






Deep Residual Learning for Image Recognition
用于图像识别的深度残差学习
2016 CVPR最佳论文;
论文一作:何恺明;
何恺明其他著作:Mask R-CNN和PReLU等;
机构:微软亚洲研究院(Microsoft Research);
本文提出ResNet(ResNet-50/ResNet-101/ResNet-152),152层的网络,CNN的又一里程碑,超越人类的水平;
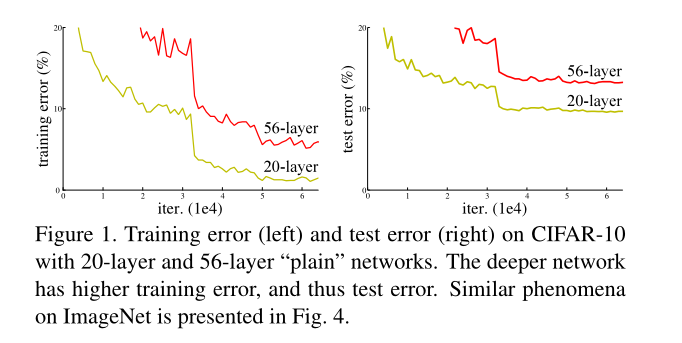
ResNet引入残差连接(short cut connection),解决网络退化问题:训练集误差大,测试集误差大;
在2015年的ImageNet分类/定位/目标检测和2015年的COCO目标检测/分割中都获得了冠军;
发表时间:[Submitted on 10 Dec 2015];
发表期刊/会议:Computer Vision and Pattern Recognition;
论文地址:https://arxiv.org/abs/1512.03385;
0 摘要
更深层的神经网络更难训练;
本文提出一个残差学习框架来简化网络的训练,提出的网络要比以往的网络架构更深;
本文明确的对学习的架构进行了重构,之前的网络学习出/拟合出一个分布,现在的网络用来拟合相对于上一层的残差(residual);
本文进行了全面的实验证明这些残差网络的性能更好,并且可以显著的从网络深度中获得精度的收益;
提出ResNet-152——比VGG深8倍,但是模型复杂度比VGG低;
1 简介
深度网络以端到端的多层方式自然地集成了低层/中层/高层特征和分类器,网络越深,提取到的特征就越丰富;
直接将网络堆叠到很深可以么?
——梯度消失/梯度爆炸问题,可以通过归一化或各种初始化技巧解决;
——网络退化(degradation)问题,深层网络在训练集和测试集的结果都变得差,如图1所示(退化问题不是过拟合问题,过拟合在训练集表现很好,在测试集表现差);
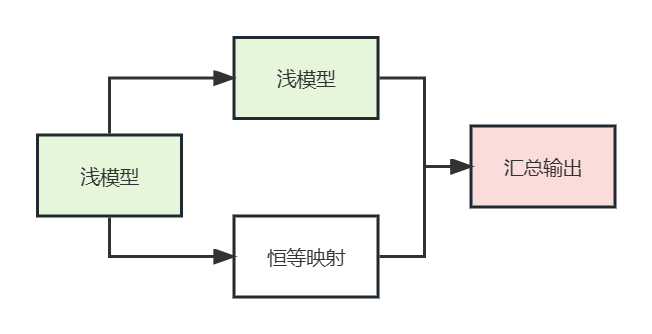
解决网络退化问题的一个方案:
浅模型的输入变为两个分支,一个分支不变(identity mapping),另一个分支同样用浅模型来处理,最后将结果汇总,这样加深网络至少保证网络性能不会下降;
——但是,这是个递归结构,很难优化,无法求解;
本文为了解决退化问题,提出一个深度残差学习框架(deep residual learning framework),模型不再拟合原先底层的映射 H ( x ) H(x) H(x),而是去拟合相对于输入的残差 F ( x ) = H ( x ) − x F(x) = H(x) - x F(x)=H(x)−x,如图2所示:
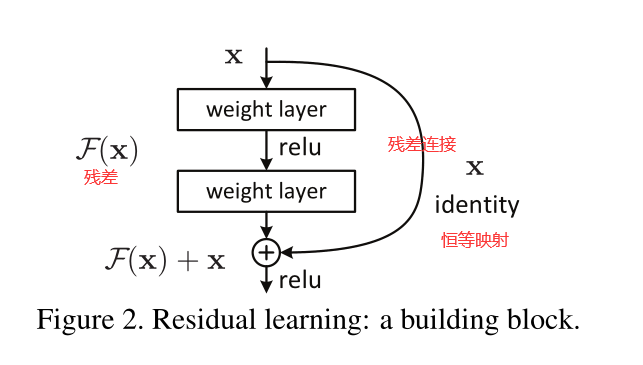
把图2所示的连接方式称为残差连接“shortcut connections”,或者称为恒等映射"identity mapping";
identity mapping不会引入额外的参数或者计算量,整个网络仍然可以用SGD进行端到端的训练;
在ImageNet上进行了综合实验:
- 极深残差网很容易优化(不会出现退化现象),但如VGG这种深层网络会出现退化问题;
- 本文的深度网络可以提升各项计算机视觉任务的性能;
在CIFAR-10数据集上,实现了100层网络和1000层网络进行实验;
2 相关工作
Residual Representations
Shortcut Connections
3 深度残差学习
3.1 残差学习
H ( x ) H(x) H(x):底层映射,原本的结果;
x x x:该层的输入;
根据万能近似定理 (universal approximation theorem),我们不直接去拟合/学习 H ( x ) H(x) H(x),而是学习相对于输入的残差 F ( x ) = H ( x ) − x F(x) = H(x) - x F(x)=H(x)−x(假设输入与输出维度是相同的);
最后将加上残差,就和原来学习底层映射效果是一样的,但是网络更容易学习了;
加了恒等映射后,深层网络至少不会比浅层网络学的差,如果当前的恒等映射已经是最优的了,那残差模块只需拟合零映射即可(非常好学习);
在实际情况下,恒等映射都不太可能是最优的,因此残差结构有助于解决这个问题,通过对输入进行处理来解决;
注: 万能近似定理(universal approximation theorem),是深度学习最根本的理论依据。它声明了在给定网络具有足够多的隐藏单元的条件下,配备一个线性输出层和一个带有任何“挤压”性质的激活函数(如logistic
sigmoid激活函数)的隐藏层的前馈神经网络,能够以任何想要的误差量近似任何从一个有限维度的空间映射到到另一个有限维度空间的Borel可测的函数。
3.2 通过shorcuts完成恒等映射
对每层都使用残差连接来学习,如下式表述:
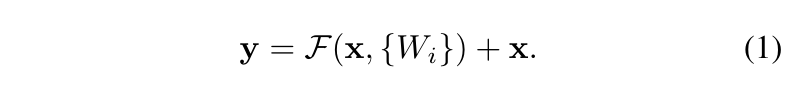
x
x
x:某层输入向量;
y
y
y:某层输出向量;
F
(
x
,
W
i
)
F(x,{W_{i}})
F(x,Wi):残差网络的输出;
也可以写作:
F
=
W
2
σ
(
W
1
x
)
F = W_{2}σ(W_{1}x)
F=W2σ(W1x)(对应于图2);
将两个结果进行逐元素相加(element-wise addition),得到输出结果 y y y;
要求 F F F与 x x x结果大小必须相同,如果不同,则需要对恒等映射进行一次线性变换;
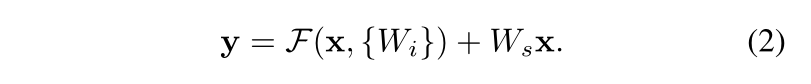
残差函数 F F F的形式是灵活多样的,可以是图2那样的2层,也可以是3层或更多,如图5右所示;
但如果只有一层,残差学习就没有优势了,这时候相当于线性层;

3.3 网络架构
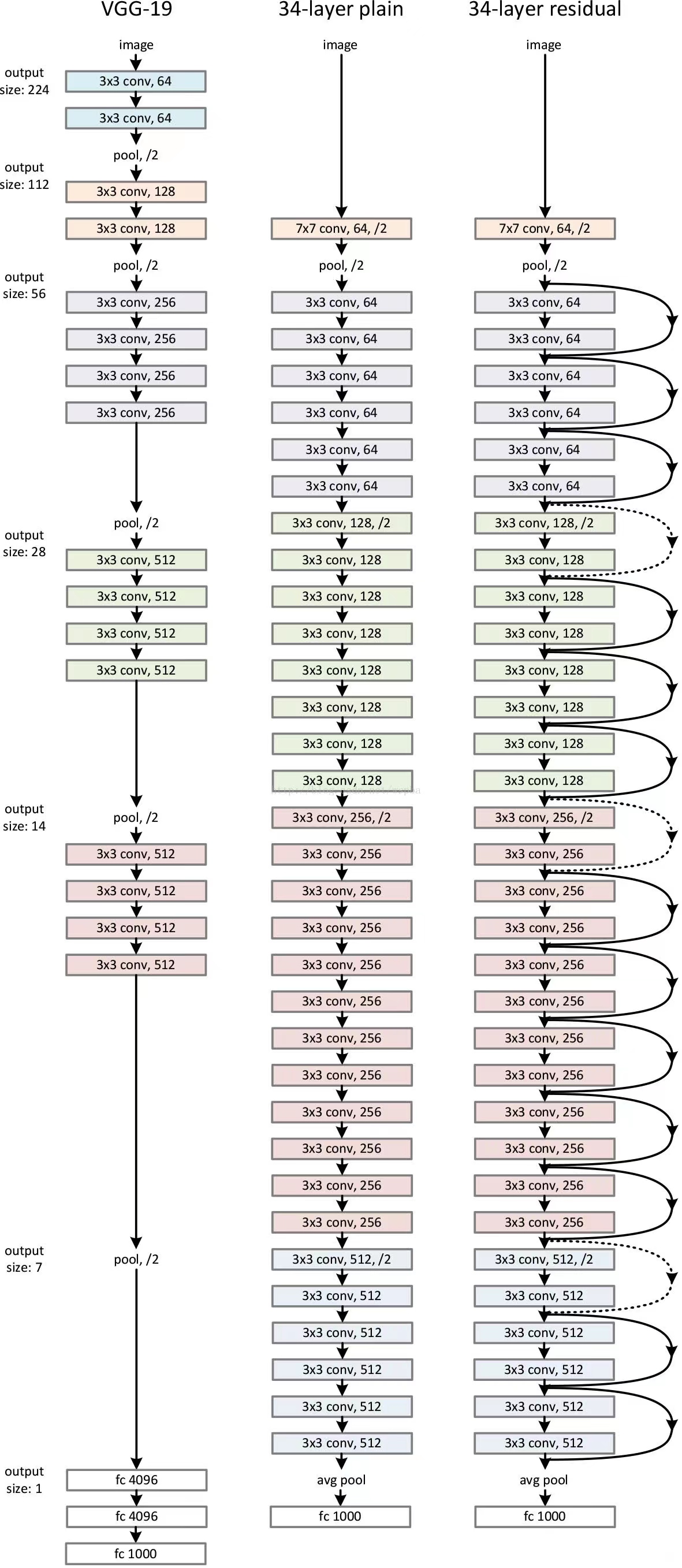
Plain Network普通网络:如图3中间的图所示;
- 和VGG类似;
- 3×3卷积;
- 每一个block内,特征图不变,卷积核个数不变;
- block之间,特征图减半,卷积核个数增加一倍;
- 通过步长为2的卷积层直接执行下采样(VGG使用GAP);
- 此模型参数是VGG的18%;
Residual Network残差网络:如图3左示意;
- 残差连接为实线:表示维度相同;
- 残差连接为虚线:表示维度不同,升维的两种方式:
- 1:对多出来的通道进行padding 0操作,没有引入额外参数;
- 2:做1×1卷积,进行升维/降维,引入额外参数;
import torch as t
from torch import nn
from torch.nn import functional as F
class ResidualBlock(nn.Module):
def __init__(self,inchanel,outchanel,stride=1,shortcut=None):
super(ResidualBlock,self).__init__()
self.left=nn.Sequential(
nn.Conv2d(inchanel,outchanel,3,stride,1,bias=False),
nn.BatchNorm2d(outchanel),
nn.ReLU(inplace=True),
nn.Conv2d(outchanel,outchanel,3,1,1,bias=False),
nn.BatchNorm2d(outchanel)
)
self.right=shortcut
def forward(self, x):
out=self.left(x)
residual = x if self.right is None else self.right(x)
out += residual
return F.relu(out)
class ResNet34(nn.Module):
def __init__(self,num_classes=1000):
"""
构建ResNet34网络的各层结构
:param num_classes:
"""
super(ResNet34,self).__init__()
self.pre=nn.Sequential(
nn.Conv2d(3, 64, 7, 2, 3, bias=True),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(3,2,1)
)
self.layer1 = self.__make_layer__(64,128,3)
self.layer2 = self.__make_layer__(128,256,4,stride=2)
self.layer3 = self.__make_layer__(256,512,6,stride=2)
self.layer4 = self.__make_layer__(512,512,3,stride=2)
self.fc = nn.Linear(512, num_classes)
def __make_layer__(self,inchannel,outchannel,block_num,stride=1):
"""
构建layer,包含多个residual block
:param inchannel:
:param outchannel:
:param block_num:
:param stride:
:return:
"""
shortcut = nn.Sequential(
nn.Conv2d(inchannel,outchannel,1,stride,bias=False),
nn.BatchNorm2d(outchannel)
)
layers = []
layers.append(ResidualBlock(inchannel,outchannel,stride,shortcut))
for i in range(1,block_num):
layers.append(ResidualBlock(inchannel,outchannel))
return nn.Sequential(*layers)
def forward(self, x):
x = self.pre(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = F.avg_pool2d(x,7)
x = x.view(x.size(0),-1)
return self.fc(x)
3.4 实现细节
- 图像增强,图像大小调整为[256,480]之间;
- 原图或镜像翻转中随机裁剪224×224大小图像,并减去每像素平均值;
- 颜色增强;
- BN;
- 遵循PRelu的权重初始化方法;
- SGD,mini-batch = 256;
- learning rate: 0.1,遇到瓶颈则/10;
- epoch:60 * 10 ^4;
- weight decay: 0.0001;
- momentum: 0.9;
- 没有dropout(不与BN共存);
- 测试:10-crop testing;
- 测试:多尺度裁剪&特征融合;
4 实验
4.1 ImageNet分类
4.1.1 普通网络和残差网络对比
图4,左图,普通18层网络(plain-18)和普通34层网络(plain-34)在验证集上的误差,普通网络出现退化问题(网络越深,误差越大);
右图,resnet网络,34层网络误差比18层网络误差小,没有出现退化现象(所用网络架构与plain网络相同,只是多了残差连接);
并且带残差的网络收敛更快;
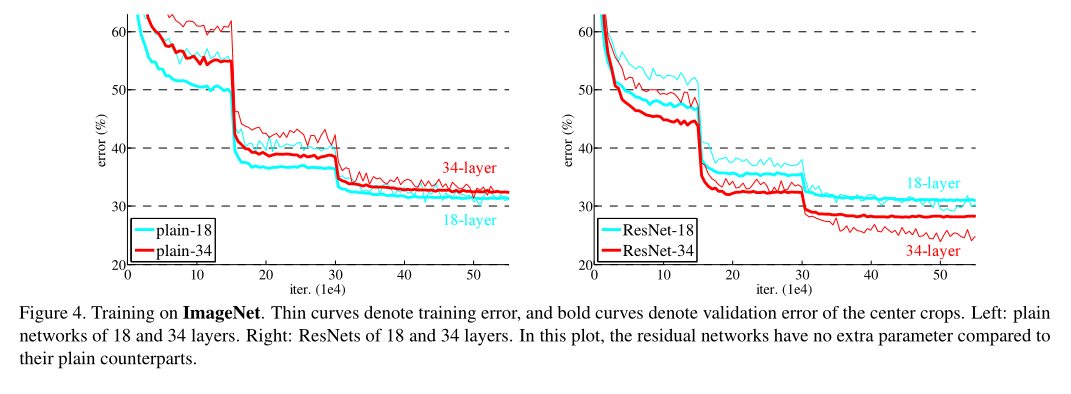
具体数值见表2:

这种深层网络的优化困难不是由于梯度消失引起的;普通网络也引入了BN(防止梯度消失),普通网络的前向传播和反向传播都没有问题,本文也验证了传回来的梯度,都是正常的;这也不是过拟合问题;
网络深度可能会影响收敛速度;
4.1.2 Identity vs. Projection Shortcuts
在shorcut是恒等映射(identity mapping)更好还是有一些处理好(projection shortcut)?
实验结果如表3所示:
- ResNet-34-A:所有shortcut都是恒等映射,在升维的时候用padding 0操作,没有额外参数(identity mapping);
- ResNet-34-B:一般的shortcut用恒等映射,在升维的时候用1×1卷积,引入额外参数(projection shortcut);
- ResNet-34-C:所有shortcut都用1×1卷积,引入额外参数(projection shortcut);
实验结果:C最好,B比A好;

但A/B/C之间的微小差异表明,projection shortcut对于解决退化问题并不重要。因此,我们在本文的其余部分中不使用选项C,以减少内存/时间复杂性和模型大小;
identity mapping对于不增加下面介绍的瓶颈架构的复杂性尤为重要;
4.1.3 Deeper Bottleneck Architectures
图5左:普通残差模块,用于ResNet-18、ResNet-34;
图5右:bottleneck残差模块,用于ResNet-50、ResNet-101、ResNet-152,用来减少参数量和计算量,1×1卷积负责升维;

无参数的shortcut(也就是identity mapping)对于bottleneck架构是非常重要的;如果图5右架构的shortcut被换成其他projection映射,时间复杂度、模型大小都会翻倍,因为shortcut连接的是两个高维向量;
因此,identity shortcut为瓶颈设计提供了更有效的模型。
4.1.4 50-layer ResNet
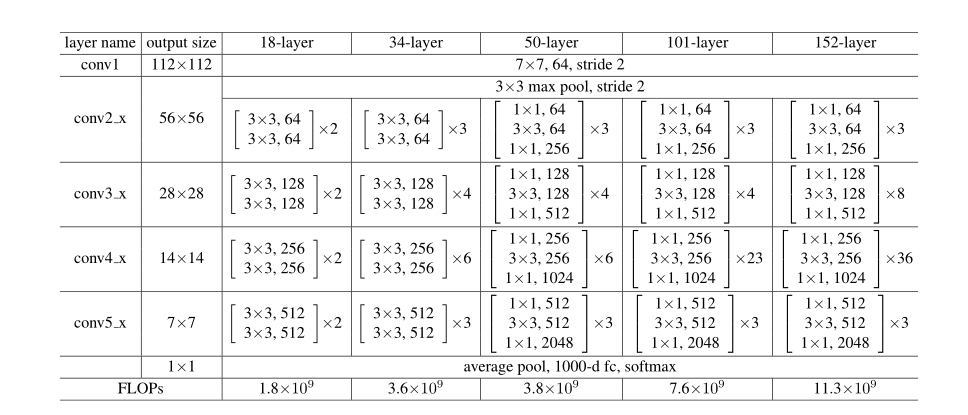
用3个bottleneck残差替换ResNet-34中的2层普通残差块得到ResNet-50,如表1所示;
shortcut使用B方案(普通层用恒等映射,其他用1×1升维),该模型有3.8 billion FLOPs;
4.1.5 101-layer and 152-layer ResNets
用更多的3层的bottleneck残差构建了ResNet-101和ResNet-152,尽管深度显著增加,152层ResNet(113亿FLOP)的复杂性仍低于VGG-16/19网络(153/196亿FLOPs);
模型对比结果见表3表4:
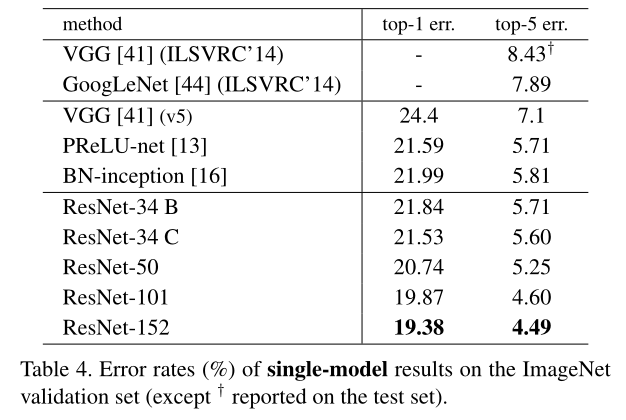
其他resnet网络架构:
4.1.6 Comparisons with State-of-the-art Methods
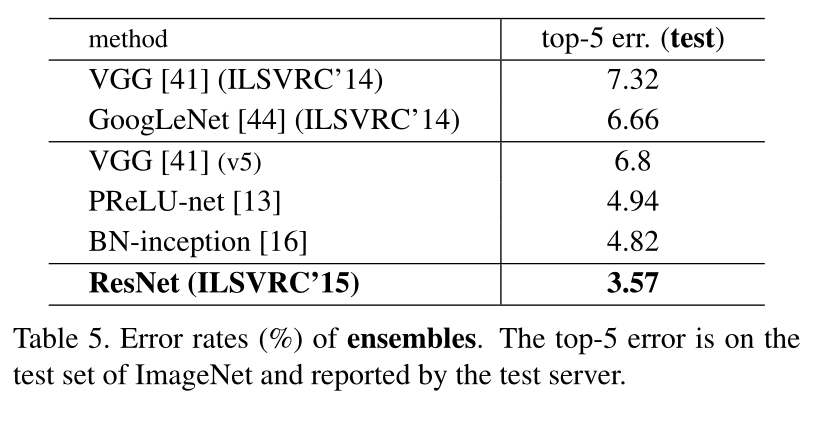
结果见表4、表5:
ResNet-152单模型性能超过了过去所有的多模型集成结果;
4.2 CIFAR-10 and Analysis
在CIFAR-10数据集进行实验,数据集包含10类,共50k训练集+10k测试集;
使用图3中及右的plain architecture 和 residual architechure,网络输入为32 × 32(减去均值);
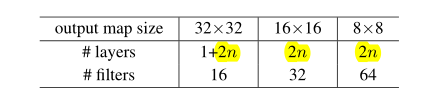
第一层是3×3卷积,之后有6n层,分别在{32, 16, 8}大小的特征图上使用,每个特征图有2n层,如下表所示;
feature map大小减半,filter数量翻倍;
用步长为2的卷积来进行降采样,共有6n+2个带权重的层;
shortcut在每一对3×3层来进行连接(一共有6n / 2 = 3n个shortcut),用A方案的shortcut(所有的都是恒等映射);
所以plain-network和residual-network具有同样的深度、宽度、参数;
结果如图6所示:
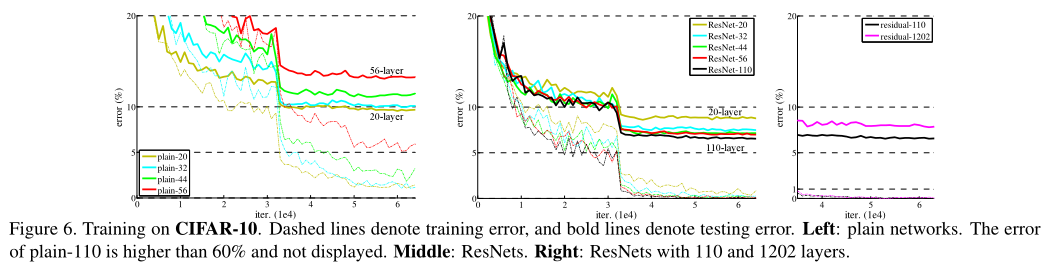
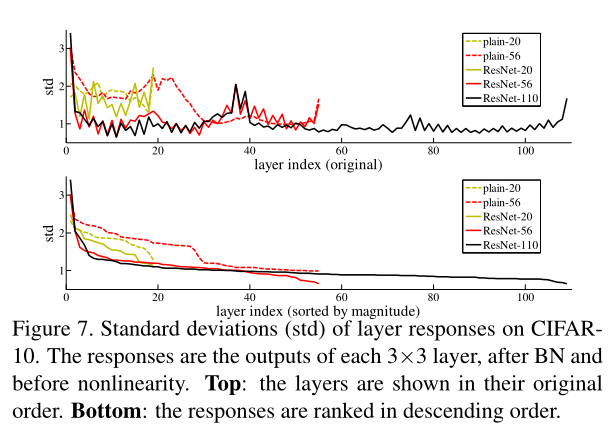
图7可视化了在CIFAR-10数据集上,各层相应的标准差;
top:
plain-network:越靠近起始层,输出越大,调整越大(大刀阔斧的改);ResNet输出小,调整小;
bottom:排序后,ResNet网络的相应都低于plain网络;
Exploring Over 1000 layers
图6右图显示了1000多层网络的性能;
n = 200, 得到1202层网络,该网络没有优化上的困难;
训练误差<0.1%;
测试集误差也很小;
但是,1202层的网络性能没有110层的网络性能好,这可能是过拟合的原因,1202层的网络对于CIFAR-10数据集来说可能太大了;
需要很强的正则化手段可能会改善;
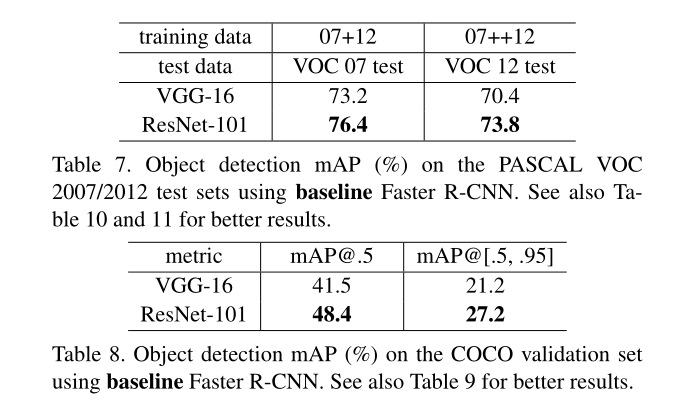
4.3 Object Detection on PASCAL and MS COCO














 6198
6198











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









