




 提出Grad-CAM技术,一种通用的可视化解释方法,适用于多种CNN架构,无需改变模型即可生成类激活映射,帮助理解深层网络的决策过程。
提出Grad-CAM技术,一种通用的可视化解释方法,适用于多种CNN架构,无需改变模型即可生成类激活映射,帮助理解深层网络的决策过程。
《Grad-CAM:Visual Explanations from Deep Networks via Gradient-based Localization》
《Grad-CAM:基于梯度定位的深层网络可视化解释》
发表于:
[v1] CVPR(Computer Vision and Pattern Recognition)Oct 2016 2016;
[v2] IJCV(International Journal of Computer Vision)3 Dec 2019 (2022IF:13.369);
注:CVPR是计算机视觉领域三大顶会中唯一一个年度学术会议。
代码:https: //github.com/ramprs/grad-cam/;
视频演示:youtu.be/COjUB9Izk6E;
Grad-CAM 可视化 可解释性;
0摘要
本文提出的方法:梯度加权类激活映射(Gradients weighted Class Activation Mapping:Grad-CAM),使用任何目标概念的梯度,流入最终的卷积层,生成一个粗略的定位图,突出显示图像中用于预测概念的重要区域。与以前的方法不同,Grad-CAM适用于各种CNN模型系列:
(1) 具有完全连接层的CNN(例如VGG);
(2) 用于结构化输出的CNN(例如字幕captioning);
(3) CNN用于具有多模式输入(例如,视觉问答)或强化学习的任务,无需更改架构或再训练;
本文将Grad-CAM与现有的细粒度可视化相结合,创建一个高分辨率的类判别可视化方法:Guided Grad-CAM,并将其应用于图像分类、图像字幕和可视化问答模型,包括基于Res-Net的体系结构。在图像分类模型的上下文中,本文的可视化:
(a) 洞察这些模型的失效模式(表明看似不合理的预测有合理的解释);
(b) 在ILSVRC-15弱监督定位任务上优于以前的方法;
(c) 更忠实于基础模型;
(d) 通过识别数据集偏差帮助实现模型泛化;
对于图像字幕和VQA,本文的可视化显示,即使是非基于注意力的模型也可以定位输入。最后,本文设计并进行了人体研究,以衡量Grad-CAM解释是否有助于用户建立对深度网络预测的适当信任,并表明Grad-CAM帮助未经训练的用户成功区分“更强”的深度网络和“较弱”的深度网络。
1简介
[背景] 可解释性在AI进化的三个阶段的作用:
- AI弱于人类水平:可解释性的目的在于确定失败模式,给研究人员提供方向;
- AI与人类水平相当:在用户中建立对网络模型适当的信任和信心;
- AI明显强于人类水平:可视化的目标是在机器教学;
[背景] 在准确性和可解释性之间存在一种平衡:
- 神经网络深度越高,准确性越高,可解释性越低;(黑盒)
- 经典的基于规则的或专家系统具有高度可解释性,但准确性低(或不够健壮);
[前人已有工作] Zhou等人提出了一种称为CAM(Class Activation Mapping)的技术,用于识别不包含任何FC层的有限类图像分类的区域,有以下缺点:
-
改变网络架构(权衡准确度和可解释性);
-
不适用于其他任务(如VQA);
见 [Zhou. Learning Deep Features for Discriminative Localization. In CVPR, 2016]
[本文模型] Grad-CAM:是CAM的推广,适用范围更广:
- 适用具有FC层的CNN(如VGG);
- 适用具有结构化输出的CNN(如Image Captioning);
- 使用具有多模式输入(如VQA)或强化学习任务;
[什么是好的视觉解释性?] 任何目标类别的好的视觉解释应该是
(a)类别区分(即在图像中定位类别);
(b)高分辨率(即捕捉细微的细节);
如下例,图1显示了“tiger cat 虎皮猫”类和“boxer dog 沙皮狗"类的大量可视化输出结果。
引导反向传播Guided Backpropagation[42]和反褶积Deconvolution[45]是高分辨率的,并突出图像中的细粒度细节,但不具有类别区分性(见图1b和图1h非常相似)。
相比之下,像CAM或本文提出的Grad-CAM这样的定位方法具有高度的类识别性(“cat”解释仅强调图1c中的“cat”区域,而不是“dog”区域,反之亦然,见图1i)。
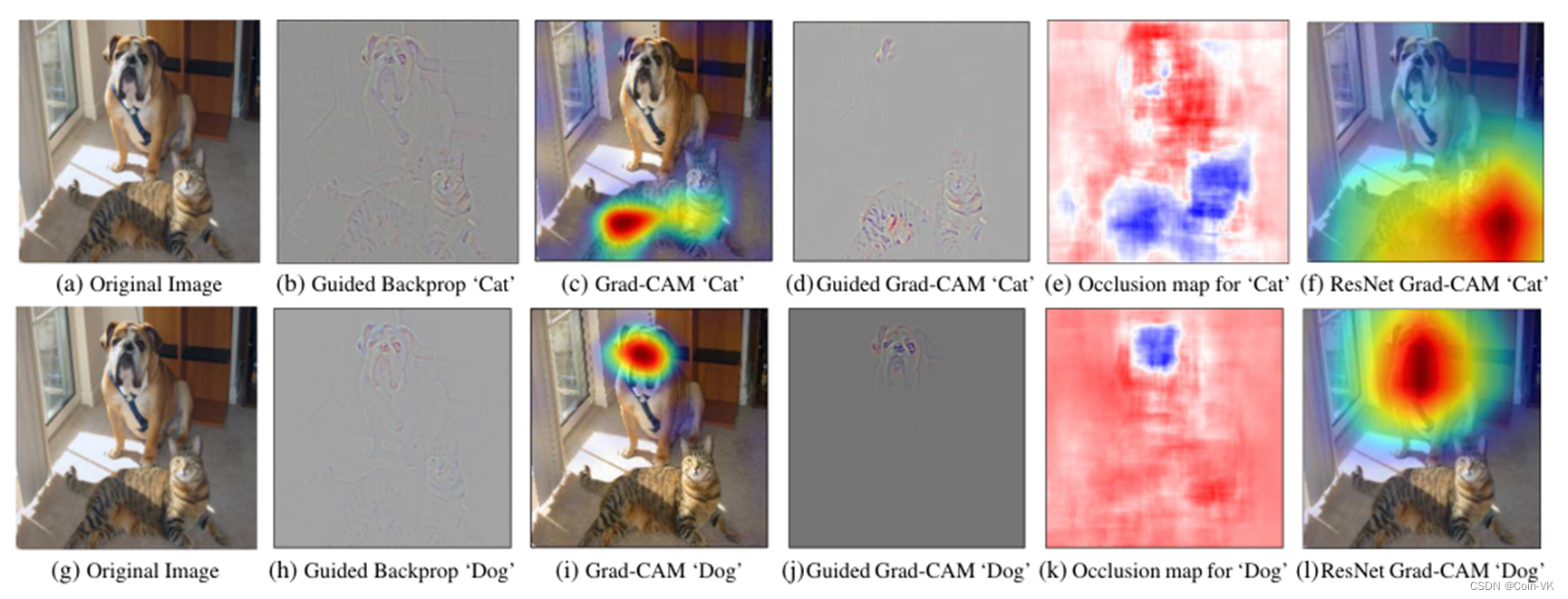
图1:(a)一只猫和一只狗的原始输入图像。(b-f)根据VGG-16和Res-Net的不同视觉效果,可视化对猫类别的支持区域。(b) Guided Backpropagation [42]: 突出所有的贡献特征。(c, f) Grad-CAM (Ours): 定位类别区分区域, (d) 结合(b)和©得到Guided Grad-CAM, 它提供高分辨率的类别区分的可视化效果。本文的Grad-CAM技术实现的定位,与©与和(e)的结果非常相似,而计算的成本却低了几个数量级。(f, l) 是ResNet-18的Grad-CAM可视化。在(c,f,i,l)中,红色区域对应的是该类的可视化证据,而在(e,k)中,蓝色对应的是该类的证据。
[本文贡献] 本文贡献如下:
- 提出Grad-CAM,一种分类识别定位技术,可以从任何CNN中生成视觉解释,而无需更改架构或重新训练;
- 评估了Grad-CAM的性能:图像分类、字幕、VQA;
- 将Res-Net应用于图像分类和VQA,从深层到浅层,Grad-CAM的辨别能力显著降低;
- 将现有的像素空间梯度可视化与Grad-CAM相融合,创造出既有高分辨率又有类别区分能力的Guided Grad-CAM可视化,Guided Grad-CAM具有类区分性,有助于人类建立对网络的信任;
2相关工作
本文的工作借鉴了最近在CNN可视化、模型信任评估和弱监督定位方面的工作。
3方法
[pipeline]
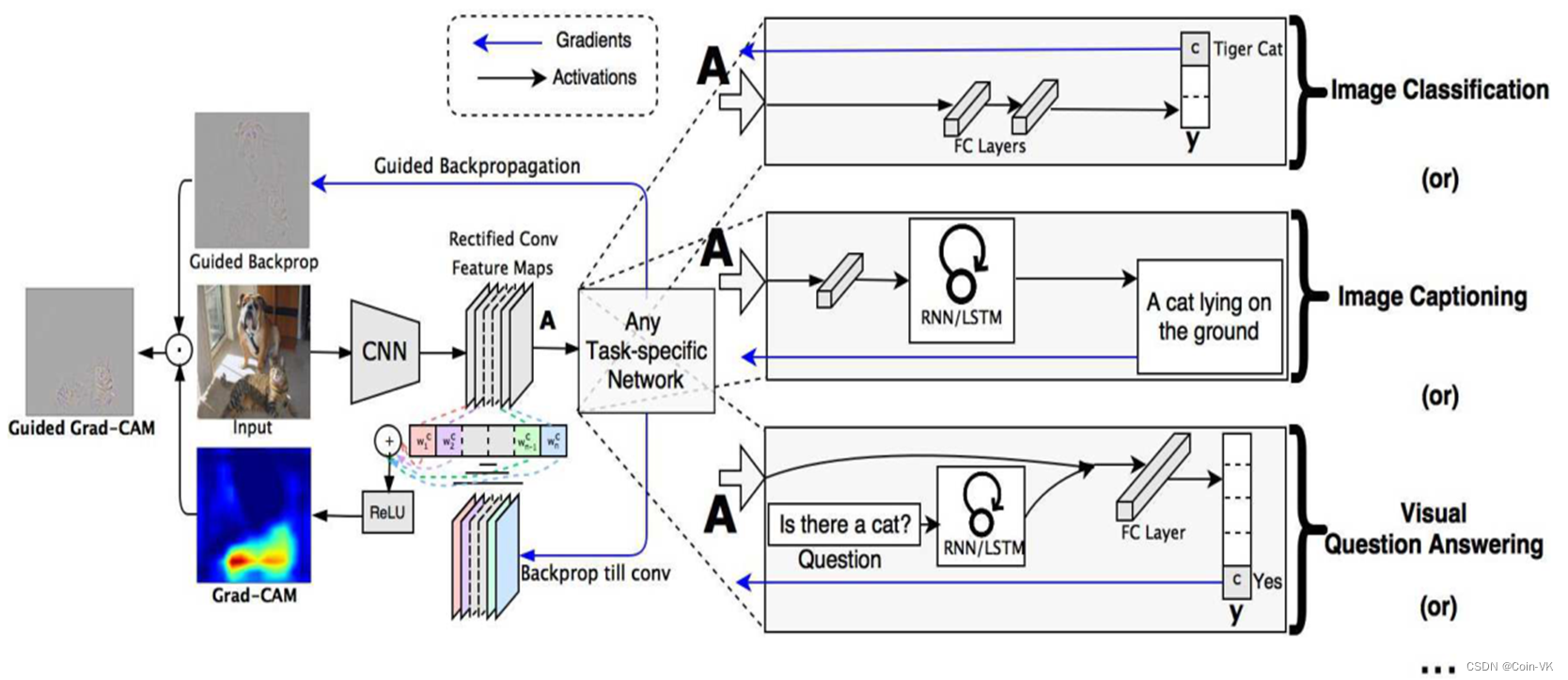
图2:Grad-CAM概述:给定一幅图像和一类感兴趣的内容作为输入,本文通过模型的CNN部分向前传播图像,然后通过特定于任务的计算获得类别的原始分数。除所需类别设置为1外,所有类别的渐变都设置为零。然后,该信号被反向传播到所关注的校正卷积特征图(Rectified Conv Feature Maps),本文结合这些特征图来计算粗糙梯度CAM定位(蓝色热图),它表示模型在做出特定决策时必须寻找的位置。最后,本文将热图与引导反向传播逐点相乘,以获得高分辨率和概念特定的Guided Grad-CAM可视化。
[pipeline 细节]
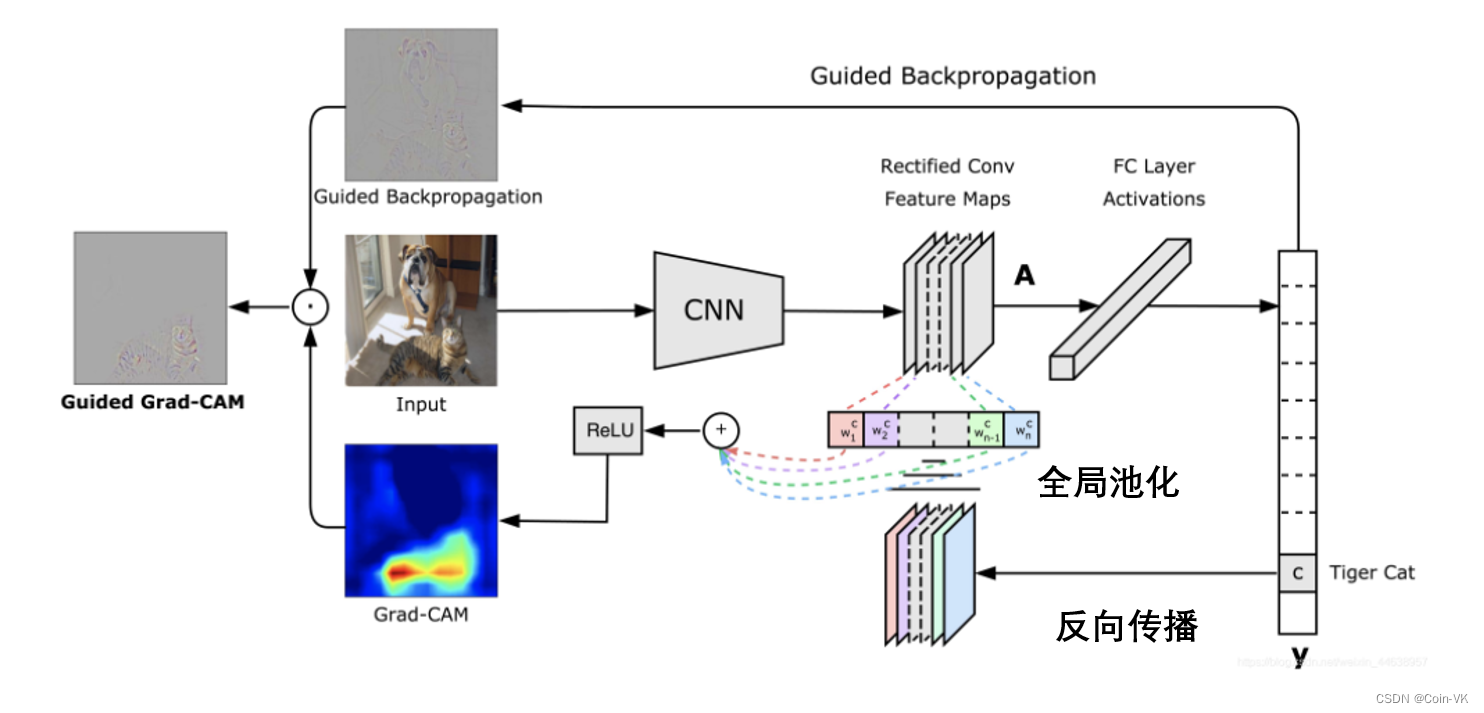
图2.1细节解释:这里的原始图像,猫作为感兴趣的区域,通过CNN模型向前传播,计算类的原始分数,然后将获得的那些分数所需的类(比如说本文关注这个猫)就将猫的类别设置为1,剩下的设置为0,然后把这个本文关注的这个信号反向传播到所关注的矫正卷积特征图(rectified conv feature maps),做了一个全局池化的操作,这里的w是权重,代表每一层feature map的重要性,然后做一个线性结合放进RELU函数,计算Grad-CAM,它表示模型在做出特定决策时必须寻找或者关注的位置。最后,将热图与引导反向传播(guided backpropaagation)逐点相乘,来获得更高分辨率和概念特定的Guided Grad-CAM可视化结果。
[计算公式]
要得到某个类别的Grad-CAM图: L G r a d C A M c ∈ R u × v L^{c}_{GradCAM}∈R^{u×v} LGradCAMc
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4986
4986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









