







【医学图像分割】读论文系列 1
Title
标题:Noisy Labels are Treasure: Mean-Teacher-Assisted Confident Learning for Hepatic Vessel Segmentation
来源:MICCAI 2021
链接:https://doi.org/10.1007/978-3-030-87193-2_1
Introduction
目前,由于CT影像具有病理变化丰富、低对比度、复杂的血管形态以及噪声等特点,人工标注CT影像是个非常昂贵的工作,这也导致了在肝脏血管分割中,缺少高质量的像素级别的数据集。而当前的深度学习模型大多是基于数据驱动的模型,大部分已有的数据集都是无标签或者错误标签的数据,这些数据集称为“噪声”数据集。噪声数据集可能会对网络的学习进行负面指导,因此,如何稳健地利用好这些大量的低质量噪声数据集的额外信息,是当前的一个巨大挑战。
Abstract
- 肝脏血管分割存在两个问题
- ①目前基于数据驱动的学习方法如果没有足够的高质量注释数据,通常会遇到欠拟合等训练不足的问题;
- ②另一方面 低质量的数据会混淆网络,导致不良的性能下降。
基于上述问题,本文提出了一种新的框架,即mean-teacher-assisted confident learning framework,可以利用噪声标注数据。
具体而言,weight-average teacher模型加以第三方辅助的自适应confident learning,通过progressive pixel-wise soft-correction,可以将额外的噪声数据集“变废为宝”,从而对网络进行有效指导。
Keyword
肝脏血管分割;噪声标签;置信学习
Method
- 使用的数据集:
- Set-HQ(高质量)数据集:3DIRCADb
- 含有20张高质量肝脏和血管标注的数据
- Set-LQ(低质量)数据集:MSD8
- 包含443张CT扫描图像,但是标注质量较低,约有65.5%未标记的血管像素,8.5%的像素被误标记为血管

- 包含443张CT扫描图像,但是标注质量较低,约有65.5%未标记的血管像素,8.5%的像素被误标记为血管
- Set-HQ(高质量)数据集:3DIRCADb
在本文的实验中,高质量数据集被随机划分,十样本用以训练模型,十样本用以测试,而低质量数据集全部用来训练(因为它们不适合做无偏估计)
-
肝脏CT图像预处理
- ①基于肝脏分割掩模对图像进行mask,并裁剪到肝脏区域。(MSD8数据集的肝脏掩模是用H-DenseUNet模型获得的),所有裁剪后的图像调整为320320D,其中D为切片号
- ②将每个像素的intensity截断到【100,250】HU范围内,然后进行Min-Max归一化
- ③引入基于Sato tubeness的过滤器作为辅助信息,通过计算Hessian矩阵的特征向量,得到图像与tubes的相似度,从而以高概率增强潜在的血管区域。通过联合考虑图像和概率图中的信息,网络可以感知到更鲁棒的血管信号。
-
模型框架
- 结构图:
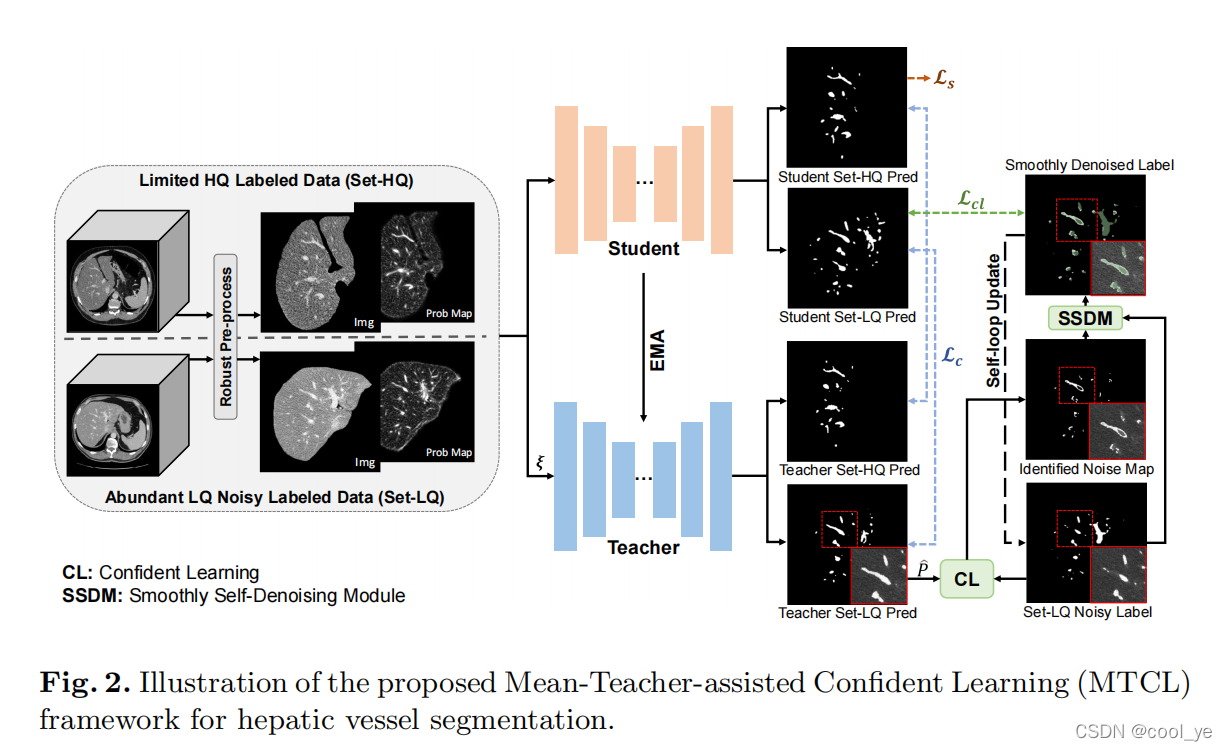
- Mean-Teacher Model
- backbone:U-Net
- 训练步骤 t t t中,学生模型的权重表示为 θ t \theta_{t} θt,老师模型权重为 θ t ′ \theta_{t}^{\prime} θt′,老师模型的权重采用EMA策略来更新,具体的公式为 θ t ′ = α θ t − 1 ′ + ( 1 − α ) θ t \theta_{t}^{\prime}=\alpha \theta_{t-1}^{\prime}+(1-\alpha) \theta_{t} θt′=αθt−1′+(1−α)θt, α \alpha α是EMA衰减权重,被设置为0.99。
- 通过最小化Set-HQ上的损失 L s \mathcal{L}_{s} Ls以及两个数据集上学生模型和教师模型预测之间的一致性损失(无监督的) L s \mathcal{L}_{s} Ls来优化学生模型。
- Self-Denoised Process
上述MT模型只能利用图像信息,而一些有噪声标签的潜在有用信息仍未被利用,为了进一步利用LQ数据集而不受标签噪声的影响,本文提出了一种渐进的自去噪过程,可以分为如下几步:- ①通过自适应的CL来识别像素级别的标签错误。首先,估计噪声标签和真实标签的联合分布;然后使用Prune By Class(PBC)方法来识别标签噪声。
- ②提取精炼Set-LQ中的噪声标签,提供有益的监督。引入the Smoothly Self-Denoising Module (SSDM)做软矫正。
- ③自循环更新。通过引入的SSDM模块,构建自循环框架,逐步用去噪标签替代Set-LQ中的噪声标签。
- Loss function
- 本文的loss函数采用如下公式计算:
- L = L s + λ c L c + λ c l L c l \mathcal{L}=\mathcal{L}_{s}+\lambda_{c} \mathcal{L}_{c}+\lambda_{c l} \mathcal{L}_{c l} L=Ls+λcLc+λclLcl
- 其中, L s \mathcal{L}_{s} Ls是在Set-HQ上的有监督损失, L c \mathcal{L}_{c} Lc是在两个数据集上的扰动一致性损失, L c l \mathcal{L}_{c l} Lcl是辅助的自去噪CL在Set-LQ上的损失。总的损失函数是这三者的加权和。
- 本文的loss函数采用如下公式计算:
- 结构图:
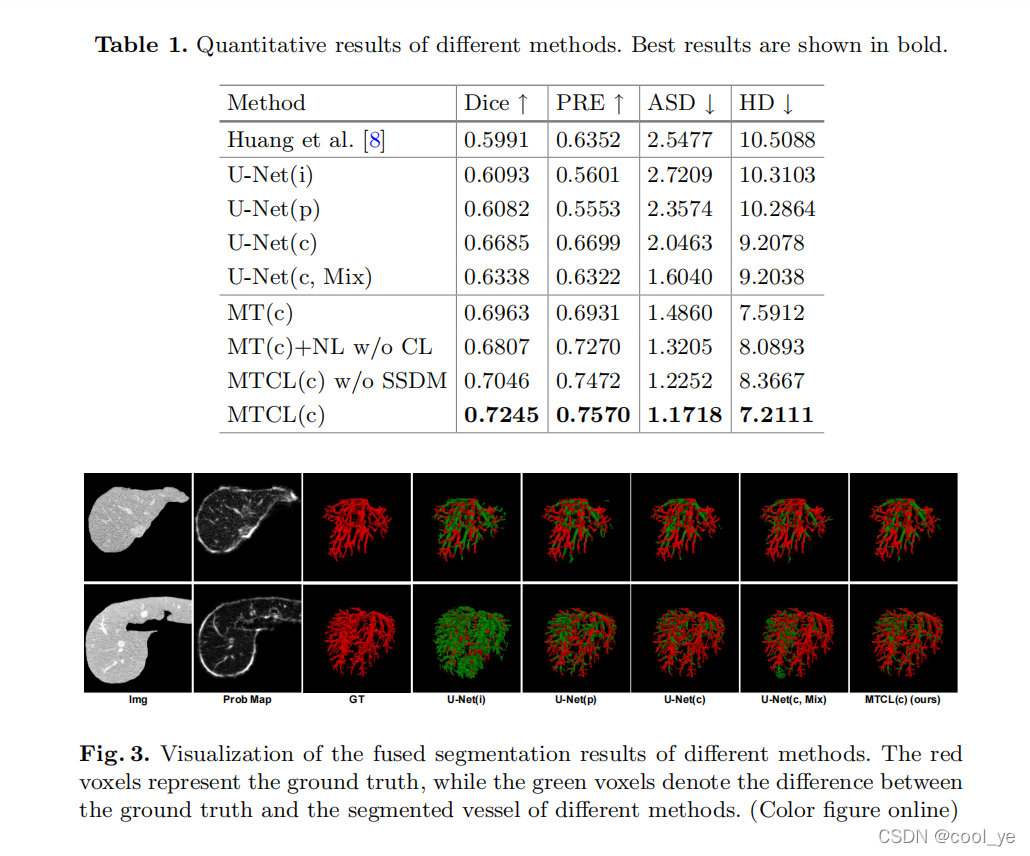
Experiment
- 评估指标 :Dice score、PRE、ASD、HD
- 优化器 :SGD
- batch size : 4
- 数据增强方法:随机翻转和旋转
- code:https://github.com/lemoshu/MTCL
- 实验结果图表:
Conclusion
- ①优点:该框架可以在只有少量高质量标记数据的情况下提高噪声标记数据的标注质量。而且在实验中表现良好。
- ②缺点:在2D的表现上好,但3D的表现上有点拉胯

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









