






对fetch_20newsgroups数据集进行分类
文章目录
前言
在概率统计中,有两个不同的核心学派,一个叫概率学派、另一个是贝叶斯学派。
概率统计其核心思想是样本数据是随机产生的,在数据样本无限大时,其计算出来的频率即为概率,而其要求的就是这个概率。
而贝叶斯学派中样本则是固定的,其求得的参数是随样本信息而变化的,这是两者最大的不同点。
一、朴素贝叶斯
朴素贝叶斯分类器模型会给问题实例分配用特征值表示的类标签,类标签取自有限集合。需要注意的是,所有朴素贝叶斯分类器都假定样本每个特征与其他特征都不相关。在这次实验中,利用贝叶斯分类器对fetch_20newsgroups数据集进行分类。
二、fetch_20newsgroups
这是一个数据集,是一个用于文本分类、文本挖掘和信息检索研究的国际标准数据集之一,该数据集收集了大约两万篇(1.8w+)新闻文章,将其分为20个话题,所以叫这个名字。
三、代码及操作过程
1.环境准备
需要用到sklearn模块,所以要先安装它。
在终端输入命令:
pip install -U scikit-learn
2.代码思想
代码思想如下:
①给出四个集,x_train、x_test、y_train、y_test,这四个集分别对应样本训练集、样本测试集、样本训练集对应的标签集、样本测试集对应的标签集,样本测试集设置其占据四分之一。
②对测试集和训练集的特征值进行标准化
③训练模型
④得出预测结果并将其打印出来
⑤将预测结果与实际结果进行对比,得出预测的准确率
代码如下:
from sklearn.naive_bayes import MultinomialNB
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
# 测试朴素贝叶斯
def navb():
# 读取训练数据
news = fetch_20newsgroups(subset='all')
# 进行数据的分割训练集合测试集
# X_train是样本训练集,X_test是样本测试集;y_train是样本训练集对应的标签集,y_test是样本测试集对应的标签集
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25)
# 特征工程(特征抽取),只需要对特征值处理即可
tv = TfidfVectorizer()
# 对测试集和训练集的特征值进行标准化
x_train = tv.fit_transform(x_train)
x_test = tv.transform(x_test)
# 进行算法流程 # 超参数
nb = MultinomialNB()
# 训练模型
nb.fit(x_train, y_train)
# 得出预测结果
y_predict = nb.predict(x_test)
print("预测结果:", y_predict)
# 得出准确率
score = nb.score(x_test, y_test)
print("准确率:", score)
print("每个类别的精确率和召回率:", classification_report(y_test, y_predict, target_names=news.target_names))
return None
if __name__ == "__main__":
navb()
四、fetch_20newsgroups下载太慢如何解决
如果直接这么运行程序会有一个问题:fetch_20newsgroups数据集需要联网下载,下载速度非常慢,而且可能会遇到网络连接错误。
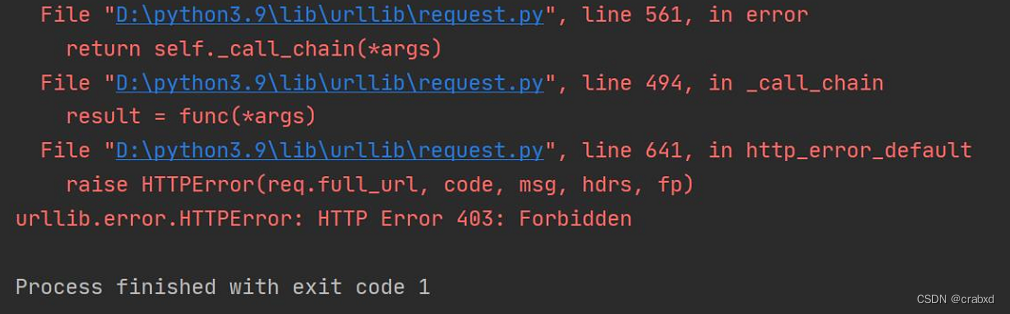
比如我用校园网下载的时候,它就报了403状态码,拒绝我访问。于是我切换成手机热点再次运行,这次倒是成功运行了,就是运行速度有点一言难尽…

足足等了它三十分钟…
为了避免该情况,可以使用如下方法:
可以通过该网站获取文件20news-bydate.tar.gz:下载网站
找到这个文件夹,C:\User\登录名\scikit_learn_data,如果你运行成功了里面会有一个20news-bydate_py3.pkz文件。如果没有,将刚刚下载的20news-bydate.tar.gz放置到该文件夹中。
找到项目所在的文件目录lib\site-packages\sklearn\datasets,打开里面的_twenty_newsgroups.py文件(数据集的联网在线下载主要是依靠它来完成的)
在该文件中找到download_20newsgroups()这个函数,将圈起的这两行代码注释掉,然后在下方添加一行代码,内容如图所示。
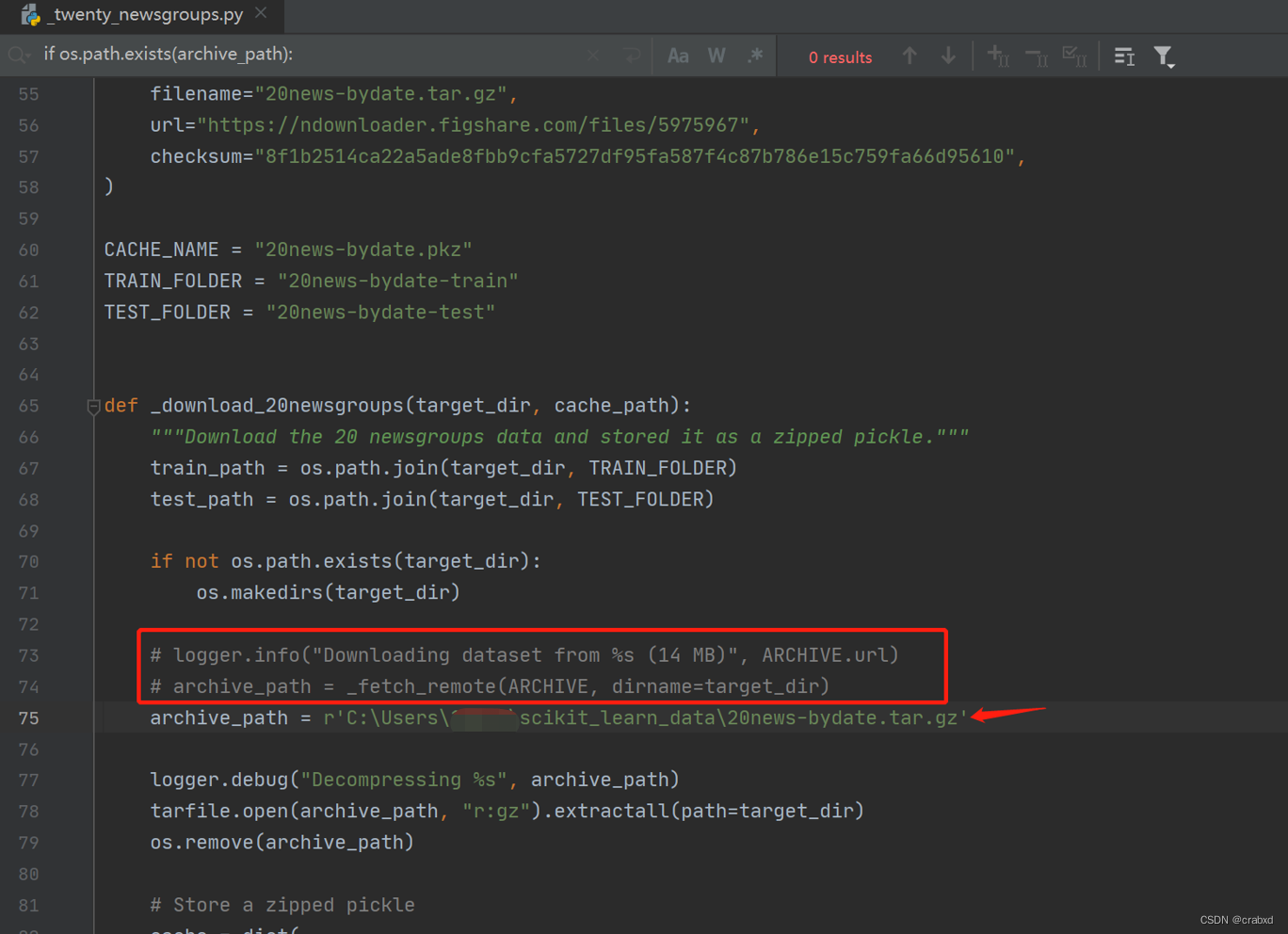
此时再次运行程序,很快便可以运行结束。
再次打开C:\User\登录名\scikit_learn_data文件夹,可以看到我们放进的20news-bydate.tar.gz已经变为20news-bydate_py3.pkz缓存文件了。

















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











