






SSD目标检测
模型简介
SSD,全称Single Shot MultiBox Detector,是Wei Liu在ECCV 2016上提出的一种目标检测算法。使用Nvidia Titan X在VOC 2007测试集上,SSD对于输入尺寸300x300的网络,达到74.3%mAP(mean Average Precision)以及59FPS;对于512x512的网络,达到了76.9%mAP ,超越当时最强的Faster RCNN(73.2%mAP)。具体可参考论文[1]。
SSD目标检测主流算法分成可以两个类型:
-
two-stage方法:RCNN系列
通过算法产生候选框,然后再对这些候选框进行分类和回归。
-
one-stage方法:YOLO和SSD
直接通过主干网络给出类别位置信息,不需要区域生成。
SSD是单阶段的目标检测算法,通过卷积神经网络进行特征提取,取不同的特征层进行检测输出,所以SSD是一种多尺度的检测方法。在需要检测的特征层,直接使用一个3 × \times × 3卷积,进行通道的变换。SSD采用了anchor的策略,预设不同长宽比例的anchor,每一个输出特征层基于anchor预测多个检测框(4或者6)。采用了多尺度检测方法,浅层用于检测小目标,深层用于检测大目标。SSD的框架如下图:
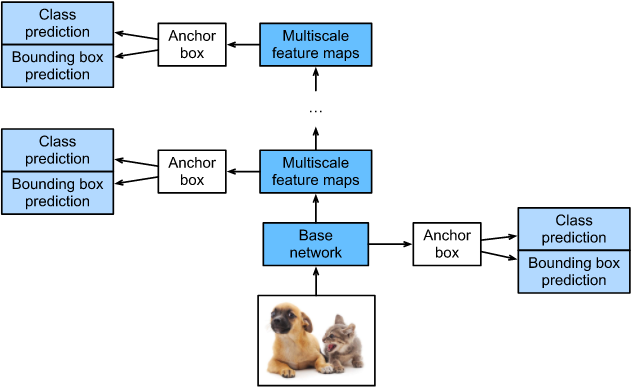
模型结构
SSD采用VGG16作为基础模型,然后在VGG16的基础上新增了卷积层来获得更多的特征图以用于检测。SSD的网络结构如图所示。上面是SSD模型,下面是YOLO模型,可以明显看到SSD利用了多尺度的特征图做检测。
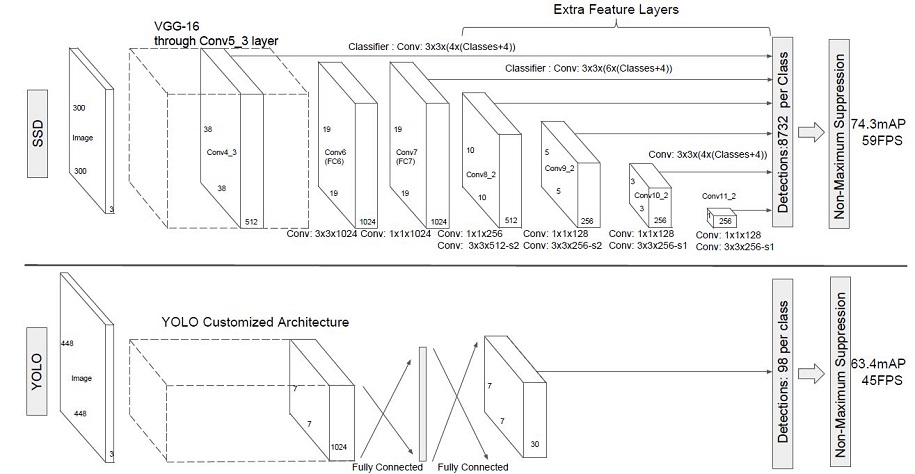
两种单阶段目标检测算法的比较:
SSD先通过卷积不断进行特征提取,在需要检测物体的网络,直接通过一个3
×
\times
× 3卷积得到输出,卷积的通道数由anchor数量和类别数量决定,具体为(anchor数量*(类别数量+4))。
SSD对比了YOLO系列目标检测方法,不同的是SSD通过卷积得到最后的边界框,而YOLO对最后的输出采用全连接的形式得到一维向量,对向量进行拆解得到最终的检测框。
模型特点
-
多尺度检测
在SSD的网络结构图中我们可以看到,SSD使用了多个特征层,特征层的尺寸分别是38 × \times × 38,19 × \times × 19,10 × \times × 10,5 × \times × 5,3 × \times × 3,1 × \times × 1,一共6种不同的特征图尺寸。大尺度特征图(较靠前的特征图)可以用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体。多尺度检测的方式,可以使得检测更加充分(SSD属于密集检测),更能检测出小目标。
-
采用卷积进行检测
与YOLO最后采用全连接层不同,SSD直接采用卷积对不同的特征图来进行提取检测结果。对于形状为m × \times × n × \times × p的特征图,只需要采用3 × \times × 3 × \times × p这样比较小的卷积核得到检测值。
-
预设anchor
在YOLOv1中,直接由网络预测目标的尺寸,这种方式使得预测框的长宽比和尺寸没有限制,难以训练。在SSD中,采用预设边界框,我们习惯称它为anchor(在SSD论文中叫default bounding boxes),预测框的尺寸在anchor的指导下进行微调。
环境准备
本案例基于MindSpore实现,开始实验前,请确保本地已经安装了mindspore、download、pycocotools、opencv-python。
%%capture captured_output
# 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
!pip uninstall mindspore -y
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
# 查看当前 mindspore 版本
!pip show mindspore
Name: mindspore
Version: 2.2.14
Summary: MindSpore is a new open source deep learning training/inference framework that could be used for mobile, edge and cloud scenarios.
Home-page: https://www.mindspore.cn
Author: The MindSpore Authors
Author-email: contact@mindspore.cn
License: Apache 2.0
Location: /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages
Requires: asttokens, astunparse, numpy, packaging, pillow, protobuf, psutil, scipy
Required-by:
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple pycocotools==2.0.7
Looking in indexes: https://pypi.mirrors.ustc.edu.cn/simple
Collecting pycocotools==2.0.7
Downloading https://mirrors.bfsu.edu.cn/pypi/web/packages/19/93/5aaec888e3aa4d05b3a1472f331b83f7dc684d9a6b2645709d8f3352ba00/pycocotools-2.0.7-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl (419 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m419.9/419.9 kB[0m [31m15.2 MB/s[0m eta [36m0:00:00[0m
[?25hRequirement already satisfied: matplotlib>=2.1.0 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from pycocotools==2.0.7) (3.9.0)
Requirement already satisfied: numpy in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from pycocotools==2.0.7) (1.26.4)
Requirement already satisfied: contourpy>=1.0.1 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from matplotlib>=2.1.0->pycocotools==2.0.7) (1.2.1)
Requirement already satisfied: cycler>=0.10 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from matplotlib>=2.1.0->pycocotools==2.0.7) (0.12.1)
Requirement already satisfied: fonttools>=4.22.0 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from matplotlib>=2.1.0->pycocotools==2.0.7) (4.53.0)
Requirement already satisfied: kiwisolver>=1.3.1 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from matplotlib>=2.1.0->pycocotools==2.0.7) (1.4.5)
Requirement already satisfied: packaging>=20.0 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from matplotlib>=2.1.0->pycocotools==2.0.7) (23.2)
Requirement already satisfied: pillow>=8 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from matplotlib>=2.1.0->pycocotools==2.0.7) (10.3.0)
Requirement already satisfied: pyparsing>=2.3.1 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from matplotlib>=2.1.0->pycocotools==2.0.7) (3.1.2)
Requirement already satisfied: python-dateutil>=2.7 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from matplotlib>=2.1.0->pycocotools==2.0.7) (2.9.0.post0)
Requirement already satisfied: importlib-resources>=3.2.0 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from matplotlib>=2.1.0->pycocotools==2.0.7) (6.4.0)
Requirement already satisfied: zipp>=3.1.0 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from importlib-resources>=3.2.0->matplotlib>=2.1.0->pycocotools==2.0.7) (3.17.0)
Requirement already satisfied: six>=1.5 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from python-dateutil>=2.7->matplotlib>=2.1.0->pycocotools==2.0.7) (1.16.0)
Installing collected packages: pycocotools
Successfully installed pycocotools-2.0.7
[1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m A new release of pip is available: [0m[31;49m24.1[0m[39;49m -> [0m[32;49m24.1.2[0m
[1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m To update, run: [0m[32;49mpython -m pip install --upgrade pip[0m
数据准备与处理
本案例所使用的数据集为COCO 2017。为了更加方便地保存和加载数据,本案例中在数据读取前首先将COCO数据集转换成MindRecord格式。使用MindSpore Record数据格式可以减少磁盘IO、网络IO开销,从而获得更好的使用体验和性能提升。
首先我们需要下载处理好的MindRecord格式的COCO数据集。
运行以下代码将数据集下载并解压到指定路径。
from download import download
dataset_url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/ssd_datasets.zip"
path = "./"
path = download(dataset_url, path, kind="zip", replace=True)
Downloading data from https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/ssd_datasets.zip (16.0 MB)
file_sizes: 100%|███████████████████████████| 16.8M/16.8M [00:00<00:00, 120MB/s]
Extracting zip file...
Successfully downloaded / unzipped to ./
然后我们为数据处理定义一些输入:
coco_root = "./datasets/"
anno_json = "./datasets/annotations/instances_val2017.json"
train_cls = ['background', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant',
'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog',
'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra',
'giraffe', 'backpack', 'umbrella', 'handbag', 'tie',
'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard',
'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup',
'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed',
'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote',
'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink',
'refrigerator', 'book', 'clock', 'vase', 'scissors',
'teddy bear', 'hair drier', 'toothbrush']
train_cls_dict = {}
for i, cls in enumerate(train_cls):
train_cls_dict[cls] = i
数据采样
为了使模型对于各种输入对象大小和形状更加鲁棒,SSD算法每个训练图像通过以下选项之一随机采样:
-
使用整个原始输入图像
-
采样一个区域,使采样区域和原始图片最小的交并比重叠为0.1,0.3,0.5,0.7或0.9
-
随机采样一个区域
每个采样区域的大小为原始图像大小的[0.3,1],长宽比在1/2和2之间。如果真实标签框中心在采样区域内,则保留两者重叠部分作为新图片的真实标注框。在上述采样步骤之后,将每个采样区域大小调整为固定大小,并以0.5的概率水平翻转。
import cv2
import numpy as np
def _rand(a=0., b=1.):
return np.random.rand() * (b - a) + a
def intersect(box_a, box_b):
"""Compute the intersect of two sets of boxes."""
max_yx = np.minimum(box_a[:, 2:4], box_b[2:4])
min_yx = np.maximum(box_a[:, :2], box_b[:2])
inter = np.clip((max_yx - min_yx), a_min=0, a_max=np.inf)
return inter[:, 0] * inter[:, 1]
def jaccard_numpy(box_a, box_b):
"""Compute the jaccard overlap of two sets of boxes."""
inter = intersect(box_a, box_b)
area_a = ((box_a[:, 2] - box_a[:, 0]) *
(box_a[:, 3] - box_a[:, 1]))
area_b = ((box_b[2] - box_b[0]) *
(box_b[3] - box_b[1]))
union = area_a + area_b - inter
return inter / union
def random_sample_crop(image, boxes):
"""Crop images and boxes randomly."""
height, width, _ = image.shape
min_iou = np.random.choice([None, 0.1, 0.3, 0.5, 0.7, 0.9])
if min_iou is None:
return image, boxes
for _ in range(50):
image_t = image
w = _rand(0.3, 1.0) * width
h = _rand(0.3, 1.0) * height
# aspect ratio constraint b/t .5 & 2
if h / w < 0.5 or h / w > 2:
continue
left = _rand() * (width - w)
top = _rand() * (height - h)
rect = np.array([int(top), int(left), int(top + h), int(left + w)])
overlap = jaccard_numpy(boxes, rect)
# dropout some boxes
drop_mask = overlap > 0
if not drop_mask.any():
continue
if overlap[drop_mask].min() < min_iou and overlap[drop_mask].max() > (min_iou + 0.2):
continue
image_t = image_t[rect[0]:rect[2], rect[1]:rect[3], :]
centers = (boxes[:, :2] + boxes[:, 2:4]) / 2.0
m1 = (rect[0] < centers[:, 0]) * (rect[1] < centers[:, 1])
m2 = (rect[2] > centers[:, 0]) * (rect[3] > centers[:, 1])
# mask in that both m1 and m2 are true
mask = m1 * m2 * drop_mask
# have any valid boxes? try again if not
if not mask.any():
continue
# take only matching gt boxes
boxes_t = boxes[mask, :].copy()
boxes_t[:, :2] = np.maximum(boxes_t[:, :2], rect[:2])
boxes_t[:, :2] -= rect[:2]
boxes_t[:, 2:4] = np.minimum(boxes_t[:, 2:4], rect[2:4])
boxes_t[:, 2:4] -= rect[:2]
return image_t, boxes_t
return image, boxes
def ssd_bboxes_encode(boxes):
"""Labels anchors with ground truth inputs."""
def jaccard_with_anchors(bbox):
"""Compute jaccard score a box and the anchors."""
# Intersection bbox and volume.
ymin = np.maximum(y1, bbox[0])
xmin = np.maximum(x1, bbox[1])
ymax = np.minimum(y2, bbox[2])
xmax = np.minimum(x2, bbox[3])
w = np.maximum(xmax - xmin, 0.)
h = np.maximum(ymax - ymin, 0.)
# Volumes.
inter_vol = h * w
union_vol = vol_anchors + (bbox[2] - bbox[0]) * (bbox[3] - bbox[1]) - inter_vol
jaccard = inter_vol / union_vol
return np.squeeze(jaccard)
pre_scores = np.zeros((8732), dtype=np.float32)
t_boxes = np.zeros((8732, 4), dtype=np.float32)
t_label = np.zeros((8732), dtype=np.int64)
for bbox in boxes:
label = int(bbox[4])
scores = jaccard_with_anchors(bbox)
idx = np.argmax(scores)
scores[idx] = 2.0
mask = (scores > matching_threshold)
mask = mask & (scores > pre_scores)
pre_scores = np.maximum(pre_scores, scores * mask)
t_label = mask * label + (1 - mask) * t_label
for i in range(4):
t_boxes[:, i] = mask * bbox[i] + (1 - mask) * t_boxes[:, i]
index = np.nonzero(t_label)
# Transform to tlbr.
bboxes = np.zeros((8732, 4), dtype=np.float32)
bboxes[:, [0, 1]] = (t_boxes[:, [0, 1]] + t_boxes[:, [2, 3]]) / 2
bboxes[:, [2, 3]] = t_boxes[:, [2, 3]] - t_boxes[:, [0, 1]]
# Encode features.
bboxes_t = bboxes[index]
default_boxes_t = default_boxes[index]
bboxes_t[:, :2] = (bboxes_t[:, :2] - default_boxes_t[:, :2]) / (default_boxes_t[:, 2:] * 0.1)
tmp = np.maximum(bboxes_t[:, 2:4] / default_boxes_t[:, 2:4], 0.000001)
bboxes_t[:, 2:4] = np.log(tmp) / 0.2
bboxes[index] = bboxes_t
num_match = np.array([len(np.nonzero(t_label)[0])], dtype=np.int32)
return bboxes, t_label.astype(np.int32), num_match
def preprocess_fn(img_id, image, box, is_training):
"""Preprocess function for dataset."""
cv2.setNumThreads(2)
def _infer_data(image, input_shape):
img_h, img_w, _ = image.shape
input_h, input_w = input_shape
image = cv2.resize(image, (input_w, input_h))
# When the channels of image is 1
if len(image.shape) == 2:
image = np.expand_dims(image, axis=-1)
image = np.concatenate([image, image, image], axis=-1)
return img_id, image, np.array((img_h, img_w), np.float32)
def _data_aug(image, box, is_training, image_size=(300, 300)):
ih, iw, _ = image.shape
h, w = image_size
if not is_training:
return _infer_data(image, image_size)
# Random crop
box = box.astype(np.float32)
image, box = random_sample_crop(image, box)
ih, iw, _ = image.shape
# Resize image
image = cv2.resize(image, (w, h))
# Flip image or not
flip = _rand() < .5
if flip:
image = cv2.flip(image, 1, dst=None)
# When the channels of image is 1
if len(image.shape) == 2:
image = np.expand_dims(image, axis=-1)
image = np.concatenate([image, image, image], axis=-1)
box[:, [0, 2]] = box[:, [0, 2]] / ih
box[:, [1, 3]] = box[:, [1, 3]] / iw
if flip:
box[:, [1, 3]] = 1 - box[:, [3, 1]]
box, label, num_match = ssd_bboxes_encode(box)
return image, box, label, num_match
return _data_aug(image, box, is_training, image_size=[300, 300])
数据集创建
from mindspore import Tensor
from mindspore.dataset import MindDataset
from mindspore.dataset.vision import Decode, HWC2CHW, Normalize, RandomColorAdjust
def create_ssd_dataset(mindrecord_file, batch_size=32, device_num=1, rank=0,
is_training=True, num_parallel_workers=1, use_multiprocessing=True):
"""Create SSD dataset with MindDataset."""
dataset = MindDataset(mindrecord_file, columns_list=["img_id", "image", "annotation"], num_shards=device_num,
shard_id=rank, num_parallel_workers=num_parallel_workers, shuffle=is_training)
decode = Decode()
dataset = dataset.map(operations=decode, input_columns=["image"])
change_swap_op = HWC2CHW()
# Computed from random subset of ImageNet training images
normalize_op = Normalize(mean=[0.485 * 255, 0.456 * 255, 0.406 * 255],
std=[0.229 * 255, 0.224 * 255, 0.225 * 255])
color_adjust_op = RandomColorAdjust(brightness=0.4, contrast=0.4, saturation=0.4)
compose_map_func = (lambda img_id, image, annotation: preprocess_fn(img_id, image, annotation, is_training))
if is_training:
output_columns = ["image", "box", "label", "num_match"]
trans = [color_adjust_op, normalize_op, change_swap_op]
else:
output_columns = ["img_id", "image", "image_shape"]
trans = [normalize_op, change_swap_op]
dataset = dataset.map(operations=compose_map_func, input_columns=["img_id", "image", "annotation"],
output_columns=output_columns, python_multiprocessing=use_multiprocessing,
num_parallel_workers=num_parallel_workers)
dataset = dataset.map(operations=trans, input_columns=["image"], python_multiprocessing=use_multiprocessing,
num_parallel_workers=num_parallel_workers)
dataset = dataset.batch(batch_size, drop_remainder=True)
return dataset
模型构建
SSD的网络结构主要分为以下几个部分:
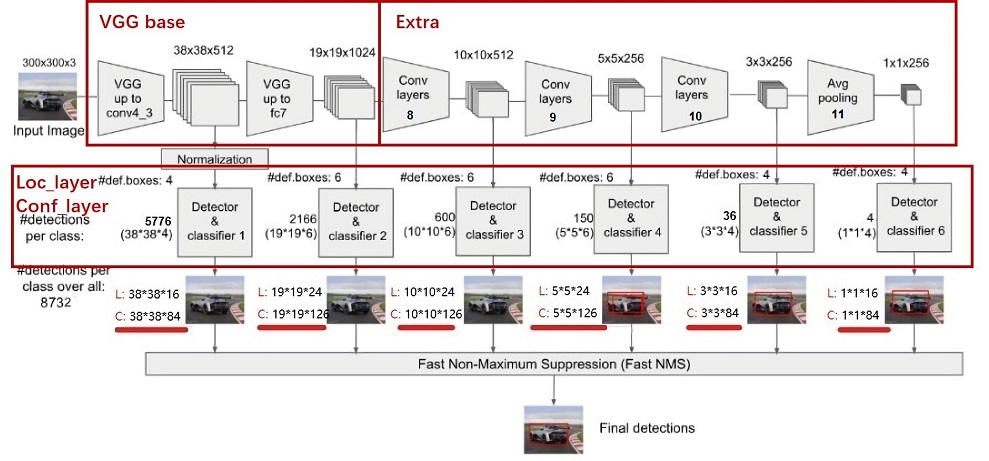
-
VGG16 Base Layer
-
Extra Feature Layer
-
Detection Layer
-
NMS
-
Anchor
Backbone Layer

输入图像经过预处理后大小固定为300×300,首先经过backbone,本案例中使用的是VGG16网络的前13个卷积层,然后分别将VGG16的全连接层fc6和fc7转换成3 × \times × 3卷积层block6和1 × \times × 1卷积层block7,进一步提取特征。 在block6中,使用了空洞数为6的空洞卷积,其padding也为6,这样做同样也是为了增加感受野的同时保持参数量与特征图尺寸的不变。
Extra Feature Layer
在VGG16的基础上,SSD进一步增加了4个深度卷积层,用于提取更高层的语义信息:

block8-11,用于更高语义信息的提取。block8的通道数为512,而block9、block10与block11的通道数都为256。从block7到block11,这5个卷积后输出特征图的尺寸依次为19×19、10×10、5×5、3×3和1×1。为了降低参数量,使用了1×1卷积先降低通道数为该层输出通道数的一半,再利用3×3卷积进行特征提取。
Anchor
SSD采用了PriorBox来进行区域生成。将固定大小宽高的PriorBox作为先验的感兴趣区域,利用一个阶段完成能够分类与回归。设计大量的密集的PriorBox保证了对整幅图像的每个地方都有检测。PriorBox位置的表示形式是以中心点坐标和框的宽、高(cx,cy,w,h)来表示的,同时都转换成百分比的形式。
PriorBox生成规则:
SSD由6个特征层来检测目标,在不同特征层上,PriorBox的尺寸scale大小是不一样的,最低层的scale=0.1,最高层的scale=0.95,其他层的计算公式如下:
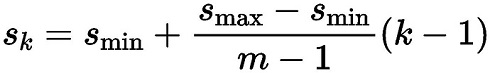
在某个特征层上其scale一定,那么会设置不同长宽比ratio的PriorBox,其长和宽的计算公式如下:
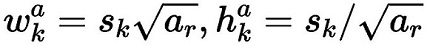
在ratio=1的时候,还会根据该特征层和下一个特征层计算一个特定scale的PriorBox(长宽比ratio=1),计算公式如下:
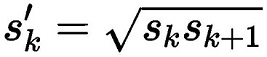
每个特征层的每个点都会以上述规则生成PriorBox,(cx,cy)由当前点的中心点来确定,由此每个特征层都生成大量密集的PriorBox,如下图:

SSD使用了第4、7、8、9、10和11这6个卷积层得到的特征图,这6个特征图尺寸越来越小,而其对应的感受野越来越大。6个特征图上的每一个点分别对应4、6、6、6、4、4个PriorBox。某个特征图上的一个点根据下采样率可以得到在原图的坐标,以该坐标为中心生成4个或6个不同大小的PriorBox,然后利用特征图的特征去预测每一个PriorBox对应类别与位置的预测量。例如:第8个卷积层得到的特征图大小为10×10×512,每个点对应6个PriorBox,一共有600个PriorBox。定义MultiBox类,生成多个预测框。
Detection Layer
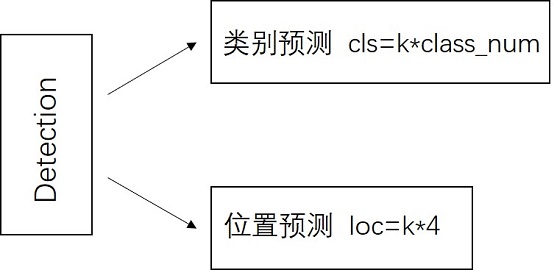
SSD模型一共有6个预测特征图,对于其中一个尺寸为m*n,通道为p的预测特征图,假设其每个像素点会产生k个anchor,每个anchor会对应c个类别和4个回归偏移量,使用(4+c)k个尺寸为3x3,通道为p的卷积核对该预测特征图进行卷积操作,得到尺寸为m*n,通道为(4+c)m*k的输出特征图,它包含了预测特征图上所产生的每个anchor的回归偏移量和各类别概率分数。所以对于尺寸为m*n的预测特征图,总共会产生(4+c)k*m*n个结果。cls分支的输出通道数为k*class_num,loc分支的输出通道数为k*4。
from mindspore import nn
def _make_layer(channels):
in_channels = channels[0]
layers = []
for out_channels in channels[1:]:
layers.append(nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=3))
layers.append(nn.ReLU())
in_channels = out_channels
return nn.SequentialCell(layers)
class Vgg16(nn.Cell):
"""VGG16 module."""
def __init__(self):
super(Vgg16, self).__init__()
self.b1 = _make_layer([3, 64, 64])
self.b2 = _make_layer([64, 128, 128])
self.b3 = _make_layer([128, 256, 256, 256])
self.b4 = _make_layer([256, 512, 512, 512])
self.b5 = _make_layer([512, 512, 512, 512])
self.m1 = nn.MaxPool2d(kernel_size=2, stride=2, pad_mode='SAME')
self.m2 = nn.MaxPool2d(kernel_size=2, stride=2, pad_mode='SAME')
self.m3 = nn.MaxPool2d(kernel_size=2, stride=2, pad_mode='SAME')
self.m4 = nn.MaxPool2d(kernel_size=2, stride=2, pad_mode='SAME')
self.m5 = nn.MaxPool2d(kernel_size=3, stride=1, pad_mode='SAME')
def construct(self, x):
# block1
x = self.b1(x)
x = self.m1(x)
# block2
x = self.b2(x)
x = self.m2(x)
# block3
x = self.b3(x)
x = self.m3(x)
# block4
x = self.b4(x)
block4 = x
x = self.m4(x)
# block5
x = self.b5(x)
x = self.m5(x)
return block4, x
import mindspore as ms
import mindspore.nn as nn
import mindspore.ops as ops
def _last_conv2d(in_channel, out_channel, kernel_size=3, stride=1, pad_mod='same', pad=0):
in_channels = in_channel
out_channels = in_channel
depthwise_conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, pad_mode='same',
padding=pad, group=in_channels)
conv = nn.Conv2d(in_channel, out_channel, kernel_size=1, stride=1, padding=0, pad_mode='same', has_bias=True)
bn = nn.BatchNorm2d(in_channel, eps=1e-3, momentum=0.97,
gamma_init=1, beta_init=0, moving_mean_init=0, moving_var_init=1)
return nn.SequentialCell([depthwise_conv, bn, nn.ReLU6(), conv])
class FlattenConcat(nn.Cell):
"""FlattenConcat module."""
def __init__(self):
super(FlattenConcat, self).__init__()
self.num_ssd_boxes = 8732
def construct(self, inputs):
output = ()
batch_size = ops.shape(inputs[0])[0]
for x in inputs:
x = ops.transpose(x, (0, 2, 3, 1))
output += (ops.reshape(x, (batch_size, -1)),)
res = ops.concat(output, axis=1)
return ops.reshape(res, (batch_size, self.num_ssd_boxes, -1))
class MultiBox(nn.Cell):
"""
Multibox conv layers. Each multibox layer contains class conf scores and localization predictions.
"""
def __init__(self):
super(MultiBox, self).__init__()
num_classes = 81
out_channels = [512, 1024, 512, 256, 256, 256]
num_default = [4, 6, 6, 6, 4, 4]
loc_layers = []
cls_layers = []
for k, out_channel in enumerate(out_channels):
loc_layers += [_last_conv2d(out_channel, 4 * num_default[k],
kernel_size=3, stride=1, pad_mod='same', pad=0)]
cls_layers += [_last_conv2d(out_channel, num_classes * num_default[k],
kernel_size=3, stride=1, pad_mod='same', pad=0)]
self.multi_loc_layers = nn.CellList(loc_layers)
self.multi_cls_layers = nn.CellList(cls_layers)
self.flatten_concat = FlattenConcat()
def construct(self, inputs):
loc_outputs = ()
cls_outputs = ()
for i in range(len(self.multi_loc_layers)):
loc_outputs += (self.multi_loc_layers[i](inputs[i]),)
cls_outputs += (self.multi_cls_layers[i](inputs[i]),)
return self.flatten_concat(loc_outputs), self.flatten_concat(cls_outputs)
class SSD300Vgg16(nn.Cell):
"""SSD300Vgg16 module."""
def __init__(self):
super(SSD300Vgg16, self).__init__()
# VGG16 backbone: block1~5
self.backbone = Vgg16()
# SSD blocks: block6~7
self.b6_1 = nn.Conv2d(in_channels=512, out_channels=1024, kernel_size=3, padding=6, dilation=6, pad_mode='pad')
self.b6_2 = nn.Dropout(p=0.5)
self.b7_1 = nn.Conv2d(in_channels=1024, out_channels=1024, kernel_size=1)
self.b7_2 = nn.Dropout(p=0.5)
# Extra Feature Layers: block8~11
self.b8_1 = nn.Conv2d(in_channels=1024, out_channels=256, kernel_size=1, padding=1, pad_mode='pad')
self.b8_2 = nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=2, pad_mode='valid')
self.b9_1 = nn.Conv2d(in_channels=512, out_channels=128, kernel_size=1, padding=1, pad_mode='pad')
self.b9_2 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=2, pad_mode='valid')
self.b10_1 = nn.Conv2d(in_channels=256, out_channels=128, kernel_size=1)
self.b10_2 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, pad_mode='valid')
self.b11_1 = nn.Conv2d(in_channels=256, out_channels=128, kernel_size=1)
self.b11_2 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, pad_mode='valid')
# boxes
self.multi_box = MultiBox()
def construct(self, x):
# VGG16 backbone: block1~5
block4, x = self.backbone(x)
# SSD blocks: block6~7
x = self.b6_1(x) # 1024
x = self.b6_2(x)
x = self.b7_1(x) # 1024
x = self.b7_2(x)
block7 = x
# Extra Feature Layers: block8~11
x = self.b8_1(x) # 256
x = self.b8_2(x) # 512
block8 = x
x = self.b9_1(x) # 128
x = self.b9_2(x) # 256
block9 = x
x = self.b10_1(x) # 128
x = self.b10_2(x) # 256
block10 = x
x = self.b11_1(x) # 128
x = self.b11_2(x) # 256
block11 = x
# boxes
multi_feature = (block4, block7, block8, block9, block10, block11)
pred_loc, pred_label = self.multi_box(multi_feature)
if not self.training:
pred_label = ops.sigmoid(pred_label)
pred_loc = pred_loc.astype(ms.float32)
pred_label = pred_label.astype(ms.float32)
return pred_loc, pred_label
损失函数
SSD算法的目标函数分为两部分:计算相应的预选框与目标类别的置信度误差(confidence loss, conf)以及相应的位置误差(locatization loss, loc):
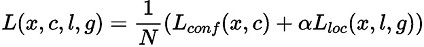
其中:
N 是先验框的正样本数量;
c 为类别置信度预测值;
l 为先验框的所对应边界框的位置预测值;
g 为ground truth的位置参数
α 用以调整confidence loss和location loss之间的比例,默认为1。
对于位置损失函数
针对所有的正样本,采用 Smooth L1 Loss, 位置信息都是 encode 之后的位置信息。
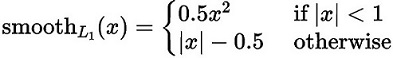
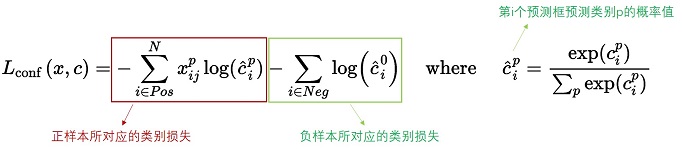
对于置信度损失函数
置信度损失是多类置信度©上的softmax损失。
def class_loss(logits, label):
"""Calculate category losses."""
label = ops.one_hot(label, ops.shape(logits)[-1], Tensor(1.0, ms.float32), Tensor(0.0, ms.float32))
weight = ops.ones_like(logits)
pos_weight = ops.ones_like(logits)
sigmiod_cross_entropy = ops.binary_cross_entropy_with_logits(logits, label, weight.astype(ms.float32), pos_weight.astype(ms.float32))
sigmoid = ops.sigmoid(logits)
label = label.astype(ms.float32)
p_t = label * sigmoid + (1 - label) * (1 - sigmoid)
modulating_factor = ops.pow(1 - p_t, 2.0)
alpha_weight_factor = label * 0.75 + (1 - label) * (1 - 0.75)
focal_loss = modulating_factor * alpha_weight_factor * sigmiod_cross_entropy
return focal_loss
Metrics
在SSD中,训练过程是不需要用到非极大值抑制(NMS),但当进行检测时,例如输入一张图片要求输出框的时候,需要用到NMS过滤掉那些重叠度较大的预测框。
非极大值抑制的流程如下:
-
根据置信度得分进行排序
-
选择置信度最高的比边界框添加到最终输出列表中,将其从边界框列表中删除
-
计算所有边界框的面积
-
计算置信度最高的边界框与其它候选框的IoU
-
删除IoU大于阈值的边界框
-
重复上述过程,直至边界框列表为空
import json
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
def apply_eval(eval_param_dict):
net = eval_param_dict["net"]
net.set_train(False)
ds = eval_param_dict["dataset"]
anno_json = eval_param_dict["anno_json"]
coco_metrics = COCOMetrics(anno_json=anno_json,
classes=train_cls,
num_classes=81,
max_boxes=100,
nms_threshold=0.6,
min_score=0.1)
for data in ds.create_dict_iterator(output_numpy=True, num_epochs=1):
img_id = data['img_id']
img_np = data['image']
image_shape = data['image_shape']
output = net(Tensor(img_np))
for batch_idx in range(img_np.shape[0]):
pred_batch = {
"boxes": output[0].asnumpy()[batch_idx],
"box_scores": output[1].asnumpy()[batch_idx],
"img_id": int(np.squeeze(img_id[batch_idx])),
"image_shape": image_shape[batch_idx]
}
coco_metrics.update(pred_batch)
eval_metrics = coco_metrics.get_metrics()
return eval_metrics
def apply_nms(all_boxes, all_scores, thres, max_boxes):
"""Apply NMS to bboxes."""
y1 = all_boxes[:, 0]
x1 = all_boxes[:, 1]
y2 = all_boxes[:, 2]
x2 = all_boxes[:, 3]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
order = all_scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
if len(keep) >= max_boxes:
break
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= thres)[0]
order = order[inds + 1]
return keep
class COCOMetrics:
"""Calculate mAP of predicted bboxes."""
def __init__(self, anno_json, classes, num_classes, min_score, nms_threshold, max_boxes):
self.num_classes = num_classes
self.classes = classes
self.min_score = min_score
self.nms_threshold = nms_threshold
self.max_boxes = max_boxes
self.val_cls_dict = {i: cls for i, cls in enumerate(classes)}
self.coco_gt = COCO(anno_json)
cat_ids = self.coco_gt.loadCats(self.coco_gt.getCatIds())
self.class_dict = {cat['name']: cat['id'] for cat in cat_ids}
self.predictions = []
self.img_ids = []
def update(self, batch):
pred_boxes = batch['boxes']
box_scores = batch['box_scores']
img_id = batch['img_id']
h, w = batch['image_shape']
final_boxes = []
final_label = []
final_score = []
self.img_ids.append(img_id)
for c in range(1, self.num_classes):
class_box_scores = box_scores[:, c]
score_mask = class_box_scores > self.min_score
class_box_scores = class_box_scores[score_mask]
class_boxes = pred_boxes[score_mask] * [h, w, h, w]
if score_mask.any():
nms_index = apply_nms(class_boxes, class_box_scores, self.nms_threshold, self.max_boxes)
class_boxes = class_boxes[nms_index]
class_box_scores = class_box_scores[nms_index]
final_boxes += class_boxes.tolist()
final_score += class_box_scores.tolist()
final_label += [self.class_dict[self.val_cls_dict[c]]] * len(class_box_scores)
for loc, label, score in zip(final_boxes, final_label, final_score):
res = {}
res['image_id'] = img_id
res['bbox'] = [loc[1], loc[0], loc[3] - loc[1], loc[2] - loc[0]]
res['score'] = score
res['category_id'] = label
self.predictions.append(res)
def get_metrics(self):
with open('predictions.json', 'w') as f:
json.dump(self.predictions, f)
coco_dt = self.coco_gt.loadRes('predictions.json')
E = COCOeval(self.coco_gt, coco_dt, iouType='bbox')
E.params.imgIds = self.img_ids
E.evaluate()
E.accumulate()
E.summarize()
return E.stats[0]
class SsdInferWithDecoder(nn.Cell):
"""
SSD Infer wrapper to decode the bbox locations."""
def __init__(self, network, default_boxes, ckpt_path):
super(SsdInferWithDecoder, self).__init__()
param_dict = ms.load_checkpoint(ckpt_path)
ms.load_param_into_net(network, param_dict)
self.network = network
self.default_boxes = default_boxes
self.prior_scaling_xy = 0.1
self.prior_scaling_wh = 0.2
def construct(self, x):
pred_loc, pred_label = self.network(x)
default_bbox_xy = self.default_boxes[..., :2]
default_bbox_wh = self.default_boxes[..., 2:]
pred_xy = pred_loc[..., :2] * self.prior_scaling_xy * default_bbox_wh + default_bbox_xy
pred_wh = ops.exp(pred_loc[..., 2:] * self.prior_scaling_wh) * default_bbox_wh
pred_xy_0 = pred_xy - pred_wh / 2.0
pred_xy_1 = pred_xy + pred_wh / 2.0
pred_xy = ops.concat((pred_xy_0, pred_xy_1), -1)
pred_xy = ops.maximum(pred_xy, 0)
pred_xy = ops.minimum(pred_xy, 1)
return pred_xy, pred_label
训练过程
(1)先验框匹配
在训练过程中,首先要确定训练图片中的ground truth(真实目标)与哪个先验框来进行匹配,与之匹配的先验框所对应的边界框将负责预测它。
SSD的先验框与ground truth的匹配原则主要有两点:
-
对于图片中每个ground truth,找到与其IOU最大的先验框,该先验框与其匹配,这样可以保证每个ground truth一定与某个先验框匹配。通常称与ground truth匹配的先验框为正样本,反之,若一个先验框没有与任何ground truth进行匹配,那么该先验框只能与背景匹配,就是负样本。
-
对于剩余的未匹配先验框,若某个ground truth的IOU大于某个阈值(一般是0.5),那么该先验框也与这个ground truth进行匹配。尽管一个ground truth可以与多个先验框匹配,但是ground truth相对先验框还是太少了,所以负样本相对正样本会很多。为了保证正负样本尽量平衡,SSD采用了hard negative mining,就是对负样本进行抽样,抽样时按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列,选取误差的较大的top-k作为训练的负样本,以保证正负样本比例接近1:3。
注意点:
-
通常称与gt匹配的prior为正样本,反之,若某一个prior没有与任何一个gt匹配,则为负样本。
-
某个gt可以和多个prior匹配,而每个prior只能和一个gt进行匹配。
-
如果多个gt和某一个prior的IOU均大于阈值,那么prior只与IOU最大的那个进行匹配。
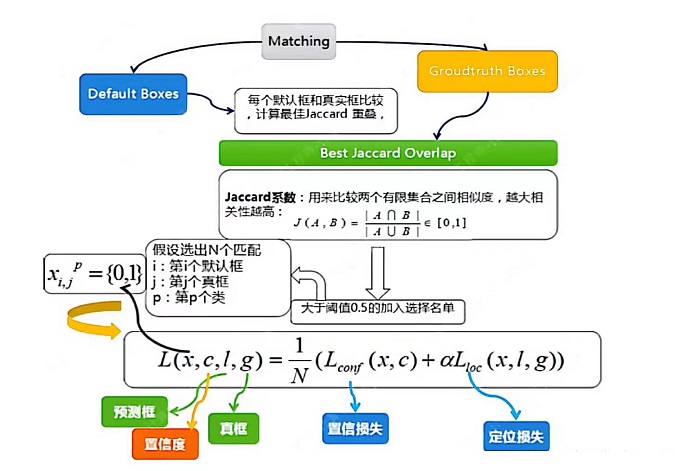
如上图所示,训练过程中的 prior boxes 和 ground truth boxes 的匹配,基本思路是:让每一个 prior box 回归并且到 ground truth box,这个过程的调控我们需要损失层的帮助,他会计算真实值和预测值之间的误差,从而指导学习的走向。
(2)损失函数
损失函数使用的是上文提到的位置损失函数和置信度损失函数的加权和。
(3)数据增强
使用之前定义好的数据增强方式,对创建好的数据增强方式进行数据增强。
模型训练时,设置模型训练的epoch次数为60,然后通过create_ssd_dataset类创建了训练集和验证集。batch_size大小为5,图像尺寸统一调整为300×300。损失函数使用位置损失函数和置信度损失函数的加权和,优化器使用Momentum,并设置初始学习率为0.001。回调函数方面使用了LossMonitor和TimeMonitor来监控训练过程中每个epoch结束后,损失值Loss的变化情况以及每个epoch、每个step的运行时间。设置每训练10个epoch保存一次模型。
import math
import itertools as it
from mindspore import set_seed
class GeneratDefaultBoxes():
"""
Generate Default boxes for SSD, follows the order of (W, H, archor_sizes).
`self.default_boxes` has a shape of [archor_sizes, H, W, 4], the last dimension is [y, x, h, w].
`self.default_boxes_tlbr` has a shape as `self.default_boxes`, the last dimension is [y1, x1, y2, x2].
"""
def __init__(self):
fk = 300 / np.array([8, 16, 32, 64, 100, 300])
scale_rate = (0.95 - 0.1) / (len([4, 6, 6, 6, 4, 4]) - 1)
scales = [0.1 + scale_rate * i for i in range(len([4, 6, 6, 6, 4, 4]))] + [1.0]
self.default_boxes = []
for idex, feature_size in enumerate([38, 19, 10, 5, 3, 1]):
sk1 = scales[idex]
sk2 = scales[idex + 1]
sk3 = math.sqrt(sk1 * sk2)
if idex == 0 and not [[2], [2, 3], [2, 3], [2, 3], [2], [2]][idex]:
w, h = sk1 * math.sqrt(2), sk1 / math.sqrt(2)
all_sizes = [(0.1, 0.1), (w, h), (h, w)]
else:
all_sizes = [(sk1, sk1)]
for aspect_ratio in [[2], [2, 3], [2, 3], [2, 3], [2], [2]][idex]:
w, h = sk1 * math.sqrt(aspect_ratio), sk1 / math.sqrt(aspect_ratio)
all_sizes.append((w, h))
all_sizes.append((h, w))
all_sizes.append((sk3, sk3))
assert len(all_sizes) == [4, 6, 6, 6, 4, 4][idex]
for i, j in it.product(range(feature_size), repeat=2):
for w, h in all_sizes:
cx, cy = (j + 0.5) / fk[idex], (i + 0.5) / fk[idex]
self.default_boxes.append([cy, cx, h, w])
def to_tlbr(cy, cx, h, w):
return cy - h / 2, cx - w / 2, cy + h / 2, cx + w / 2
# For IoU calculation
self.default_boxes_tlbr = np.array(tuple(to_tlbr(*i) for i in self.default_boxes), dtype='float32')
self.default_boxes = np.array(self.default_boxes, dtype='float32')
default_boxes_tlbr = GeneratDefaultBoxes().default_boxes_tlbr
default_boxes = GeneratDefaultBoxes().default_boxes
y1, x1, y2, x2 = np.split(default_boxes_tlbr[:, :4], 4, axis=-1)
vol_anchors = (x2 - x1) * (y2 - y1)
matching_threshold = 0.5
from mindspore.common.initializer import initializer, TruncatedNormal
def init_net_param(network, initialize_mode='TruncatedNormal'):
"""Init the parameters in net."""
params = network.trainable_params()
for p in params:
if 'beta' not in p.name and 'gamma' not in p.name and 'bias' not in p.name:
if initialize_mode == 'TruncatedNormal':
p.set_data(initializer(TruncatedNormal(0.02), p.data.shape, p.data.dtype))
else:
p.set_data(initialize_mode, p.data.shape, p.data.dtype)
def get_lr(global_step, lr_init, lr_end, lr_max, warmup_epochs, total_epochs, steps_per_epoch):
""" generate learning rate array"""
lr_each_step = []
total_steps = steps_per_epoch * total_epochs
warmup_steps = steps_per_epoch * warmup_epochs
for i in range(total_steps):
if i < warmup_steps:
lr = lr_init + (lr_max - lr_init) * i / warmup_steps
else:
lr = lr_end + (lr_max - lr_end) * (1. + math.cos(math.pi * (i - warmup_steps) / (total_steps - warmup_steps))) / 2.
if lr < 0.0:
lr = 0.0
lr_each_step.append(lr)
current_step = global_step
lr_each_step = np.array(lr_each_step).astype(np.float32)
learning_rate = lr_each_step[current_step:]
return learning_rate
import mindspore.dataset as ds
ds.config.set_enable_shared_mem(False)
import time
from mindspore.amp import DynamicLossScaler
set_seed(1)
# load data
mindrecord_dir = "./datasets/MindRecord_COCO"
mindrecord_file = "./datasets/MindRecord_COCO/ssd.mindrecord0"
dataset = create_ssd_dataset(mindrecord_file, batch_size=5, rank=0, use_multiprocessing=True)
dataset_size = dataset.get_dataset_size()
image, get_loc, gt_label, num_matched_boxes = next(dataset.create_tuple_iterator())
# Network definition and initialization
network = SSD300Vgg16()
init_net_param(network)
# Define the learning rate
lr = Tensor(get_lr(global_step=0 * dataset_size,
lr_init=0.001, lr_end=0.001 * 0.05, lr_max=0.05,
warmup_epochs=2, total_epochs=60, steps_per_epoch=dataset_size))
# Define the optimizer
opt = nn.Momentum(filter(lambda x: x.requires_grad, network.get_parameters()), lr,
0.9, 0.00015, float(1024))
# Define the forward procedure
def forward_fn(x, gt_loc, gt_label, num_matched_boxes):
pred_loc, pred_label = network(x)
mask = ops.less(0, gt_label).astype(ms.float32)
num_matched_boxes = ops.sum(num_matched_boxes.astype(ms.float32))
# Positioning loss
mask_loc = ops.tile(ops.expand_dims(mask, -1), (1, 1, 4))
smooth_l1 = nn.SmoothL1Loss()(pred_loc, gt_loc) * mask_loc
loss_loc = ops.sum(ops.sum(smooth_l1, -1), -1)
# Category loss
loss_cls = class_loss(pred_label, gt_label)
loss_cls = ops.sum(loss_cls, (1, 2))
return ops.sum((loss_cls + loss_loc) / num_matched_boxes)
grad_fn = ms.value_and_grad(forward_fn, None, opt.parameters, has_aux=False)
loss_scaler = DynamicLossScaler(1024, 2, 1000)
# Gradient updates
def train_step(x, gt_loc, gt_label, num_matched_boxes):
loss, grads = grad_fn(x, gt_loc, gt_label, num_matched_boxes)
opt(grads)
return loss
print("=================== Starting Training =====================")
for epoch in range(600):
network.set_train(True)
begin_time = time.time()
for step, (image, get_loc, gt_label, num_matched_boxes) in enumerate(dataset.create_tuple_iterator()):
loss = train_step(image, get_loc, gt_label, num_matched_boxes)
end_time = time.time()
times = end_time - begin_time
print(f"Epoch:[{int(epoch + 1)}/{int(600)}], "
f"loss:{loss} , "
f"time:{times}s ")
ms.save_checkpoint(network, "ssd-60_9.ckpt")
print("=================== Training Success =====================")
=================== Starting Training =====================
Epoch:[1/600], loss:1084.1497 , time:30.86062979698181s
Epoch:[2/600], loss:1074.2557 , time:1.9650640487670898s
Epoch:[3/600], loss:1056.8951 , time:1.9375627040863037s
Epoch:[4/600], loss:1038.4043 , time:1.8517911434173584s
Epoch:[5/600], loss:1019.45105 , time:1.9078209400177002s
Epoch:[6/600], loss:1000.02765 , time:2.0097851753234863s
Epoch:[7/600], loss:979.8791 , time:1.89394211769104s
Epoch:[8/600], loss:958.6157 , time:1.9265844821929932s
Epoch:[9/600], loss:935.74915 , time:1.9756755828857422s
Epoch:[10/600], loss:910.7067 , time:1.888533115386963s
Epoch:[11/600], loss:882.87103 , time:2.062509775161743s
Epoch:[12/600], loss:851.63904 , time:1.9104552268981934s
Epoch:[13/600], loss:816.519 , time:1.8358547687530518s
Epoch:[14/600], loss:777.25073 , time:1.8439290523529053s
Epoch:[15/600], loss:733.97534 , time:1.868915319442749s
Epoch:[16/600], loss:687.3044 , time:1.8895354270935059s
Epoch:[17/600], loss:638.4035 , time:1.9046196937561035s
Epoch:[18/600], loss:588.7995 , time:1.9187510013580322s
Epoch:[19/600], loss:540.23016 , time:1.9392268657684326s
Epoch:[20/600], loss:494.2876 , time:1.9513444900512695s
Epoch:[21/600], loss:452.18365 , time:1.9313628673553467s
Epoch:[22/600], loss:414.63 , time:1.9439330101013184s
Epoch:[23/600], loss:381.84375 , time:1.9361605644226074s
Epoch:[24/600], loss:353.64685 , time:1.9491877555847168s
Epoch:[25/600], loss:329.6475 , time:1.9155528545379639s
Epoch:[26/600], loss:309.32376 , time:1.9582924842834473s
Epoch:[27/600], loss:292.1488 , time:1.989046573638916s
Epoch:[28/600], loss:277.5958 , time:1.9845423698425293s
Epoch:[29/600], loss:265.23407 , time:1.9845829010009766s
Epoch:[30/600], loss:254.72318 , time:1.9615955352783203s
Epoch:[31/600], loss:245.69928 , time:1.895005226135254s
Epoch:[32/600], loss:237.95857 , time:1.9360558986663818s
Epoch:[33/600], loss:231.26953 , time:1.8412189483642578s
Epoch:[34/600], loss:225.46921 , time:1.943666934967041s
Epoch:[35/600], loss:220.42117 , time:1.910740852355957s
Epoch:[36/600], loss:216.01483 , time:2.3094236850738525s
Epoch:[37/600], loss:212.17096 , time:1.9180114269256592s
Epoch:[38/600], loss:208.79095 , time:2.0196070671081543s
Epoch:[39/600], loss:205.8301 , time:1.9408385753631592s
Epoch:[40/600], loss:203.24126 , time:2.156447410583496s
Epoch:[41/600], loss:200.95872 , time:1.9866917133331299s
Epoch:[42/600], loss:198.97131 , time:1.8703935146331787s
Epoch:[43/600], loss:197.22267 , time:1.9925622940063477s
Epoch:[44/600], loss:195.7137 , time:1.913522481918335s
Epoch:[45/600], loss:194.39456 , time:1.9156956672668457s
Epoch:[46/600], loss:193.25168 , time:1.8471744060516357s
Epoch:[47/600], loss:192.28032 , time:1.8700926303863525s
Epoch:[48/600], loss:191.4564 , time:1.9468822479248047s
Epoch:[49/600], loss:190.76175 , time:1.7169315814971924s
Epoch:[50/600], loss:190.17786 , time:1.8847301006317139s
Epoch:[51/600], loss:189.70422 , time:1.9241282939910889s
Epoch:[52/600], loss:189.32454 , time:1.8982083797454834s
Epoch:[53/600], loss:189.0238 , time:1.968883752822876s
Epoch:[54/600], loss:188.79703 , time:1.9623157978057861s
Epoch:[55/600], loss:188.63405 , time:1.9596054553985596s
Epoch:[56/600], loss:188.51492 , time:1.8357810974121094s
Epoch:[57/600], loss:188.44803 , time:1.9511055946350098s
Epoch:[58/600], loss:188.40463 , time:2.079028844833374s
Epoch:[59/600], loss:188.38773 , time:1.845308542251587s
Epoch:[60/600], loss:188.37622 , time:2.235647201538086s
Epoch:[61/600], loss:188.37569 , time:1.9061458110809326s
Epoch:[62/600], loss:188.37567 , time:1.8661017417907715s
Epoch:[63/600], loss:188.37886 , time:1.8463733196258545s
Epoch:[64/600], loss:188.3789 , time:1.761702299118042s
Epoch:[65/600], loss:188.37886 , time:1.899357557296753s
Epoch:[66/600], loss:188.37889 , time:1.888037919998169s
Epoch:[67/600], loss:188.37946 , time:1.9195020198822021s
Epoch:[68/600], loss:188.3794 , time:1.8520593643188477s
Epoch:[69/600], loss:188.37936 , time:1.9103012084960938s
Epoch:[70/600], loss:188.37943 , time:1.7491989135742188s
Epoch:[71/600], loss:188.37943 , time:1.8370237350463867s
Epoch:[72/600], loss:188.37943 , time:1.948974370956421s
Epoch:[73/600], loss:188.37943 , time:2.2136874198913574s
Epoch:[74/600], loss:188.37943 , time:1.7754967212677002s
Epoch:[75/600], loss:188.37943 , time:1.8914849758148193s
Epoch:[76/600], loss:188.37941 , time:1.9102694988250732s
Epoch:[77/600], loss:188.37946 , time:1.8784689903259277s
Epoch:[78/600], loss:188.37946 , time:1.8668544292449951s
Epoch:[79/600], loss:188.37898 , time:2.279966354370117s
Epoch:[80/600], loss:188.379 , time:2.07421875s
Epoch:[81/600], loss:188.37897 , time:1.8998150825500488s
Epoch:[82/600], loss:188.37901 , time:1.892047643661499s
Epoch:[83/600], loss:188.37912 , time:1.9405834674835205s
Epoch:[84/600], loss:188.37907 , time:1.944732666015625s
Epoch:[85/600], loss:188.37906 , time:1.8872950077056885s
Epoch:[86/600], loss:188.37906 , time:1.9162583351135254s
Epoch:[87/600], loss:188.37906 , time:1.9550495147705078s
Epoch:[88/600], loss:188.37909 , time:1.8799934387207031s
Epoch:[89/600], loss:188.37906 , time:2.018885850906372s
Epoch:[90/600], loss:188.37903 , time:1.8448684215545654s
Epoch:[91/600], loss:188.37907 , time:1.7154390811920166s
Epoch:[92/600], loss:188.37909 , time:1.8363282680511475s
Epoch:[93/600], loss:188.37903 , time:2.138831615447998s
Epoch:[94/600], loss:188.37904 , time:2.2803561687469482s
Epoch:[95/600], loss:188.37907 , time:1.8890752792358398s
Epoch:[96/600], loss:188.37906 , time:1.8987860679626465s
Epoch:[97/600], loss:188.37875 , time:1.9056100845336914s
Epoch:[98/600], loss:188.3788 , time:1.8384995460510254s
Epoch:[99/600], loss:188.3788 , time:1.91251802444458s
Epoch:[100/600], loss:188.37878 , time:1.879709243774414s
Epoch:[101/600], loss:188.37878 , time:2.0873970985412598s
Epoch:[102/600], loss:188.37872 , time:2.0442092418670654s
Epoch:[103/600], loss:188.37875 , time:2.075549364089966s
Epoch:[104/600], loss:188.37875 , time:1.9359126091003418s
Epoch:[105/600], loss:188.37874 , time:1.9307827949523926s
Epoch:[106/600], loss:188.37857 , time:1.9777381420135498s
Epoch:[107/600], loss:188.37854 , time:1.9581537246704102s
Epoch:[108/600], loss:188.3786 , time:1.891711950302124s
Epoch:[109/600], loss:188.37854 , time:1.9627478122711182s
Epoch:[110/600], loss:188.37857 , time:2.06095027923584s
Epoch:[111/600], loss:188.37851 , time:1.9639966487884521s
Epoch:[112/600], loss:188.37859 , time:1.9033927917480469s
Epoch:[113/600], loss:188.37857 , time:1.8789749145507812s
Epoch:[114/600], loss:188.37856 , time:1.9860529899597168s
Epoch:[115/600], loss:188.37857 , time:1.946465253829956s
Epoch:[116/600], loss:188.37859 , time:1.885061502456665s
Epoch:[117/600], loss:188.37854 , time:1.83247709274292s
Epoch:[118/600], loss:188.37856 , time:1.8742828369140625s
Epoch:[119/600], loss:188.37851 , time:1.8780326843261719s
Epoch:[120/600], loss:188.37856 , time:1.8810043334960938s
Epoch:[121/600], loss:188.37854 , time:1.914259910583496s
Epoch:[122/600], loss:188.37857 , time:1.9242641925811768s
Epoch:[123/600], loss:188.37852 , time:1.9370036125183105s
Epoch:[124/600], loss:188.37857 , time:1.9210433959960938s
Epoch:[125/600], loss:188.37857 , time:1.8470649719238281s
Epoch:[126/600], loss:188.37859 , time:1.962592363357544s
Epoch:[127/600], loss:188.37857 , time:1.8703532218933105s
Epoch:[128/600], loss:188.37857 , time:1.8404300212860107s
Epoch:[129/600], loss:188.37852 , time:1.9200024604797363s
Epoch:[130/600], loss:188.37854 , time:2.2880609035491943s
Epoch:[131/600], loss:188.37857 , time:1.923091173171997s
Epoch:[132/600], loss:188.37857 , time:1.9541983604431152s
Epoch:[133/600], loss:188.37856 , time:1.870420217514038s
Epoch:[134/600], loss:188.37859 , time:1.9514918327331543s
Epoch:[135/600], loss:188.3786 , time:1.9435644149780273s
Epoch:[136/600], loss:188.3786 , time:1.8722777366638184s
Epoch:[137/600], loss:188.37854 , time:1.9356486797332764s
Epoch:[138/600], loss:188.37857 , time:1.915917158126831s
Epoch:[139/600], loss:188.37856 , time:1.9427490234375s
Epoch:[140/600], loss:188.37856 , time:1.9155688285827637s
Epoch:[141/600], loss:188.3786 , time:2.002415418624878s
Epoch:[142/600], loss:188.37854 , time:1.9361698627471924s
Epoch:[143/600], loss:188.37856 , time:1.8679277896881104s
Epoch:[144/600], loss:188.37854 , time:1.911771535873413s
Epoch:[145/600], loss:188.37859 , time:1.8430299758911133s
Epoch:[146/600], loss:188.37859 , time:1.9204416275024414s
Epoch:[147/600], loss:188.37856 , time:1.9070813655853271s
Epoch:[148/600], loss:188.37854 , time:2.4021832942962646s
Epoch:[149/600], loss:188.3786 , time:2.17209529876709s
Epoch:[150/600], loss:188.37857 , time:1.9139797687530518s
Epoch:[151/600], loss:188.37857 , time:1.914320468902588s
Epoch:[152/600], loss:188.37856 , time:1.9024651050567627s
Epoch:[153/600], loss:188.37854 , time:1.8947803974151611s
Epoch:[154/600], loss:188.37857 , time:1.9186427593231201s
Epoch:[155/600], loss:188.37859 , time:1.9227428436279297s
Epoch:[156/600], loss:188.37854 , time:1.8949134349822998s
Epoch:[157/600], loss:188.37859 , time:1.9331448078155518s
Epoch:[158/600], loss:188.37856 , time:1.8838796615600586s
Epoch:[159/600], loss:188.3786 , time:1.829977035522461s
Epoch:[160/600], loss:188.37859 , time:2.200533866882324s
Epoch:[161/600], loss:188.37856 , time:1.9860930442810059s
Epoch:[162/600], loss:188.37857 , time:1.8985581398010254s
Epoch:[163/600], loss:188.37854 , time:1.9004161357879639s
Epoch:[164/600], loss:188.37857 , time:1.8910491466522217s
Epoch:[165/600], loss:188.37852 , time:2.155933141708374s
Epoch:[166/600], loss:188.37854 , time:1.9427380561828613s
Epoch:[167/600], loss:188.37854 , time:1.8550941944122314s
Epoch:[168/600], loss:188.37854 , time:1.8890490531921387s
Epoch:[169/600], loss:188.37856 , time:1.8915667533874512s
Epoch:[170/600], loss:188.37852 , time:1.9224789142608643s
Epoch:[171/600], loss:188.37852 , time:1.8886711597442627s
Epoch:[172/600], loss:188.37857 , time:1.9616458415985107s
Epoch:[173/600], loss:188.37856 , time:1.8762037754058838s
Epoch:[174/600], loss:188.37854 , time:1.877793788909912s
Epoch:[175/600], loss:188.37854 , time:1.881915807723999s
Epoch:[176/600], loss:188.37854 , time:1.8977577686309814s
Epoch:[177/600], loss:188.37856 , time:1.8842477798461914s
Epoch:[178/600], loss:188.37854 , time:1.9445745944976807s
Epoch:[179/600], loss:188.37854 , time:1.8519113063812256s
Epoch:[180/600], loss:188.37857 , time:2.3383569717407227s
Epoch:[181/600], loss:188.37856 , time:1.9188573360443115s
Epoch:[182/600], loss:188.37857 , time:1.8220798969268799s
Epoch:[183/600], loss:188.37857 , time:1.9341838359832764s
Epoch:[184/600], loss:188.37857 , time:1.9151420593261719s
Epoch:[185/600], loss:188.37857 , time:1.932147741317749s
Epoch:[186/600], loss:188.37856 , time:1.8949909210205078s
Epoch:[187/600], loss:188.37859 , time:1.8938539028167725s
Epoch:[188/600], loss:188.37854 , time:1.8974840641021729s
Epoch:[189/600], loss:188.37857 , time:1.9339358806610107s
Epoch:[190/600], loss:188.37857 , time:1.9310569763183594s
Epoch:[191/600], loss:188.37857 , time:1.8806233406066895s
Epoch:[192/600], loss:188.37857 , time:1.9312958717346191s
Epoch:[193/600], loss:188.37856 , time:1.8633415699005127s
Epoch:[194/600], loss:188.37856 , time:1.809281826019287s
Epoch:[195/600], loss:188.37857 , time:1.907397747039795s
Epoch:[196/600], loss:188.37857 , time:1.9417457580566406s
Epoch:[197/600], loss:188.37854 , time:2.0560526847839355s
Epoch:[198/600], loss:188.37857 , time:1.9369611740112305s
Epoch:[199/600], loss:188.37857 , time:1.824328899383545s
Epoch:[200/600], loss:188.37854 , time:1.8158912658691406s
Epoch:[201/600], loss:188.3786 , time:1.8839547634124756s
Epoch:[202/600], loss:188.37856 , time:1.8570919036865234s
Epoch:[203/600], loss:188.37857 , time:1.9241950511932373s
Epoch:[204/600], loss:188.37857 , time:2.377271890640259s
Epoch:[205/600], loss:188.37857 , time:1.9568099975585938s
Epoch:[206/600], loss:188.37857 , time:1.936509132385254s
Epoch:[207/600], loss:188.37854 , time:1.9863758087158203s
Epoch:[208/600], loss:188.37857 , time:1.9057445526123047s
Epoch:[209/600], loss:188.37857 , time:1.9109282493591309s
Epoch:[210/600], loss:188.37857 , time:1.938847541809082s
Epoch:[211/600], loss:188.3786 , time:1.9582295417785645s
Epoch:[212/600], loss:188.37859 , time:1.8419034481048584s
Epoch:[213/600], loss:188.37857 , time:1.8981304168701172s
Epoch:[214/600], loss:188.37859 , time:1.8817479610443115s
Epoch:[215/600], loss:188.37857 , time:2.186211585998535s
Epoch:[216/600], loss:188.37859 , time:1.9858474731445312s
Epoch:[217/600], loss:188.3786 , time:1.970782995223999s
Epoch:[218/600], loss:188.37857 , time:1.9347617626190186s
Epoch:[219/600], loss:188.37857 , time:1.9285027980804443s
Epoch:[220/600], loss:188.37856 , time:2.0001211166381836s
Epoch:[221/600], loss:188.37857 , time:1.8413310050964355s
Epoch:[222/600], loss:188.37859 , time:1.893350601196289s
Epoch:[223/600], loss:188.37856 , time:1.8966138362884521s
Epoch:[224/600], loss:188.37859 , time:2.049260139465332s
Epoch:[225/600], loss:188.37859 , time:2.132143259048462s
Epoch:[226/600], loss:188.37859 , time:2.063427209854126s
Epoch:[227/600], loss:188.37856 , time:2.120331287384033s
Epoch:[228/600], loss:188.37854 , time:1.863887071609497s
Epoch:[229/600], loss:188.37854 , time:1.8822925090789795s
Epoch:[230/600], loss:188.37857 , time:1.8654215335845947s
Epoch:[231/600], loss:188.37852 , time:1.859323263168335s
Epoch:[232/600], loss:188.37854 , time:1.9664554595947266s
Epoch:[233/600], loss:188.37854 , time:1.9281988143920898s
Epoch:[234/600], loss:188.37856 , time:1.9267387390136719s
Epoch:[235/600], loss:188.37857 , time:1.847092628479004s
Epoch:[236/600], loss:188.37854 , time:1.8874273300170898s
Epoch:[237/600], loss:188.37854 , time:1.9469246864318848s
Epoch:[238/600], loss:188.37857 , time:1.8628604412078857s
Epoch:[239/600], loss:188.3786 , time:1.9499750137329102s
Epoch:[240/600], loss:188.3786 , time:1.992382526397705s
Epoch:[241/600], loss:188.37854 , time:1.9203784465789795s
Epoch:[242/600], loss:188.3786 , time:2.2645621299743652s
Epoch:[243/600], loss:188.37857 , time:1.9545602798461914s
Epoch:[244/600], loss:188.37857 , time:1.938964605331421s
Epoch:[245/600], loss:188.3786 , time:1.8735957145690918s
Epoch:[246/600], loss:188.37854 , time:1.8787848949432373s
Epoch:[247/600], loss:188.37857 , time:2.0466089248657227s
Epoch:[248/600], loss:188.37859 , time:1.9010069370269775s
Epoch:[249/600], loss:188.37857 , time:1.8816943168640137s
Epoch:[250/600], loss:188.37859 , time:1.8506755828857422s
Epoch:[251/600], loss:188.37852 , time:1.9371037483215332s
Epoch:[252/600], loss:188.37859 , time:1.9160573482513428s
Epoch:[253/600], loss:188.37859 , time:1.89524507522583s
Epoch:[254/600], loss:188.37859 , time:1.9284965991973877s
Epoch:[255/600], loss:188.37857 , time:1.8957431316375732s
Epoch:[256/600], loss:188.37856 , time:1.8915939331054688s
Epoch:[257/600], loss:188.37857 , time:1.9113235473632812s
Epoch:[258/600], loss:188.37857 , time:1.8604331016540527s
Epoch:[259/600], loss:188.37852 , time:1.8543028831481934s
Epoch:[260/600], loss:188.3786 , time:1.8935306072235107s
Epoch:[261/600], loss:188.3786 , time:2.379755735397339s
Epoch:[262/600], loss:188.3786 , time:1.9306089878082275s
Epoch:[263/600], loss:188.37854 , time:1.914419174194336s
Epoch:[264/600], loss:188.3786 , time:1.88968825340271s
Epoch:[265/600], loss:188.37857 , time:1.884547233581543s
Epoch:[266/600], loss:188.37859 , time:1.9168856143951416s
Epoch:[267/600], loss:188.37854 , time:1.9038572311401367s
Epoch:[268/600], loss:188.37857 , time:1.9013309478759766s
Epoch:[269/600], loss:188.37856 , time:1.9306435585021973s
Epoch:[270/600], loss:188.37859 , time:1.8750956058502197s
Epoch:[271/600], loss:188.37856 , time:1.8548827171325684s
Epoch:[272/600], loss:188.3786 , time:2.0269076824188232s
Epoch:[273/600], loss:188.37857 , time:1.9472556114196777s
Epoch:[274/600], loss:188.37857 , time:1.861856460571289s
Epoch:[275/600], loss:188.37854 , time:1.929530382156372s
Epoch:[276/600], loss:188.37854 , time:1.9220004081726074s
Epoch:[277/600], loss:188.37851 , time:1.8920118808746338s
Epoch:[278/600], loss:188.37854 , time:2.2901108264923096s
Epoch:[279/600], loss:188.37854 , time:1.943664789199829s
Epoch:[280/600], loss:188.37859 , time:1.8920924663543701s
Epoch:[281/600], loss:188.37857 , time:1.9362118244171143s
Epoch:[282/600], loss:188.37857 , time:2.412808418273926s
Epoch:[283/600], loss:188.37856 , time:1.8900232315063477s
Epoch:[284/600], loss:188.37856 , time:1.8428146839141846s
Epoch:[285/600], loss:188.3786 , time:1.8389625549316406s
Epoch:[286/600], loss:188.37856 , time:2.0901787281036377s
Epoch:[287/600], loss:188.37854 , time:1.8897221088409424s
Epoch:[288/600], loss:188.37856 , time:1.9260423183441162s
Epoch:[289/600], loss:188.37856 , time:1.9461030960083008s
Epoch:[290/600], loss:188.37857 , time:1.969346523284912s
。。。。
Epoch:[598/600], loss:188.37852 , time:1.9605398178100586s
Epoch:[599/600], loss:188.37854 , time:1.8862216472625732s
Epoch:[600/600], loss:188.37857 , time:1.9470226764678955s
=================== Training Success =====================
评估
自定义eval_net()类对训练好的模型进行评估,调用了上述定义的SsdInferWithDecoder类返回预测的坐标及标签,然后分别计算了在不同的IoU阈值、area和maxDets设置下的Average Precision(AP)和Average Recall(AR)。使用COCOMetrics类计算mAP。模型在测试集上的评估指标如下。
精确率(AP)和召回率(AR)的解释
-
TP:IoU>设定的阈值的检测框数量(同一Ground Truth只计算一次)。
-
FP:IoU<=设定的阈值的检测框,或者是检测到同一个GT的多余检测框的数量。
-
FN:没有检测到的GT的数量。
精确率(AP)和召回率(AR)的公式
-
精确率(Average Precision,AP):
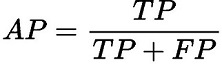
精确率是将正样本预测正确的结果与正样本预测的结果和预测错误的结果的和的比值,主要反映出预测结果错误率。
-
召回率(Average Recall,AR):
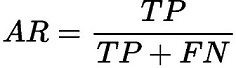
召回率是正样本预测正确的结果与正样本预测正确的结果和正样本预测错误的和的比值,主要反映出来的是预测结果中的漏检率。
关于以下代码运行结果的输出指标
-
第一个值即为mAP(mean Average Precision), 即各类别AP的平均值。
-
第二个值是iou取0.5的mAP值,是voc的评判标准。
-
第三个值是评判较为严格的mAP值,可以反应算法框的位置精准程度;中间几个数为物体大小的mAP值。
对于AR看一下maxDets=10/100的mAR值,反应检出率,如果两者接近,说明对于这个数据集来说,不用检测出100个框,可以提高性能。
mindrecord_file = "./datasets/MindRecord_COCO/ssd_eval.mindrecord0"
def ssd_eval(dataset_path, ckpt_path, anno_json):
"""SSD evaluation."""
batch_size = 1
ds = create_ssd_dataset(dataset_path, batch_size=batch_size,
is_training=False, use_multiprocessing=False)
network = SSD300Vgg16()
print("Load Checkpoint!")
net = SsdInferWithDecoder(network, Tensor(default_boxes), ckpt_path)
net.set_train(False)
total = ds.get_dataset_size() * batch_size
print("\n========================================\n")
print("total images num: ", total)
eval_param_dict = {"net": net, "dataset": ds, "anno_json": anno_json}
mAP = apply_eval(eval_param_dict)
print("\n========================================\n")
print(f"mAP: {mAP}")
def eval_net():
print("Start Eval!")
ssd_eval(mindrecord_file, "./ssd-60_9.ckpt", anno_json)
eval_net()
Start Eval!
Load Checkpoint!
========================================
total images num: 9
loading annotations into memory...
Done (t=0.01s)
creating index...
index created!
Loading and preparing results...
DONE (t=1.36s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=1.36s).
Accumulating evaluation results...
DONE (t=0.37s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.008
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.016
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.001
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.006
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.027
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.021
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.042
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.070
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.058
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.304
========================================
mAP: 0.007881190699077868
引用
[1] Liu W, Anguelov D, Erhan D, et al. Ssd: Single shot multibox detector[C]//European conference on computer vision. Springer, Cham, 2016: 21-37.
import time
L = time.localtime(time.time()+8*3600)
print(time.strftime("%Y-%m-%d %H:%M:%S",L),"modWizard")
2024-07-09 15:13:16 modWizard
心得
1、根据论文,Epoch大约迭代了5000多次,而实际上测试超过80次以上LOSS=188.37854 几乎不变,估计是对图像的预处理还是有所欠缺。
可能需要添加自动变化的图如拼接、旋转,Crop等,但需要相应的重新计算GroundTruth的框位置。
另外有可能是学习率问题。学习率设置过高或过低都可能导致模型训练不稳定或陷入局部最优。















 817
817











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









