







 本文深入解析ResNet原理,探讨如何利用残差学习框架训练更深的网络。文章指出,ResNet并非为解决梯度消失或爆炸问题,而是针对网络深度增加导致的退化问题。文中详细介绍了ResNet的设计理念及其实现方式。
本文深入解析ResNet原理,探讨如何利用残差学习框架训练更深的网络。文章指出,ResNet并非为解决梯度消失或爆炸问题,而是针对网络深度增加导致的退化问题。文中详细介绍了ResNet的设计理念及其实现方式。
本文就是ResNet,网上感觉对ResNet误解挺多的,在ResNet论文中提到了梯度爆炸或者梯度消失,但是这不是本文要解决的问题。ResNet是通过恒等映射解决的网络退化的问题。
0、摘要
更深的DNN是非常难以训练的。我们提出了一个residual learning framework(残差学习框架)能够轻松训练一个比之前还要深得多的网络。
我们提供一个经验性的证据(实验)证明residual networks是更容易优化的,能够获得更高的精度(更容易优化就可以训练更深的网络,也就能获得更高的精度)
在ImageNet数据集上使用一个152层的残差网络(比VGG深8倍,但复杂度却更低)。残差网络的ensemble获得了3.57%的误差在ImageNet测试集上,这个结果在ILSVRC2015分类任务上赢得了第一。
深度在图像识别任务中是非常重要的,因此因为残差我们能够训练更深的网络,也因此在目标检测、分割等任务上获得了很NB的效果。
1、引言
深度网络能够整合低/中/高层级的特征然后进行分类,这些层级的特征图可以被多个堆叠的层(也就是深度)丰富,从而拥有更好的表现。最近的研究揭示了网络的深度在有调挑战性的ImageNet数据集上至关重要。
但是随着网络深度的大幅度增长,一系列问题也产生了:Is learning better networks as easy as stacking more layers?(堆叠网络很简单,那么让这些很深的网络学习到更好的表现也是这么简单吗?简而言之训练网络和搭建网络一样简单吗?)
一个臭名昭著的麻烦是:梯度消失或爆炸,这将从一开始就阻碍收敛。但是这个问题很大程度通过normalized initialization和中间的normalized layers(BN层)被解决了
(注意:所以ResNet论文不是解决梯度消失或者爆炸的,它以及被解决了)
但是一个退化问题被暴露了出来:随着网络深度的增加,当精度饱和了后,(深度继续增加)将快速 退化。(这才是本文要解决的问题)
出人意料的是这个退化不是过拟合导致的(为什么不是过拟合?因为过拟合表现为网络越大,训练集精度越高而测试集精度越低,但是从下图可以看到这里却是训练集精度和测试集精度都更差了,显然是网络还没之前训练的好)。
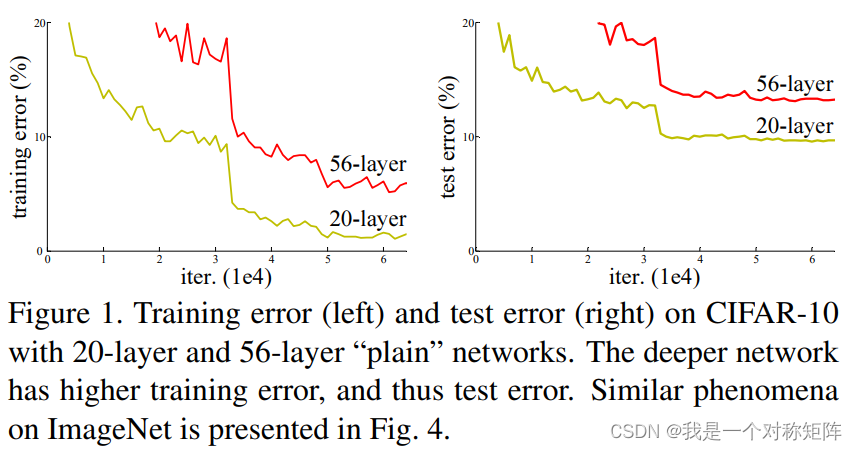
网络退化现象表明不是所有的系统都是能简单的被优化。对于网络退化问题我们可以设想一下,如果在数据集上,某个浅层的网络训练的足够好,那么再增加几层后只要这几层学到恒等映射(就是出入输出一样,不做任何改变),那么加深的层的输出应该和浅层的输出一样,至少加深的层的精度不会比浅层网络的低(最差就是学到恒等映射,那么深层网络的精度=浅层网络的精度)

但结果却是更深的网络表现比浅层网络差,这说明恒等映射不好学。比如下图,想要输入x经过两层运算后仍然输出x,恐怕就没那么简单。
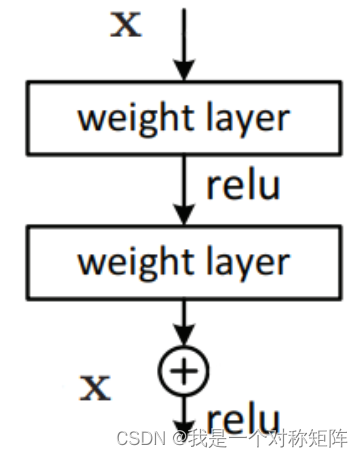
于是本文设计了一种残差网络,使得更容易学到恒等映射
为了解决这个退化问题,我们设计一个深度残差学习框架(也就是残差块),我们希望它能够学到期望的映射:
H
(
x
)
H(x)
H(x)=残差块输入到输出的映射

可以看到残差块映射可以表示为:
H
(
x
)
=
F
(
x
)
+
x
H(x)=F(x)+x
H(x)=F(x)+x。残差表示为
F
(
x
)
=
H
(
x
)
−
x
F(x)=H(x)-x
F(x)=H(x)−x,如果想学到恒等映射,就意味着输入x经过两层运算后等于0,这很简单,让这两层的参数全部等于0即可(相比于原来这两层要学到一堆复杂参数使得输入x经过运算后仍等于x,这很简单了)。(因为这里作者说了”我们假设优化残差映射比优化原始映射更加简单“)
(个人觉得:让两层参数学习到全0的确要比学习到一堆特定参数要简单,因为如果是全0则不管输入怎么变这都是恒等映射的。但是如果是原始堆叠那样学到一堆特定参数,当输入变化时,这堆参数也要变化才能维持“恒等”,相比之下这就很困难了。同时现在的模型初始化常见的都是全0初始化或者以为均值的初始化,这样来看似乎残差块在一出生就近似恒等映射了)
而另一个优点就是没有新增参数,仅仅是条件一个跳跃链接。在没有新增参数的条件下还能提高性能,确实令人喜爱。
我们在ImageNet上设计全面的实验展示退化问题和验证我们的方法:
- 我们设计的非常深的残差网是很容易优化的(对应的“朴素”网络难以训练且误差高)
- 我们的残差网络能够从更深度的网络中轻松获得精度收益,获得比之前网络更好的效果
2、Deep Residual Learning
2.1 Residual Learning
这部分的内容在引言中以及讲过了
2.2 Identity Mapping by Shortcuts
核心其实就是这个结构
用公式表示为:
y
=
F
(
x
,
W
i
)
+
x
y=F(x,{W_i})+x
y=F(x,Wi)+x
x
x
x和
y
y
y表示为输入和输出,函数
F
(
x
,
W
i
)
F(x,{W_i})
F(x,Wi)表示可被学习的residual mapping。
F + x F+x F+x是element-wise addition的shortcut connection,我们采用在两次非线性(两次卷积块)之后进行addition。
shortcut connection不新增任何参数,这除了保持模型复杂度外,还意味着能够公平地与plain网络(没有残差)比较。(因为新增参数量能够提高模型能力,那么一个模块改进后增加了参数量,其性能的提升究竟是模块改进带来的还是参数量增加带来的?事实上感觉很多论文都没有考虑这一点,这里足以见证作者地严谨性)
3、结构
实际上后面都是结构的介绍和试验了。
残差结构块有两种,第一种有两个卷积块,在ResNet18、ResNet34中应用,第二种更加复杂,在ResNet50/101/12中应用

几种不同ResNet网络结构图
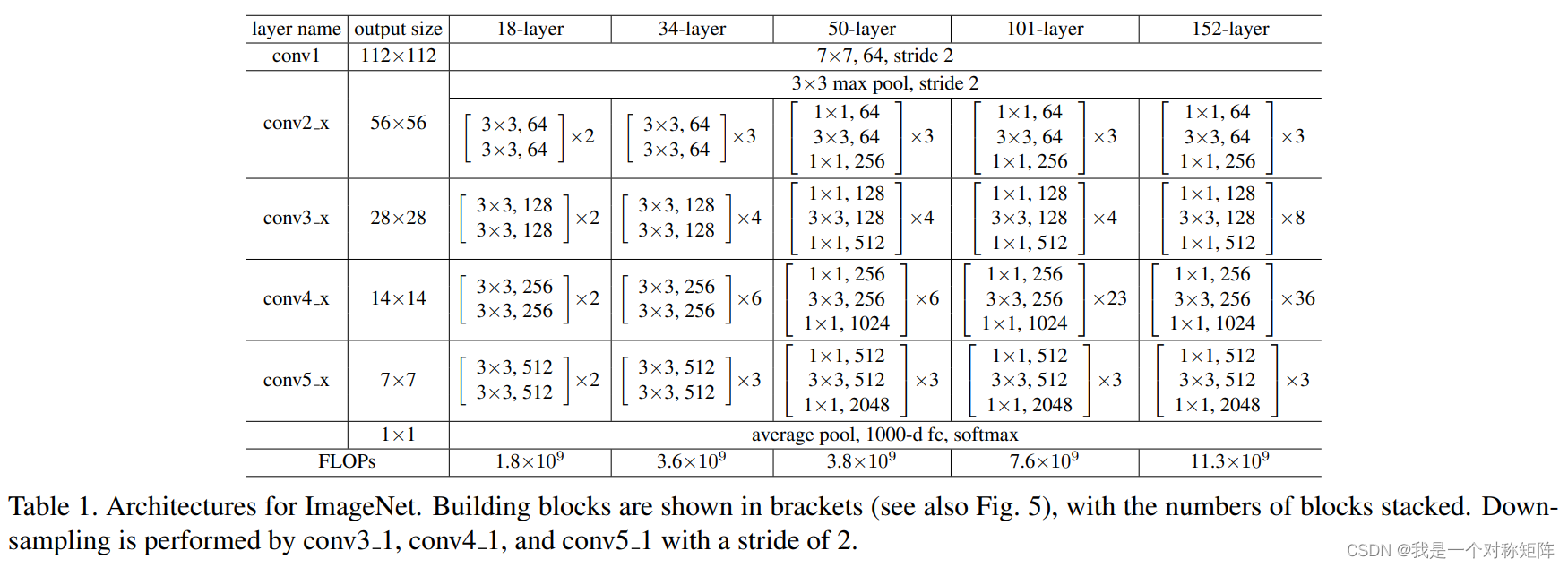
注意图题,下采样只在conv3_1、conv4_1、conv5_1且stride=2
从论文图三的说明可以看到普通的34层网络的参数和residual的34层网络参数量一样,即短接不增加参数

4、实验
作者在ImageNet Classification、CIFAR-10 and Analysis、 Object Detection on PASCAL and MS COCO,我们主要记录一下分类的实验
在ImageNet Classification任务上,作者使用ImageNet2012分类数据集,它有1000个类别,其中训练集包含128万张图片,验证集包含5w张图片,最终的结果是在有10w张图片的测试集上获得的,同时验证了top1和top5错误率
为了对比,首先验证了普通的18层和34层网络,从图可以看到普通网络和residual一样,只不过没有短接而已。
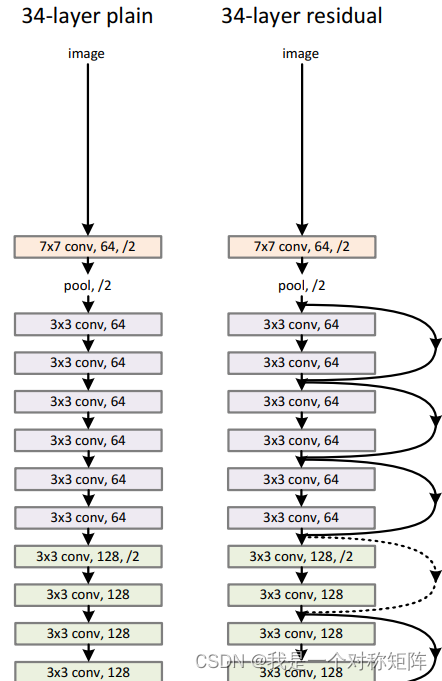
从图4的实验可以看出,普通的18层和34层(左)网络,更深的网络反常地具有更高的误差。而residual地18层和34层(右)网络,更深地网络具有更低地误差。
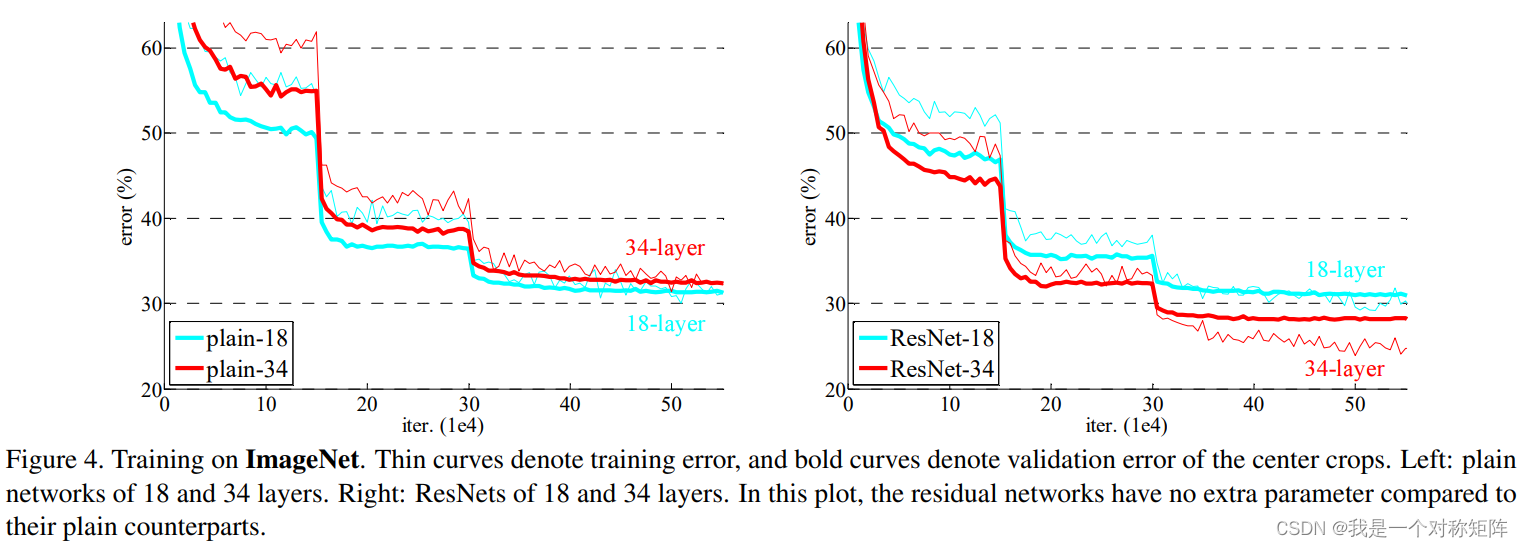

这能够看出,没有残差的网络越深越不好训练,误差反而更大,但是有残差的网络越深也很好训练,也能够拥有更好的性能从而进一步降低误差。
和普通网络对比验证残差的有效性后,接着和经典网络进行对比
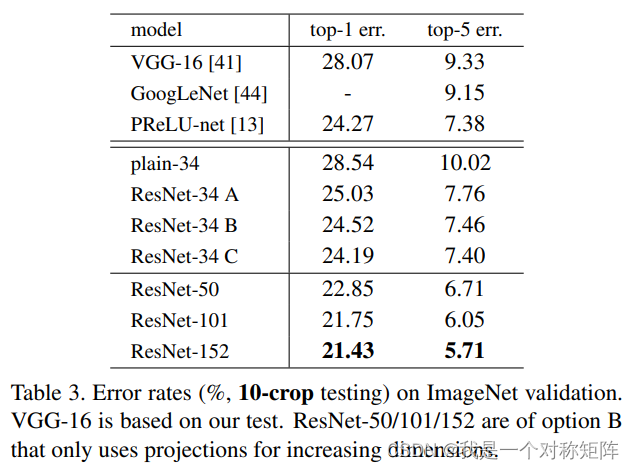
注意:这里是10-crop testing 测试结果,也就是将测试集的一张图进行TenCrop后进行推理得到10个结果,再对10个结果取均值作为该张图片的推理结果
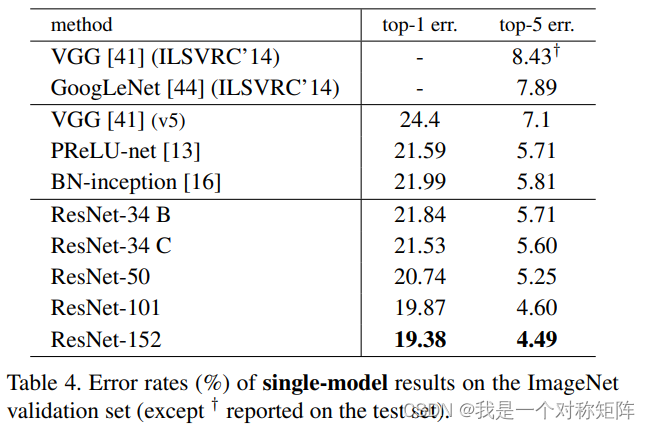
表5就是ILSVRC2015夺冠的数据(This result won the 1st place on the ILSVRC 2015 classification task. We also won the 1st places on the tasks of ImageNet detection, ImageNet localization,COCO detection, and COCO segmentation。),也就是通过集成ensemble后再次提升了精度(非单网络)
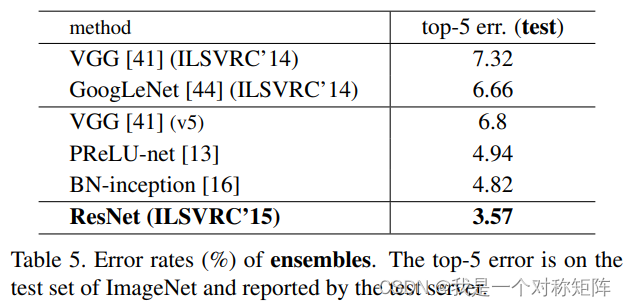
表六是在CIFAR10上的实验数据,不过我更关心"best(mean±std)"
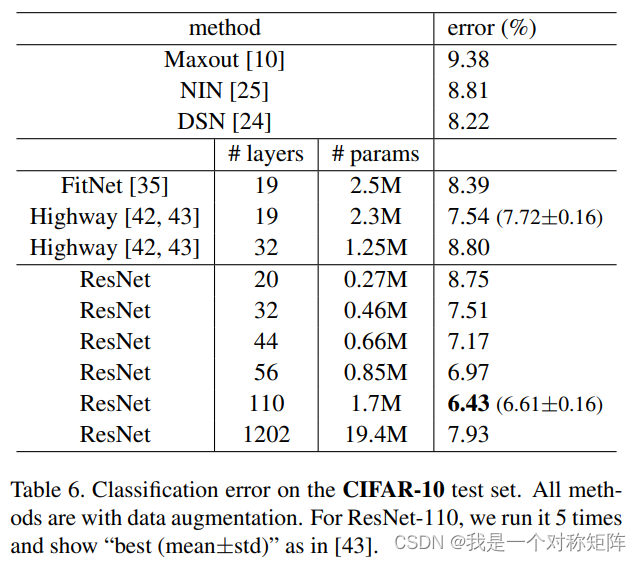
5、更详细的分析
Identity Mappings in Deep Residual Networks是同作者的文章,相当于ResNet论文更详细的理论分析吧,并且改进了残差块,提高了性能:
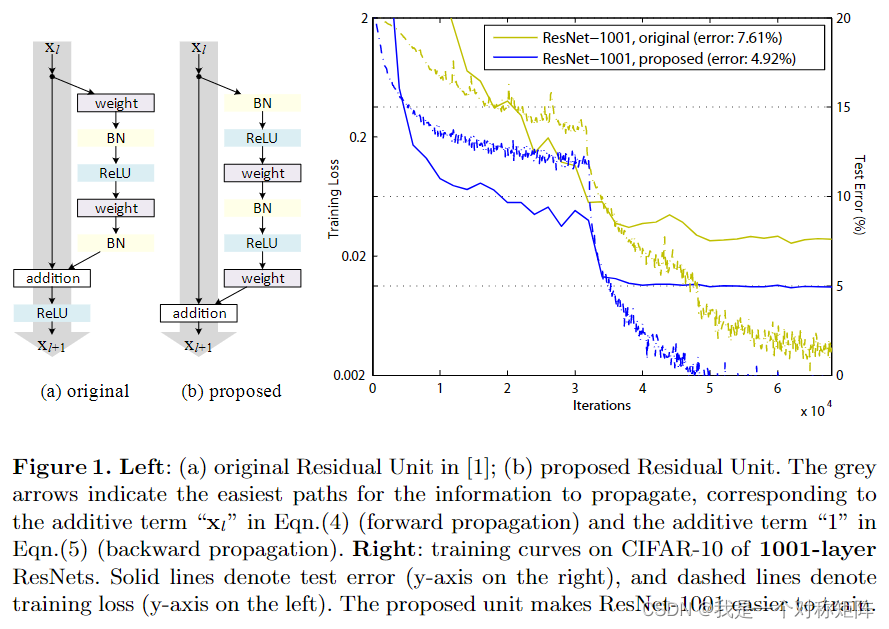
“在本文中,我们分析了残差构建块背后的传播公式,这表明,当使用恒等映射作为跳过连接和相加激活后,前向和后向信号可以从一个块直接传播到任何其他块。一系列消融实验支持这些同一映射的重要性。这促使我们提出了一种新的残差单元,它使训练更容易,并提高了泛化能力。”


















 736
736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











