







文章目录
一、KMeans算法的步骤
- 对于给定的一组数据,随机初始化K个聚类中心(簇中心)
- 计算每个数据到簇中心的距离,并把该数据归为离它最近的簇。
- 根据得到的簇,重新计算簇中心。
- 对 2、3 进行迭代直至簇中心不再改变或者小于指定阈值。
二、KMeans实现过程中需要注意的地方
1.初始聚类中心的确定
在上面的步骤中,簇中心的选取尤为重要,它对最终的聚类影响较大。初始化簇中心常用的选取方法是从数据集中随机选取K个数据作为簇中心。
但是这种随机初始化簇中心导致了KMeans的缺点:聚类的结果不够稳定。
可以使用KMeans++来改进初始簇中心的选择。
2. 常用的距离度量
常用的距离度量可以使用欧氏距离:
点x到点y的距离

3. 聚类效果的衡量 SSE
在KMeans中,可以使用误差平方和( SSE )作为目标函数来衡量聚类效果的好坏。
下面是SSE的计算方法:
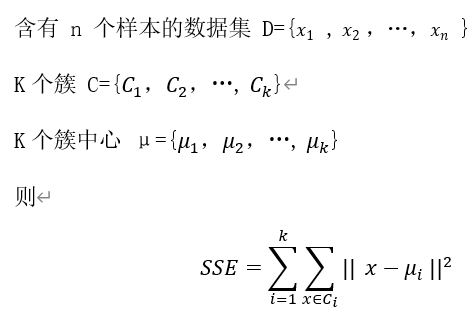
直观上理解,SSE越小,表示数据越接近它们的簇中心,聚类效果也就越好。
4.迭代结束条件
迭代结束的条件可以自己设置最大的迭代次数,或者让目标函数收敛(根据上面的SSE公式可以知道,目标函数收敛也就是簇中心几乎不再变化)。
5.空簇的处理
在随机初始化聚类中心的过程或迭代过程中可能会出现有的簇没有被分配到样本,这样的簇叫做空簇。在代码实现的过程中,出现空簇后再进行下一次簇中心迭代时会出现除零的问题。
下面举个例子

故意设置了簇中心位置来碰空簇的瓷,不然碰到空簇的概率属实有点低。。
图中左边四个菱形为初始化的4个簇中心。
根据步骤二来确定样本点所属的簇,从图上可以直观看出,绿色和红色的簇中心到样本点的距离要比蓝色和紫色的要大,因此就会导致没有样本点被分到绿色和红色的簇中。
在迭代求簇中点均值时就会报“除零”的错。

解决方法:可以选取离当前已知簇中心最远的点作为空簇的簇中心。因为
这样消除对当前SSE影响最大的点对SSE的影响(该点到该空簇簇中心的距离为0)
如果有多个空簇,反复进行上述过程即可。
解决空簇问题后的最终聚类结果:

三、结果展示
1. 样本的聚类

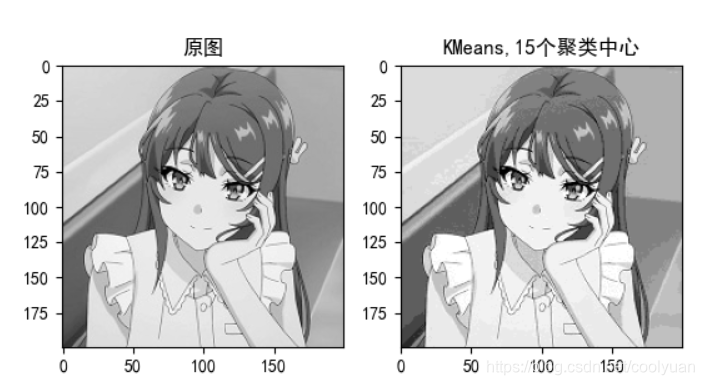
2. 图片压缩
用聚类进行图片压缩其实就是将图片的每个像素的像素值通过聚类来进行划分,然后将原有的像素的像素值用其聚类中心的像素值来代替。用这种方法来减少色彩种类并保持图片的大致轮廓,从而实现图片的压缩。
对灰度图:

对彩图:


你设置的簇中心数越多,像素或灰度就越丰富,也就越能接近原图,但是这反而会让图片占用空间变大,因此在图片压缩时要对K值得有一个合理的考量。
四、源码链接
五、KMeans++的实现
KMeans++相较于KMeans就在于改良了初始簇中心的选择方式,
其思想是:选择相距较远的样本点作为簇中心而非随机选取样本点
以此来加强聚类的稳定性。
算法步骤
- 从样本集中随机选取一个样本作为第一个簇中心
- 然后计算所有点到离它最近的簇中心的距离D(x)
- 再选择一个新的样本作为新的簇中心,选择的原则是:D(x)较大的点, 被选取作为簇中心的概率较大(不直接取D(x)最大的点作为簇中心主要是为了防止噪声的干扰)
- 重复2、3直至K个初始簇中心被选出
- 执行KMeans算法的后续步骤
代码的重点实现主要是如何选取D(x)较大的样本。
一种实现方法是计算所有样本的D(x)总和(记作sum(D(x))),然后随机选取0 到 sum(D(x))之间的一个数(记作 randDis),再计算RandDis−=D(x),直至RandDis<=0,选取D(x)对应的样本点作为簇中心。
上面的方法可以这么理解:有一条按D(x)划分区域的长度为sum(D(x))的带子,现在在带子上随机打一个点,点打在D(x)较大的区域的概率也就较大。而D(x)较大的区域也就是我们要找的新的簇中心。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









