







简介
Network In Network 是发表于 2014 年 ICLR 的一篇 paper。当前被引了 3298 次。这篇文章采用较少参数就取得了 Alexnet 的效果,Alexnet 参数大小为 230M,而 Network In Network 仅为 29M,这篇 paper 主要两大亮点:mlpconv (multilayer perceptron,MLP,多层感知机)作为 "micro network"和 Global Average Pooling(全局平均池化)
论文地址:https://arxiv.org/abs/1312.4400
Network in Network架构
多层感知机(MLP)
在介绍 mlpconv Layer 之前,我们先看看经典的 Linear Convolutional Layer(线性卷积层)是怎么进行操作的,
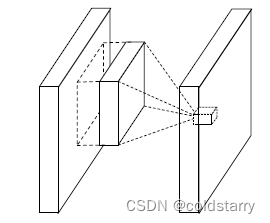
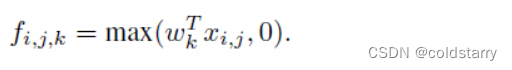
(i, j) 是特征图中像素的位置索引,x_ij 表示像素值,而 k 用于特征图通道的索引,W 是参数,经过 WX 计算以后经过一个 relu 激活进行特征的抽象表示。
下面就介绍 mlpconv Layer 结构
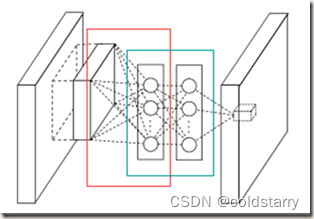
- 红框部分是在进行传统的卷积,可见卷积使用了多个filters。图中竖排圆圈是卷积得到的feature maps在某个位置上所有通道的数值,而不是某个feature map。这也是为了简单直观。
- 图中蓝色框部分是MLP的前两层,最后一层在mlpconv layer输出的feature map上,只有一个节点,即蓝色框后面的小立方体
- MLP是在多组feature maps的同一位置建立的,而且feature maps每个通道内的元素前一组feature maps中对应元素连接的权重相同(想象1*1卷积)
- MLP计算过程中得到的feature maps长宽一致。理解不了的话可以从1*1卷积的角度思考
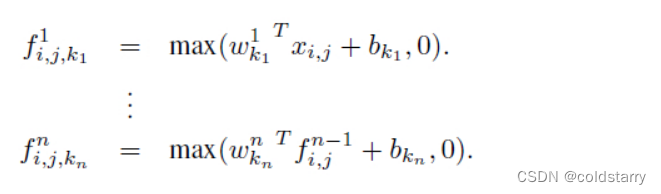
式中,n是多层感知器层数,从max()也可以看出多层感知器中使用的激活函数是Rectified linear unit。该计算过程等同于在一个传统的卷积层之后连接级联的跨通道参数池化层。每一个池化层先在输入的feature maps上进行加权线性重构,然后将结果输入一个rectifier linear unit激活。
跨通道池化得到feature maps接下来会在后面的layers中重复被跨通道池化。这种级联的跨通道参数池化结构(cascaded cross channel parameteric pooling structure)允许复杂的可学习的跨通道信息交互。
跨通道参数池化层就相当于一个卷积核为1*1的 linear convolution layer(包括激活函数)
Global Average Pooling Layer
之前的卷积神经网络的最后会加一层全连接来进行分类,但是,全连接层具有非常大的参数量,导致模型非常容易过拟合。因此,全局平均池化的出现替代了全连接层。我们在最后一层 mlpconv 得到的特征图使用全局平均池化(也就是取每个特征图的平均值)进而将结果输入到 softmax 层中。
全局平均池化的优点
- 全局平均池化没有参数,可以避免过拟合产生。
- 全局平均池可以对空间信息进行汇总,因此对输入的空间转换具有更强的鲁棒性。
下图是全连接层和全局平均池化的一个对比图
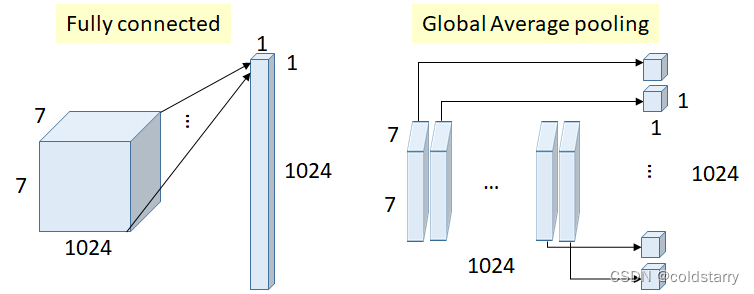
具体是:在最后一层mlpconv layer中为分类任务中的每一个类生成一个feature map;后面不接全连接网络,而是取每个feature map的均值,这样就得到一个长度为N的向量,与类别对应;添加softmax层,前面的向量直接传入计算,这样就得到了每个类别的概率。
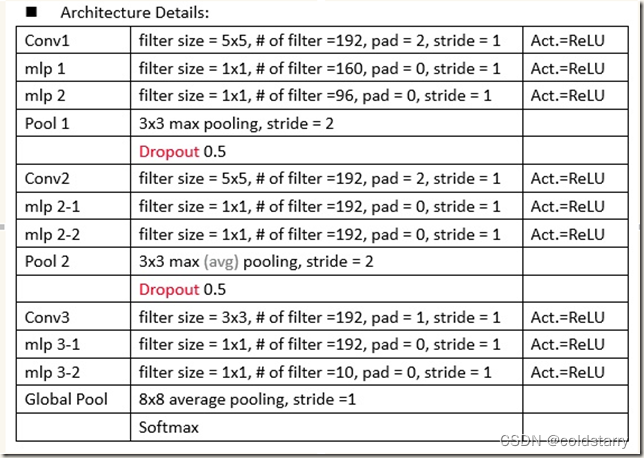
总体架构图
1000物体分类:4层NIN+全局均值池化

1*1卷积
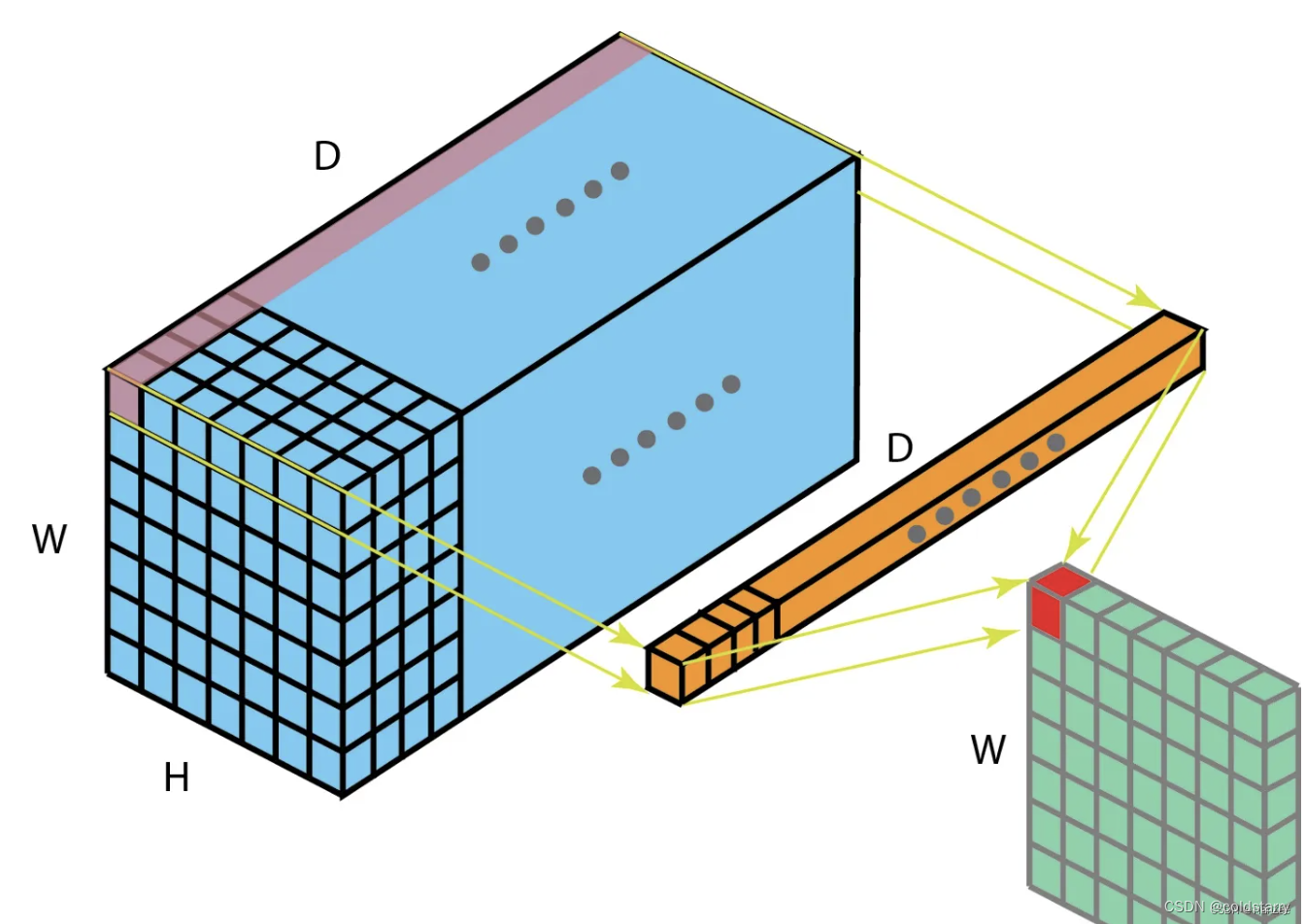
1 * 1卷积实际上就是对特征图所有channel对应的像素点做全连接网络,由于它只考虑了1个像素点,它不像3 * 3卷积那样可以考虑周围像素点,但是可以让特征图在不需要padding的情况下保证的H、W不变,也就是融合了买个像素点不同通道的特征所以它也有跨通道交融的作用。卷积核的数量决定了输出的维度,所以用1 * 1卷积只会改变特征图的channel数,这也就是1 * 1卷积有升维 、降维的作用,在维度降低的同时,计算量也就减少了,模型速度会变快,与此同时,它在保留了空间信息的同时,还增加了非线性激活函数,非线性激活函数可以增加模型的复杂程度,让模型逼近更复杂的曲线。
如果是一张6×6×32的图片,那么使用1×1过滤器进行卷积效果更好。具体来说,1×1卷积所实现的功能是遍历这36个单元格,计算左图中32个数字和过滤器中32个数字的元素积之和,然后应用ReLU非线性函数。
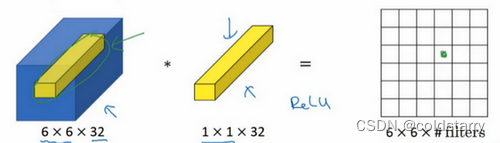
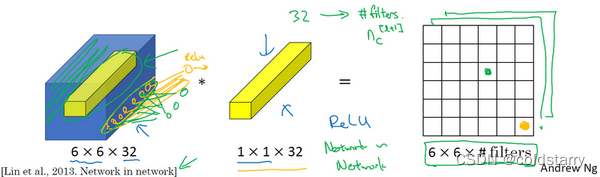
假设这是一个28×28×192的输入层,你可以使用池化层压缩它的高度和宽度,这个过程我们很清楚。但如果通道数量很大,该如何把它压缩为28×28×32维度的层呢?你可以用32个大小为1×1的过滤器,严格来讲每个过滤器大小都是1×1×192维,因为过滤器中通道数量必须与输入层中通道的数量保持一致。但是你使用了32个过滤器,输出层为28×28×32,这就是压缩通道数(nc)的方法,对于池化层我只是压缩了这些层的高度和宽度。
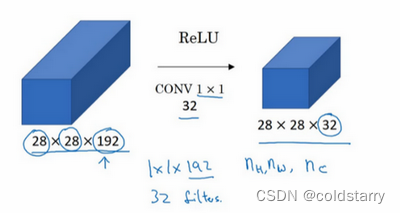
在之后我们看到在某些网络中1×1卷积是如何压缩通道数量并减少计算的。当然如果你想保持通道数192不变,这也是可行的,1×1卷积只是添加了非线性函数,当然也可以让网络学习更复杂的函数,比如,我们再添加一层,其输入为28×28×192,输出为28×28×192。

1*1的卷积,可以给神经网络添加了一个非线性函数,从而减少或保持输入层中的通道数量不变,当然如果你愿意,也可以增加通道数量

参考文章:
卷积神经网络之-NiN网络(Network In Network)-CSDN博客
https://www.cnblogs.com/Lilu-1226/p/10588137.html
深度学习:NiN(Network In Network)详细讲解与代码实现-云社区-华为云
吴恩达的深度学习















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









