







AlexNet原理理解及实验复现
原文理解
网络结构
AlexNet的网络结构由5个卷积层和3个全连接层组成,5个卷积层的卷积核的大小从第一层到第五层分别为11×11×3(原始图像大小为224×224×3)、5×5×96(如果是两个GPU并行训练则每个GPU处理48通道)、3×3×256、3×3×384、3×3×384,第二层的输入以第一层的输出经过局部响应归一化(LRN)和最大池化(Max Pooling)后的输出作为输入,第三层同理。经过这些卷积层,图片中的特征被由浅到深地提取出来,而LRN和Max Pooling使得模型能在训练过程中保留重要特征,增强特征的区分性并减少过拟合。
由于训练任务是对包含1000个类别的ILSVRC数据集执行分类任务,所以最后需要三层全连接层将卷积层提取的高维空间特征压缩为全局语义向量,并通过Softmax将4096维向量映射到1000个类别概率。
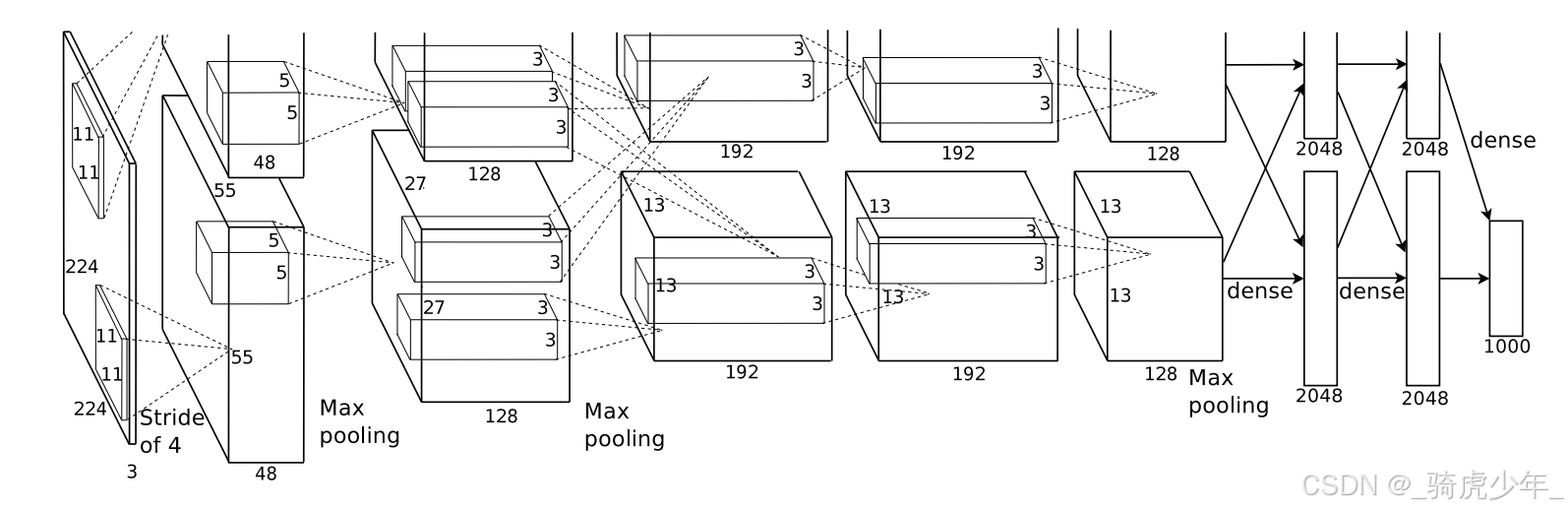
图1:AlexNet的模型结构

图2:第一层卷积层的可视化结果
可以看出,经过训练后的卷积核学习到了图片中的纹理和边缘特征。
避免过拟合的方法
在AlexNet的原文中共提到了以下几种防止过拟合的方法:
模型设计方面,在卷积、池化层使用了局部响应归一化(LRN)和重叠池化层。
数据预处理方面,采用了图像平移和水平翻转(Translation and Horizontal Reflection)和RGB通道强度变化(RGB Intensity Alteration)方法进行训练数据的扩充和增强。
训练方法方面,采用了Dropout机制防止在训练过程中的过拟合。
(一)数据增强
1. 图像平移和水平翻转
原理:
原始图片大小为256×256,训练时随机裁剪出224×224的小块(位置随机),并随机进行水平翻转(镜像)。这样每张原图可生成大量不同视角的样本(例如,不同位置、不同方向),相当于将数据量扩大了2048倍。
测试时的处理:
预测时,对每张测试图片裁剪出5个固定区域(四个角和中心),每个区域再做水平翻转,共得到10个样本。最终预测结果是这10个样本的平均结果。
作用:
让模型学会关注物体的本质特征,而不是位置或方向,从而提高鲁棒性。
2. RGB通道强度变化
通过改变RGB通道的强度来生成新的训练样本。具体来说,对RGB通道的像素值进行调整,模拟不同光照条件下的图像变化。
这种调整是基于RGB通道的主成分分析(PCA)结果实现的。
具体实现:
PCA分析:首先对整个ImageNet训练集的RGB像素值进行主成分分析(PCA),得到RGB通道的主成分和对应的方差。
强度调整:对于每张训练图像,根据PCA结果,对每个像素的RGB值进行调整。具体公式如下:
new_pixel = pixel + ∑ i = 1 3 α i ⋅ λ i ⋅ p i \text{new\_pixel} = \text{pixel} + \sum_{i=1}^{3} \alpha_i \cdot \lambda_i \cdot p_i new_pixel=pixel+i=1∑3αi⋅λi⋅pi
其中:
- pixel \text{pixel} pixel是原始像素值。
- α i \alpha_i αi是从高斯分布 N(0, 0.1) 中随机采样的值。
- λ i \lambda_i λi 是第i个主成分的方差。
- p i \ p_i pi 是第i个主成分向量。
作用:
模拟光照变化:通过调整RGB通道的强度,模型可以学习到在不同光照条件下的图像特征,从而提高对光照变化的鲁棒性。
减少过拟合:这种数据增强方法增加了训练数据的多样性,使得模型更不容易过拟合。
提高分类性能:实验表明,这种调整可以将模型的top-1错误率降低超过1%。

如图,通过对每一类别的图像数据进行增强,模拟位置、方向、光照的变化,使模型适应现实世界中复杂的视觉条件。
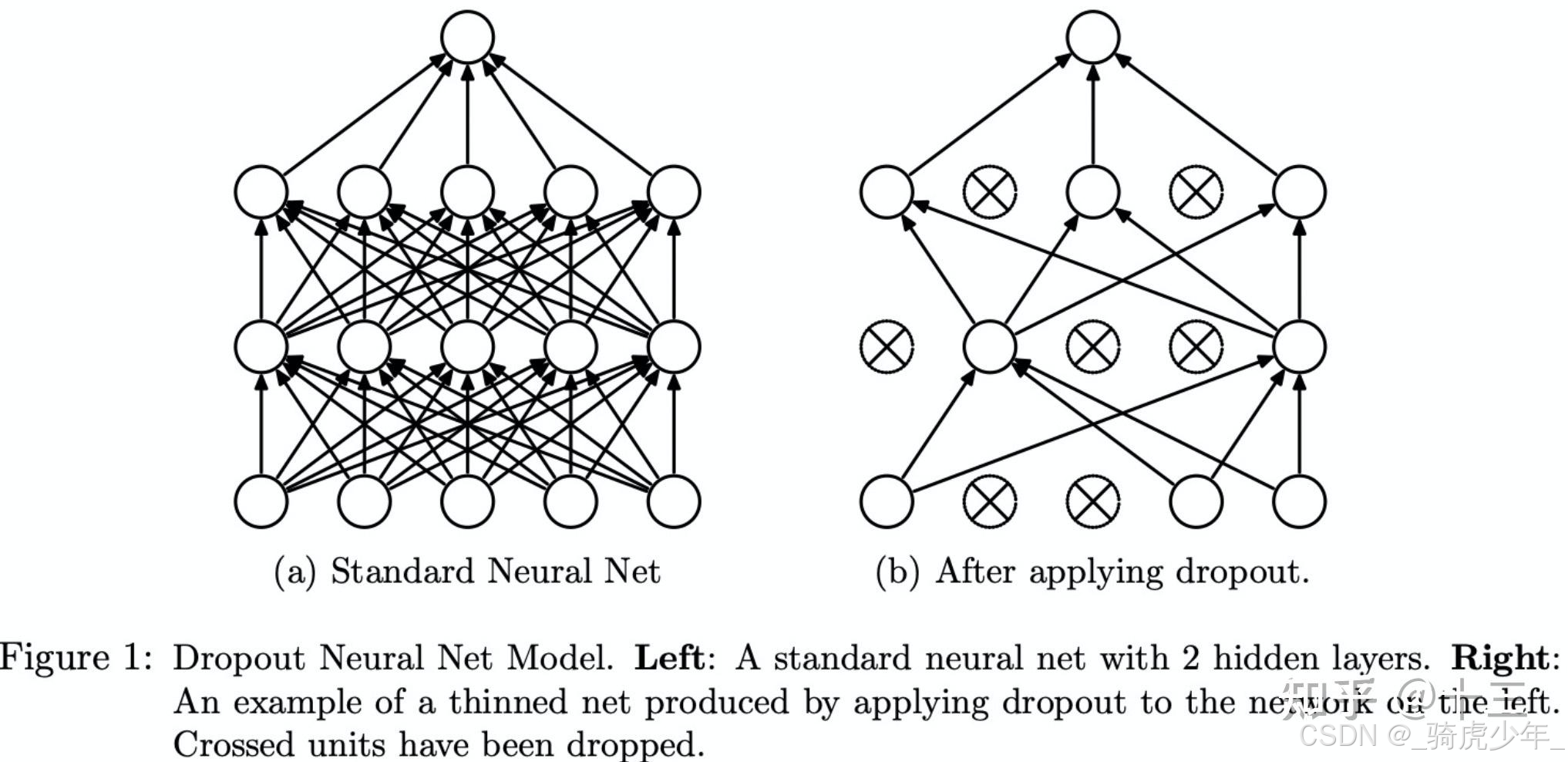
(二)Dropout
Dropout机制可以理解为一种“随机让部分神经元罢工”的方法,目的是防止神经网络过度依赖某些局部特征,从而提高泛化能力。
AlexNet在全连接层(尤其是最后两层)使用Dropout,因为全连接层参数占整个网络的95%以上,最容易过拟合。通过随机丢弃,模型在ImageNet数据集上的错误率显著降低。
在训练阶段,每次迭代随机丢弃50%的神经元后,只更新活跃神经元的参数,被关闭的神经元参数保持不变,在测试阶段,所有神经元恢复工作,但每个神经元的输出会乘以0.5(假设训练时丢弃率50%),这是为了平衡训练时只有一半神经元参与计算的期望值。
(三)局部响应归一化和重叠池化
局部响应归一化
LRN的灵感来源于神经生物学中的“侧抑制”现象:活跃的神经元会抑制周围神经元的活动。在AlexNet中,LRN被用在卷积层之后(ReLU激活函数之后),目的是让显著的特征更突出,同时抑制不重要的特征,从而增强模型的泛化能力。
具体的做法是,对每个特征图的像素值,横向比较相邻通道(即不同卷积核的输出)的响应值,公式为:
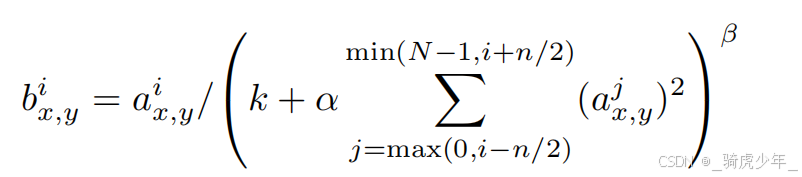
其中
a
x
,
y
i
a^i_{x,y}
ax,yi是第i个通道在位置(x,y)的激活值,n是相邻通道数,N为卷积层中的卷积核数量,k,α,β是超参数。
LRN后来被更高效的Batch Normalization(BN)取代,但它在AlexNet中使错误率降低了1.2%,并首次验证了“归一化”对深度网络的重要性。
重叠池化
传统池化(如2×2池化核,步长2)不重叠,而AlexNet采用3×3池化核,步长2,在最大池化的计算方式基础上使相邻池化窗口有部分重叠,通过更密集的采样,避免模型过度依赖局部特征,同时保留更多空间信息,对后续分类更有利。
网络训练加速的机制
使用ReLU作为激活函数以及恰当地设置训练参数的初始值是加速训练的方法,也是该论文的创新点之一。
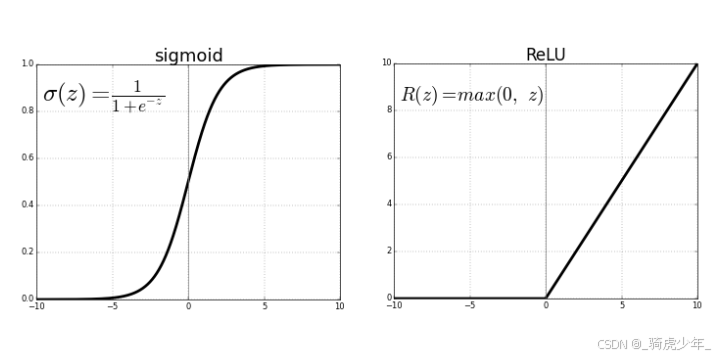
为什么用ReLU
早期神经网络常用
tanh
\text{tanh}
tanh或
sigmoid
\text{sigmoid}
sigmoid作为激活函数,而在反向传播过程中,激活函数也要参与梯度计算,这些函数在输入值较大时梯度趋近于零(饱和区),导致反向传播时梯度消失,导致深层网络中参数难以更新。
ReLU定义为f(x)=max(0,x),当输入为正时,梯度恒为1;输入为负时,梯度为0。这种非饱和特性使得正向传播时神经元不易饱和,反向传播时梯度能有效传递,尤其适合深层网络的训练,同时减少了神经元之间的耦合性,使网络更高效地学习特征。
如何设置训练初始值
由于上述ReLU函数的特点(当输入为正时,梯度恒为1;输入为负时,梯度为0),所有权重(卷积层和全连接层的权重矩阵)从均值为0、标准差为0.01的高斯分布中随机初始化。第二、第四、第五卷积层和全连接层的偏置初始化为常数1。其他层(如第一、第三卷积层)的偏置初始化为常数0,权重则初始化为0.01,并在结束训练前降低三次。
这样做的原因是ReLU在输入为负时输出0,可能导致部分神经元“死亡”。较小的权重初始化值使初始阶段大部分输入接近0,但仍有一定概率为正。将偏置初始化为1,相当于为每个神经元的输入增加了一个正偏移量,保证神经元能被激活,促进梯度反向传播。
实验复现
数据集下载
训练集链接: ILSVRC2012_img_train.tar
验证集链接:ILSVRC2012_img_val.tar
Dev_kit:ILSVRC2012_devkit_t12.tar.gz
数据集预处理
在完成下载和解压后,由于初始验证集没有分为与训练集对应的1000类,需要先进行分类后才能使用,在修改路径后执行下列的python脚本即可完成分类。
import scipy.io
import shutil
import os
def move_valimg(val_dir='./val', devkit_dir='./ILSVRC2012_devkit_t12'):
"""
将验证集图片移动到对应的类别文件夹中。
"""
# 加载类别信息和验证集标签
synset = scipy.io.loadmat(os.path.join(devkit_dir, 'data', 'meta.mat'))
ground_truth = open(os.path.join(devkit_dir, 'data', 'ILSVRC2012_validation_ground_truth.txt'))
lines = ground_truth.readlines()
labels = [int(line[:-1]) for line in lines]
# 遍历验证集图片
root, _, filenames = next(os.walk(val_dir))
for filename in filenames:
val_id = int(filename.split('.')[0].split('_')[-1]) # 获取图片的ID
ILSVRC_ID = labels[val_id - 1] # 获取对应的类别ID
WIND = synset['synsets'][ILSVRC_ID - 1][0][1][0] # 获取对应的类别名称
# 创建对应的类别文件夹
output_dir = os.path.join(root, WIND)
if not os.path.isdir(output_dir):
os.mkdir(output_dir)
# 移动图片到对应的类别文件夹
shutil.move(os.path.join(root, filename), os.path.join(output_dir, filename))
if __name__ == '__main__':
val_dir = './Data/val' # 将此处改为解压后的验证集目录
devkit_dir = './ILSVRC2012_devkit_t12' # 将此处改为解压后的开发工具包目录
move_valimg(val_dir, devkit_dir)
模型搭建
1.设置基本参数,如模型的训练轮次、batchsize等
import os
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils import data
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from tensorboardX import SummaryWriter
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 超参数(严格按论文设置)
NUM_EPOCHS = 90 #训练轮次
BATCH_SIZE = 128 #一次训练中所使用的样本数量
MOMENTUM = 0.9 #动量
WEIGHT_DECAY = 0.0005 #权重衰减
BASE_LR = 0.01 #初始学习率
IMAGE_DIM = 224 #训练图像尺寸224*224
NUM_CLASSES = 1000 #训练样本分为1000类
DEVICE_IDS = [0, 1] # 使用两个GPU
# PCA参数(需替换为实际计算的ImageNet参数)
PCA_EIG_VAL = torch.tensor([0.2175, 0.0188, 0.0045]) # 示例值
PCA_EIG_VEC = torch.tensor([
[-0.5675, 0.7192, 0.4009],
[-0.5808, -0.0045, -0.8140],
[-0.5836, -0.6948, 0.4203]
]) # 示例值
root = './ILSVRC/Data/CLS-LOC/' #下载并解压训练数据集后的存放路径
OUTPUT_DIR = 'alexnet_data_out' #训练日志及模型存放路径
LOG_DIR = os.path.join(OUTPUT_DIR, 'tblogs') #日志存放路径
CHECKPOINT_DIR = os.path.join(OUTPUT_DIR, 'models') #模型存放路径
os.makedirs(CHECKPOINT_DIR, exist_ok=True)
2.数据增强模块:原文提到了两种数据增强策略,分别是图片裁剪翻转和PCA扰动。
PCA:
PCA颜色扰动是一种基于主成分分析(Principal Component Analysis, PCA)的颜色变换方法,其主要思想是通过调整图像颜色的主要变化方向来生成新的训练样本,从而模拟真实世界中的光照条件变化。
初始化 (init 方法):在这个方法中,定义了PCA的特征向量(eig_vec)和特征值(eig_val),它们代表了图像颜色空间的主成分。此外,还有一个参数 alpha_std 用于控制扰动的强度,它决定了从标准正态分布中采样的尺度。
调用 (call 方法):这个方法对输入的图像张量进行实际的扰动操作。首先,根据设定的标准差 alpha_std 随机生成三个数值(对应RGB三通道)。然后,使用这些随机数、特征值和特征向量计算出一个扰动矩阵,并将其加到原始图像上。最后,通过 torch.clamp 函数确保像素值保持在 [0, 1] 范围内。
裁切翻转:
十裁切技术是指在模型验证阶段,从每个图像中提取多个裁剪图并对其进行预测,以增加评估的准确性。具体实现包括五种不同的裁剪位置加上它们各自水平翻转后的版本。
初始化 (init 方法):这里初始化了一个 FiveCrop 变换对象,该对象可以对输入图像执行五个不同位置的中心裁剪。
调用 (call 方法):此方法首先使用 five_crop 对输入图像执行五次裁剪,得到五个不同的图像块。然后,对这五个裁剪结果分别进行水平翻转(hflip),产生另外五个图像块。最终,将原始裁剪和翻转后的裁剪合并为一个包含十个图像块的元组返回。
class PCAPerturbation:
"""PCA颜色扰动"""
def __init__(self, eig_vec, eig_val, alpha_std=0.1):
self.alpha_std = alpha_std
self.eig_vec = eig_vec
self.eig_val = eig_val
def __call__(self, tensor):
alpha = torch.randn(3) * self.alpha_std
perturbation = torch.mv(self.eig_vec, self.eig_val * alpha)
perturbation = perturbation.view(3, 1, 1)
return torch.clamp(tensor + perturbation, 0, 1)
class TenCropWithFlip:
"""模型验证时生成10个补丁(5位置+翻转)"""
def __init__(self):
self.five_crop = transforms.FiveCrop(IMAGE_DIM)
def __call__(self, img):
crops = list(self.five_crop(img)) # 转为列表
flipped = [transforms.functional.hflip(c) for c in crops] # 修正拼写错误
return tuple(crops + flipped) # 合并后转为元组
在模型训练阶段,则采用的是随机裁切和随机翻转加上PCA扰动,以扩大训练集的样本量,从而提高训练效果。
train_transform = transforms.Compose([
transforms.Resize(256),
transforms.RandomResizedCrop(IMAGE_DIM), # 随机裁剪
transforms.RandomHorizontalFlip(), # 随机翻转
transforms.ToTensor(),
PCAPerturbation(PCA_EIG_VEC, PCA_EIG_VAL, alpha_std=0.1), # 先做扰动
normalize # 后做标准化
])
3.按原文中的模型结构进行定义以及定义对权重偏置作初始化的方法:
# ------------------- 模型定义 -------------------
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(3, 96, 11, stride=4, padding=2), # 输出55x55的特征图
nn.ReLU(inplace=True),
nn.LocalResponseNorm(5, alpha=1e-4, beta=0.75, k=2),
nn.MaxPool2d(3, 2), # 55→27
nn.Conv2d(96, 256, 5, padding=2),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(5, alpha=1e-4, beta=0.75, k=2),
nn.MaxPool2d(3, 2), # 27→13
nn.Conv2d(256, 384, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 384, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, 3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2), # 13→6
)
self.classifier = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(256*6*6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
self.init_weights()
def init_weights(self):
for layer in self.net:
if isinstance(layer, nn.Conv2d):
# 使用Kaiming初始化(适配ReLU)
nn.init.kaiming_normal_(layer.weight, mode='fan_in', nonlinearity='relu')
nn.init.constant_(layer.bias, 0) # 所有卷积层偏置初始化为0
for module in self.classifier:
if isinstance(module, nn.Linear):
nn.init.normal_(module.weight, 0, 0.01) # 保持原论文全连接层初始化
nn.init.constant_(module.bias, 1) if module in [self.classifier[1], self.classifier[4]] else 0
def forward(self, x):
x = self.net(x)
x = x.view(x.size(0), 256*6*6)
return self.classifier(x)
4.训练、验证数据集的加载:
def data_loader(root, batch_size):
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) #通道标准化
# 训练集转换
# 修正训练集转换顺序
train_transform = transforms.Compose([
transforms.Resize(256),
transforms.RandomResizedCrop(IMAGE_DIM), # 随机裁剪
transforms.RandomHorizontalFlip(), # 随机翻转
transforms.ToTensor(),
PCAPerturbation(PCA_EIG_VEC, PCA_EIG_VAL, alpha_std=0.1), # 先做扰动
normalize # 后做标准化
])
# 验证集转换
val_transform = transforms.Compose([
transforms.Resize(256),
TenCropWithFlip(), # 十裁切
transforms.Lambda(lambda crops: [transforms.ToTensor()(c) for c in crops]),
transforms.Lambda(lambda crops: [normalize(c) for c in crops])
])
# 数据集
train_dataset = datasets.ImageFolder(os.path.join(root, 'train'), train_transform)
val_dataset = datasets.ImageFolder(os.path.join(root, 'val'), val_transform)
# 自定义collate_fn处理多补丁
def collate_fn(batch):
imgs = [item[0] for item in batch] # 每个item的imgs是10个补丁的列表
labels = [item[1] for item in batch]
# 堆叠为 [batch_size, 10, C, H, W]
imgs_tensor = torch.stack([torch.stack(patch) for patch in imgs])
labels_tensor = torch.tensor(labels)
return imgs_tensor, labels_tensor
train_loader = data.DataLoader(
train_dataset, batch_size=batch_size, shuffle=True, num_workers=4, pin_memory=True)
val_loader = data.DataLoader(
val_dataset, batch_size=max(1, batch_size//10),
collate_fn=collate_fn, num_workers=4, pin_memory=True)
return train_loader, val_loader
5.定义训练循环,并在每一轮训练结束时进行验证,计算loss值与进行学习率调整:
在原文中采用的是当前学习率下当验证误差不再改变时调整学习率,但实际训练过程中发现,这样做会使得梯度下降过慢,模型难以收敛。所以学习率调整策略就改成了每30轮下降一次,每次除以10。
# ------------------- 训练循环 -------------------
if __name__ == '__main__':
# 初始化
torch.manual_seed(42)
os.environ['CUDA_LAUNCH_BLOCKING'] = '1' # 调试CUDA错误
torch.backends.cudnn.benchmark = True # 启用cuDNN优化
tbwriter = SummaryWriter(log_dir=LOG_DIR)
# 数据加载
train_loader, val_loader = data_loader(root, BATCH_SIZE)
# 模型
alexnet = AlexNet(NUM_CLASSES).to(device)
if torch.cuda.device_count() > 1:
alexnet = nn.DataParallel(alexnet, device_ids=DEVICE_IDS)
# 优化器
optimizer = optim.SGD(
alexnet.parameters(),
lr=BASE_LR,
momentum=MOMENTUM,
weight_decay=WEIGHT_DECAY)
# 学习率调整
best_val_acc = 0.0
current_lr = BASE_LR
lr_decay_count = 0 # 新增计数器
patience = 5 # 连续5个epoch验证准确率未提升时降低学习率
#no_improve_epochs = 0
# 训练循环
for epoch in range(NUM_EPOCHS):
alexnet.train()
train_loss = 0.0
for imgs, labels in train_loader:
imgs, labels = imgs.to(device), labels.to(device)
# 前向传播
outputs = alexnet(imgs)
loss = F.cross_entropy(outputs, labels)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item() * imgs.size(0)
# 验证阶段
alexnet.eval()
val_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for imgs_list, labels in val_loader:
imgs_list, labels = imgs_list.to(device), labels.to(device)
batch_size, num_crops, C, H, W = imgs_list.shape
# 合并补丁维度
combined_imgs = imgs_list.view(-1, C, H, W)
outputs = alexnet(combined_imgs)
outputs = outputs.view(batch_size, num_crops, -1)
# 平均概率
avg_logits = outputs.mean(dim=1) # [batch, num_crops, classes] → [batch, classes]
loss = F.cross_entropy(avg_logits, labels)
val_loss += loss.item() * batch_size
_, preds = torch.max(avg_logits, 1)
correct += (preds == labels).sum().item()
total += batch_size
# 计算指标
train_loss /= len(train_loader.dataset)
val_loss /= total
val_acc = correct / total
# 学习率调整
new_lr = BASE_LR * (0.1 ** (epoch // 30)) # 0-29: 0.01, 30-59:0.001, 60-89:0.0001
if new_lr < current_lr:
lr_decay_count += 1
print(f"Learning rate reduced to {new_lr:.4f} (Decay count: {lr_decay_count}/3)")
current_lr = new_lr # 更新当前学习率记录
for param_group in optimizer.param_groups:
param_group['lr'] = new_lr
# 记录日志
tbwriter.add_scalar('train/loss', train_loss, epoch)
tbwriter.add_scalar('val/loss', val_loss, epoch)
tbwriter.add_scalar('val/acc', val_acc, epoch)
print(f'Epoch [{epoch+1}/{NUM_EPOCHS}] '
f'Train Loss: {train_loss:.4f} | Val Loss: {val_loss:.4f} | Val Acc: {val_acc:.2%}')
# 保存检查点
checkpoint = {
'epoch': epoch,
'state_dict': alexnet.state_dict(),
'optimizer': optimizer.state_dict(),
'val_acc': val_acc
}
torch.save(checkpoint, os.path.join(CHECKPOINT_DIR, f'checkpoint_{epoch}.pth'))
tbwriter.close()
模型训练
训练环境为在线训练平台上的RTX 4090单卡,PyTorch 2.3.0、Cuda 12.1,在训练过程中,根据训练情况调整了原文设置中的一些初始值。
问题分析与代码改进
刚开始为了与原文的初始化方法保持一致,即将第二、第四、第五卷积层和全连接层的偏置初始化为常数1。其他层(如第一、第三卷积层)的偏置初始化为常数0,权重则初始化为0.01,初始化部分的代码为:
def init_weights(self):
for layer in self.net:
if isinstance(layer, nn.Conv2d):
nn.init.normal_(layer.weight, mean=0, std=0.01)
if layer in [self.net[4], self.net[10], self.net[12]]: # 第2、4、5卷积层
nn.init.constant_(layer.bias, 1)
else:
nn.init.constant_(layer.bias, 0)
for module in self.classifier:
if isinstance(module, nn.Linear):
nn.init.normal_(module.weight, mean=0, std=0.01)
if module in [self.classifier[1], self.classifier[4]]: # 前两个全连接层
nn.init.constant_(module.bias, 1)
else:
nn.init.constant_(module.bias, 0)
但使用这种初始化策略的训练日志输出为:
Epoch [1/90] Train Loss: 6.9095 | Val Loss: 6.9078 | Val Acc: 0.10%
Epoch [2/90] Train Loss: 6.9069 | Val Loss: 6.9078 | Val Acc: 0.10%
Epoch [3/90] Train Loss: 6.9065 | Val Loss: 6.9078 | Val Acc: 0.10%
Epoch [4/90] Train Loss: 6.9063 | Val Loss: 6.9078 | Val Acc: 0.10%
Epoch [5/90] Train Loss: 6.9063 | Val Loss: 6.9078 | Val Acc: 0.10%
后面几轮训练的验证集准确度也维持在0.10%,有可能是训练过程中发生了梯度消失问题。
为了确认这一问题,在训练循环中添加梯度监控代码:
# 监控梯度
total_grad_norm = 0.0
for name, param in alexnet.named_parameters():
if param.grad is not None:
total_grad_norm += param.grad.norm().item() ** 2
total_grad_norm = total_grad_norm ** 0.5
print(f"Gradient Norm: {total_grad_norm:.4f}") # 正常范围:1e3~1e5
输出的部分结果为:
Gradient Norm: 0.1586
Gradient Norm: 0.1520
Gradient Norm: 0.1590
Gradient Norm: 0.1599
Gradient Norm: 0.1541
Gradient Norm: 0.1539
Gradient Norm: 0.1574
Gradient Norm: 0.1504
Gradient Norm: 0.1494
Gradient Norm: 0.1481
Gradient Norm: 0.1564
Gradient Norm: 0.1523
Gradient Norm: 0.1515
Gradient Norm: 0.1492
Gradient Norm: 0.1598
Gradient Norm: 0.1542
Gradient Norm: 0.1580
Gradient Norm: 0.1530
最终值停留在0.15左右,说明反向传播梯度消失,模型的参数更新失效。
原因分析:
AlexNet原文中使用的初始化方法相对简单,通常是对权重进行正态分布初始化,并且偏置项设置为常数值(例如0或1)。这种方法没有特别考虑到激活函数对信号传播的影响,因此在更深的网络中可能会遇到梯度消失的问题。特别是在使用ReLU激活函数时,由于ReLU将负值截断为零,这可能导致某些神经元在早期训练阶段无法被激活,进而导致梯度消失的问题。
Kaiming初始化:
Kaiming初始化通过仔细选择权重的标准差来平衡每层的输出方差,确保在网络较深的情况下,梯度能够有效地传递到每一层,从而避免梯度消失的问题。Kaiming初始化通过对权重进行更合理的初始化,确保了每层输出的方差与输入相近,从而有效缓解了梯度消失问题,使得模型能够正常收敛。而AlexNet原文中的初始化方法则缺乏这种针对激活函数特性的调整,因此在更深的网络结构中容易遇到梯度消失的问题。
所以最终在init_weight方法中采用了
nn.init.kaiming_normal_(layer.weight, mode='fan_in', nonlinearity='relu')
训练过程及结果分析
训练过程输出如下:
Epoch [1/90] Train Loss: 5.9246 | Val Loss: 4.8583 | Val Acc: 9.71%
Epoch [2/90] Train Loss: 4.7814 | Val Loss: 4.0206 | Val Acc: 19.55%
Epoch [3/90] Train Loss: 4.3130 | Val Loss: 3.6351 | Val Acc: 25.08%
Epoch [4/90] Train Loss: 4.0596 | Val Loss: 3.4478 | Val Acc: 28.31%
Epoch [5/90] Train Loss: 3.9004 | Val Loss: 3.2166 | Val Acc: 31.38%
Epoch [6/90] Train Loss: 3.8000 | Val Loss: 3.1365 | Val Acc: 33.47%
Epoch [7/90] Train Loss: 3.7248 | Val Loss: 3.0658 | Val Acc: 34.45%
Epoch [8/90] Train Loss: 3.6711 | Val Loss: 3.0507 | Val Acc: 34.96%
Epoch [9/90] Train Loss: 3.6326 | Val Loss: 3.0503 | Val Acc: 34.40%
Epoch [10/90] Train Loss: 3.6001 | Val Loss: 2.9941 | Val Acc: 36.14%
Epoch [11/90] Train Loss: 3.5747 | Val Loss: 3.0514 | Val Acc: 34.77%
Epoch [12/90] Train Loss: 3.5536 | Val Loss: 2.9708 | Val Acc: 36.33%
Epoch [13/90] Train Loss: 3.5359 | Val Loss: 2.9312 | Val Acc: 37.27%
Epoch [14/90] Train Loss: 3.5182 | Val Loss: 2.8785 | Val Acc: 37.67%
Epoch [15/90] Train Loss: 3.5086 | Val Loss: 2.8238 | Val Acc: 38.23%
Epoch [16/90] Train Loss: 3.4956 | Val Loss: 2.8315 | Val Acc: 38.06%
Epoch [17/90] Train Loss: 3.4861 | Val Loss: 2.9091 | Val Acc: 36.98%
Epoch [18/90] Train Loss: 3.4778 | Val Loss: 2.8684 | Val Acc: 37.47%
Epoch [19/90] Train Loss: 3.4676 | Val Loss: 2.9079 | Val Acc: 37.89%
Epoch [20/90] Train Loss: 3.4596 | Val Loss: 2.9102 | Val Acc: 37.42%
Epoch [21/90] Train Loss: 3.4542 | Val Loss: 2.8584 | Val Acc: 38.13%
Epoch [22/90] Train Loss: 3.4506 | Val Loss: 2.8234 | Val Acc: 38.14%
Epoch [23/90] Train Loss: 3.4425 | Val Loss: 2.8718 | Val Acc: 38.03%
Epoch [24/90] Train Loss: 3.4428 | Val Loss: 2.8392 | Val Acc: 38.59%
Epoch [25/90] Train Loss: 3.4353 | Val Loss: 2.9220 | Val Acc: 37.23%
Epoch [26/90] Train Loss: 3.4293 | Val Loss: 2.8266 | Val Acc: 38.84%
Epoch [27/90] Train Loss: 3.4264 | Val Loss: 2.8169 | Val Acc: 38.80%
Epoch [28/90] Train Loss: 3.4225 | Val Loss: 2.7373 | Val Acc: 40.42%
Epoch [30/90] Train Loss: 3.4187 | Val Loss: 2.8333 | Val Acc: 38.55%
Learning rate reduced to 0.0010 (Decay count: 1/3)
Epoch [31/90] Train Loss: 3.4152 | Val Loss: 2.8496 | Val Acc: 38.98%
Epoch [32/90] Train Loss: 2.8414 | Val Loss: 2.1718 | Val Acc: 50.85%
Epoch [33/90] Train Loss: 2.7172 | Val Loss: 2.1366 | Val Acc: 51.64%
Epoch [34/90] Train Loss: 2.6662 | Val Loss: 2.1010 | Val Acc: 52.24%
Epoch [35/90] Train Loss: 2.6338 | Val Loss: 2.0667 | Val Acc: 52.74%
Epoch [36/90] Train Loss: 2.6133 | Val Loss: 2.0660 | Val Acc: 52.76%
Epoch [37/90] Train Loss: 2.5935 | Val Loss: 2.0518 | Val Acc: 52.93%
Epoch [38/90] Train Loss: 2.5779 | Val Loss: 2.0413 | Val Acc: 52.95%
Epoch [39/90] Train Loss: 2.5681 | Val Loss: 2.0343 | Val Acc: 53.19%
Epoch [40/90] Train Loss: 2.5557 | Val Loss: 2.0606 | Val Acc: 52.69%
Epoch [41/90] Train Loss: 2.5455 | Val Loss: 2.0479 | Val Acc: 53.11%
Epoch [42/90] Train Loss: 2.5352 | Val Loss: 2.0274 | Val Acc: 53.24%
Epoch [43/90] Train Loss: 2.5249 | Val Loss: 2.0490 | Val Acc: 53.07%
Epoch [44/90] Train Loss: 2.5147 | Val Loss: 2.0361 | Val Acc: 53.19%
Epoch [45/90] Train Loss: 2.5062 | Val Loss: 2.0544 | Val Acc: 52.90%
Epoch [46/90] Train Loss: 2.4980 | Val Loss: 2.0448 | Val Acc: 53.12%
Epoch [47/90] Train Loss: 2.4916 | Val Loss: 2.0746 | Val Acc: 52.50%
Epoch [48/90] Train Loss: 2.4828 | Val Loss: 2.0169 | Val Acc: 53.78%
Epoch [49/90] Train Loss: 2.4771 | Val Loss: 2.0800 | Val Acc: 52.60%
Epoch [50/90] Train Loss: 2.4721 | Val Loss: 2.0061 | Val Acc: 53.72%
Epoch [51/90] Train Loss: 2.4630 | Val Loss: 2.0083 | Val Acc: 53.75%
Epoch [52/90] Train Loss: 2.4552 | Val Loss: 2.0426 | Val Acc: 53.07%
Epoch [53/90] Train Loss: 2.4515 | Val Loss: 2.0217 | Val Acc: 53.51%
Epoch [54/90] Train Loss: 2.4472 | Val Loss: 2.0089 | Val Acc: 53.71%
Epoch [55/90] Train Loss: 2.4380 | Val Loss: 1.9955 | Val Acc: 54.19%
Epoch [56/90] Train Loss: 2.4344 | Val Loss: 1.9732 | Val Acc: 54.55%
Epoch [57/90] Train Loss: 2.4276 | Val Loss: 2.0113 | Val Acc: 53.79%
Epoch [58/90] Train Loss: 2.4240 | Val Loss: 1.9843 | Val Acc: 54.24%
Epoch [59/90] Train Loss: 2.4183 | Val Loss: 2.0307 | Val Acc: 53.56%
Epoch [60/90] Train Loss: 2.4157 | Val Loss: 1.9911 | Val Acc: 53.99%
Learning rate reduced to 0.0001 (Decay count: 2/3)
Epoch [61/90] Train Loss: 2.4129 | Val Loss: 2.0004 | Val Acc: 54.12%
Epoch [62/90] Train Loss: 2.2159 | Val Loss: 1.8485 | Val Acc: 57.26%
Epoch [63/90] Train Loss: 2.1828 | Val Loss: 1.8387 | Val Acc: 57.41%
Epoch [64/90] Train Loss: 2.1717 | Val Loss: 1.8359 | Val Acc: 57.63%
Epoch [65/90] Train Loss: 2.1611 | Val Loss: 1.8233 | Val Acc: 57.86%
Epoch [66/90] Train Loss: 2.1568 | Val Loss: 1.8295 | Val Acc: 57.85%
Epoch [67/90] Train Loss: 2.1502 | Val Loss: 1.8210 | Val Acc: 57.69%
Epoch [68/90] Train Loss: 2.1450 | Val Loss: 1.8215 | Val Acc: 57.77%
Epoch [69/90] Train Loss: 2.1399 | Val Loss: 1.8250 | Val Acc: 57.90%
Epoch [70/90] Train Loss: 2.1346 | Val Loss: 1.8179 | Val Acc: 57.94%
Epoch [71/90] Train Loss: 2.1303 | Val Loss: 1.8283 | Val Acc: 57.75%
Epoch [72/90] Train Loss: 2.1285 | Val Loss: 1.8207 | Val Acc: 57.83%
Epoch [73/90] Train Loss: 2.1271 | Val Loss: 1.8212 | Val Acc: 57.85%
Epoch [74/90] Train Loss: 2.1191 | Val Loss: 1.8194 | Val Acc: 58.01%
Epoch [75/90] Train Loss: 2.1204 | Val Loss: 1.8249 | Val Acc: 57.72%
Epoch [76/90] Train Loss: 2.1140 | Val Loss: 1.8094 | Val Acc: 58.03%
Epoch [77/90] Train Loss: 2.1117 | Val Loss: 1.8151 | Val Acc: 57.90%
Epoch [79/90] Train Loss: 2.1084 | Val Loss: 1.8220 | Val Acc: 58.01%
Epoch [80/90] Train Loss: 2.1068 | Val Loss: 1.8307 | Val Acc: 57.55%
Epoch [81/90] Train Loss: 2.1054 | Val Loss: 1.8160 | Val Acc: 57.89%
Epoch [82/90] Train Loss: 2.1011 | Val Loss: 1.8159 | Val Acc: 57.92%
Epoch [83/90] Train Loss: 2.1006 | Val Loss: 1.8143 | Val Acc: 58.06%
Epoch [84/90] Train Loss: 2.0966 | Val Loss: 1.8203 | Val Acc: 57.82%
Epoch [85/90] Train Loss: 2.0945 | Val Loss: 1.8165 | Val Acc: 57.88%
Epoch [86/90] Train Loss: 2.0929 | Val Loss: 1.8275 | Val Acc: 57.65%
Epoch [87/90] Train Loss: 2.0902 | Val Loss: 1.8198 | Val Acc: 57.96%
Epoch [88/90] Train Loss: 2.0874 | Val Loss: 1.8174 | Val Acc: 57.85%
Epoch [89/90] Train Loss: 2.0872 | Val Loss: 1.8212 | Val Acc: 57.88%
Epoch [90/90] Train Loss: 2.0842 | Val Loss: 1.8236 | Val Acc: 57.72%
训练结果分析及与原论文对比:
1.最终准确率对比
当前模型: 最终验证准确率 57.72%(Top-1)。
原论文结果: AlexNet 在 ImageNet 的 Top-1 准确率为 56.9%~57.1%。
结论: 当前模型性能略优于原论文,差异在合理范围内,表明实现正确且超参数调整有效。
2.训练动态分析
学习率调整影响:
Epoch 30: 学习率降至 0.001,验证准确率从 38.55% 快速跃升至 50.85%(Epoch 32),符合预期。
Epoch 60: 学习率降至 0.0001,验证准确率从 53.99% 提升至 57.26%(Epoch 62),模型收敛稳定。
策略有效性: 分段学习率调整与原论文一致,成功跳出局部最优。
过拟合控制:
训练损失持续下降(最终 2.0842),验证损失稳定在 1.82,未见明显过拟合。
正则化手段(Dropout、权重衰减)与数据增强(PCA扰动、随机裁剪)有效。
总结
文章创新点:
1.数据预处理层面:采用了图像平移和水平翻转(Translation and Horizontal Reflection)和RGB通道强度变化(RGB Intensity Alteration)方法进行训练数据的扩充和增强,使得训练出的模型具有一定的鲁棒性和泛化能力。
2.模型设计层面:采用了ReLU作为激活函数替代sigmoid,其非饱和特性使得正向传播时神经元不易饱和,反向传播时梯度能有效传递。采用了LRN和Dropput以及重叠池化机制防止过拟合,增加模型抓取特征的能力,提高泛化能力
不足之处:
1.权重偏置初始化策略比较简单,对激活函数、反向传播的考虑不够充分,所以训练过程容易出现梯度消失的问题
2.对识别图像中尺度大小不同的物体没有专门的训练策略(后面的VGG、GoogLeNet对此有不同的优化策略)

















 1048
1048

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









