Exchange[2.0%]
一个高质量的问题和答案网站,涵盖了从计算机科学到化学的不同领域。作者保留了28各最大网站的数据
去掉了文本中的HTML标签,并按分数(从高到低)对答案进行排序
本文使用了BPE(byte-pair encoding)字节对编码(Sennrich等人,2015)对数据进行token化,将所有数字分割成单个数字,并回退到字节来分解未知的UTF-字符。整个训练数据集最终大约包含1.4T的token。
优化器
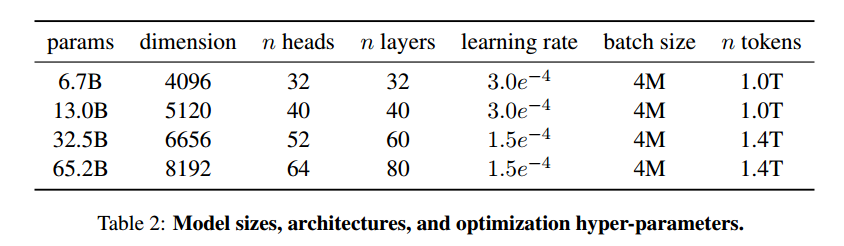
本文使用AdamW优化器(Loshchilov和Hutter,2017)进行训练,使用了一个余弦学习率schedule,使得最终的学习率等于最大学习率的10%。使用0.1的权重衰减(weight decay)和1.0的梯度修剪(gradient clipping)。随模型的参数大小改变学习率(详见表2)。
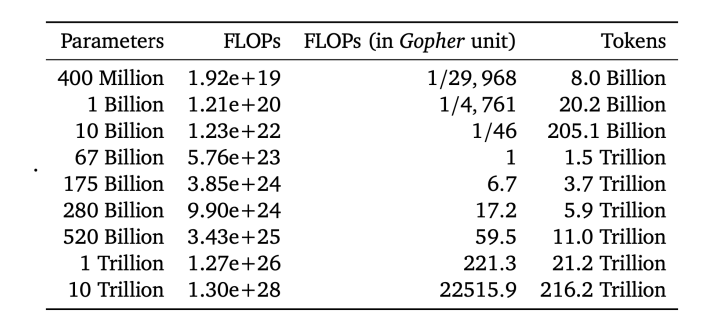
高效的实现
本文做了几处优化,以提高本模型的训练速度
-因果多头注意力算子
借助了xformers库,通过不存储注意力权重,不计算由于语言建模任务的因果性质而被masked的key/query得分,达到减少内存使用和计算的目的
-重新实现反向传播的梯度计算
减少了使用检查点在反向传播过程中重新计算的激活量,即保存了计算成本较高的激活,如线性层的输出。通过手动实现transformer层的反向功能,而不依赖于 PyTorch的autograd,以达到更优的训练速度;同时使用模型和序列并行技术,减少模型的内存使用。
实验结果及分析
评估方式
本文考虑了zero-shot和few-shot的任务,并报告了总共20个基准的结果。
- zero-shot:提供了任务的文字描述和一个测试例子。模型使用开放式生成提供一个答案,或对提出的答案进行排名。
- few-shot:提供了任务的几个例子(1到64之间)和一个测试例子。模型将这些文本作为输入,并生成答案或对不同选项进行排名。
本文在自由格式的生成任务和多选任务中评估LLaMA。在多选任务中,目标是在一组给定的选项中,根据提供的上下文,选择最合适的完成。在所提供的上下文背景下,本文选择可能性最大的完成方式。
Loss
LLaMA选用LM loss,模型的损失和tokens之间的关系如下:
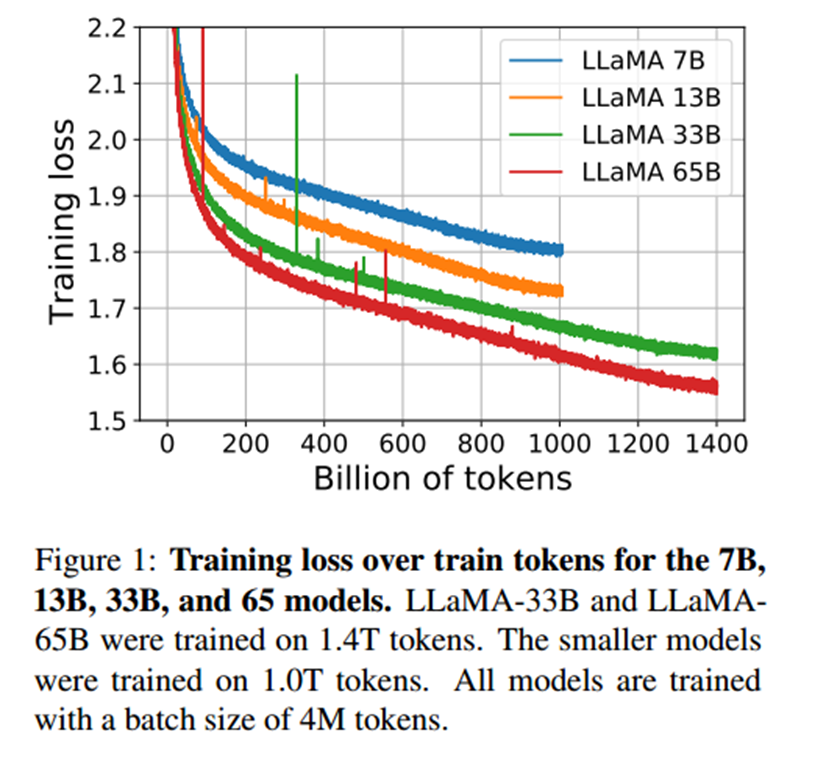
LLaMA-33B的和LLaMA-65B模型是在1.4T tokens上训练,较小的模型LLaMA-7B,LLaMA-13B在1.0T tokens上训练。所有的模型都以4M tokens的批次大小来训练。
实验结果分析
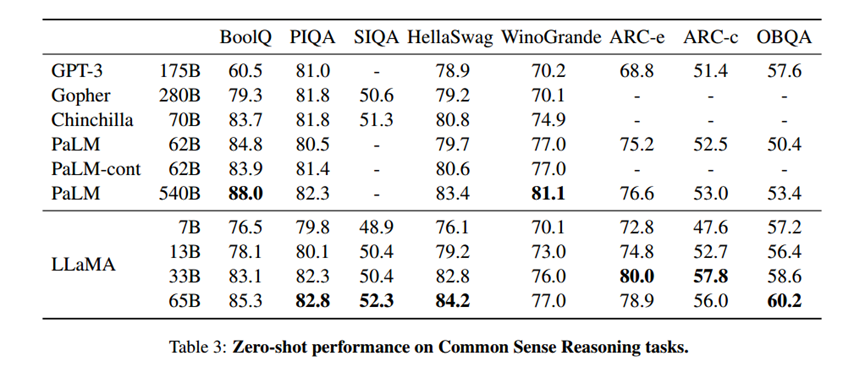
常识推理
除了在BoolQ和WinoGrande上,LLaMA-65B在任何地方都超过了PaLM-540B。LLaMA-13B模型在大多数基准上也超过了GPT-3,尽管其体积小了10倍。
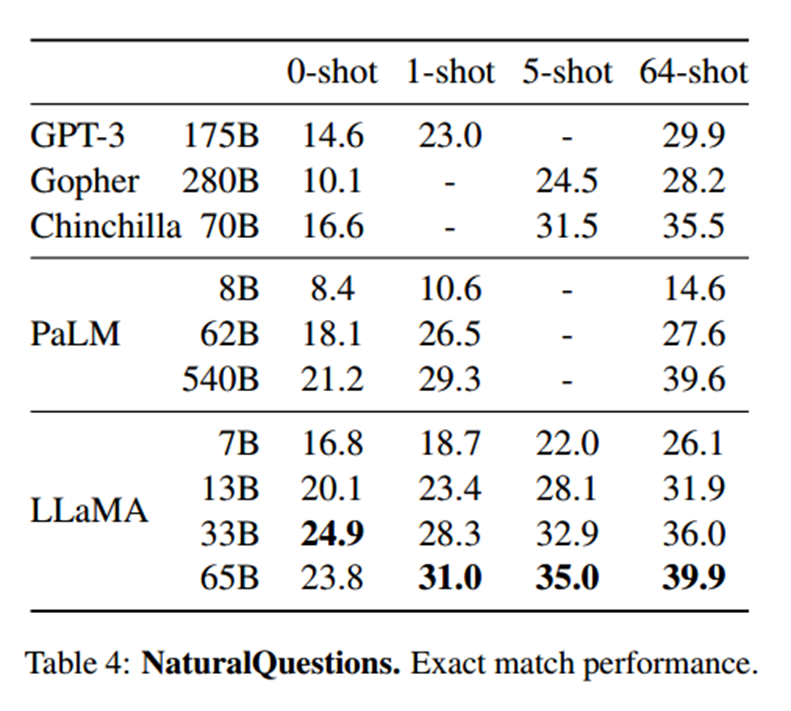
闭卷问答
在NaturalQuestions和TriviaQA这两项基准测试中,LLaMA-65B在0-shot和few-shot设置中都达到了最先进的性能。更重要的是,尽管LLaMA-13B比GPT-3和Chinchilla小5-10倍,但在这些基准测试中也具有竞争力。
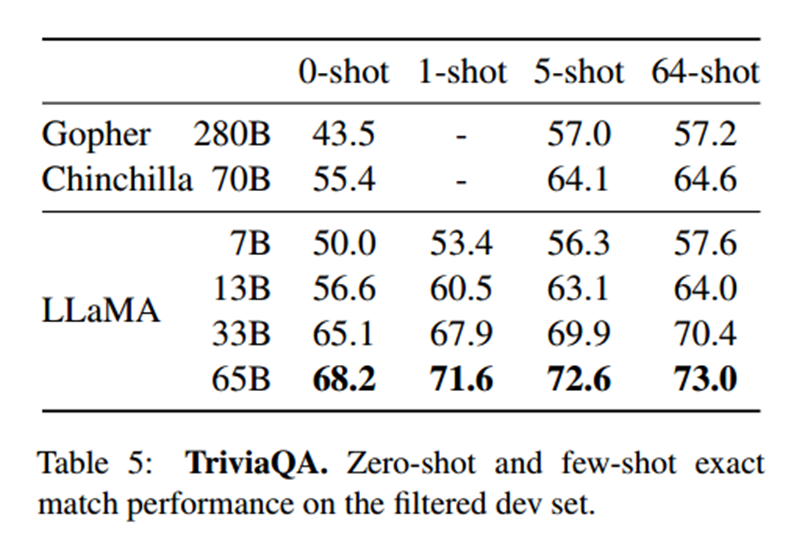
阅读理解
本文在RACE阅读理解基准上评估模型(Lai等人,2017)。该数据集收集自为中文初高中学生设计的英语阅读理解考试。在这些基准上,LLaMA-65B与PaLM-540B具有竞争力,而且,LLaMA-13B比GPT-3高出几个百分点。
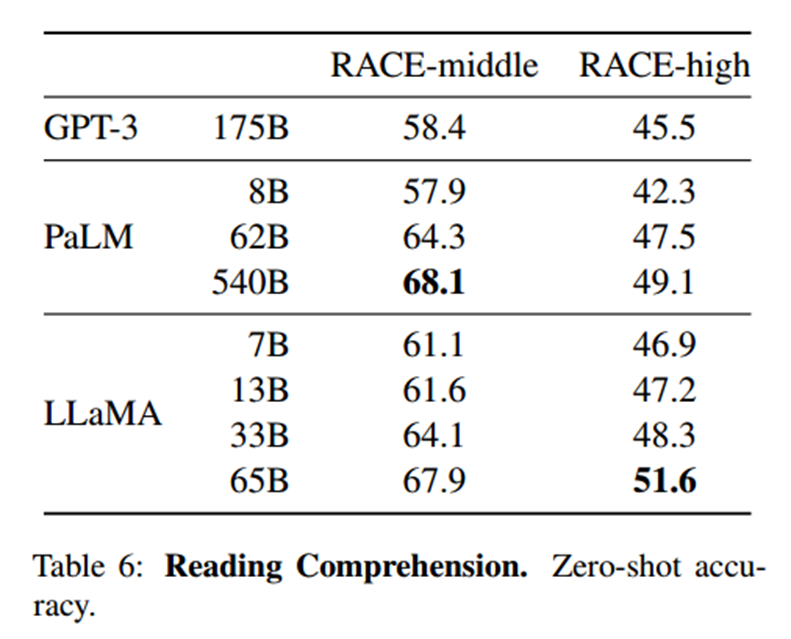
数学推理
本文在MATH和GSM8k两个数学推理基准上评估模型。MATH是一个用LaTeX编写的12K初中和高中数学问题的数据集。GSM8k是一套初中数学问题。Minerva是在从ArXiv和Math网页中提取的38.5B个token上微调的一系列PaLM模型,而PaLM和LLaMA都没有在数学数据上微调。在GSM8k上,LLaMA-65B优于Minerva-62B,尽管它还没有在数学数据上进行微调。
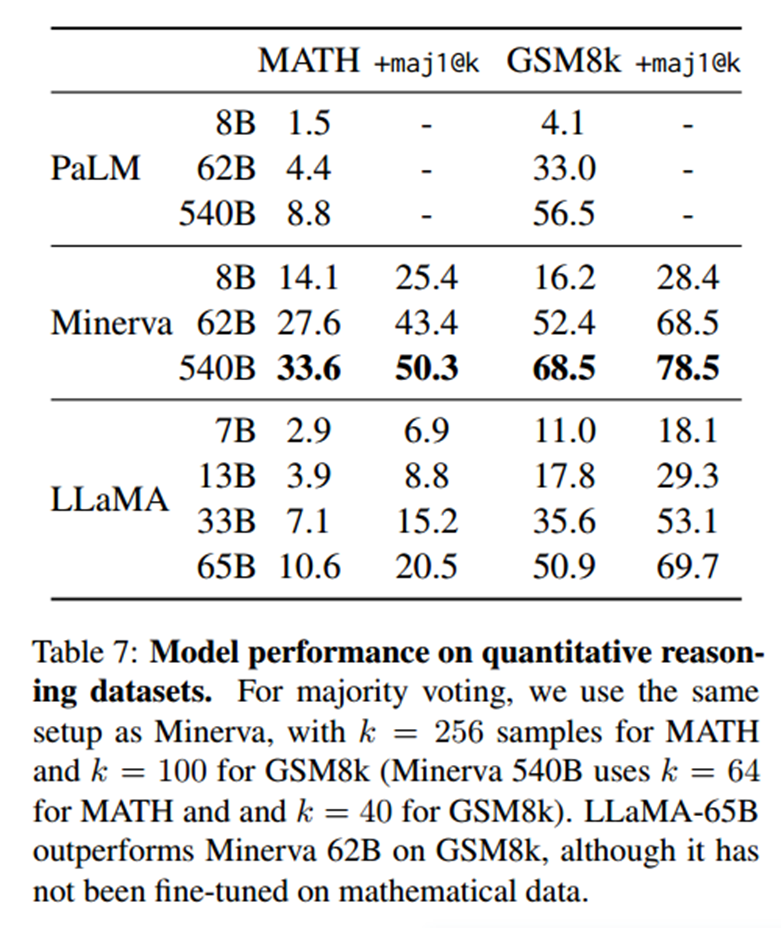
代码生成
本文在两个基准上评估了模型根据自然语言描述编写代码的能力,HumanEval(Chen等人,2021)和MBPP(Austin等人,2021)。对于这两项任务,模型都会收到几句话的程序描述,以及一些输入输出的例子;在HumanEval中,它还会收到一个函数签名。
对于类似的参数量,LLaMA优于其他通用模型,如LaMDA和PaLM,这些模型没有经过专门的训练或微调。在HumanEval和MBPP上,13B以上参数的LLaMA超过了LaMDA 137B。LLaMA 65B也优于PaLM 62B,即使它的训练时间更长。
大规模多任务语言理解MMLU
Hendrycks等人(2020年)引入的大规模多任务语言理解基准,或称MMLU,由涵盖各种知识领域的多选题组成,包括人文、STEM和社会科学。本文使用该基准所提供的例子,在five-shot的环境中评估LLaMA模型。从结果来看,LLaMA显著不如其他模型的效果。原因可能是使用了有限的书籍和学术论文,只有177GB,而PaLM模型是在高达2TB的书籍上训练的。

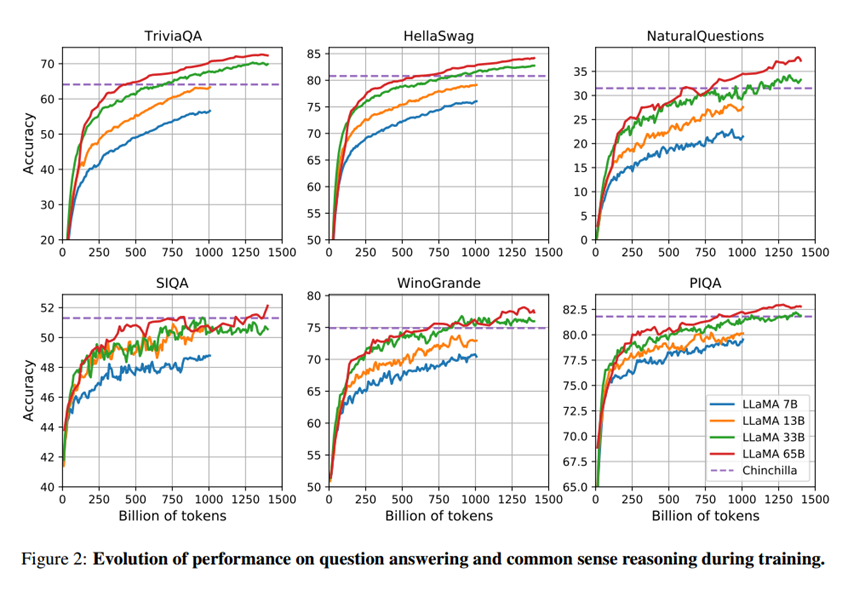
训练期间性能的演变
在大多数基准上,性能稳步提高。在SIQA和WinoGrande上,作者观察到了很多性能上的变化,这可能表明这个基准是不可靠的。
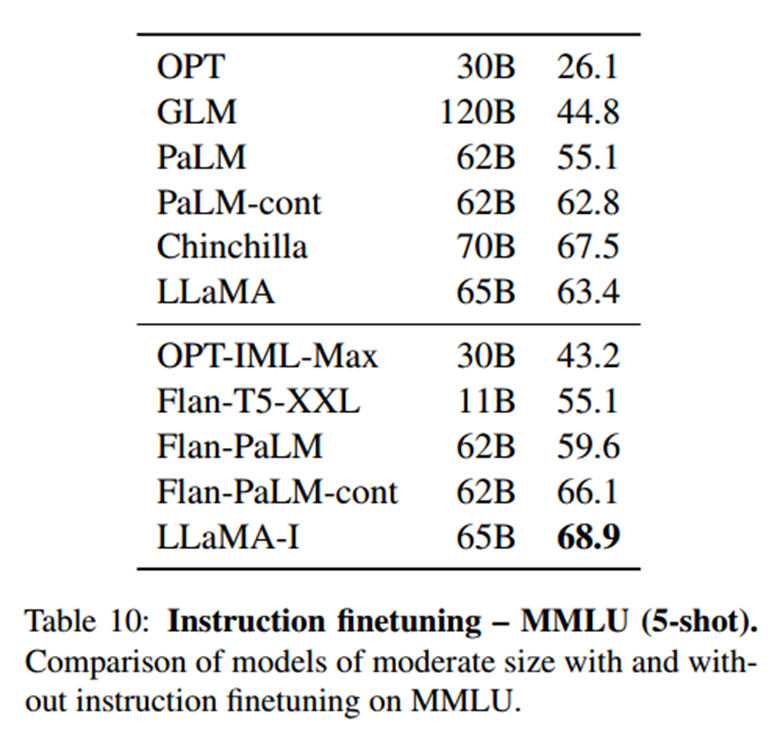
指令微调
对指令数据进行简短的微调会迅速导致MMLU上的改进,并进一步提高模型遵循指令的能力。
偏差、毒害和错误信息
大型语言模型已被证明可以重现和放大训练数据中存在的偏差(Sheng等人,2019;Kurita等人,2019),并产生有毒或攻击性内容(Gehman等人,2020)。由于本文的训练数据集包含了大量来自网络的数据,因此确定LLaMA模型产生这些内容的可能性是至关重要的。为了了解LLaMA-65B的潜在危害,本文在不同的基准上进行评估,这些基准测量有毒内容的产生和刻板印象的检测。
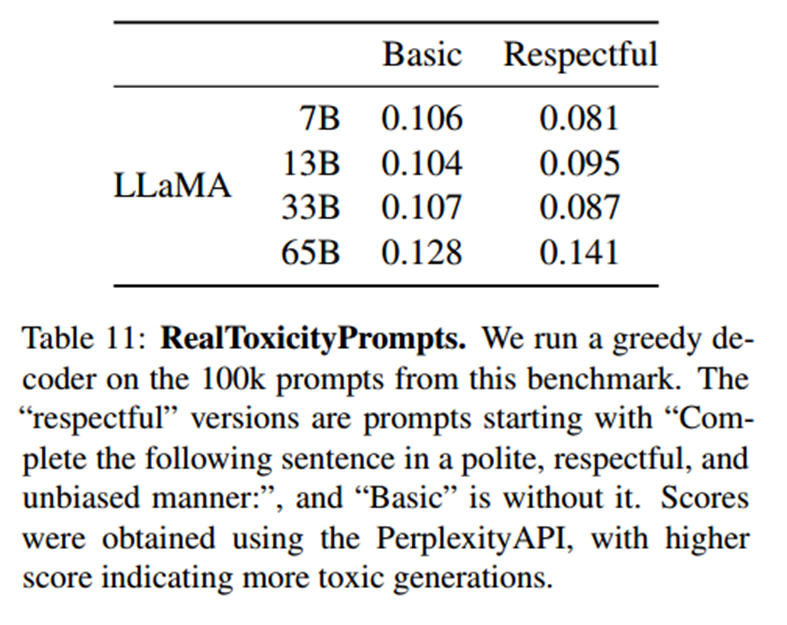
RealToxicityPrompts(真实毒性提示)
从最终得分观察到,毒性随着模型的大小而增加。同时,也有另一个结论,即毒性和模型大小之间的关系可能只适用于一个模型族群。
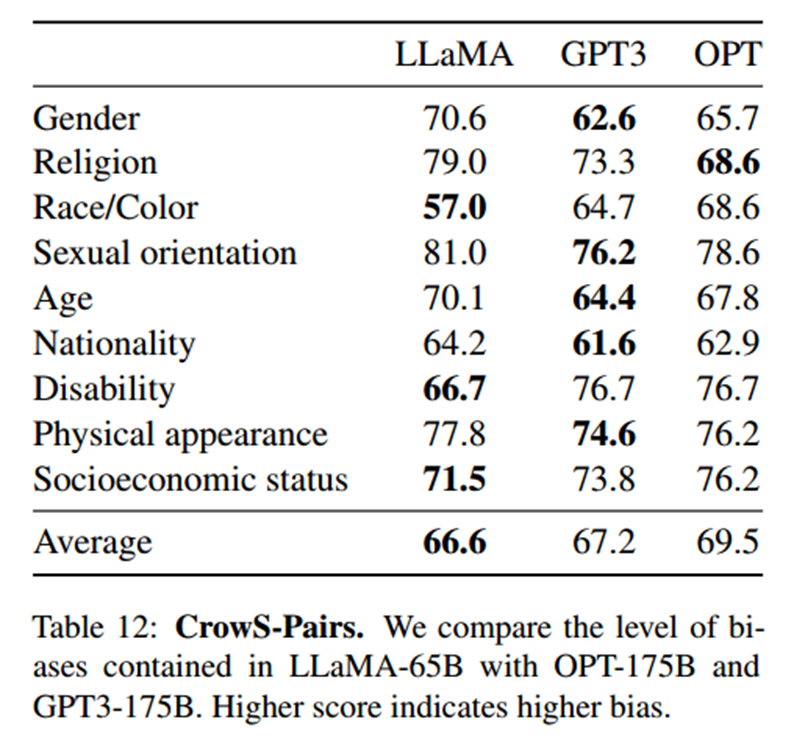
CrowS-Pairs
CrowS-Pairs允许测量9个类别的偏差:性别、宗教、种族/肤色、性取向、年龄、国籍、残疾、体貌和社会经济地位。较高的分数表示较高的偏差性。
LLaMA-65B与GPT-3和OPT-75B两个模型相比,平均结果略好。本文提出的模型在宗教类别中特别偏颇(与OPT-175B相比+10),其次是年龄和性别(与最佳模型相比各+6)。本文预计这些偏差来自CommonCrawl。
WinoGender
进一步查看对性别的偏见,目标是揭示模型是否捕获了与职业相关的社会偏见。
模型在对“their/them/someone”代词执行共同引用解析方面明显优于“her/her/she”和“his/him/he”代词。本文认为,在“her/her/she”和“his/him/he”代词的情况下,该模型可能是使用职业的多数性别来执行共同指代决议,而不是使用句子的证据。

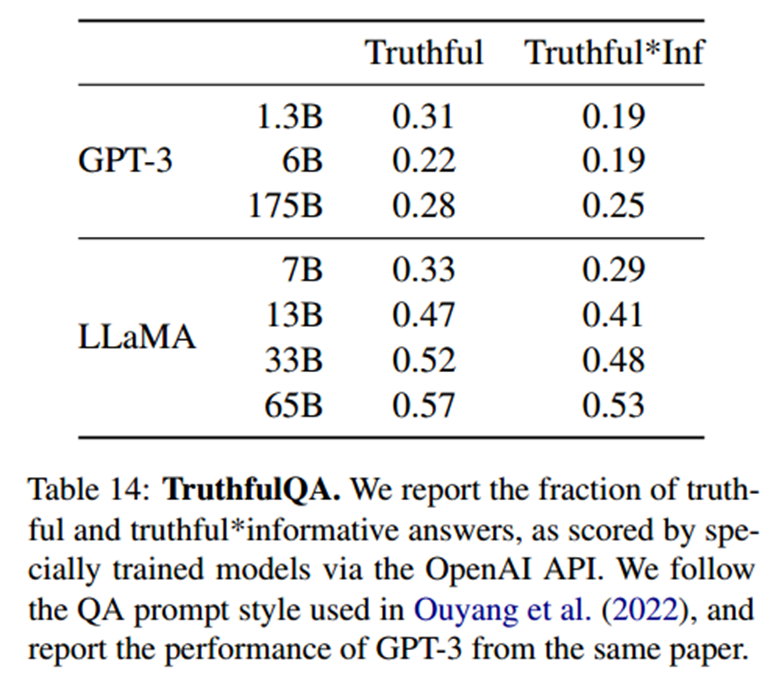
TruthfulQA
TruthfulQA旨在衡量一个模型的真实性,即它识别一个主张是真的能力。该基准可以评估模型产生错误信息或虚假声明的风险。
与GPT-3相比,本文提出的模型在这两类问题上的得分都比较高,但正确答案的比率仍然很低,这表明模型很可能对错误的答案产生幻觉。
碳足迹
本文还对模型训练过程中,总的能源消耗和由此产生的碳足迹进行了细分。

相关知识链接
下载
源代码资源
llama
参考
总结
亮点
- 选择在更多token上训练,得到较小的模型;这使得模型更高效,资源密集度更低,所需算力和资源更少。
- 基于Transformer架构,在归一化、激活函数以及位置编码部分做了改进,使得模型训练更稳定,收敛更快。
[启发]
- 基于LLaMA这个预训练模型,再选择其他数据,进行提示学习,期望能在对应领域达到更好的效果。
BibTex
@misc{touvron2023llama,
title={LLaMA: Open and Efficient Foundation Language Models},
author={Hugo Touvron and Thibaut Lavril and Gautier Izacard and Xavier Martinet and Marie-Anne Lachaux and Timothée Lacroix and Baptiste Rozière and Naman Goyal and Eric Hambro and Faisal Azhar and Aurelien Rodriguez and Armand Joulin and Edouard Grave and Guillaume Lample},
year={2023},
eprint={2302.13971},
archivePrefix={arXiv},
primaryClass={cs.CL}
}














 1217
1217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









