







安装Spark
Spark技术栈
Spark Core 核心组件,分布式计算引擎
Spark Sql 高性能的基于Hadoop的SQL解决方案
Spark Streaming可以实现高吞吐量、具备容错机制的准实时流处理系统
Spark GraphX 分布式图处理框架
Spark MLib 构建在Spark上的分布式机器学习库
安装
安装spark需要安装scala
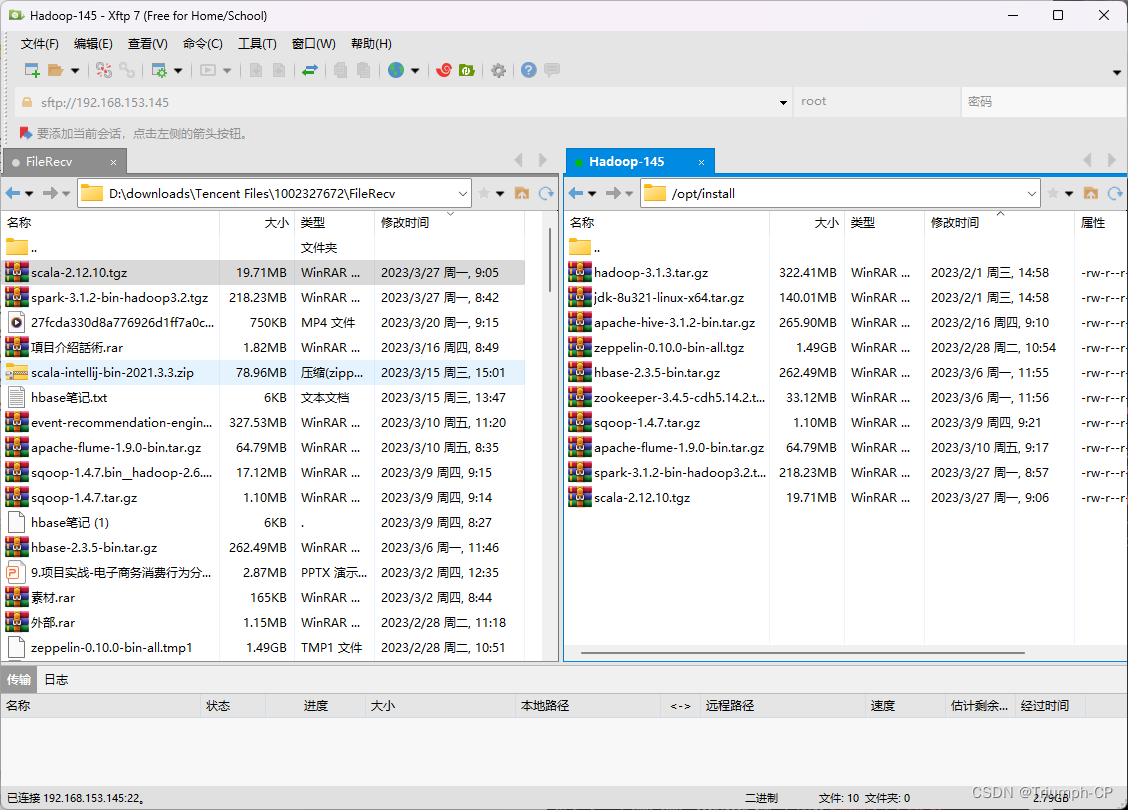
scala
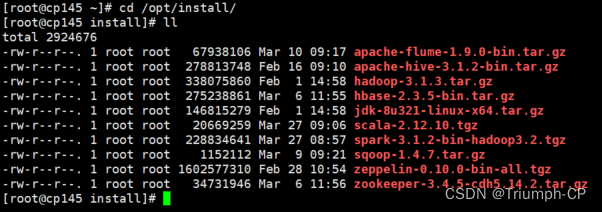
解压
[root@cp145 install]# tar -zxf scala-2.12.10.tgz -C ../soft/
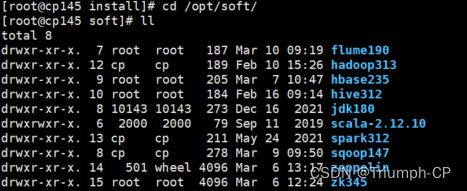
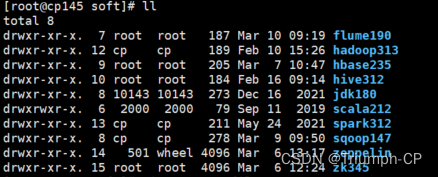
改名
[root@cp145 soft]# mv scala-2.12.10/ scala212
配置环境变量
vim /etc/profile

配完source一下,使用scala即可进入
spark
解压
[root@cp145 install]# tar -zxf spark-3.1.2-bin-hadoop3.2.tgz -C ../soft/

改名
[root@cp145 soft]# mv spark-3.1.2-bin-hadoop3.2/ spark312
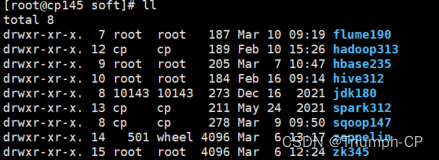
修改环境变量
vim /etc/profile

修改conf文件

spark-env.sh
[root@cp145 conf]# cp spark-env.sh.template spark-env.sh
[root@cp145 conf]# vim ./spark-env.sh
export SCALA_HOME=/opt/soft/scala212
export JAVA_HOME=/opt/soft/jdk180
export SPARK_HOME=/opt/soft/spark312
export HADOOP_INSTALL=/opt/soft/hadoop313
export HADOOP_CONF_DIR=$HADOOP_INSTALL/etc/hadoop
export SPARK_MASTER_IP=cp145
export SPARK_DRIVER_MEMORY=2G
export SPARK_LOCAL_DIRS=/opt/soft/spark312
export SPARK_EXECUTOR_MEMORY=2G
works配置集群用得到
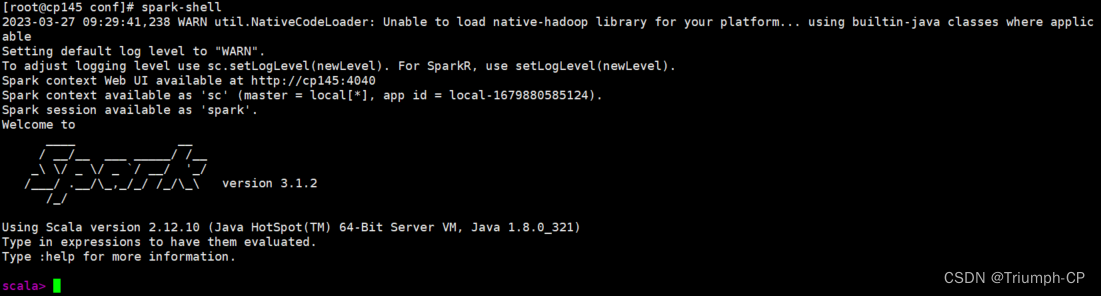
配完source一下,使用spark-shell即可进入
通过http://cp145:4040可以看到网页
简单实现wordcount
words.txt
hello world
hello java
hadoop java java gogo gogo
读取本地文件
sc.textFile("file:///opt/stufile/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect.foreach(println)

读取hdfs文件
sc.textFile("hdfs://cp145:9000/tmp/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect.foreach(println)
















 1182
1182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









