










TLogic: Temporal Logical Rules for Explainable Link Forecasting on Temporal Knowledge Graphs(AAAI 2022)
Introduction
- 目的(原有的局限性):
- 以往的embedding方法都是将实体和关系投影到一个低维的向量空间中,同时保留TKG的拓扑结构和时间动力学,这些方法可以学习导致事件的复杂模式,但往往缺乏透明度和可解释性。
- 提供人类可理解的解释是必要的。这可以由逻辑规则提供。然而,由于事件的复杂性,手动创建规则是困难的,这就导致了一个被称为知识获取瓶颈的问题(the knowledge acquisition bottlenect)。一般来说,使用逻辑规则的符号方法往往会遇到可伸缩性问题。
- 本文提出可以**通过从图中提取动态(temporal)随机游走来实现自动挖掘循环时态(temporal)逻辑规则的TLogic方法。**以temporal rules的形式实现了较高的预测性能和时间一致的解释,这与一个事件的发生通常是由以前的事件触发的观察结果相一致,本文的贡献如下:
- 提出了TLogic。第一种直接从TKG中学习temporal逻辑规则并将这些规则应用于link prediction任务中的方法
- 以temporal logical rules的方式提供了明确和人类可读的解释,并可扩展到大数据集
- 在ICEWS14、ICEWS18和ICEWS0515上进行实验表明该方法的先进性
- 演示了TLogic在归纳设置中的有效性,其中学习到的规则被转移到一个具有公共词汇表的相关数据集
Preliminaries
在文中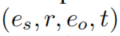 叫做edge或者link
叫做edge或者link
- Link forecasting
- 给出query
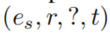 ,方法的目的就是给出object candidates的ranked list,来补充这个缺失的四元组
,方法的目的就是给出object candidates的ranked list,来补充这个缺失的四元组 - 同理,对于subject entity,也是补充类似的
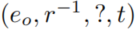 四元组。
四元组。
- 给出query
- Temporal random walk

- non-increasing temporal random walk服从时间限制,所以边只在时间上向后遍历,也可以沿着具有相同的时间戳的边行走
- Temporal logical rule
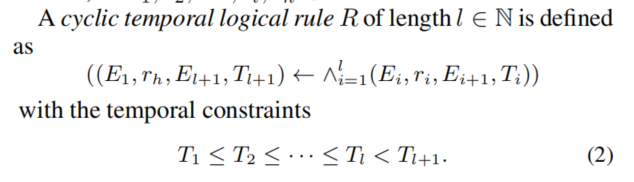
- temporal logical rule表示如上,即左边的是rule head,右边的是rule body,即联合右边的几个规则可以推导出左边的规则。并且这些规则推导必须遵守约束(2)
- 当变量
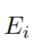 和
和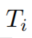 被恒定的项替换时,被称为grounding或者instantiation,比如一个temporal rule
被恒定的项替换时,被称为grounding或者instantiation,比如一个temporal rule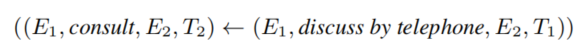 可以被grounding为 _(Angela Merkel, discuss by telephone, _
可以被grounding为 _(Angela Merkel, discuss by telephone, _
Barack Obama, 2014/07/22)和(Angela Merkel, consult, Barack Obama, 2014/08/09)。
- rule grounding参考变量在整个规则中的变换,body grounding参考仅在body中被替换的变量,所有grounding都必须服从约束(2)
- body support被定义为body grounding的数量
- rule support被定义为 存在
 在
在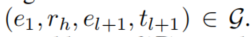 中的body grounding的数量。
中的body grounding的数量。
- rule confidence = rule support / body support
Framwork
TLogic首先从图中提取temporal walks,然后将这些walks提升到一个更抽象的语义级别,以获得推广到新数据的temporal rules。这些rules可以生成候选答案,其中在图中的body groudings作为明确的和人类可读的解释。
Rule learning

- 作为一个长度为 l 的rule,采样一个长度为 l + 1 的walks,其中额外的步骤与规则头部相对应。
- 设
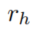 为一个固定的关系,为它学习规则。对于第一个采样步骤 m = 1, 我们采样一个edge
为一个固定的关系,为它学习规则。对于第一个采样步骤 m = 1, 我们采样一个edge 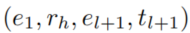 来作为 rule 的头部,从所有关系类型为
来作为 rule 的头部,从所有关系类型为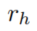 的edge中均匀采样。一个temporal random walker对当前对象附近的edges迭代采样,直到得到长度为 l + 1 的walks。
的edge中均匀采样。一个temporal random walker对当前对象附近的edges迭代采样,直到得到长度为 l + 1 的walks。 - 对后续的采样步骤
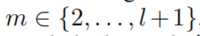 ,让
,让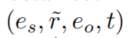 代表之前的采样的edge,
代表之前的采样的edge,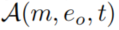 表示下一个转换的可行的edges。为了满足(1)和(2)中的时间约束,我们定义了:
表示下一个转换的可行的edges。为了满足(1)和(2)中的时间约束,我们定义了:
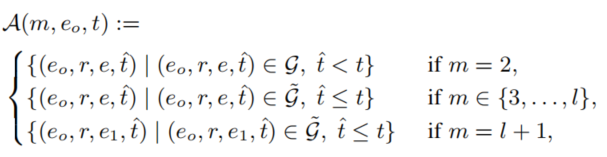
- 其中
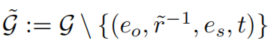 排除了inverse edge来避免规则冗余。
排除了inverse edge来避免规则冗余。
- 其中
- 为了获得循环行走,我们在最后一步 m = l + 1中,将edge和walk相连到第一个entity
 中如果存在这些edge,否则进行下一个walk的采样。
中如果存在这些edge,否则进行下一个walk的采样。 - 在下一组edge中的transition distribution可以是均匀或者是指数来加权
- 定义一个索引映射
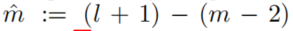 ,来与(1)的索引相一致,然后为选择的边
,来与(1)的索引相一致,然后为选择的边 (其中
(其中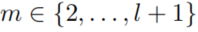 )计算指数加权概率,概率计算公式如下:
)计算指数加权概率,概率计算公式如下:
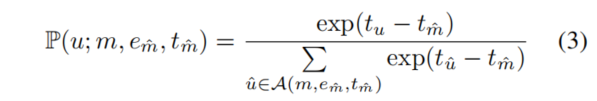
- 其中
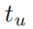 表示edge
表示edge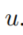 中的timestamp,指数加权倾向于与之前的时间戳更详尽的eges,因为这可能将会与预测更相关
中的timestamp,指数加权倾向于与之前的时间戳更详尽的eges,因为这可能将会与预测更相关
- 其中
- 得到的时间游走W为
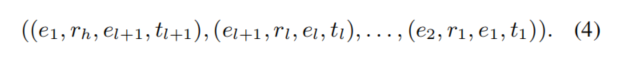
- W 可以被转化为temporal rule 通过变量替换实体和和时间戳
- 当第一个在W的edge作为rule head
 ,另外的edges被映射为body atoms,即每个edge
,另外的edges被映射为body atoms,即每个edge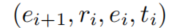 转化为
转化为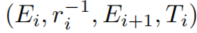 。
。 - 最终的规则 R 被记作
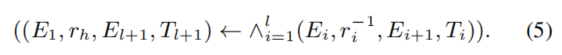
- 值得注意的是,依然有一致性约束
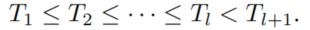
- 值得注意的是,依然有一致性约束
- 在 W 中的实体不需要不同,因为一对实体可以在不同的时间点有许多相互作用。W中相同的实体重复出现将被替换为R(temporal logic rule)中相同的随机变量,以保持这一知识
- 为了评估R的置信度,我们从图中采样固定数量的body groudings,这些body groundings必须与body relations和上述提到的变量约束相匹配,并满足条件(2)
- 独一无二的body的数量视作body support,
- rule support的计算规则为:
- 计算在body中存在关系类型
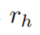 连接的
连接的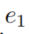 与
与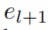 实体对的数量
实体对的数量 - 另外关于这些edge的时间戳必须比所有body的时间戳还大来满足条件(2)
- 计算在body中存在关系类型
- 对于
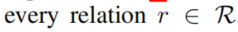 ,我们为预先设定长度
,我们为预先设定长度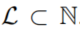 采样了n组随机游走。
采样了n组随机游走。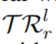 代表了所有长度为
代表了所有长度为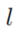 的,且关系的头为
的,且关系的头为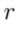 的规则及其对应的置信度。关系
的规则及其对应的置信度。关系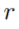 被包含在
被包含在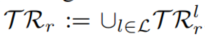 ,完整的时间学习规则被
,完整的时间学习规则被 来表示。
来表示。
- 定义一个索引映射
Rule Application

任务: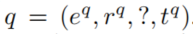 预测query中的缺失实体。答案从body grounding中寻找,如果没有规则在
预测query中的缺失实体。答案从body grounding中寻找,如果没有规则在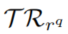 中来回答query中的关系
中来回答query中的关系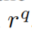 ,或没有匹配的body grounding在图中,那么对于该query将没有答案。
,或没有匹配的body grounding在图中,那么对于该query将没有答案。
- 为了在相关数据应用这些规则,将检索一个在时间窗口
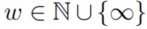 中的子图
中的子图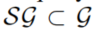 。对于
。对于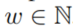 ,子图
,子图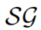 包含了
包含了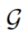 中所有有时间戳
中所有有时间戳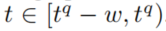 的edges。
的edges。
- 如果
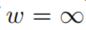 ,那么所有在
,那么所有在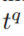
- 之前的时间戳的edges将被用于规则应用中。即
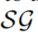 包含所有的事实,当
包含所有的事实,当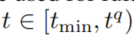 ,其中
,其中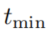 是在
是在 中的最小时间戳
中的最小时间戳
- 如果
- 我们通过减小置信度(后面会给出函数的定义)来应用
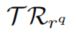 ,其中每个规则
,其中每个规则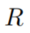 生成一组候选答案
生成一组候选答案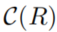
- 使用
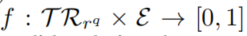 来映射候选答案
来映射候选答案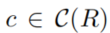 在这组query中成为正确答案的概率
在这组query中成为正确答案的概率
- 使用
- 设
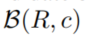 是
是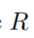 中的一组body groudings,且开始于实体
中的一组body groudings,且开始于实体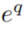 结束于候选实体
结束于候选实体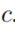 。我们选择一个函数
。我们选择一个函数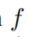 作为规则的置信度和一个以时差
作为规则的置信度和一个以时差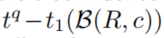 的函数为输入的凸组合作为分数,其中
的函数为输入的凸组合作为分数,其中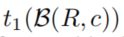 代表body中最早的时间戳
代表body中最早的时间戳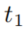 。如果存在几个body groundings,那么我们从所有可能的
。如果存在几个body groundings,那么我们从所有可能的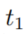 中选取最接近
中选取最接近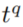 的那个。
的那个。 - 对于
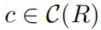 ,评分函数被定义为
,评分函数被定义为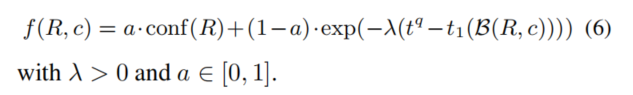
- 选择这个评分函数的直觉是,由高置信度规则生成的候选实体应该由一个高的分数。增加对rule grounding的时间框是基于这样的考虑:即随着edges之间的时间差减小,规则中的edges的存在变得越来越有可能。
- 选择指数分布是因为它通常用来模拟事件的相互到达时间。对于未来的时间戳
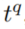 ,时间差
,时间差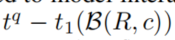 必是一个非负数,假设存在一个固定的均值,指数分布也是该时间差变量的最大熵分布。指数分布被重新调整,使两个和都在[0,1]之间。
必是一个非负数,假设存在一个固定的均值,指数分布也是该时间差变量的最大熵分布。指数分布被重新调整,使两个和都在[0,1]之间。
- 所有的候选答案连同他们的分数都保存在
 ,为这样的格式:
,为这样的格式: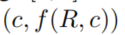 。我们停止规则应用程序当不同的候选答案
。我们停止规则应用程序当不同的候选答案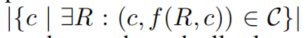 个数至少为
个数至少为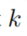 的时候,因此不需要走通所有的规则。
的时候,因此不需要走通所有的规则。
Candidate Ranking
对所有候选答案的排名,每个候选答案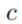 的所有分数将通过一个noisy-OR计算进行聚合,产生最终的分数:
的所有分数将通过一个noisy-OR计算进行聚合,产生最终的分数: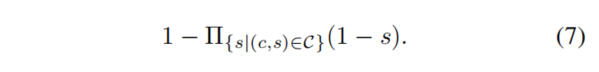
想法是聚合这些分数,去产生一个概率,其中被更多规则暗示的候选答案应该有更高分数。
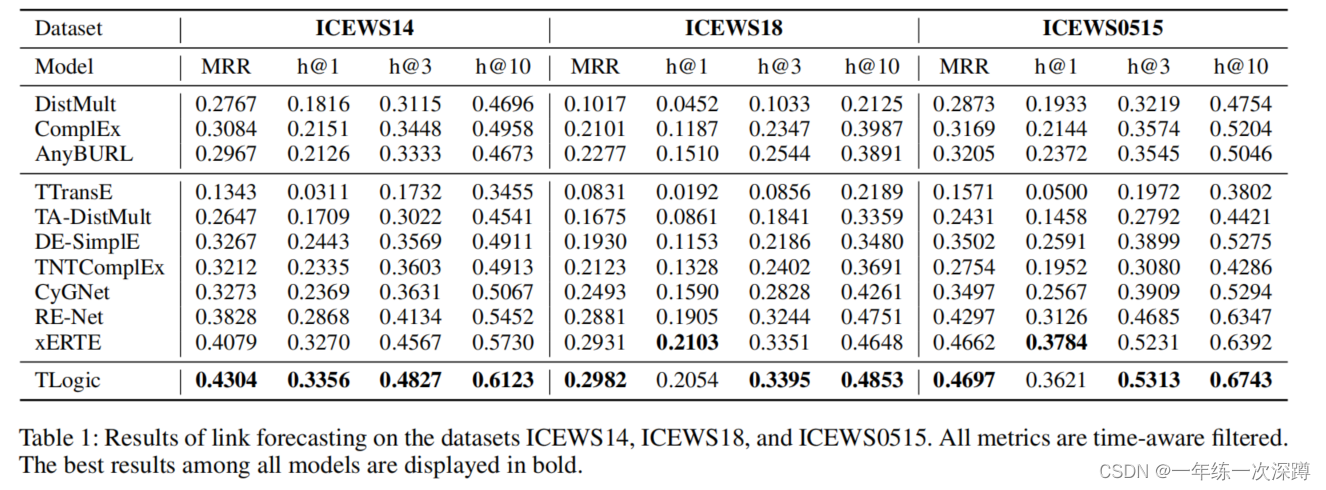
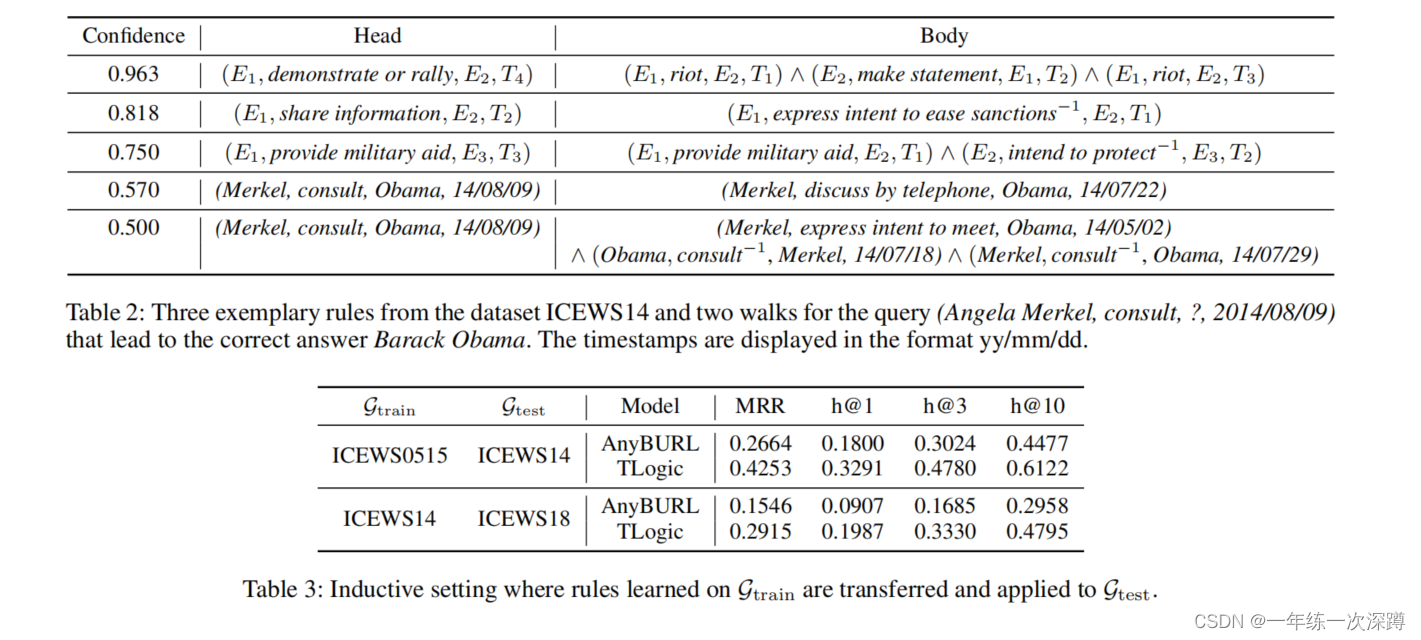
Experiment

















 1303
1303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









