










Keras 入门教程
Keras 卷积神经网络 (CNN)
让我们将模型从 上节的MPL 修改为卷积神经网络(CNN),解决我们早期的数字识别问题。
CNN可以表示如下:
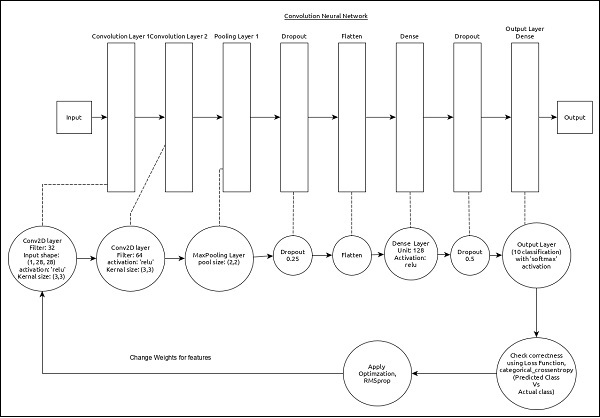
该模型的核心特征如下
- 输入层由 (1, 8, 28) 个值组成。
- 第一层,
Conv2D由32个过滤器和内核大小为(3,3)的“relu”激活函数组成。 - 第二层,
Conv2D由64个过滤器和内核大小为(3,3)的“relu”激活函数组成。 - 第三层,
MaxPooling的池大小为(2, 2)。 - 第五层,
Flatten用于将其所有输入展平为单一维度。 - 第六层,
Dense由128个神经元和“relu”激活函数组成。 - 第七层,
Dropout的值为0.5。 - 第八层也是最后一层由
10个神经元和“softmax”激活函数组成。 - 使用
categorical_crossentropy作为损失函数。 - 使用
Adadelta()作为优化器。 - 使用
accuracy作为指标。 - 使用
128作为批量大小。 - 使用
20作为纪元。
第 1 步 - 导入模块
导入必要的模块。
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
# from tensorflow.keras.optimizers import RMSprop
from keras.callbacks import EarlyStopping
from sklearn import preprocessing
from keras.datasets import mnist
from keras import backend as K
%matplotlib inline
第 2 步 - 加载数据
导入 mnist 数据集。
(x_train, y_train), (x_test, y_test) = mnist.load_data()
第 3 步 - 处理数据
根据我们的模型更改数据集,以便将其输入到我们的模型中。
img_rows, img_cols = 28, 28
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = tf.keras.utils.to_categorical(y_train, 10)
y_test = tf.keras.utils.to_categorical(y_test, 10)
除了输入数据的形状和图像格式配置之外,数据处理类似于 MPL 模型。
第 4 步 - 创建模型
创建实际模型。
model = Sequential()
model.add(Conv2D(32, kernel_size = (3, 3),
activation = 'relu', input_shape = input_shape))
model.add(Conv2D(64, (3, 3), activation = 'relu'))
model.add(MaxPooling2D(pool_size = (2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation = 'relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation = 'softmax'))
model.summary()
'''
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 26, 26, 32) 320
conv2d_1 (Conv2D) (None, 24, 24, 64) 18496
max_pooling2d (MaxPooling2D (None, 12, 12, 64) 0
)
dropout (Dropout) (None, 12, 12, 64) 0
flatten (Flatten) (None, 9216) 0
dense (Dense) (None, 128) 1179776
dropout_1 (Dropout) (None, 128) 0
dense_1 (Dense) (None, 10) 1290
=================================================================
Total params: 1,199,882
Trainable params: 1,199,882
Non-trainable params: 0
_________________________________________________________________
'''
第 5 步 - 编译模型
使用选定的损失函数、优化器和指标来编译模型。
model.compile(loss = tf.keras.losses.categorical_crossentropy,
optimizer = tf.keras.optimizers.Adadelta(), metrics = ['accuracy'])
第 6 步 - 训练模型
使用fit()方法训练模型。
history=model.fit(
x_train, y_train,
batch_size = 128,
epochs = 12,
verbose = 1,
validation_data = (x_test, y_test)
)
执行应用程序将输出以下信息:
Epoch 1/12
469/469 [==============================] - 127s 268ms/step - loss: 2.2788 - accuracy: 0.1560 - val_loss: 2.2402 - val_accuracy: 0.4071
Epoch 2/12
469/469 [==============================] - 124s 265ms/step - loss: 2.2179 - accuracy: 0.2786 - val_loss: 2.1629 - val_accuracy: 0.5571
Epoch 3/12
469/469 [==============================] - 125s 267ms/step - loss: 2.1368 - accuracy: 0.3890 - val_loss: 2.0607 - val_accuracy: 0.6457
Epoch 4/12
469/469 [==============================] - 126s 268ms/step - loss: 2.0310 - accuracy: 0.4629 - val_loss: 1.9230 - val_accuracy: 0.7033
Epoch 5/12
469/469 [==============================] - 126s 268ms/step - loss: 1.8898 - accuracy: 0.5249 - val_loss: 1.7433 - val_accuracy: 0.7487
Epoch 6/12
469/469 [==============================] - 123s 263ms/step - loss: 1.7219 - accuracy: 0.5703 - val_loss: 1.5320 - val_accuracy: 0.7806
Epoch 7/12
469/469 [==============================] - 123s 262ms/step - loss: 1.5429 - accuracy: 0.6035 - val_loss: 1.3167 - val_accuracy: 0.7990
Epoch 8/12
469/469 [==============================] - 115s 246ms/step - loss: 1.3770 - accuracy: 0.6306 - val_loss: 1.1274 - val_accuracy: 0.8111
Epoch 9/12
469/469 [==============================] - 109s 233ms/step - loss: 1.2343 - accuracy: 0.6593 - val_loss: 0.9757 - val_accuracy: 0.8219
Epoch 10/12
469/469 [==============================] - 106s 225ms/step - loss: 1.1238 - accuracy: 0.6794 - val_loss: 0.8594 - val_accuracy: 0.8303
Epoch 11/12
469/469 [==============================] - 111s 236ms/step - loss: 1.0331 - accuracy: 0.6978 - val_loss: 0.7713 - val_accuracy: 0.8376
Epoch 12/12
469/469 [==============================] - 116s 248ms/step - loss: 0.9639 - accuracy: 0.7129 - val_loss: 0.7031 - val_accuracy: 0.8469
第 7 步 - 查看训练曲线
plt.plot(history.epoch,history.history.get('loss'),label="loss")
plt.plot(history.epoch,history.history.get('val_loss'),label="val_loss")
plt.xlabel("epoch")
plt.ylabel("loss")
plt.legend()

plt.plot(history.epoch,history.history.get('accuracy'),label="accuracy")
plt.plot(history.epoch,history.history.get('val_accuracy'),label="val_accuracy")
plt.xlabel("epoch")
plt.ylabel("accuracy")
plt.legend()

从上图可以看出还没有达到上限,还有提升的空间,验证数据比训练数据好,说明没有过拟合
第 8 步 - 评估模型
让我们使用测试数据评估模型。
score = model.evaluate(x_test, y_test, verbose = 0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
执行上述代码将输出以下信息:
Test loss: 0.7031074166297913
Test accuracy: 0.8468999862670898
测试准确率为84.69%。我们创建了一个最佳模型来识别手写数字。
第 9 步- 预测
最后,从图像中预测数字如下:
pred = model.predict(x_test)
pred = np.argmax(pred, axis = 1)[:5]
label = np.argmax(y_test,axis = 1)[:5]
print(pred)
print(label)
上述应用程序的输出如下:
[7 2 1 0 4]
[7 2 1 0 4]
两个数组的输出是相同的,这表明我们的模型正确预测了前五个图像。
总结
上述方法,只说明这个方法的一些过程,如何优化提升模型的效果并非本节的内容,不过可以明确的告诉大家,如果多进行训练,可以提升效果,考虑到时间的问题,不在此问题上深探,如果有兴趣的小伙伴可以一起讨论。
PS :后继,本人测试过效果不明显。
后续
将编译方法进行了修改,模型的效果提升了很多。
model.compile(optimizer="adam", loss="categorical_crossentropy", metrics = ['accuracy'])
history=model.fit(
x_train, y_train,
batch_size = 128,
epochs = 6,
verbose = 1,
validation_data = (x_test, y_test)
)
Epoch 1/6
469/469 [==============================] - 118s 251ms/step - loss: 0.2381 - accuracy: 0.9274 - val_loss: 0.0518 - val_accuracy: 0.9831
Epoch 2/6
469/469 [==============================] - 122s 259ms/step - loss: 0.0831 - accuracy: 0.9755 - val_loss: 0.0375 - val_accuracy: 0.9882
Epoch 3/6
469/469 [==============================] - 124s 265ms/step - loss: 0.0615 - accuracy: 0.9816 - val_loss: 0.0330 - val_accuracy: 0.9887
Epoch 4/6
469/469 [==============================] - 131s 279ms/step - loss: 0.0506 - accuracy: 0.9844 - val_loss: 0.0301 - val_accuracy: 0.9900
Epoch 5/6
469/469 [==============================] - 127s 271ms/step - loss: 0.0425 - accuracy: 0.9863 - val_loss: 0.0282 - val_accuracy: 0.9908
Epoch 6/6
469/469 [==============================] - 120s 256ms/step - loss: 0.0383 - accuracy: 0.9880 - val_loss: 0.0319 - val_accuracy: 0.9895
Epoch 1/6
469/469 [==============================] - 118s 251ms/step - loss: 0.2381 - accuracy: 0.9274 - val_loss: 0.0518 - val_accuracy: 0.9831
Epoch 2/6
469/469 [==============================] - 122s 259ms/step - loss: 0.0831 - accuracy: 0.9755 - val_loss: 0.0375 - val_accuracy: 0.9882
Epoch 3/6
469/469 [==============================] - 124s 265ms/step - loss: 0.0615 - accuracy: 0.9816 - val_loss: 0.0330 - val_accuracy: 0.9887
Epoch 4/6
469/469 [==============================] - 131s 279ms/step - loss: 0.0506 - accuracy: 0.9844 - val_loss: 0.0301 - val_accuracy: 0.9900
Epoch 5/6
469/469 [==============================] - 127s 271ms/step - loss: 0.0425 - accuracy: 0.9863 - val_loss: 0.0282 - val_accuracy: 0.9908
Epoch 6/6
469/469 [==============================] - 120s 256ms/step - loss: 0.0383 - accuracy: 0.9880 - val_loss: 0.0319 - val_accuracy: 0.9895
Test loss: 0.03192790597677231
Test accuracy: 0.9894999861717224















 1355
1355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









