






本文概述了点云压缩(PCC)最近的标准化活动。点云是一种3D数据表示,用于与沉浸式媒体相关的各种应用,包括虚拟/增强现实、沉浸式远程呈现、自动驾驶和文化遗产档案。媒体压缩的国际标准机构,也被称为电影专家组(Motion Picture Experts Group, MPEG),计划在2020年发布两个PCC标准规范:基于视频的PCC (V-CC)和基于几何的PCC (G-PCC)。V-PCC和G-PCC将成为ISO/IEC 23090系列沉浸式媒体内容编码表示的一部分。在本文中,我们提供了一个详细的描述编解码算法和它们的编码性能。此外,我们还将讨论点云压缩的某些独特方面。
关键词:沉浸式媒体,MPEG-I,点云压缩,基于视频的点云压缩,V-PCC, ISO/IEC 23090-5,基于几何的点云压缩,G-PCC, ISO/IEC 23090-9
I.引言
视觉捕捉技术的最新进展使三维世界场景对应的点的捕捉和数字化成为可能。点云是主要的3D数据表示方法之一,除了提供空间坐标外,它还提供了与3D世界中的点相关的属性(如颜色或反射率)。原始格式的点云需要大量的存储内存或传输带宽。例如,用于娱乐目的的典型动态点云通常每帧包含大约100万个点,如果不压缩的话,每秒30帧的总带宽为3.6 Gbps。此外,高分辨率点云捕获技术的出现反过来对点云的大小提出了更高的要求。为了使点云可用,压缩是必要的。
30多年来,电影专家组(MPEG)一直在生产国际上成功的压缩标准,如MPEG-2、AVC和HEVC,其中许多标准已广泛应用于电视或智能手机等设备。标准对于数据交换生态系统的发展至关重要。2013年,MPEG首先考虑在沉浸式远程呈现应用程序中使用点云,并随后讨论了如何压缩这种类型的数据。随着越来越多的点云使用案例变得可用和出现,2017年发布了一份建议书(CfP)。基于对CfP的响应,我们选择了两种不同的压缩技术用于点云压缩(PCC)标准化活动:基于视频的PCC (V-PCC)和基于几何的PCC (G-PCC)。这两个标准计划分别为ISO/IEC 23090-5和-9。
本文的目的是给一个洞察对于MPEG的PCC活动。我们还描述了整体的编解码器架构,它的元素和功能,以及特定于各种用例的编码性能。我们还提供了一些示例,演示了使用这种新数据格式在编码器端获得更高的编码性能和区别的可用灵活性。本文的内容如下:第二部分提供了点云的一般定义,以及用例和对当前标准化活动的简要描述。第三节描述了基于视频的PCC方法,也称为V-PCC,并讨论了用于PCC的编码器工具。在第四节中,我们讨论了基于几何的PCC (G-PCC)方法,并举例说明了编码工具。第五节介绍了这两种方法的性能指标,第六节总结了本文。
II.点云
在本节中,我们定义点云的通用术语,介绍用例,并简要讨论正在进行的标准化过程和活动。
A)定义、获取和呈现
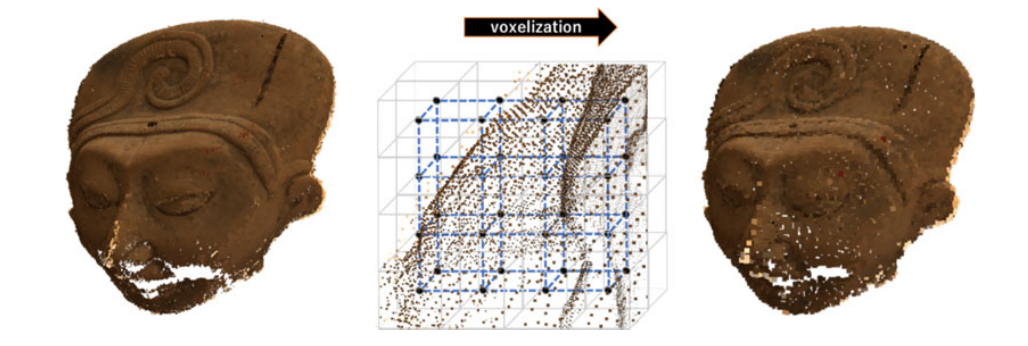
图1。浮点坐标的原始点云(左)和整数坐标的体素化点云(右)。
点云是由三维空间中的点集合组成的。3D空间中的每个点都与几何位置以及相关的属性信息(如颜色、反射率等)相关联。一个点的三维坐标通常用浮点值表示;但是,它们可以根据预先定义的空间精度量化为整数值。量化过程在三维空间中创建网格,每个子网格体内的所有点都映射到子网格中心坐标,今后称为体素。这种将浮点空间坐标转换为基于网格的坐标表示的过程也称为体素化。每个体素可以被认为是对应于二维图像网格坐标的像素的三维扩展。注意,空间精度可能会影响点云的感知质量,如图1所示。
空间信息可以通过两种不同的方法获得:被动或主动。被动方法使用多个摄像机,通过图像匹配和空间三角剖分来推断在三维空间中被捕获物体与摄像机之间的距离。立体匹配算法[5]和多视角结构[6]已经被提出作为深度获取的被动方法。主动方法使用光源(如红外线或激光)和后向散射反射光来测量物体和传感器之间的距离。例如,主动的深度传感器:微软的Kinect,苹果的TrueDepth Camera,英特尔的Realsense,索尼的DepthSense等等。
主动和被动深度采集方法都可以作为一种互补的方式来改善点云的生成。捕获技术的最新趋势是volumetric studios,其中,被动方法(仅使用RGB相机)或被动和主动方法的组合(使用RGB和深度相机)创建高质量的点云。volumetric capture studios的例子有8i、Intel studios和Sony Innovation studios。
不同的应用程序可以使用点云信息来执行不同的任务。在汽车应用中,空间信息可用于预防事故,而在娱乐行业应用中,三维坐标可为用户提供身临其境的体验。在娱乐用例方面,基于点云信息的渲染系统也正在出现,基于点云编辑和渲染的解决方案已经出现(例如Nurulize提供了体积数据编辑和可视化的解决方案)。
B)用例
因此,有许多应用程序使用点云作为首选的数据捕获格式。这里我们解释了一些典型的用例,如图2所示。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gDoixELC-1689735803819)(https://oss.xljsci.com//literature/42743910/page0/1689735497856.png)]
图二。点云的用例示例,从左到右:VR/AR、远程呈现、自动驾驶汽车和世界遗产。
1)VR/AR
动态点云序列,如[15]中呈现的点云序列,可以为用户提供从任何角度观看移动内容的能力:这一特性也被称为6自由度(6DoF)。这类内容通常用于虚拟/增强现实(VR/AR)应用。例如,在[19,20]中,提出了使用移动设备的点云可视化应用程序。因此,利用手机中可用的视频解码器和GPU资源,对V-PCC编码的点云进行实时解码和重构。随后,当与AR框架(如ARCore,ARkit)结合时,点云序列可以通过移动设备覆盖在真实世界上。
2)电信
V-PCC具有很高的压缩效率,可以在带宽有限的网络上传输点云视频。因此,它可以用于远程呈现应用程序。例如,佩戴头戴式显示设备的用户将能够通过发送/接收用V-PCC编码的点云与虚拟世界进行远程交互。
3)自动驾驶汽车
自动驾驶汽车使用点云来收集周围环境的信息,以避免碰撞。如今,为了获取三维信息,车辆上安装了多个视觉传感器。LIDAR传感器就是这样一个例子:它将周围环境捕获为时变稀疏点云序列。G-PCC可以对这个稀疏序列进行压缩,从而以一种轻便高效的算法帮助改善车内的数据流。
4)世界遗产
对于文物档案,用3D传感器将物体扫描成高分辨率的静态点云。许多学术/研究项目生成高质量的历史建筑或文物点云来保存它们,并为虚拟世界创造数字副本。激光范围扫描仪或Structure from Motion(SfM)技术被使用在内容生成过程中。此外,G-PCC可以用于无损耗压缩生成的点云,减少存储需求的同时保持准确的测量。
C) MPEG标准化
沉浸式远程呈现是MPEG在2013年讨论的点云的第一个用例。空间中分布不规则的点的动态特性往往会产生大量的数据,从而提供了压缩需要的初步证据。由于行业对点云越来越感兴趣,MPEG 2017年1月收集了需求,并根据CfP启动了PCC标准化。将点云内容分为三类:静态表面(第一类)、动态表面(第二类)和动态获取激光雷达序列(第三类)。CfP发布后,几家公司以不同的压缩技术方案回应了这一呼吁。首先,MPEG确定了三种不同的技术:用于动态获取数据的LIDAR点云压缩(L-PCC),用于静态点云数据的surface PCC (S-PCC),以及用于动态内容[24]的V -PCC。由于S-PCC与L-PCC的相似之处,两项提案后来合并为G-PCC。首个测试模型于2017年10月开发,一个用于2类(TMC2),另一个用于1类和3类(TMC13)。2年来,通过不断的技术贡献,测试模型得到了进一步的改进,PCC标准规范将于2020年最终确定。在下面的章节中,提供了V-PCC和G-PCC编解码算法的更详细的技术描述。
III.基于视频的点云压缩
在下面的小节中,我们将描述V-PCC的编码原理,并解释它的一些编码工具。
A)基于投影的编码原理
由于视频编码标准的广泛采用,二维视频压缩是一项成功的技术。为了充分利用这一技术,PCC方法可以将点云数据从3D转换为2D,然后由2D视频编码器进行编码。在MPEG的CfP中,几个对CfP的响应应用了3D到2D投影。这个提议成为了V-PCC测试模型的基础,它通过将点云划分为若干连接区域(称为3D patch)来生成3D表面片段。然后,将每个3D patch独立投影到2D patch中。这种方法有助于减少投影问题,如自遮挡和隐藏表面,并为点云转换问题提供了一个可行的解决方案。此外,正投影被用来避免重采样问题,并允许无损压缩。
将一个3D贴片投影到一个2D贴片上,就像一个虚拟的正投影相机,捕捉点云的特定部分。点云投影过程类似于几个虚拟摄像机对点云的部分进行注册,并将这些摄像机图像组合成一个马赛克,即包含投影2D补丁集合的图像。这个过程会产生一组与每个补丁的投影相关联的元数据信息,或者类似地,每个虚拟捕获相机的描述。对于每个图集,我们也有多达3个相关的图像:(1)二值图像,称为占用图,它表示像素是否对应有效的3d投影点;(2)包含深度信息的几何图像,即每个点的位置与投影平面之间的距离;(3)一个属性图像(s),如每个点的纹理(颜色),即包含颜色信息的R、G、B分量的彩色图像,或一个材料属性,可以用单色图像表示。对于V-PCC的情况,几何图像特别类似于深度图,因为它记录了3D点和投影平面之间的距离。其他类型的几何图像,如[26,27]中描述的图像,不测量距离,而是使用不同的映射算法将3D信息转换为2D图像。此外,这种映射只用于3D网格,而不是点云。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SFez26xK-1689735803819)(https://oss.xljsci.com//literature/42743910/page0/1689735462739.png)]
图3。 3D Patch projection and respective occupancy map,geometry, and attribute 2D images,(a) 3D patch, (b)3D Patch 占用图,© 3D Patch 几何图, (d) 3D Patch 属性图.
图3提供了一个3D补丁及其各自投影图像的示例。注意,在图3中,我们只展示了每个投影点的纹理;其他属性图像也可以。基于投影的方法非常适合于密集序列,当投影时,生成像图像一样连续和光滑的表面。对于稀疏的点云,基于投影的编码可能不是有效的,后面描述的G-PCC等其他方法可能更合适。
B) V-PCC编解码架构
本节讨论了V-PCC编解码器架构的一些主要功能元素/工具,主要有:补丁生成、打包、占用图、几何图、属性图、图集图像生成、图像填充和视频压缩。应该注意的是,列出的每种工具提供的功能可以以不同的方式和方法实现。这些功能的具体实现是非规范的,V-PCC标准没有规定。因此,它成为编码器的选择,允许灵活性和差异化。
在V-PCC的标准化过程中,开发了一个参考软件(TMC2),以衡量V-PCC的编码性能,并比较V-PCC所考虑的点云编码方法的技术优势。TMC2编码器应用了几种技术来提高编码性能,包括如何对补丁进行打包、创建占用图、几何形、纹理图以及压缩占用图、几何形、纹理和补丁信息。请注意,TMC2使用HEVC编码生成的2D视频,但使用HEVC不是强制性的,也可以使用任何适当的图像/视频编解码器。尽管如此,本文提出的结构和结果使用HEVC作为基础编码器。TMC2编码器架构如图4所示。下一小节将详细介绍下面所示的每个编码块。
1)补丁生成
这里我们描述了如何在TMC2中生成3D补丁。首先,每个点的法线被估计为[29]。给定六个正投影方向(±x,±y,±z),每个点都与投影方向相关,该投影方向产生点法线之间最大的点积,并选择相应的投影方向。根据相邻点投影方向的分类,进一步细化点分类。一旦点的分类完成,具有相同投影方向(类别)的点将使用连接组件算法组合在一起。作为这个过程的结果,每个连接的组件被称为一个3D补丁。然后,根据3D补丁的投影方向,将3D补丁点正交投影到轴对齐的包围盒的六个面之一上。注意,由于投影曲面位于一个垂直对齐的包围盒上,因此投影后,点的三个坐标中的两个保持不变,点的第三个坐标被注册为点在三维空间中的位置与投影曲面之间的距离函数(图5)。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2oXYc2Sb-1689735803819)(https://oss.xljsci.com//literature/42743910/page0/1689735000583.png)]
图5。补丁生成。
由于3D补丁可能会有多个点投影到相同的像素位置上,TMC2使用多个“图”来存储这些重叠的点。特别地,我们假设有一组点H(u,v)被投射到相同的(u,v)位置上。因此,例如,TMC2可以决定使用两个地图:一个近图和一个远图。近图存储了H(u,v)处深度值最低的点D0。远图在用户定义的间隔(D0, D0+D)中存储具有最高深度值的点。用户自定义的区间大小D表示表面厚度,可由编码器设置,用于改进几何编码和重建。
TMC2可以选择在两个单独的视频流中编码远端图和近端图的差分地图,或者将近端和远端地图临时交错成一个流并编码绝对值。在这两种情况下,区间大小D都可以用来改进深度重构过程,因为重构值必须位于预定义的区间(D0, D0+D)内。第二个映射可以完全删除,只使用插值方案生成远图。此外,这两帧可以进行下采样和空间交错,以提高重建质量,而不是只重建一个图,并提高编码效率,而不是发送两个图。
远图可能携带映射到同一位置的多个元素的信息。在无损模式下,TMC2修改远地地图图像,这样就可以使用增强的delta-depth (EDD)代码对多个点进行编码,而不是对每个样本进行单个点编码。EDD代码通过设置EDD代码比特位来表示在近深度值D0和远深度值D1之间是否有位置被占用。然后,这段代码被添加到远图的顶部。通过这种方式,只需使用两个图就可以表示多个点。
然而,仍然有可能有一些点可能缺失,并且仅使用六个投影方向可能会限制点云的重建质量。为了改进任意方向曲面的重构,在标准[34]中增加了12种模式,对应于45度方向的摄像机。注意,点云旋转到45度可以只使用整数操作建模,从而避免了旋转引起的重采样问题。
为了生成适合视频编码的图像,TMC2增加了执行滤波操作的选项。例如,TMC2定义了一个块大小为T × T(例如T=16),其中深度值不能有大的变化,深度值高于确定的阈值的点从3D patch中被删除。此外,TMC2还定义了一个范围来表示深度,如果深度值大于允许的范围,那么它就会从3D补丁中移除。请注意,从3D patch中移除的点稍后将由连接组件算法进行分析,并可能用于生成新的3D patch。3D patch生成的进一步改进包括使用颜色信息进行平面分割和自适应选择最佳平面进行深度投影。
TMC2可以通过用户自定义参数来限制3D补丁中的最小点数。因此,它将不允许生成可能包含比指定的最小点数量更少的点的3D补丁。尽管如此,如果这些被拒绝的点在编码点云的某个用户定义阈值内,它们也可能不包含在任何其他常规补丁中。对于有损编码,TMC2可能决定忽略这些点。另一方面,对于无损编码,没有包含在任何补丁中的点可以被额外的无损编码补丁编码。这些额外的补丁被称为辅助补丁,直接将(x, y, z)坐标存储在为常规补丁创建的几何图像D0中,用于2D视频编码。或者,辅助补丁可以存储在一个单独的图像和编码为增强图像。
2)补丁打包
补丁打包是指将投影的2D Patch放置在尺寸为W×H的2D图像中。这是一个迭代的过程:首先,补丁按照大小排序。然后,通过光栅扫描顺序的彻底搜索确定每个patch的位置,选择保证无重叠插入的第一个位置(即该patch占用的所有T × T块在atlas图像中不被另一个patch占用)。为了提高拟合的机会,[37]还允许八个不同的补丁方向(四个旋转结合或不结合镜像)。该区域内包含有效深度值像素(如占用图所示)的块被patch大小(舍入T的倍数)所覆盖,即被占用的块,不能被其他patch使用,因此保证每个T × T块只与一个唯一的patch相关联。当下一个patch没有空闲空间时,图像高度H加倍,再次计算该patch的插入。在插入所有补丁后,最终的高度被调整到所需的最小值。图6显示了打包补丁的占用图、几何图形和纹理图像的示例。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-v3STPgFF-1689735803820)(https://oss.xljsci.com//literature/42743910/page0/1689735078928.png)]
图6。补丁包装的例子。
为了提高压缩效率,需要将内容相似的补丁放置在时间上相似的位置。为了生成时间上一致的packing, TMC2在不同帧的patch之间寻找匹配的patch,并尝试在相似的位置插入匹配的patch。对于patch匹配操作,TMC2使用intersection over union (IOU)来求两个投影patch之间的重叠量,根据如下公式:
Q i , j = ∩ ( p r e R e c t [ i ] , R e c t [ j ] ) ∪ ( p r e R e c t [ i ] , R e c t [ j ] ) Q_{i,j}=\frac{∩(preRect[i], Rect[j])}{∪(preRect[i], Rect[j])} Qi,j=∪(preRect[i],Rect[j])∩(preRect[i],Rect[j])
其中preRect[i]是前一帧在二维空间中投影的patch[i]的二维包围框。Rect[j]是当前帧在二维空间中投影的patch[j]的包围盒。∩(preRect[i], Rect[j])是preRect[i]和Rect[j]的相交区域,∪(preRect[i], Rect[j])是preRect[i]和Rect[j]的并集区域。
最大IOU值决定了前一帧patch[i]和patch[j]之间的潜在匹配。如果IOU值大于预先定义的阈值,则认为这两个补丁匹配,并使用前一帧的信息对当前补丁进行打包和编码。例如,TMC2对匹配的patch使用相同的patch方向和法线方向,只对patch位置和包围框信息进行区别编码。
补丁匹配信息可用于在不同时间内以一致的方式放置补丁。在[39]中,theatlas中的空间是预先分配的,以避免补丁冲突和保证时间一致性。补丁位置的进一步优化可能会考虑压缩性能以外的其他方面。例如,在[40]中,将patch放置过程修改为低延迟解码,即解码器不需要等待所有patch的信息进行解码,就可以从投影的2D图像中提取出块到patch的信息,在被解码时可以立即识别出哪个像素属于哪个patch。
3)几何和占用地图
与[26,27]中定义的几何图像在三个不同通道中存储(x,y,z)值不同,V-PCC中的几何图像只使用视频序列的亮度通道存储点的三维位置缺失坐标到三维包围框中投影面之间的距离。因为补丁可以有任意的形状,一些像素可能会在补丁填充后保持空。为了区分几何视频中用于3D重建的像素和未使用的像素,TMC2传输了与每个点云帧相关的占用图。占用图具有用户定义的B × B块精度,其中对于无损编码B=1和有损编码,通常使用B=4,具有视觉上可接受的质量,同时显著减少编码占用图所需的位数。
占用图是一个二进制图像,使用无损视频编码器[41]编码。值1表示几何视频中相应的B × B块中至少有一个有效的像素,而值0表示图像填充过程中的像素填充了一个空白区域。对于视频编码,二值图像(W/B, H/B)被压缩到发光通道中并进行无损编码,但占用图的有损编码也可能是[42]。注意,对于有损的情况,当图像分辨率降低时,占用图图像需要放大到指定的标称分辨率。尺度的提升过程会导致占用图的额外的不准确性,其最终效果是在重建的点云中增加点。
4)图像填充,组扩张,重新着色,和视频压缩
对于几何图像,TMC2使用填充函数填充patch之间的空白,目的是生成适合于更高效率的视频压缩的分段平滑图像。每个T × T(如16 × 16)像素块单独处理。如果块是空的(即块中没有有效的深度值),则块的像素通过块按光栅扫描顺序复制前一个T × T块的最后一行或列来填充。如果块是满的(即所有像素都有有效的深度值),填充是不必要的。如果块中既有有效像素也有无效像素,那么空的位置将迭代地用其非空的邻居的平均值填充。填充过程,也被称为几何膨胀,是独立执行的每一帧。但是,近图和远图的空位置是相同的,使用相似的值可以提高压缩效率。因此,执行组膨胀,其中空白区域的填充值取平均值,并且对两帧使用相同的值。
视频编码常用的输入原始格式是YUV420,具有8位亮度和下采样色度通道。tmc2只将几何图像打包到亮度通道中,因为用距离表示的几何图像只有一个分量。此外,仔细考虑编码的GOP结构也可以导致显著的压缩效率。在无损编码的情况下,不能在规则的patch中表示的点的x、y、z坐标被块交错,直接存储在亮度通道中。此外,10位配置文件,如HEVC编码器可以提高精度和编码性能。此外,可以给编码器提示在图集中放置补丁,以改进运动估计过程。
由于重构后的几何形状可能与原始的不同,TMC2将颜色从原始的点云传输到解码后的点云,并使用这些新的颜色值进行传输。重着色过程[47]考虑了离原始点云最近的点的颜色值以及离重构点更近的点的一个邻域,以确定一个可能更好的颜色值。一旦知道颜色值,TMC2就会使用应用于几何图形的相同映射将颜色从3D映射到2D。为了填充彩色图像,TMC2可以采用基于mip-map插值的程序,并采用稀疏线性优化模型进一步改进填充,如图7所示。mip-map插值创建了由占用图引导的纹理图像的多分辨率表示,即使当它们被空像素下采样时,仍然保留活动像素。基于高斯-赛德尔松弛的稀疏线性优化可以用来填充每个分辨率尺度上的空像素。然后用较低的分辨率作为初值,对更高尺度的上采样图像进行优化。通过这种方式,背景被平滑地填充,这些值与补丁的边缘相似。此外,在地图空白区域(几何图像的分组膨胀)之前的平均位置原则也可以用于属性。然后将填充后的图像序列从RGB444彩色转换到YUV420彩色,并用传统的视频编码器进行编码。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jcqaOIB4-1689735803820)(https://oss.xljsci.com//literature/42743910/page0/1689735348362.png)]
图七。mip图图像纹理填充与稀疏线性优化。
5)重复修剪,几何平滑,属性平滑
重建过程使用解码的位流占用图,几何,和属性图像重建三维点云。当TMC2使用两个图时,近图和远图,两幅深度图像的值相同,TMC2可能会生成多个重复的点。这可能会影响质量,也会为无损编码创建不必要的点数。为了克服这一问题,在重构过程中,当近图和远图中存储的坐标相同时,每个patch (u,v)坐标只创建一个点,有效地修剪重复点。
几何图像和属性图像的压缩以及占用图上采样引入的附加点可能会引入伪影,从而影响重构点云。TMC2可以利用技术提高局部重建质量。请注意,类似的后处理方法可以在解码器侧发出信号并完成。例如,为了减少可能由分割引起的几何伪影,TMC2可以使用一种称为3D几何平滑的过程来平滑patches的边界点。一种潜在的点云平滑候选方法是在一个小的三维网格中识别在patch边缘的点并计算解码点的质心。在求出2 × 2 × 2网格的质心和点数后,应用常用的三线性滤波器。
由于点云分割过程和patch分配过程中,可能会将具有不同属性的patch放置在图像附近,patch边界处的颜色值也容易产生视觉伪影。此外,编码的块工件可能会创建跨越patch边界的重构模式,在重构点云中创建可见的接缝工件。TMC2可以选择对重构点云进行属性平滑[51],以减少对重构点云的接缝效应。此外,在三维空间中进行属性平滑,以便在估计新的平滑值时利用正确的邻域。
6)图集压缩
前面介绍的许多技术都具有非规范方面,这意味着它们只在编码器处执行,而解码器不需要知道它们。然而,有几个方面,特别是用于从二维视频数据重构三维数据的元数据是规范的,需要送到解码器进行适当处理。例如,patch的位置和方向,在包装中使用的块大小,以及其他都是需要传送给解码器的atlas元数据。
V-PCC标准定义了一个基于NAL单元的图集元数据流,用于传输补丁数据信息。NAL单元结构类似于HEVC[3]中使用的比特流结构,它允许更大的编码灵活性。在当前的标准规范[52]中,可以找到规范语法元素的描述,以及元数据流编码技术的说明,如补丁数据之间的预测。
IV.基于几何的点云编码
在下面的小节中,我们将描述G-PCC的编码原理,并解释它的一些编码工具。
A) 基于几何的编码原理
V-PCC编码方法是基于3D到2D投影,G-PCC则相反,直接在3D空间对内容进行编码。为了实现这一点,G-PCC利用了数据结构,例如描述3D空间中的点位置的八叉树,这将在下一节中进一步详细解释。此外,G-PCC对输入点云坐标表示不做任何假设。这些点有一个内部的基于整数的值,由浮点值表示转换而来。这种转换在概念上类似于输入点云的体素化,可以通过缩放、平移和舍入来实现。
G-PCC的另一个关键概念是tiles和slices的定义,它们允许并行编码功能[53]。在G-PCC中,slice被定义为一个可以独立编码和解码的点集(几何和属性)。反过来,一个tile是带有边界框信息的一组slice。一个tile可能与另一个tile重叠,解码器可以通过访问特定的slices来解码点云的部分区域。
当前G-PCC标准的一个限制是,它只定义为内部预测,也就是说,它目前没有使用任何时间预测工具。然而,基于点云运动估计和帧间预测的技术正在考虑用于下一个版本的标准。
B) G-PCC编解码架构:TMC13

图8。G-PCC参考编码器图。
图8展示了描述G-PCC参考编码器(也称为TMC13)的框图,它将在下一节中进行描述。它并不代表TMC13的全部功能,而只是它的一些核心模块。首先,可以看到几何和属性是分开编码的。然而,属性编码依赖于已解码的几何。因此,点云位置首先被编码。
源几何点可以用世界坐标系中的浮点数表示。因此,几何编码的第一步是执行坐标变换,然后是体素化。第二步包括使用八叉树或trisoup格式的几何分析,如在IV.B.1节和IV.B.2节中讨论的那样。最后,对生成的结构进行算术编码。关于属性编码,TMC13支持RGB到YCbCr的可选转换。然后,使用三种可用的转换工具中的一种,即区域自适应分层变换(RAHT)、预测变换和提升变换。这些变换将在第IV.B.3节中讨论。在变换之后,系数被量化并进行算术编码。
1)八叉树编码
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SLQwfVh1-1689735803821)(https://oss.xljsci.com//literature/42743910/page0/1689733758298.png)]
图9。八叉树构造过程的前两个步骤。
体素化点云使用八叉树结构以无损的方式表示。让我们假设点云包含在一个量化体积为D×D×D的体素中。首先,在垂直和水平方向上将立方体分割为8个子立方体,尺寸为D/2 ×D/2 ×D/2体素,如图9所示。这个过程对每个被占用的子立方体递归地重复,直到D等于1。值得指出的是,通常只有1%的体素位置被占用,这使得八叉树非常方便地表示点云的几何形状。在每个分解步骤中,验证哪些块被占用,哪些块没有被占用。已占用的块标记为1,未占用的块标记为0。在此过程中生成的八位元用1字节表示八叉树节点占用状态,并通过考虑到与相邻八位元相关性的熵编码器进行压缩。对于孤立点的编码,由于体积内没有其他可关联的点,引入了一种对八位元进行熵编码的替代方法,即直接编码模式(Direct coding Mode, DCM)。在DCM中,点的坐标直接编码而不进行任何压缩。DCM模式是从邻近节点推断出来的,以避免对树中的所有节点发出使用dcm的信号。
2)用trisoup进行曲面逼近
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iWu7R62l-1689735803821)(https://oss.xljsci.com//literature/42743910/page0/1689733829794.png)]
图10。解码器处的Trisoup点推导。
或者,几何可以用修剪过的八叉树来表示,从根构造到任意层次,其中叶子表示已占用的比体素大的子块。对象表面近似为一系列三角形,由于没有关联多个三角形的连接性信息,因此该技术称为“三角汤”(或trisoup)。它是一种可选的编码工具,在较低的比特率下提高主观质量,因为量化给出了粗略的速率自适应。如果启用了trisoup,几何比特流将变成八叉树、段指示器和顶点位置信息的组合。在解码过程中,解码器计算trisoup网格与体素网格的交点,如[59]所示。解码器中派生点的数量由可控制的体素网格距离d决定(图10)。
3)属性编码
在G-PCC中,属性编码有三种方法:(a) RAHT;(b)预测变换;©提升变换。RAHT背后的主要思想是使用更低级别的八叉树属性值来预测下一级别的值。预测变换实现了一种基于插值的分层最近邻预测方案。提升变换是建立在预测变换之上的,但是有一个额外的更新/提升步骤。正因为如此,从这一点开始,它们将被联合称为预测/提升变换。用户可以自由选择上述任何一种转换。但是,给定一个特定的上下文,一种方法可能比另一种更合适。决定使用哪种方法的通用标准是失真率性能和计算复杂度的结合。在下两个部分中,将描述RAHT和预测/提升属性编码方法。
RAHT变换
RAHT是通过考虑点云的八叉树表示来执行的。在它的规范形式中,它从八叉树的叶子开始(最高级别),然后向后推进,直到到达它的根(最低级别)。变换应用于每个节点,并在三个步骤中执行,在每个x、y和z方向上执行一个,如图11所示。每一步生成低通 g n g_n gn系数和高通 h n h_n hn系数。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ceMffsDR-1689735803821)(https://oss.xljsci.com//literature/42743910/page0/1689733869001.png)]
图11。2×2×2块的转换进程。
RAHT是受Haar启发的层次变换。因此,如果将一维Haar变换作为一个初始例子,可以更好地理解它。考虑一个带有N个元素的信号 v v v。对 v v v进行Haar分解得到g和h,它们分别是原始信号的低通和高通分量,每个分量都有N/2个元素。 g g g和 v v v的第n个系数用下列公式重新计算:
[ g n h n ] = 1 2 [ 1 1 − 1 1 ] [ v 2 n v 2 n + 1 ] \begin{bmatrix} g_n\\ h_n\\ \end{bmatrix} =\frac{1}{\sqrt{2}} \begin{bmatrix} 1&1\\ -1&1\\ \end{bmatrix} \begin{bmatrix} v_{2n}\\ v_{2n+1}\\ \end{bmatrix} [gnhn]=21[1−111][v2nv2n+1]
变换可以递归地进行,将 g g g作为新的输入信号 v v v,在每次递归,低通系数的数量被划分成两部分。 g g g分量可以解释为相等加权的连续 v v v对的比例和, h h h分量可以被解释为它们的比例差。然而,如果选择使用Haar变换来编码点云,则必须修改变换以考虑输入点云的稀疏性。这可以通过引入权重根据点的分布进行调整来实现。因此,RAHT的递归实现可以定义如下:
[ g n l h n l ] = T [ g 2 n l + 1 h 2 n + 1 l + 1 ] , \begin{bmatrix} g_n^l\\ h_n^l\\ \end{bmatrix} =T \begin{bmatrix} g_{2n}^{l+1}\\ h_{2n+1}^{l+1}\\ \end{bmatrix}, [gnlhnl]=T[g2nl+1h2n+1l+1],
T = 1 w 1 + w 2 [ w 1 w 2 − w 2 w 1 ] , T =\frac{1}{\sqrt{w_1+w_2}}\begin{bmatrix} \sqrt{w_1}&\sqrt{w_2}\\ -\sqrt{w_2}&\sqrt{w_1}\\ \end{bmatrix}, T=w1+w21[w1−w2w2w1],
w n l = w 1 + w 2 , w_n^l=w_1+w_2, wnl=w1+w2,
w 1 = w 2 n l + 1 , w 2 = w 2 n + 1 l + 1 , w_1=w_{2n}^{l+1}, w_2=w_{2n+1}^{l+1}, w1=w2nl+1,w2=w2n+1l+1,
其中l为分解级别, w 1 w_1 w1和 w 2 w_2 w2为l+1级的 g 2 n l + 1 g^{l+1}_{2n} g2nl+1和 g 2 n + 1 l + 1 g^{l+1}_{2n+1} g2n+1l+1低通系数的权重, w n l w^l_n wnl为l级的低通系数 g n l g^l_n gnl的权重。因此,对密集区域点赋予更高的权值,使RAHT比非自适应变换能更好地平衡变换域内的信号。
RAHT的[定点公式][https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8777188]在中提出。它基于矩阵分解和量化步骤的标度。仿真表明,定点实现可以被认为等效于它的浮点对等物。
最近,在RAHT中提出了一种变换域预测[63],并在目前的测试模型TMC13中可用。其主要思想是,对于每个块,从d - 1处的属性和解码后计算出经过转换后的d级属性和上转换后的属性和,作为对d级属性和转换后的属性和的预测,生成可进一步量化和熵编码的高通残差。上转换过程是通过对相邻节点加权平均来完成的。图12显示了前面描述的预测方案的简化示意图。在没有预测的情况下,报告的RAHT公式增益显示了率失真感的显著改善(颜色的总体平均增益高达30%左右,反射率为16%)。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VqXyrFL4-1689735803822)(https://oss.xljsci.com//literature/42743910/page0/1689733913326.png)]
图12。在RAHT中转换变换域预测的例子。
预测/提升变换
预测变换是一种基于距离的属性编码预测方案。它依赖于详细级别(LoD)表示,该表示使用确定性的欧几里德距离准则将输入点分布在细化级别®集合中。图13显示了一个示例点云的例子,它按照原来的顺序组织,并重新组织为三个细化级别,以及相应的详细级别( L o D 0 、 L o D 1 和 L o D 2 LoD_0、LoD_1和LoD_2 LoD0、LoD1和LoD2)。可以注意到,详细级别L是通过取0到L的细化级别的并集获得的。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-k3VwKdiR-1689735803822)(https://oss.xljsci.com//literature/42743910/page0/1689733998826.png)]
图13。详细级别(LoD)生成过程
点的属性使用由LoD顺序决定的预测进行编码。以图13为例,只考虑 L o D 0 LoD_0 LoD0。在这个情况下,P2的属性可以通过它的最近邻居P4、P5或P0的重构版本来预测,或者通过这些点的基于距离的加权平均来预测。可以指定预测候选的最大数量,编码器为每个点确定最近邻的数量。此外,还进行了邻域可变性分析。如果给定点P的邻域(编码器为每个点确定的最近邻?)内任意两个属性之间的最大差异大于阈值,则使用率失真优化程序来控制最佳预测器。默认情况下,细化级别R(j)的属性值总是使用其前一个LoD中最近邻的k个属性值来预测,即LoD(j - 1)。但是,将flag设置为1可以实现相同细化级别的预测[64],如图14所示。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nFI83JUh-1689735803822)(https://oss.xljsci.com//literature/42743910/page0/1689734029939.png)]
图14。LoD引用方案。
预测变换
预测变换采用基于LoD结构的两个运算符,即分割算子和合并算子。设L(j)和H(j)分别为LoD(j)和R(j)关联的属性集。分割算子以L(j + 1)作为输入,返回低分辨率样本L(j)和高分辨率样本H(j)。合并算子取L(j)和H(j),返回L(j + 1),预测方案如图15所示。首先,将代表整个点云的属性信号L(N + 1)分解为H(N)和L(N)。然后用L(N)预测H(N),并计算残差D(N)。在那之后,这个过程递归地进行。通过级联合并操作得到重构的属性。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-clPKRgUY-1689735803822)(https://oss.xljsci.com//literature/42743910/page0/1689734070071.png)]
图15。正、逆预测变换。
提升变换
提升变换是建立在预测变换之上的,如图16所示。该算法引入了更新算子和自适应量化策略。在LoD预测方案中,每个点都与一个影响权重相关联。在较低的LoDs中的点被更频繁地使用,因此,对编码过程的影响更大。更新算子根据残差D(j)确定U(j),然后用U(j)更新L(j)的值,如图16所示。更新信号U(j)是残差D(j)、预测点与相邻点之间的距离及其对应权值的函数。最后,为了指导量化过程,将与每个点相关的变换系数乘以它们各自的权值的平方根。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-K06bmilw-1689735803823)(https://oss.xljsci.com//literature/42743910/page0/1689734151313.png)]
图16。正反预测/提升变换。
V.点云压缩性能
在本节中,我们将展示V-PCC在AR/VR用例中的性能,即对动态点云序列进行编码,以及G-PCC在遗产收集和自动驾驶中的性能。几何和属性使用最新的参考软件(TMC2v8.0和TMC13v7.0)编码,遵循由MPEG组设置的通用测试条件(CTC)。此外,压缩伪迹引起的失真使用pc_error工具进行测量,其中除了点对点(D1)和点对平面(D2)的几何失真外,还报告了PSNR和比特率方面的属性失真。在我们的模拟中使用的PCC数据集的部分如图17所示。本文给出的结果可以通过CTC来重现。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J308JMcz-1689735803823)(https://oss.xljsci.com//literature/42743910/page0/1689735639687.png)]
图17。点云测试集, (a) Longdress, (b) Red and Black, © Soldier, (d) Head, (e) Ford.
A) V-PCC性能
这里我们展示了TMC2编码动态点云序列的压缩性能,例如Longdress,Red and Black,和 Soldier sequences。它们是由一个人的10秒点云序列以每秒30帧的速度组成的。每个点云帧大约有100万个点,具有体素化的位置和RGB颜色属性。自标准化过程开始以来,参考软件的性能有了显著的提高,如图18所示。例如,对于Longdress序列,TMC2v8.0与TMC2v1.0相比,点对点度量(D1)的BD-rate节省了约60%,luma属性的BD-rate节省了约40%。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-y4gbOqU3-1689735803823)(https://oss.xljsci.com//literature/42743910/page0/1689735667398.png)]
图18。TMC2v1.0 vs TMC2v8.0,(a)点对点几何失真(D1),(b)点对平面几何失真(D2),©Luma属性失真。
点对点和点对面度量都显示了所采用技术的效率。此外,还可以验证属性RD性能的改进。由于TMC2的压缩性能依赖于现有的视频编解码器,其改进主要来自于编码器的优化,如以时间一致性方式在帧间分配补丁,或补丁生成器对视频编码器的运动估计指导。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9QCfEudB-1689735803824)(https://oss.xljsci.com//literature/42743910/page0/1689735696702.png)]
图19。使用PCC渲染软件主观质量,(a) 2.2 Mbps的Longdress, (b) 10.9Mbps的Longdress, © 25.2 Mbps的Longdress。
图19给出了使用MPEG PCC参考渲染软件绘制的编码序列的可视化图。在最新的TMC2版本8中,10-15Mbps比特流提供了超过70db的良好视觉质量,而初始的TM v1需要30-40Mbps才能达到同样的质量。
B) G-PCC performance
有不同的编码场景涉及几何表示(八叉树或trisoup)、属性转换(RAHT、预测或提升变换)以及压缩方法(有损、无损和接近无损)。根据使用场景,选择这些工具的子集。在本节中,我们将比较使用无损八叉树几何和有损属性压缩方案的RAHT和预测/提升变换。给出了代表特定用例的两个点云的结果。第一个点云(head_00039_vox12,约1400万个点)是文化遗产应用的一个例子。在这个用例中,点云是密集的,并且需要保留颜色属性。第二个点云(ford_01_q1 mm,约80000点/帧)实际上是一个点云序列,代表了自动驾驶应用。在这个用例中,点云非常稀疏,一般情况下需要保存反射信息。图20(a)显示了RAHT(带和不带变换域预测)和提升变换编码的head_00039_vox12的亮度PSNR图(Y-PSNR)。图20(b)显示了使用相同的属性编码器编码的ford_01_q1 mm的反射PSNR图(R-PSNR)。如前所述,在这两种情况下,几何都是无损编码的。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lem7yPl2-1689735803824)(https://oss.xljsci.com//literature/42743910/page0/1689735745695.png)]
图20。G-PCC编码性能的例子。
PSNR图表明,对于head_00039_vox12,具有变换域预测的RAHT在亮度率失真方面优于无预测的RAHT和提升变换。对于ford_01_q1mm, RAHT优于提升变换;然而,关闭变换域预测会产生更好的结果。
对于无损几何和无损属性压缩,采用了预测变换。在本例中,考虑到几何和属性,head_00039_vox12和ford_01_q1mm的压缩比分别约为3比1和2比1。考虑CTC中所有的点云,平均压缩比约为3比1。在[69]中对开源3D编解码器Draco进行了比较。对于同一点云,在这两种情况下,观察到的Draco压缩比都在1.7左右。同样,考虑到所有CTC的点云,Draco的平均压缩比约为1.6比1。总的来说,当前的TMC13实现在无损压缩方面的性能是Draco的2倍。
VI.结论
近年来三维捕获技术的发展为三维视觉数据的捕获和生成提供了巨大的机遇。PCC标准化工作的一个独特方面是视频编码和计算机图形学专家的联合参与,共同提供一个结合了2D视频编码和计算机图形学最新技术的3D编解码标准。
在本文中,我们介绍了与PCC相关的主要概念,如点云体素化、三维到二维投影和三维数据结构。此外,我们还概述了当前V-PCC和G-PCC标准测试模型中使用的编码工具。对于V-PCC,讨论了补丁生成、包装、几何、占用图、属性图像生成和填充等主题。对于G-PCC,讨论了诸如八叉树、三组几何编码和三维属性转换(如RAHT和预测/提升)等主题。本文给出了两种编码体系结构压缩性能的一些演示结果,结果表明,考虑到动态点云序列、世界遗产收集和自动驾驶等用例,这些工具在PCC中实现了当前最先进的性能。
人们期望这两个PCC标准为新市场提供有竞争力的解决方案,满足各种应用程序需求或用例。在未来,MPEG也在考虑将PCC标准扩展到新的用例,比如V-PCC的动态网格压缩,以及包括新的工具,比如G-PCC的inter coding。对于感兴趣的读者,MPEG PCC网站[70]提供了更多的信息资源,以及V-PCC和G-PCC的最新测试模型软件。

















 1283
1283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}