







chapter_1 检查系统环境和第三方库是否安装完毕
在Web服务器, gui应用程序和jupyter笔记本运行python程序时,出现
“RuntimeError: This event loop is already running”。可能是因为循环出现了嵌套.
解决方法是:下面的程序.
此模块修补asyncio以允许嵌套使用asyncio.run和 loop.run_until_complete。
import nest_asyncio
nest_asyncio.apply()
导入必要的库.
其中collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。
import collections
import numpy as np
import tensorflow as tf
import tensorflow_federated as tff
np.random.seed(0)
tff.federated_computation()第一个参数如果是一个函数,那么返回一个基于这个函数的TFF计算实例
a=tff.federated_computation(lambda: 'Hello, World!')()
a
b'Hello, World!'
至此,说明我们的环境已经配置完毕了.
如果有报错,可以参考这一个博客进行TFF和TF的安装,方便又快捷.
https://blog.csdn.net/condom10010/article/details/126733539
chapter_2 准备输入数据
联合数据通常是非独立同分布( non-i.i.d)的,这带来了一系列独特的挑战。
TFF内置了一个联合版本的 MNIST,该版本包含原始 NIST 数据集的一个版本,该数据集已使用 Leaf 进行重新处理,以便数据由数字的原始编写者键入。
emnist_train, emnist_test = tff.simulation.datasets.emnist.load_data()
这里导入的数据之后只是用来模拟客户端的数据的.我们可以查看训练集中客户端id的数量
len(emnist_train.client_ids)
3383
emnist_train.client_ids[2]
'f0005_26'
训练集和测试集中的元素结构是:标签(int)和28*28的图片(float32)
emnist_test.element_type_structure
OrderedDict([('label', TensorSpec(shape=(), dtype=tf.int32, name=None)),
('pixels',
TensorSpec(shape=(28, 28), dtype=tf.float32, name=None))])
emnist_train.element_type_structure
OrderedDict([('label', TensorSpec(shape=(), dtype=tf.int32, name=None)),
('pixels',
TensorSpec(shape=(28, 28), dtype=tf.float32, name=None))])
根据客户id创建样本,并查看客户子数据集包含的样本数量
example_dataset = emnist_train.create_tf_dataset_for_client(
emnist_train.client_ids[0])
list(example_dataset.as_numpy_iterator()).__len__()
93
查看第一个元素
example_element = next(iter(example_dataset))
label = example_element['label'].numpy()
print(f'label:{label}')
img = example_element['pixels'].numpy()
label:1
import matplotlib.pyplot as plt
plt.imshow(img,cmap='gray',aspect='equal')
plt.grid(False)
plt.show()

2.1 探索联合数据中的 异质性(heterogeneity)
联合数据通常是非独立同分布的,用户通常具有不同的数据分布,具体取决于使用模式。一些客户端可能在设备上的训练样例较少,本地数据匮乏,而一些客户端的训练样例会绰绰有余。让我们使用我们可用的 EMNIST 数据来探索联邦系统中典型的数据异质性概念。需要注意的是,这种对客户数据的深入分析仅对我们可用,因为这是一个模拟环境,我们可以在本地获得所有数据。在真正的生产联合环境中,您将无法检查单个客户端的数据。
首先,让我们抓取一个客户的数据样本,以感受在一台模拟设备上的示例。因为我们使用的数据集是由唯一的作者键入的,所以一个客户的数据代表一个人对数字 0 到 9 的样本的笔迹,模拟了一个用户的独特“使用模式”。
figure = plt.figure(figsize=(20,8))
j=0
for example in example_dataset.take(40):
# 选择样本的前40个进行展示
plt.subplot(4,10,j+1)
plt.imshow(example['pixels'].numpy(),cmap='gray',aspect='equal')
plt.axis('off')
label = example['label'].numpy()
# print(label)
j+=1

现在让我们可视化每个客户端上每个 MNIST 数字标签的样本数量。在联邦学习环境中,每个客户端上的样本数量可能会有很大差异,具体取决于用户行为。
f = plt.figure(figsize=(12,7))
f.suptitle('Label Count for a Sample of Clients')
# 选择前6位用户
client_num=6
for i in range(client_num):
client_dataset=emnist_train.create_tf_dataset_for_client( \
emnist_train.client_ids[i])
plot_data=collections.defaultdict(list)
for example in client_dataset:
label = example['label'].numpy()
# 统计1-9的标签有几个,存放在一个字典变量中
plot_data[label].append(label)
plt.subplot(2,3,i+1)
plt.title(f"Client{i}")
for j in range(10):
plt.hist(x=plot_data[j],density=False,bins=[0,1,2,3,4,5,6,7,8,9])
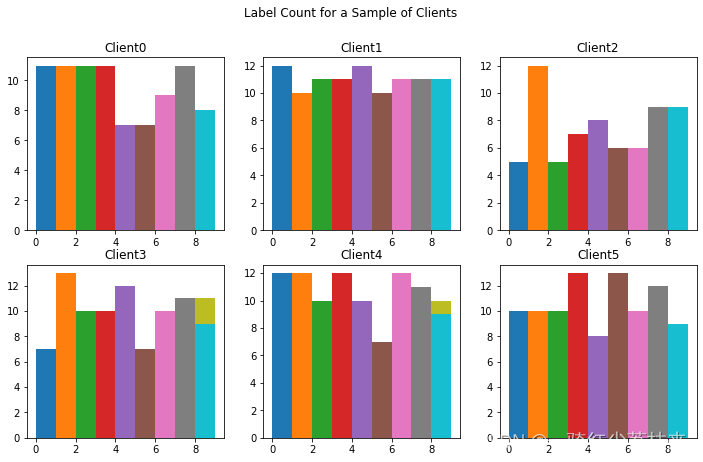
现在让我们可视化每个 MNIST 标签的每个客户端的平均图像。此代码将为一个标签的所有用户样本生成每个像素值的平均值。我们会看到,由于每个人独特的笔迹风格,一个客户对一个数字的平均图像与另一个客户对同一数字的平均图像看起来会有所不同。我们可以思考每一轮本地训练将如何在每个客户端上将模型推向不同的方向,因为我们正在从该用户在该本地轮次中自己的独特数据中学习。在本教程的后面,我们将看到如何从所有客户端获取模型的每次更新并将它们聚合到我们的新全局模型中,该模型从每个客户端自己的独特数据中学习。
每个客户都有不同的平均图像,这意味着每个客户都会促使模型在本地自己的方向训练
for i in range(6):
client_dataset = emnist_train.create_tf_dataset_for_client(emnist_train.client_ids[i])
plot_data=collections.defaultdict(list)
for example in client_dataset:
label = example['label'].numpy()
img = example['pixels'].numpy()
plot_data[label].append(img)
f = plt.figure(i,figsize=(12,5))
f.suptitle(f"Client{i} Mean Image Label")
for j in range(10):
mean_img = np.mean(plot_data[j],0)
plt.subplot(2,5,j+1)
plt.imshow(mean_img)
plt.axis('off')


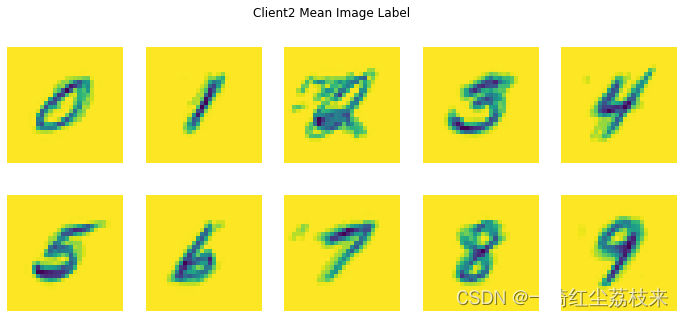



用户数据可能是嘈杂的并且标签不可靠。例如,查看上面客户端 #2 的数据,我们可以看到对于标签 2,可能存在一些错误标记的示例,从而创建了噪声更大的平均图像。
2.2 预处理输入数据
由于数据已经是 tf.data.Dataset,因此可以使用数据集转换来完成预处理。在这里,我们将 28x28 图像展平为 784 个元素的数组,将单个示例打乱,将它们组织成Batch,并将特征从像素和标签重命名为 x 和 y,以便与 Keras 一起使用。我们还重复数据集以运行几个 epoch。
NUM_CLIENTS=10
NUM_EPOCH=5
BATCH_SIZE=5
SHUFFLE_BUFFER=100 #打乱时的缓存区大小
PREFECTH_BUFFER=10 #预取元素
def preprocess(dataset):
# dataset = tf.data.Dataset()
def batch_formate_fn(element):
# 把元素变成x,y.并且把图像展开成784个元素
return collections.OrderedDict(
x=tf.reshape(element['pixels'],[-1,784]),
y=tf.reshape(element['label'],[-1,1])
)
return dataset.repeat(NUM_EPOCH) \
.shuffle(SHUFFLE_BUFFER,seed=1) \
.batch(BATCH_SIZE) \
.map(batch_formate_fn) \
.prefetch(PREFECTH_BUFFER)
下面取出第一个batch,测试一下函数是不是正常的.
preprocess_example_dataset = preprocess(example_dataset)
sample_batch = tf.nest.map_structure(lambda x:x.numpy(),
next(iter(preprocess_example_dataset)))
sample_batch
OrderedDict([('x',
array([[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.]], dtype=float32)),
('y',
array([[2],
[1],
[5],
[7],
[1]], dtype=int32))])
我们拥有几乎所有构建块来构建联合数据集。
在模拟中将联合数据提供给 TFF 的一种方法是简单地作为 Python 列表.无论是作为列表还是作为 tf.data.Dataset,列表的每个元素都保存单个用户的数据。下面将会使用tf.data.Dataset的结构.
def make_federated_data(client_data,client_idx):
return [
preprocess(client_data.create_tf_dataset_for_client(x)
) for x in client_idx
]
这个函数将会返回处理后的所有client的数据
现在,我们如何选择客户端?
在典型的联合训练场景中,我们正在处理潜在的大量用户设备,其中只有一小部分可能在给定时间点可用于训练。例如,当客户端设备是仅在插入电源、网络通畅并且空闲时才参与训练的手机
时就是这种情况。
当然,我们是在模拟环境中,所有的数据都是本地可用的。通常,在运行模拟时,我们会简单地对参与每一轮训练的客户的随机子集进行抽样,每轮训练通常不同。
在这里我们要是对一组客户端进行一次采样,然后在各轮中重复使用相同的一组以加速收敛(故意过度拟合这些少数用户的数据)。
正如我们通过研究有关联邦平均算法的论文所发现的那样,在每轮中随机抽样客户端子集的系统中实现收敛可能需要更长的时间。我们将其作为练习留给读者,修改本教程以模拟随机抽样 - 这很容易做到(一旦你这样做,请记住让模型收敛可能需要一段时间)。
sample_clients = emnist_train.client_ids[0:NUM_CLIENTS]
federated_train_data = make_federated_data(emnist_train,sample_clients)
print(f'Number of client datasets: {len(federated_train_data)}')
print(f'First dataset: {federated_train_data[0]}')
Number of client datasets: 10
First dataset: <PrefetchDataset shapes: OrderedDict([(x, (None, 784)), (y, (None, 1))]), types: OrderedDict([(x, tf.float32), (y, tf.int32)])>
chapter_3 通过Keras构建模型
from tensorflow.keras import models,layers,losses,metrics
def create_keras_model():
# 网络由一个全连接层组成,输入784,输出10.
return models.Sequential([
layers.InputLayer(input_shape=(784,)),
layers.Dense(10,kernel_initializer='zeros'),
layers.Softmax(),
])
为了使用带有 TFF 的任何模型,需要将其包装在 tff.learning.Model 接口的实例中,该接口公开了标记模型的前向传递、元数据属性等的方法,与 Keras 类似,但还引入了额外的元素,例如控制计算联合指标的过程的方法。我们暂时不用担心这个;
如果您有一个像我们上面刚刚定义的 Keras 模型,您可以通过调用 tff.learning.from_keras_model 让 TFF 包装它,将模型和样本数据批次作为参数传递,如下所示。
def model_fn():
keras_model = create_keras_model()
return tff.learning.from_keras_model(
keras_model=keras_model,
input_spec=preprocess_example_dataset.element_spec,
loss=losses.SparseCategoricalCrossentropy(),
metrics=[metrics.SparseCategoricalAccuracy()]
)
解释一下from_keras_model的参数:
- keras_model:keras构建的模型
- input_spec:输入数据的类型,这里选择预处理之后的数据类型
- loss:损失函数,这里是选择的多分类问题中的交叉熵损失
- metrics:分类准确率,0-1
上述函数的API可以在这个网站查看:
https://tensorflow.google.cn/federated/api_docs/python/tff/learning/from_keras_model
chapter_4 在联邦数据上训练模型
现在我们有了一个包装为 tff.learning.Model 的模型以与 TFF 一起使用,我们可以让 TFF 通过调用辅助函数来构造一个联邦平均算法
from tensorflow_federated import learning
from tensorflow import optimizers
4.1 定义一个联邦训练处理对象.
这一部分2022.09.08官网上用的是tff.learning.algorithms.build_weighted_fed_avg,为高版本TFF所具有的.本文使用TFF0.19.0没有这个函数,替换为tff.learning.build_federated_averaging_process.
请记住,参数必须是构造函数(例如上面的 model_fn),而不是已经构造的实例,以便模型的构造可以在 TFF 控制的上下文中进行(如果您对为此,我们鼓励您阅读有关自定义算法的后续教程)。
下面是关于联邦平均算法的一个重要说明,有 2 个优化器:一个 _clientoptimizer 和一个 _serveroptimizer。 _clientoptimizer 仅用于计算每个客户端上的本地模型更新。 _serveroptimizer 将平均更新应用于服务器上的全局模型。特别是,这意味着使用的优化器和学习率的选择可能需要与您在标准 i.i.d数据集 上训练模型时使用的不同。我们建议从常规 SGD 开始,可能使用比平时更小的学习率。我们使用的学习率没有经过仔细调整,请随意尝试。
iterative_process = learning.build_federated_averaging_process(
model_fn=model_fn,
client_optimizer_fn=lambda: optimizers.SGD(learning_rate=0.02),
server_optimizer_fn=lambda: optimizers.SGD(learning_rate=1)
)
他们API都差不多,官网现在查不到build_federated_averaging_process的API了,这里学习一下函数build_weighted_fed_avg的API:
https://tensorflow.google.cn/federated/api_docs/python/tff/learning/algorithms/build_weighted_fed_avg
- 刚才发生了什么?
:TFF 构建了一对联合计算并将它们打包到 tff.templates.IterativeProcess 中,其中这些计算可作为一对属性 initialize 和 next 使用。
简而言之,联邦计算是 TFF 内部语言的程序,可以表达各种联邦算法(您可以在自定义算法教程中找到更多相关信息)。在这种情况下,生成并打包到 iterative_process 中的两个计算实现了联合平均。
TFF 的目标是定义计算,使其可以在真实的联邦学习设置中执行,但目前我们仅实现本地执行模拟运行。要在模拟器中执行计算,您只需像 Python 函数一样调用它。这个默认的解释环境不是为高性能而设计的,但对于本教程来说已经足够了;
我们希望提供更高性能的模拟运行时,以促进未来版本中的更大规模研究。
让我们从初始化计算开始。与所有联合计算的情况一样,您可以将其视为一个函数。计算不接受任何参数,并返回一个结果:服务器上联合平均过程的状态表示。虽然我们不想深入研究 TFF 的细节,但看看这个状态是什么样子可能会很有启发性。您可以将其可视化如下。
print(iterative_process.initialize.type_signature.formatted_representation())
( -> <
model=<
trainable=<
float32[784,10],
float32[10]
>,
non_trainable=<>
>,
optimizer_state=<
int64
>,
delta_aggregate_state=<
value_sum_process=<>,
weight_sum_process=<>
>,
model_broadcast_state=<>
>@SERVER)
虽然上述类型签名乍一看可能有点神秘,但您可以认识到服务器状态由 global_model_weights(将分发给所有设备的 MNIST 的初始模型参数)、一些空参数(如分发器,它管理服务器到客户端的通信)和终结器组件。终结器用来控制服务器在一轮结束时更新其模型的逻辑,并包含一个表示FedAvg已经发生了多少轮的整数。
4.2 调用初始化计算来构造服务器状态。
上文中,我们构建了一个联合计算对象IterativeProcess,这个对象包含2个方法. initialize 和 next 使用。
首先我们使用initialize来构造一个初始的联邦学习服务状态.
state = iterative_process.initialize()
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow_federated/python/core/impl/compiler/tensorflow_computation_transformations.py:60: extract_sub_graph (from tensorflow.python.framework.graph_util_impl) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.compat.v1.graph_util.extract_sub_graph`
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow_federated/python/core/impl/compiler/tensorflow_computation_transformations.py:60: extract_sub_graph (from tensorflow.python.framework.graph_util_impl) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.compat.v1.graph_util.extract_sub_graph`
接下来,我们介绍IterativeProcess的第二个方法next,代表单轮联合平均(Federated Averaging),其中包括把服务器状态(包括模型参数)推送到客户端、在设备上对其本地数据进行训练、收集和平均模型更新,并在服务器上生成新的更新模型。
从概念上讲,您可以将 next 视为具有如下所示的功能类型签名。
SERVER_STATE, FEDERATED_DATA -> SERVER_STATE, TRAINING_METRICS
如何理解上面的式子?
->左边:输入联邦学习服务器的状态SERVER_STATE, 联邦学习的数据FEDERATED_DATA
->右边:输出更新后的联邦学习服务器的状态SERVER_STATE,联邦学习的训练状态TRAINING_METRICS
特别是,不应将 next() 视为在服务器上运行的函数,而应将其视为整个去中心化计算的声明性函数表示. 一些输入由服务器 (SERVER_STATE) 提供,但是每个参与设备都有自己的本地数据集。
4.3 运行一轮训练并可视化结果。
我们可以将上面已经生成的联邦学习数据用于用户样本。
state,metrics = iterative_process.next(state,federated_train_data)
print('训练状态:')
metrics
训练状态:
OrderedDict([('broadcast', ()),
('aggregation',
OrderedDict([('mean_value', ()), ('mean_weight', ())])),
('train',
OrderedDict([('sparse_categorical_accuracy', 0.56831276),
('loss', 1.469168)])),
('stat', OrderedDict([('num_examples', 4860)]))])
4.4 然后让我们训练10轮:
NUM_ROUNDS=10
state = iterative_process.initialize()
for round_num in range(0,NUM_ROUNDS):
state,metrics=iterative_process.next(state,federated_train_data)
print('round', round_num+1,'loss:',metrics['train']['loss'])
round 1 loss: 5.2703967
round 2 loss: 4.575706
round 3 loss: 4.115935
round 4 loss: 3.4195397
round 5 loss: 2.9929774
round 6 loss: 2.7245579
round 7 loss: 2.3100283
round 8 loss: 2.102916
round 9 loss: 1.8347658
round 10 loss: 1.6228148
可见,训练过程中,损失是不断下降的.
4.5 [拓展]在每一个epoch随机选择client
先测试一下从所有客户中随机采样NUM_CLIENTS个客户出来:
import numpy as np
client_num_all = len(emnist_train.client_ids)
random_clients_idx = np.random.randint(client_num_all,size=NUM_CLIENTS)
client_ids_numpy = np.array(emnist_train.client_ids)
random_clients=list(client_ids_numpy[random_clients_idx])
['f3714_05',
'f1773_18',
'f3312_28',
'f1006_19',
'f2337_71',
'f0488_39',
'f3684_46',
'f0929_23',
'f2186_55',
'f3641_13']
可以看到已经可以随机采样了,下面就把上面代码加入循环中.每个循环都随机选择一批客户进行训练
NUM_ROUNDS=10
state = iterative_process.initialize()
for round_num in range(0,NUM_ROUNDS):
client_num_all = len(emnist_train.client_ids)
random_clients_idx = np.random.randint(client_num_all,size=NUM_CLIENTS)
client_ids_numpy = np.array(emnist_train.client_ids)
random_clients=list(client_ids_numpy[random_clients_idx])
federated_train_data = make_federated_data(emnist_train,random_clients)
state,metrics=iterative_process.next(state,federated_train_data)
print('round', round_num+1,'loss:',metrics['train']['loss'])
round 1 loss: 5.11803
round 2 loss: 4.7252603
round 3 loss: 4.249384
round 4 loss: 3.8406074
round 5 loss: 3.0722911
round 6 loss: 2.7794824
round 7 loss: 2.7126424
round 8 loss: 2.2197828
round 9 loss: 2.245559
round 10 loss: 2.3454423
可以看到,相比4.4中固定客户训练,每轮中随机客户训练时,loss下降速度明显减小了,需要更多的轮才能收敛.
chapter_5 将训练结果在tensorboard上显示
接下来,让我们使用 Tensorboard 可视化来自这些联邦计算的指标。让我们首先创建目录和相应的摘要编写器以将指标写入其中。
logdir='./logs/'
summary_write=tf.summary.create_file_writer(logdir)
state = iterative_process.initialize()
with summary_write.as_default():
for round_num in range(NUM_ROUNDS):
state,metrics=iterative_process.next(state,federated_train_data)
for acc,value in metrics['train'].items():
tf.summary.scalar(acc,value,step=round_num)
!ls {logdir}
events.out.tfevents.1662623089.ce8d4bacd914.322.33260.v2
%tensorboard --logdir {logdir} --port=0
可以通过vscode 打开tensorboard界面,可见损失不断下降,acc逐渐增加.
这里的loss和acc是指的服务器端的总体损失和总体acc


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









