







1 数据集
该数据集由两个心跳信号收集组成,来自心跳分类中两个著名数据集:MIT-BIH心律失常数据集和PTB诊断心电图数据库。这两个集合中的样本数量足够大,可以用于训练深度神经网络。
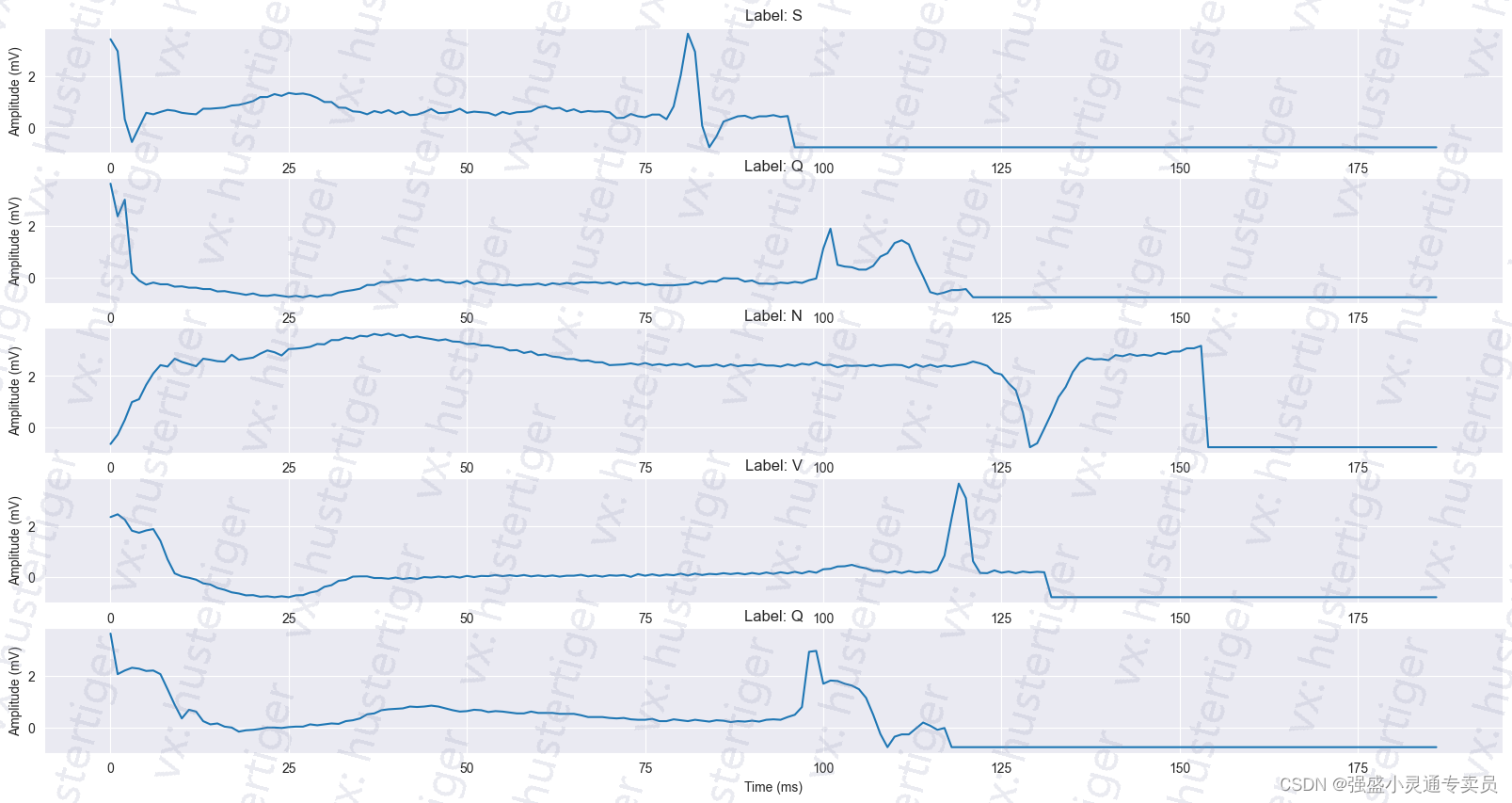
该数据集已经被用于探索使用深度神经网络架构进行心跳分类,并观察在该数据集上的迁移学习的一些能力。这些信号对应于心跳的心电图(ECG)形状,包括正常情况下的心跳和受不同心律失常和心肌梗死影响的情况。这些信号经过预处理和分割,每个分段对应一个心跳。

标签分别为'Normal Beats', 'Unknown Beats', 'Ventricular Ectopic Beats', 'Supraventricular Ectopic Beats', 'Fusion Beats'

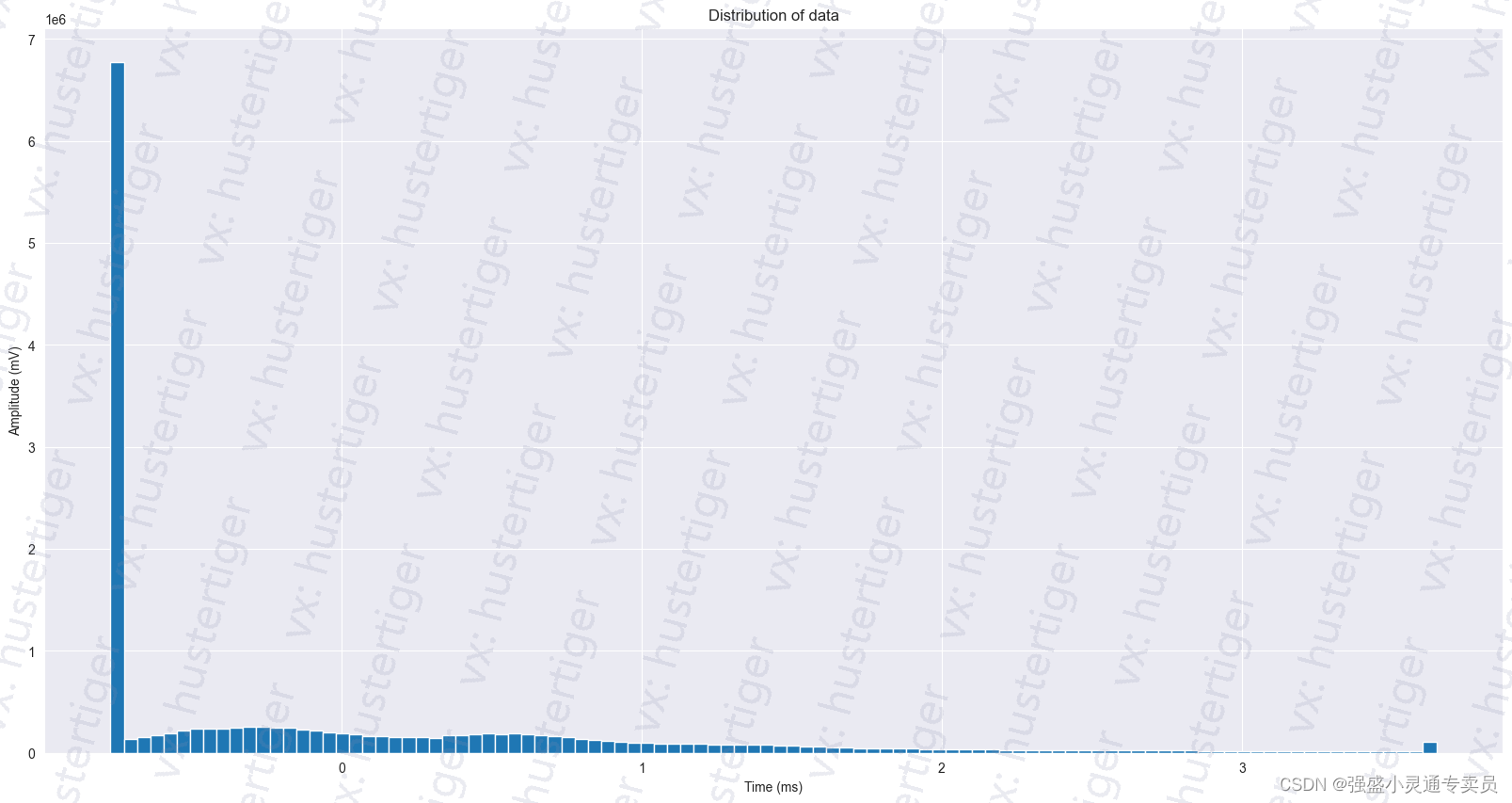
数据的时间分布如下:
2 模型
#make some convolutional blocks to use in the model
def nin_block(in_channels, out_channels, kernel_size, padding, strides):
return nn.Sequential(
nn.Conv1d(in_channels, out_channels, kernel_size, strides, padding),
nn.BatchNorm1d(out_channels),
nn.GELU(),
nn.Conv1d(out_channels, out_channels, kernel_size=1), nn.GELU(),
nn.Conv1d(out_channels, out_channels, kernel_size=1), nn.GELU()
)def get_model():
return nn.Sequential( #input shape: (batch_size, 1, 187)
nin_block(1, 48, kernel_size=11, strides=4, padding=0), #output shape: (batch_size, 48, 44)
nn.MaxPool1d(3, stride=2), #output shape: (batch_size, 48, 21)
nin_block(48, 128, kernel_size=5, strides=1, padding=2), #output shape: (batch_size, 128, 21)
nn.MaxPool1d(3, stride=2), #output shape: (batch_size, 128, 10)
nin_block(128, 256, kernel_size=3, strides=1, padding=1), #output shape: (batch_size, 256, 10)
nn.MaxPool1d(3, stride=2), #output shape: (batch_size, 256, 4)
nn.Dropout(0.4),
#last layers for classification of 5 classes
nin_block(256, 5, kernel_size=3, strides=1, padding=1), #output shape: (batch_size, 5, 4)
nn.AdaptiveAvgPool1d(1), #output shape: (batch_size, 5, 1)
nn.Flatten() #output shape: (batch_size, 5)
)绘制模型的网络结构图(需要安装Graphviz ):
安装graphviz之后出现make sure the Graphviz executables are on your systems' PATH的错误_c_daofeng的博客-CSDN博客
from torchviz import make_dot
x = torch.randn(1024, 1, 187).requires_grad_(True) # 定义一个网络的输入值
y = model(x) # 获取网络的预测值
model_viz = make_dot(y, params=dict(list(model.named_parameters()) + [('x', x)]))
model_viz.format = "png"
# 指定文件生成的文件夹
model_viz.directory = "output"
# 生成文件
model_viz.view()
3 训练
def train(model, criterion, optimizer, train_dl, val_dl, epochs, lr_scheduler: StepLR=None):
"""trains the model for the given number of epochs
Args:
model (nn.Module): nn model
criterion (nn.CELoss): loss function
optimizer (torch.optim): optimizer
train_dl (Dataloader): training dataloader
val_dl (Dataloader): validation dataloader
epochs (int): number of epochs to train for
lr_scheduler (StepLR): learning rate scheduler to adjust lr during training
Returns:
list of training losses and validation losses, best model parameters, best accuracy
"""
train_losses = []
val_losses = []
best_model_params = deepcopy(model.state_dict())
best_accuracy = 0.0
for epoch in range(epochs):
print(f'Epoch {epoch+1}/{epochs}')
print('-'*10)
train_loss = 0
val_loss = 0
model.train() #set the model to training mode
for x, y in train_dl: #x: (batch_size, 1, 187), y: (batch_size, 1)
x = x.to(device)
y = y.to(device)
optimizer.zero_grad()
output = model(x) #the output shape is (batch_size, 5) so it's a distribution over the 5 classes
loss = criterion(output, y.squeeze())
loss.backward()
optimizer.step()
train_loss += loss.item()*x.size(0)
train_loss = train_loss/len(train_dl.dataset)
train_losses.append(train_loss)
lr_scheduler.step() #update the learning rate every n epochs
model.eval() #set the model to evaluation mode
corrects = 0 #in order to calculate accuracy we store the number of correct predictions
for x, y in val_dl:
x = x.to(device)
y = y.to(device)
output = model(x) #out shape: (batch_size, 5)
loss = criterion(output, y.squeeze())
val_loss += loss.item()*x.size(0)
#calculate the number of correct predictions
corrects += torch.sum(torch.argmax(output, dim=1) == y.squeeze()).item()
val_loss = val_loss/len(val_dl.dataset)
accuracy = corrects/len(val_dl.dataset)
val_losses.append(val_loss)
print(f'Train Loss: {train_loss:.4f} \t Val Loss: {val_loss:.4f} \t Val Accuracy: {accuracy:.4f}')
#if the model performs better on the validation set, save the model parameters
if accuracy > best_accuracy:
best_accuracy = accuracy
best_model_params = deepcopy(model.state_dict())
print('Finished Training and the best accuracy is: {:.4f}'.format(best_accuracy))
return train_losses, val_losses, best_model_params, best_accuracy

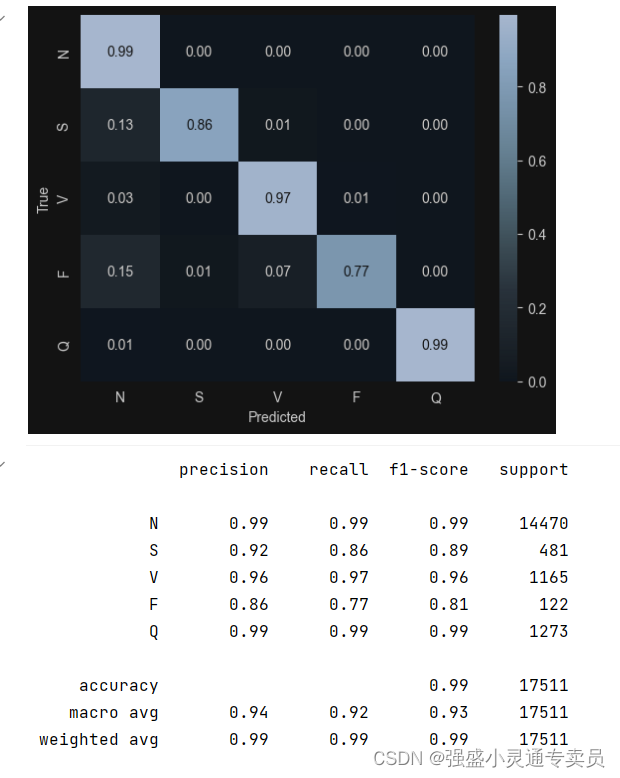
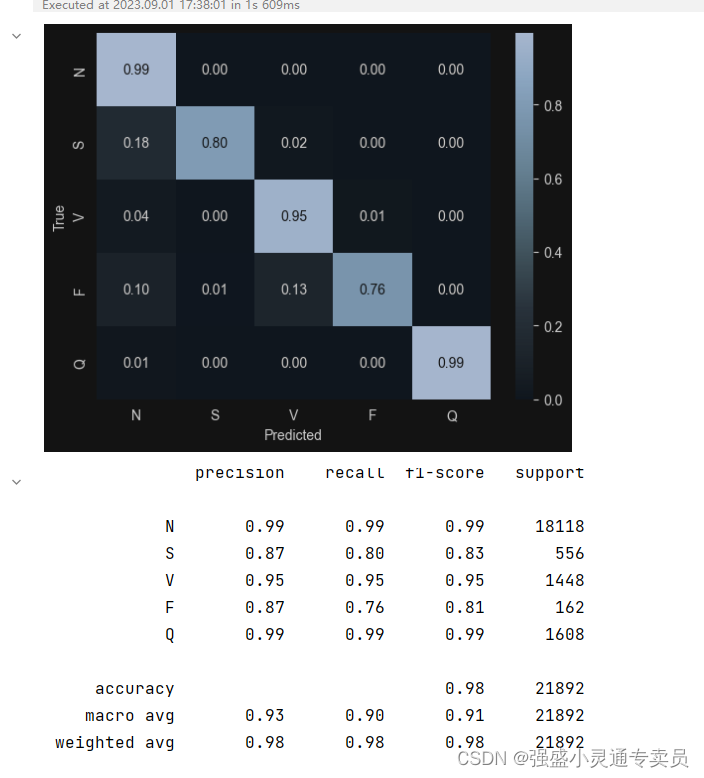
4 验证















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









