







 本文介绍了LLVM编译器基础设施,包括其起源、模块化设计、LLVMIR的作用,以及关键工具如opt、代码生成器和LLVMIR的使用。重点讲解了模块化设计在LLVM优化器中的应用和LLVMIR的通用性和结构。
本文介绍了LLVM编译器基础设施,包括其起源、模块化设计、LLVMIR的作用,以及关键工具如opt、代码生成器和LLVMIR的使用。重点讲解了模块化设计在LLVM优化器中的应用和LLVMIR的通用性和结构。
LLVM编译器基础设施项目始于2000年伊利诺伊大学,最初是一个研究项目,旨在为各种静态和动态编程语言提供基于SSA(静态单赋值)的现代编译技术。如今,它已发展成为一个包含许多子项目的综合项目,提供一系列具有明确定义接口的可重用库。
LLVM是用C++实现的,其核心是它提供的LLVM核心库。这些库为我们提供了opt工具,即目标独立的优化器,以及对各种目标架构的代码生成支持。还有其他一些工具使用核心库,但本书的主要焦点将与上述三个相关。这些工具是围绕LLVM中间表示(LLVM IR)构建的,几乎可以映射所有高级语言。因此,基本上,要使用LLVM的优化器和代码生成技术为某种编程语言编写的代码,我们所需要做的就是为该语言编写一个前端,将高级语言转换为LLVM IR。已经有许多针对C、C++、Go、Python等语言的前端。本章将涵盖以下主题:
- 模块化设计和库的集合
- 熟悉LLVM IR
- LLVM工具及其在命令行的使用
模块化设计和库的集合
LLVM最重要的特点是它被设计成一系列的库。让我们通过LLVM优化器opt的例子来理解这一点。优化器可以运行许多不同的优化过程。每个过程都写成了一个从LLVM的Pass类派生的C++类。每个写好的过程都可以编译成一个**.o文件,然后被存档成一个.a**库。这个库将包含opt工具的所有过程。库中的所有过程都是松散耦合的,即它们明确地指明了对其他过程的依赖。
当优化器运行时,LLVM的PassManager使用明确提及的依赖信息以最优方式运行过程。基于库的设计允许实现者选择执行过程的顺序,也可以根据需求选择要执行的过程。只有需要的过程才会链接到最终应用程序,而不是整个优化器。
下图展示了如何将每个过程链接到特定库中的特定对象文件。在下图中,PassA引用LLVMPasses.a中的PassA.o,而自定义过程则引用另一个库MyPasses.a中的MyPass.o对象文件。
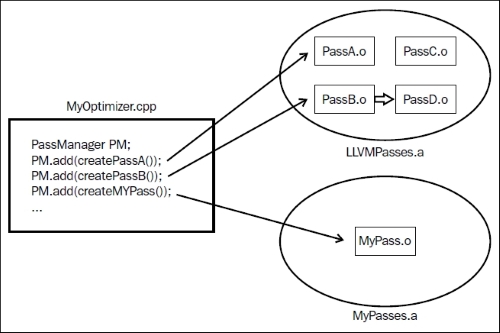
代码生成器也像优化器一样,利用了这种模块化设计,将代码生成分解为若干个独立的过程,包括指令选择、寄存器分配、调度、代码布局优化和汇编代码生成。
在上述的每个阶段中,几乎每个目标都有一些共通之处,例如为虚拟寄存器分配可用的物理寄存器的算法,尽管不同目标的寄存器集合各不相同。因此,编译器的编写者可以修改上述的每个过程,并创建定制的针对特定目标的过程。使用 tablegen 工具和针对特定架构的表描述 .td 文件,可以帮助实现这一点。我们将在本书后面讨论这是如何实现的。
由此产生的另一个能力是,能够轻松地将一个错误定位到优化器中的特定过程。一个名为 Bugpoint 的工具利用了这一能力,可以自动缩减测试用例,并定位出导致错误的过程。
了解LLVM IR
LLVM的中间表示(IR)是LLVM项目的核心。通常,每个编译器都会生成一个中间表示,然后在其上运行大部分优化。对于面向多源语言和不同架构的编译器,在选择IR时的一个重要决策是,它既不应是非常高级的,即与源语言紧密相连,也不应是非常低级的,即接近于目标机器指令。LLVM IR旨在成为一种通用的IR,通过处于足够低的级别,以便高级思想可以清晰地映射到它上。理想情况下,LLVM IR应该是与目标无关的,但由于某些编程语言本身的固有目标依赖性,它并非如此。例如,在Linux系统中使用标准C头文件时,头文件本身是目标依赖的,它可能为实体指定特定类型,以便与特定目标架构的系统调用匹配。
大多数LLVM工具都围绕这个中间表示旋转。不同语言的前端从高级源语言生成这个IR。LLVM的优化器工具在这个生成的IR上运行,以优化代码,提高性能,代码生成器使用这个IR进行针对特定目标的代码生成。这个IR有三种等效形式:
- 内存中的编译器IR
- 磁盘上的位码表示
- 人类可读形式(LLVM汇编)
现在我们来看一个例子,了解LLVM IR是什么样子的。我们将采用一小段C代码,并使用clang将其转换为LLVM IR,尝试通过将其映射回源语言来理解LLVM IR的细节。
$ cat add.c
int globvar = 12;
int add(int a) {
return globvar + a;
}
使用以下选项的clang前端将其转换为LLVM IR:
$ clang -emit-llvm -c -S add.c
$ cat add.ll
; ModuleID = 'add.c'
target datalayout = "e-m:e-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-unknown-linux-gnu"
@globvar = global i32 12, align 4
; Function Attrs: nounwind uwtable
define i32 @add(i32 %a) #0 {
%1 = alloca i32, align 4
store i32 %a, i32* %1, align 4
%2 = load i32, i32* @globvar, align 4
%3 = load i32, i32* %1, align 4
%4 = add nsw i32 %2, %3
ret i32 %4
}
attributes #0 = { nounwind uwtable "less-precise-fpmad"="false" "no-frame-pointer-elim"="true" "no-frame-pointer-elim-non-leaf" "no-infs-fp-math"="false" "no-nans-fp-math"="false" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "unsafe-fp-math"="false" "use-soft-float"="false" }
!llvm.ident = !{!0}
CopyExplain
现在,让我们看一下生成的IR,并了解它的全部内容。您可以看到第一行给出了ModuleID,它定义了add.c文件的LLVM模块。一个LLVM模块是一个顶级数据结构,包含了输入LLVM文件的全部内容。它由函数、全局变量、外部函数原型和符号表条目组成。
接下来的几行显示了目标数据布局和目标三元组,从中我们可以知道目标是运行在Linux上的x86_64处理器。datalayout字符串告诉我们机器的字节序(‘e’表示小端序),以及名称改编方式(m : e表示elf类型)。每个规格由’-'分隔,每个后续规格提供关于该类型及其大小的信息。例如,i64:64表示64位整数是64位的。
然后,我们有一个全局变量globvar。在LLVM IR中,所有全局变量以’@‘开头,所有局部变量以’%'开头。变量使用这些符号作为前缀的两个主要原因是:第一个原因是,编译器不必担心与保留字发生命名冲突;第二个原因是,编译器可以快速地为变量生成一个临时名称,而不必担心与符号表发生冲突。这第二个属性对于在静态单赋值(SSA)形式中表示IR很有用,在SSA形式中,每个变量只被赋值一次,而且每个变量的使用都在其定义之前。因此,在将常规程序转换为SSA形式时,我们会为变量的每次重新定义创建一个新的临时名称,并将早期定义的范围限制在此重新定义之前。
LLVM将全局变量视为指针,因此需要使用load指令显式地解引用全局变量。同样,要存储一个值,需要一个显式的store指令。
局部变量有两类:
-
寄存器分配的局部变量:这些是临时的和分配的虚拟寄存器。在代码生成阶段,虚拟寄存器被分配给物理寄存器,我们将在本书的后面章节中看到。它们是通过为变量使用新符号创建的,例如:
%1 = some value -
栈分配的局部变量:这些是通过使用
alloca指令,在当前执行函数的栈帧上分配变量来创建的。alloca指令提供了一个指向分配类型的指针,需要显式使用load和store指令来访问和存储值。%2 = alloca i32
现在,让我们看看add函数在LLVM IR中是如何表示的。define i32 @add(i32 %a)与C中的函数声明非常相似。它指定函数返回整数类型i32并接受一个整数参数。此外,函数名称前有’@',表示它具有全局可见性。
函数内部是实际的功能处理。这里需要注意的一些重要事项是,LLVM使用三地址指令,即一个数据处理指令,它有两个源操作数,并将结果放在单独的目标操作数中(%4 = add i32 %2, %3)。此外,代码是SSA形式的,即IR中的每个值都有一个定义该值的单一赋值。这对许多优化非常有用。
在生成的IR中紧随其后的属性字符串指定了函数属性,这与C++属性非常相似。这些属性是为已定义的函数所设。在LLVM IR中,为每个定义的函数都定义了一组属性。
属性之后的代码是用于ident指令的,用于识别模块和编译器版本。
-
LLVM工具及其在命令行中的使用
到目前为止,我们已经了解了LLVM IR(人类可读形式)是什么,以及如何用它来表示高级语言。现在,我们将看一看LLVM提供的一些工具,这些工具可以让我们将这个IR转换成其他格式,然后再转换回原始形式。让我们逐一看一下这些工具及其示例。
-
llvm-as:这是LLVM汇编器,它接受LLVM IR的汇编形式(人类可读)并将其转换为位码格式。使用前面的
add.ll作为例子,将其转换为位码。要了解更多关于LLVM Bitcode文件格式,请参阅$ llvm-as add.ll –o add.bc要查看这个位码文件的内容,可以使用诸如
hexdump之类的工具。$ hexdump –c add.bc -
llvm-dis:这是LLVM反汇编器。它接受位码文件作为输入,并输出LLVM汇编。
$ llvm-dis add.bc –o add.ll如果您检查
add.ll并与之前的版本进行比较,它将与之前的版本相同。 -
llvm-link:llvm-link链接两个或多个llvm位码文件,并输出一个llvm位码文件。为了查看演示,请编写一个调用
add.c文件中函数的main.c文件。$ cat main.c #include<stdio.h> extern int add(int); int main() { int a = add(2); printf("%d\n",a); return 0; }使用以下命令将C源代码转换为LLVM位码格式。
$ clang -emit-llvm -c main.c现在链接
main.bc和add.bc以生成output.bc。$ llvm-link main.bc add.bc -o output.bc -
lli:lli直接使用即时编译器或解释器(如果当前架构有)执行LLVM位码格式的程序。lli不像虚拟机,无法执行不同架构的IR,只能解释主机架构的IR。使用由llvm-link生成的位码格式文件作为lli的输入。它将在标准输出上显示输出。
$ lli output.bc 14 -
llc:llc是静态编译器。它将LLVM输入(汇编形式/位码形式)编译成指定架构的汇编语言。在以下示例中,它接受由llvm-link生成的
output.bc文件,并生成汇编文件output.s。$ llc output.bc –o output.s让我们看一下
output.s汇编的内容,特别是生成代码的两个函数,这与本地汇编器生成的内容非常相似。
Function main: .type main,@function main: # @main .cfi_startproc # BB#0: pushq %rbp .Ltmp0: .cfi_def_cfa_offset 16 .Ltmp1: .cfi_offset %rbp, -16 movq %rsp, %rbp .Ltmp2: .cfi_def_cfa_register %rbp subq $16, %rsp movl $0, -4(%rbp) movl $2, %edi callq add movl %eax, %ecx movl %ecx, -8(%rbp) movl $.L.str, %edi xorl %eax, %eax movl %ecx, %esi callq printf xorl %eax, %eax addq $16, %rsp popq %rbp retq .Lfunc_end0: Function: add add: # @add .cfi_startproc # BB#0: pushq %rbp .Ltmp3: .cfi_def_cfa_offset 16 .Ltmp4: .cfi_offset %rbp, -16 movq %rsp, %rbp .Ltmp5: .cfi_def_cfa_register %rbp movl %edi, -4(%rbp) addl globvar(%rip), %edi movl %edi, %eax popq %rbp retq .Lfunc_end1:CopyExplain-
opt:这是模块化的LLVM分析器和优化器。它接受输入文件并根据命令行指定的选项执行优化或分析。它执行分析器还是优化器取决于命令行选项。
opt [options] [input file name]当提供了
--analyze选项时,它对输入执行各种分析。已经提供了一组可以通过命令行指定的分析选项,或者可以编写自己的分析通道并提供给该分析通道的库。一些有用的分析通道,可以使用以下命令行参数指定:- basicaa:基本别名分析
- da:依赖性分析
- instcount:计算各种指令类型
- loops:有关循环的信息
- scalar evolution:标量演化分析
当没有传递
--analyze选项时,opt工具执行实际的优化工作,并尝试根据传递的命令行选项优化代码。与前面的情况类似,您可以使用一些已有的优化通道,或为优化编写自己的通道。一些有用的优化通道,可以使用以下命令行参数指定:- constprop:简单的常量传播
- dce:死代码消除通道
- globalopt:全局变量优化通道
- inline:函数内联通道
- instcombine:组合冗余指令
- licm:循环不变代码移动
- tailcallelim:尾调用消除
-
注意
在继续之前,我们必须注意本章中提到的所有工具都是为编译器编写者准备的。最终用户可以直接使用clang来编译C代码,而无需将C代码转换为中间表示
总结
在本章中,我们探讨了LLVM的模块化设计:如何在LLVM的opt工具中使用它,以及它如何适用于LLVM核心库。然后我们研究了LLVM的中间表示,以及一个语言的各种实体(变量、函数等)如何映射到LLVM IR。在最后一节中,我们讨论了一些重要的LLVM工具,以及它们如何用于将LLVM IR从一种形式转换为另一种形式。
在下一章中,我们将看到如何编写一个可以输出LLVM IR的语言前端,使用LLVM机制。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









