




 该研究提出了一种深度残差池化网络,用于纹理识别。通过保留特征图的空间信息并结合残差编码,实现了一个端到端的学习框架。这种方法克服了传统方法中的限制,提高了学习效率,并在多个纹理识别数据集上表现出优越性能。
该研究提出了一种深度残差池化网络,用于纹理识别。通过保留特征图的空间信息并结合残差编码,实现了一个端到端的学习框架。这种方法克服了传统方法中的限制,提高了学习效率,并在多个纹理识别数据集上表现出优越性能。
Title
Deep residual pooling network for texture recognition
Year/ Authors/ Journal
2021
/Mao, Shangbo and Rajan, Deepu and Chia, Liang Tien
/ Pattern Recognition
citation
@article{
mao2021deep,
title={
Deep residual pooling network for texture recognition},
author={
Mao, Shangbo and Rajan, Deepu and Chia, Liang Tien},
journal={
Pattern Recognition},
volume={
112},
pages={
107817},
year={
2021},
publisher={
Elsevier}
}
Summary
-
The balance between the orderless features and the spatial information for effective texture recognition.
-
Experiments show that retaining the spatial information before aggregation is helpful in feature learning for texture recognition.
Interesting Point(s)
-
It would be interesting to explore if the best feature maps could be automatically identified as suitable candidates for combining.
-
In our method, the multi-size training can influence only the features learned in the convolutional transfer module, which will not lead to a major influence in the final performance. We plan to address this in the future.
-
The properties of the Deep-TEN for integrating Encoding Layer with and end-to-end CNN architecture.
-
spatial information + orderless features.
-
end to end training.
-
same dimensions.
-
Research Objective(s)

Fig. 1. Overall framework of deep residual pooling network. When the backbone network is Resnet-50 and the input image size is 224 ×224 ×3 , the dimension of the feature map extracted from $ f_{cnn} $ is 7 ×7 ×2048 , as the orange cube in the figure shows. (For interpretation of the references to color in this figure legend, the reader is referred to the web version of this article.)
Current deep learning-based texture recognition methods extract spatial orderless features from pretrained deep learning models that are trained on large-scale image datasets. These methods either pro- duce high dimensional features or have multiple steps like dictionary learning, feature encoding and dimension reduction. In this paper, we propose a novel end-to-end learning framework that not only overcomes these limitations, but also demonstrates faster learning.
Contributions
The contribution of our work is three fold:
- We propose a learnable residual pooling layer comprising of a residual encoding module and an aggregation module. We take advantage of the feature learning ability of the convolutional layer and integrate the idea of residual encoding to pro- pose a learnable pooling layer. Besides, the proposed layer produces the residual codes retaining spatial information and aggregates them to a feature with a lower dimension compared with the state-of-the-art methods. Experiments show that retaining the spatial information before aggregation is helpful in feature learning for texture recognition.
- We propose a novel end-to-end learning framework that integrates the residual pooling layer into a pretrained CNN model for efficient feature transfer for texture recognition. We show the overview of the proposed residual pooling framework in Fig. 1 .
- We compare our feature dimensions as well as the performance of the proposed pooling layer with other residual encoding schemes to illustrate state-of-the-art performance on bench- mark texture datasets and also on a visual inspection dataset from industry. We also test our method on a scene recognition dataset.
Background / Problem Statement
- Following its success, several pretrained CNN models complemented by specific modules to improve accuracy have been proposed [5,13,25] that achieve better performance on benchmark datasets such as Flickr Material Dataset (FMD) [23] and Describable Texture Dataset (DTD) [3] . However, since the methods proposed in [4,25] contain multiple steps such as feature extraction, orderless encoding and dimension reduction, the advantages offered by end-to-end learning are not fully utilized. Moreover, the features extracted by all of these methods [4,5,25] have high dimensions resulting in operation on large matrices.
- There is a need to balance orderless feature and ordered spatial information for effective texture recognition [33] . From feature visualization experiments, we see that pretrained CNN features are able to differentiate textures only to a certain ex- tent. Hence, we propose to use the pretrained CNN features as the compact dictionary. Since the pretrained CNN features mainly focus on the extraction of spatial sensitive information, we implement the hard assignment based on the spatial locations during the calculation of the residuals. Then, in order to get an orderless feature, we propose an aggregation module to remove the spatial sensitive information.
- The challenge is to make the loss function differentiable with respect to the inputs and layer parameters.
All in one word: for better transferring the deep-learning method into texture recognition. Since model in this field always with pretrained in large dataset (such as ImageNet).
Method(s)
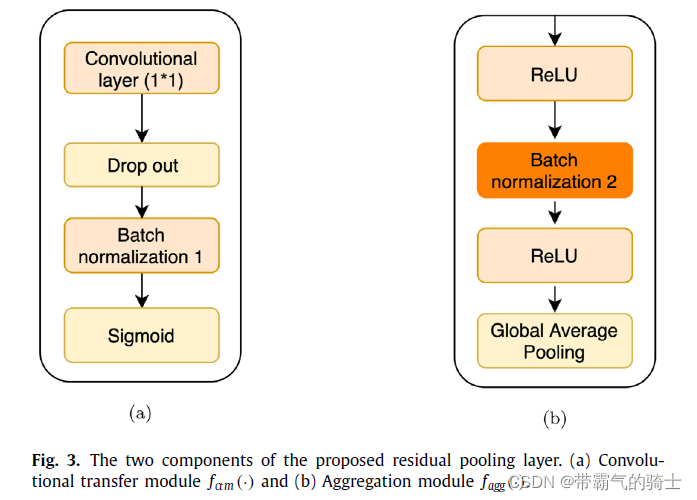
Unlike Deep TEN [34] , which removed the spatial sensitive information at the beginning itself, we retain the spatial sensitive information until the aggregation module to achieve the balance of orderless features and ordered spatial information.
Our proposed residual encoding module is motivated by Deep TEN [34] , but there are two main differences. The fir
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1149
1149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









