






本文 的 原文 地址
尼恩:LLM大模型学习圣经PDF的起源
在40岁老架构师 尼恩的读者交流群(50+)中,经常性的指导小伙伴们改造简历。
经过尼恩的改造之后,很多小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试机会,拿到了大厂机会。
然而,其中一个成功案例,是一个9年经验 网易的小伙伴,当时拿到了一个年薪近80W的大模型架构offer,逆涨50%,那是在去年2023年的 5月。
不到1年,小伙伴也在团队站稳了脚跟,成为了名副其实的大模型 应用 架构师。接下来,尼恩架构团队,通过 梳理一个《LLM大模型学习圣经》 帮助更多的人做LLM架构,拿到年薪100W, 这个内容体系包括下面的内容:
-
《LLM大模型学习圣经:从0到1精通RAG架构,基于LLM+RAG构建生产级企业知识库》
-
《LLM大模型学习圣经:从0到1吃透大模型的顶级架构》
-
《LLM 智能体 学习圣经:从0到1吃透 LLM 智能体 的架构 与实操》
-
《LLM 智能体 学习圣经:从0到1吃透 LLM 智能体 的 中台 架构 与实操》
-
《Spring AI 学习圣经 和配套视频 》
-
《AI部署架构:A100、H100、A800、H800、H20的差异以及如何选型?开发、测试、生产环境如何进行部署架构?》
以上学习圣经 的 配套视频, 2025年 5月份之前发布。
美团面试:LLM 大模型会有 什么问题?说说进行 RAG 优化的方法?
首先,介绍 RAG解决的问题
参考资料:ACL 2023 Tutorial: Retrieval-based Language Models and Applications
(1) 长尾知识覆盖不足 :
对于一些相对通用和大众的知识,LLM 通常能生成比较准确的结果,而对于一些长尾知识,LLM 生成的回复通常并不可靠。
尽管大模型拥有庞大的参数和训练数据集,但在长尾知识(即不常见或罕见的知识)的覆盖上仍显不足。这可能导致在处理一些特定领域或专业问题时,大模型的表现不尽如人意。
ICML 会议上的这篇论文 Large Language Models Struggle to Learn Long-Tail Knowledge,就研究了 LLM 对基于事实的问答的准确性和预训练数据中相关领域文档数量的关系,发现有很强的相关性,即预训练数据中相关文档数量越多,LLM 对事实性问答的回复准确性就越高。
从这个研究中可以得出一个简单的结论 ——LLM 对长尾知识的学习能力比较弱。
为了提升 LLM 对长尾知识的学习能力,容易想到的是在训练数据加入更多的相关长尾知识,或者增大模型的参数量,虽然这两种方法确实都有一定的效果,上面提到的论文中也有实验数据支撑,但这两种方法是不经济的,即需要一个很大的训练数据量级和模型参数才能大幅度提升 LLM 对长尾知识的回复准确性。
而通过检索的方法把相关信息在 LLM 推断时作为上下文 ( Context ) 给出,既能达到一个比较好的回复准确性,也是一种比较经济的方式。
(2)生成过程中的幻觉问题:
大模型在生成文本时可能会产生看似合理但实际上并不真实或准确的“幻觉”内容。这在一定程度上降低了生成内容的可信度。
(3)私有数据
ChatGPT 这类通用的 LLM 预训练阶段利用的大部分都是公开的数据,不包含私有数据,因此对于一些私有领域知识是欠缺的。
比如问 ChatGPT 某个企业内部相关的知识,ChatGPT 大概率是不知道或者胡编乱造。虽然可以在预训练阶段加入私有数据或者利用私有数据进行微调,但训练和迭代成本很高。此外,有研究和实践表明,通过一些特定的攻击手法,可以让 LLM 泄漏训练数据,如果训练数据中包含一些私有信息,就很可能会发生隐私信息泄露。
如果把私有数据作为一个外部数据库,让 LLM 在回答基于私有数据的问题时,直接从外部数据库中检索出相关信息,再结合检索出的相关信息进行回答。这样就不用通过预训练或者微调的方法让 LLM 在参数中记住私有知识,既节省了训练或者微调成本,也一定程度上避免了私有数据的泄露风险。
(4)数据新鲜度
由于 LLM 中学习的知识来自于训练数据,虽然大部分知识的更新周期不会很快,但依然会有一些知识或者信息更新得很频繁。LLM 通过从预训练数据中学到的这部分信息就很容易过时。
如果把频繁更新的知识作为外部数据库,供 LLM 在必要的时候进行检索,就可以实现在不重新训练 LLM 的情况下对 LLM 的知识进行更新和拓展,从而解决 LLM 数据新鲜度的问题。
(5)来源验证和可解释性
通常情况下,LLM 生成的输出不会给出其来源,比较难解释为什么会这么生成。而通过给 LLM 提供外部数据源,让其基于检索出的相关信息进行生成,就在生成的结果和信息来源之间建立了关联,因此生成的结果就可以追溯参考来源,可解释性和可控性就大大增强。即可以知道 LLM 是基于什么相关信息来生成的回复。
利用检索来增强 LLM 的输出,其中很重要的一步是通过一些检索相关的技术从外部数据中找出相关信息片段,然后把相关信息片段作为上下文供 LLM 在生成回复时参考。有人可能会说,随着 LLM 的上下文窗口 ( Context Window ) 越来越长,检索相关信息的步骤是不是就没有必要了,直接在上下文中提供尽可能多的信息。
然后,介绍一下rag(检索增强生成)技术的基本原理
rag 检索增强 LLM ( Retrieval Augmented LLM ),简单来说,就是给 LLM 提供外部数据库,对于用户问题 ( Query ),通过一些信息检索 ( Information Retrieval, IR ) 的技术,先从外部数据库中检索出和用户问题相关的信息,然后让 LLM 结合这些相关信息来生成结果。
下图是一个检索增强 LLM 的简单示意图。
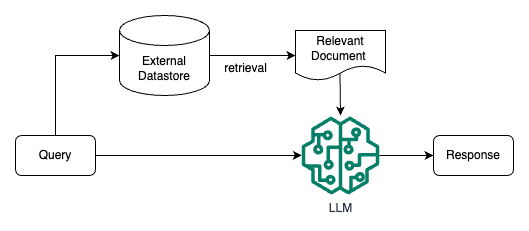
传统的信息检索工具,比如 Google/Bing 这样的搜索引擎,只有检索能力 ( Retrieval-only ),现在 LLM 通过预训练过程,将海量数据和知识嵌入到其巨大的模型参数中,具有记忆能力 ( Memory-only )。
从这个角度看,检索增强 LLM 处于中间,将 LLM 和传统的信息检索相结合,通过一些信息检索技术将相关信息加载到 LLM 的工作内存 ( Working Memory ) 中,即 LLM 的上下文窗口 ( Context Window ),亦即 LLM 单次生成时能接受的最大文本输入。
检索增强 LLM ( Retrieval Augmented LLM ),简单来说,就是给 LLM 提供外部数据库,对于用户问题 ( Query ),通过一些信息检索 ( Information Retrieval, IR ) 的技术,先从外部数据库中检索出和用户问题相关的信息,然后让 LLM 结合这些相关信息来生成结果。
OpenAI 研究科学家 Andrej Karpathy 前段时间在微软 Build 2023 大会上做过一场关于 GPT 模型现状的分享 State of GPT,这场演讲前半部分分享了 ChatGPT 这类模型是如何一步一步训练的,后半部分主要分享了 LLM 模型的一些应用方向,其中就对检索增强 LLM 这个应用方向做了简单介绍。
下面这张图就是 Andrej 分享中关于这个方向的介绍。
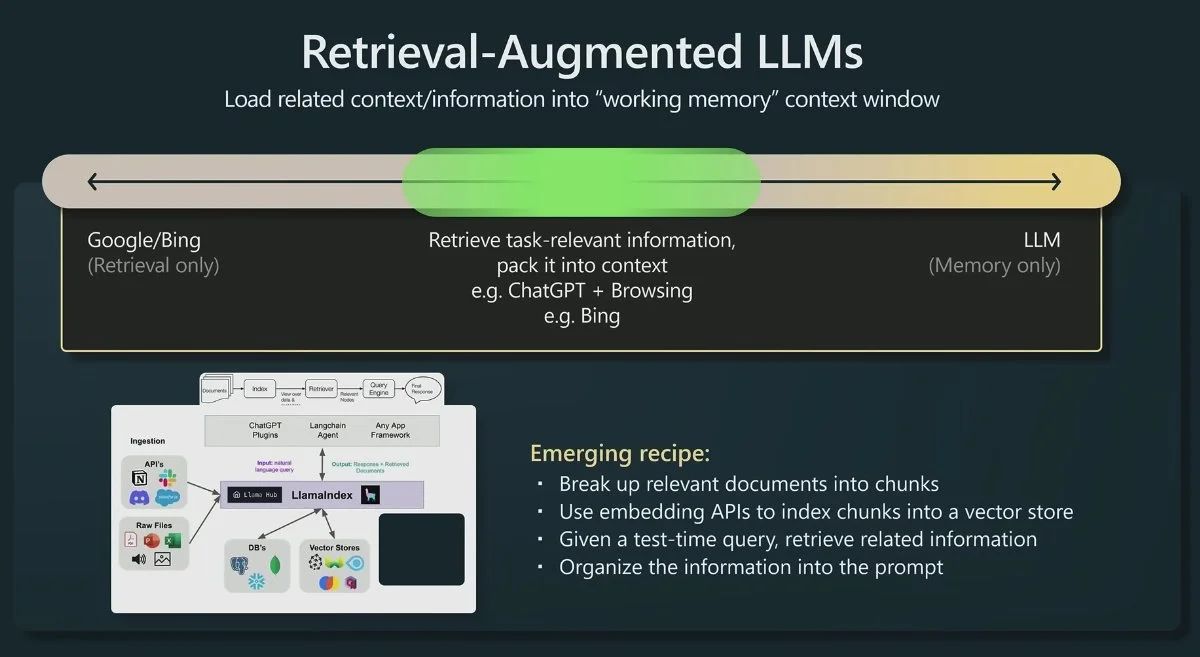
传统的信息检索工具,比如 Google/Bing 这样的搜索引擎,只有检索能力 ( Retrieval-only ),现在 LLM 通过预训练过程,将海量数据和知识嵌入到其巨大的模型参数中,具有记忆能力 ( Memory-only )。
从这个角度看,检索增强 LLM 处于中间,将 LLM 和传统的信息检索相结合,通过一些信息检索技术将相关信息加载到 LLM 的工作内存 ( Working Memory ) 中,即 LLM 的上下文窗口 ( Context Window ),亦即 LLM 单次生成时能接受的最大文本输入。
不仅 Andrej 的分享中提到基于检索来增强 LLM 这一应用方式,从一些著名投资机构针对 AI 初创企业技术栈的调研和总结中,也可以看到基于检索来增强 LLM 技术的广泛应用。
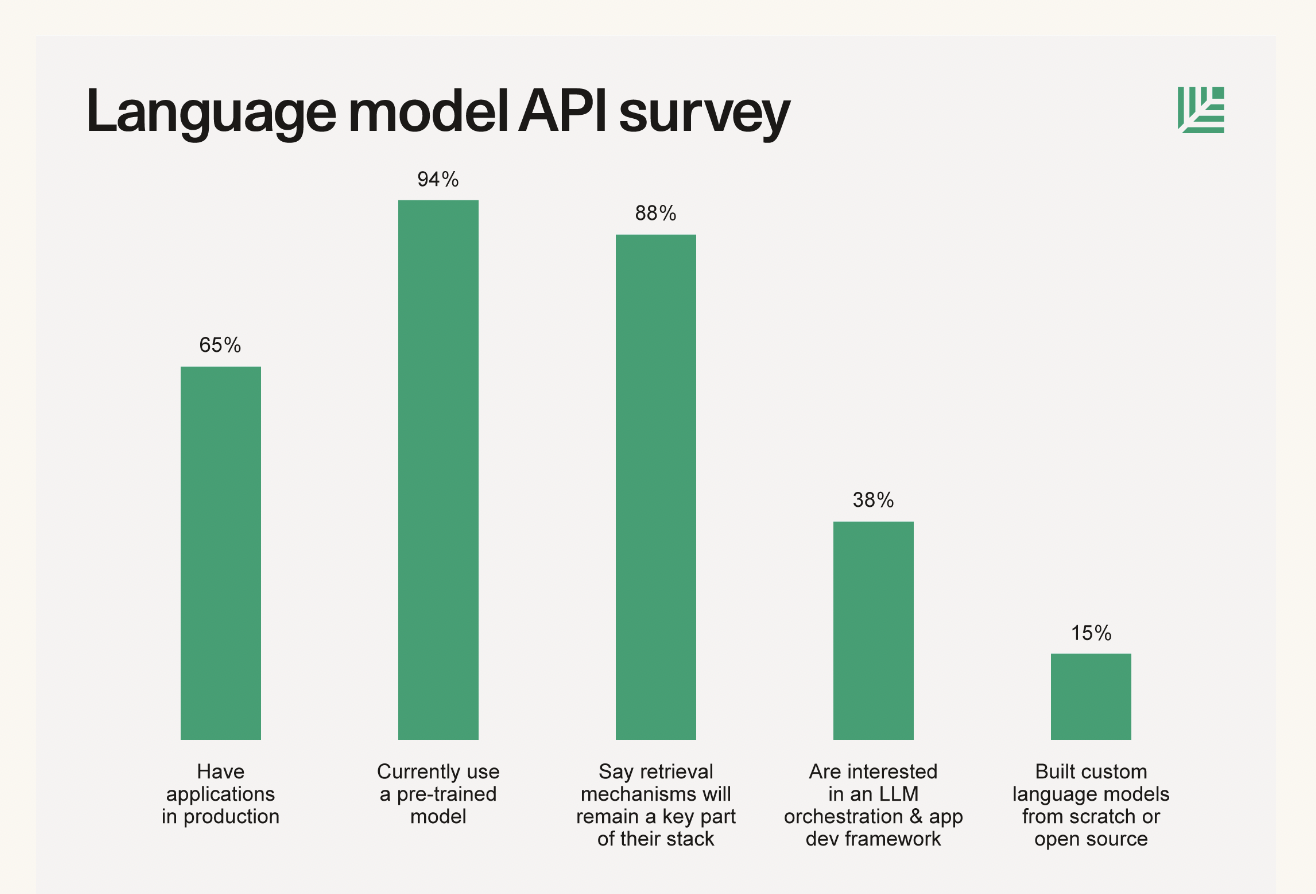
比如今年6月份红杉资本发布了一篇关于大语言模型技术栈的文章 The New Language Model Stack,其中就给出了一份对其投资的33家 AI 初创企业进行的问卷调查结果,下图的调查结果显示有 88% 左右的创业者表示在自己的产品中有使用到基于检索增强 LLM 技术。
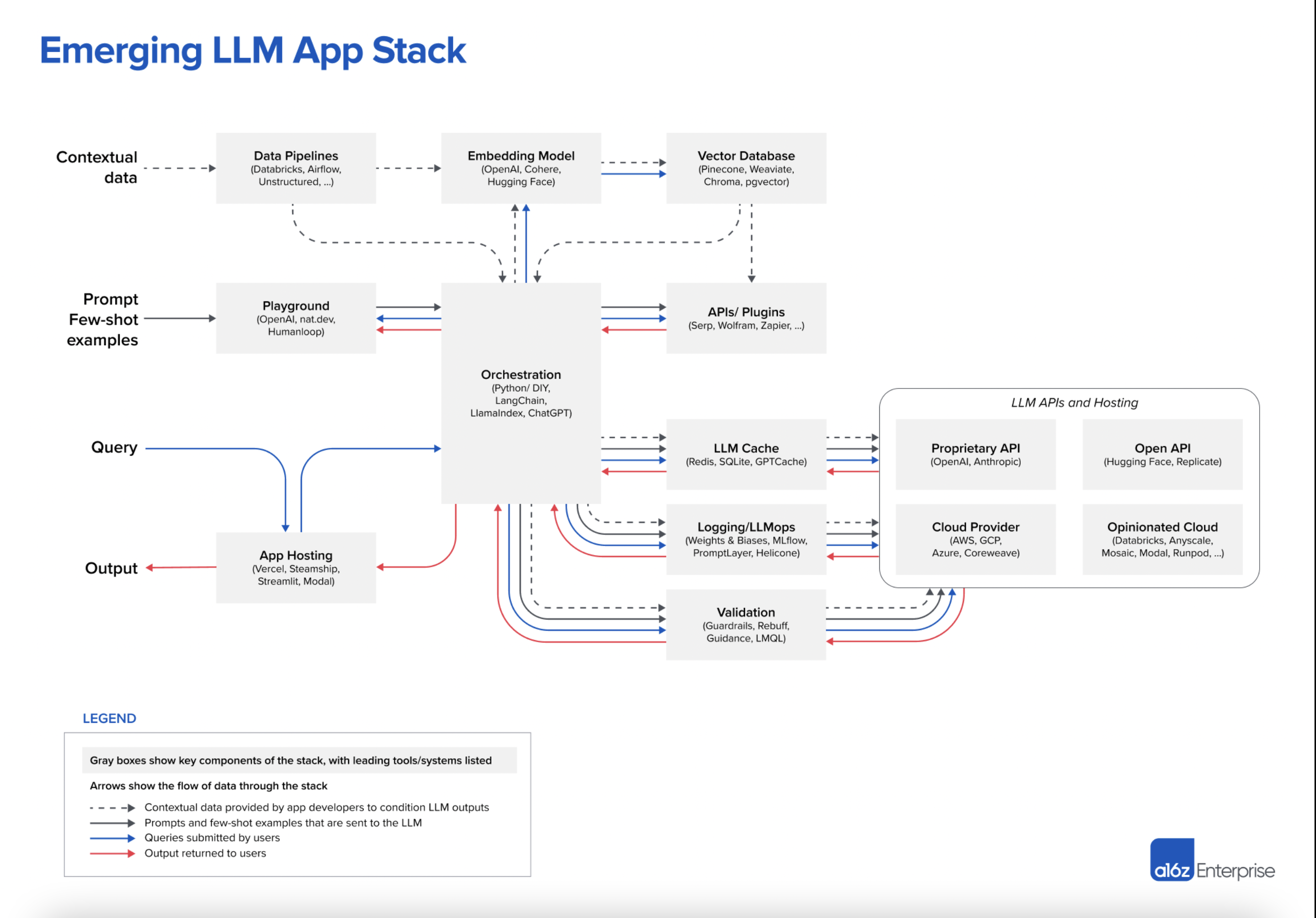
无独有偶,美国著名风险投资机构 A16Z 在今年6月份也发表了一篇介绍当前 LLM 应用架构的总结文章 Emerging Architectures for LLM Applications,
下图就是文章中总结的当前 LLM 应用的典型架构,其中最上面 Contextual Data 引入 LLM 的方式就是一种通过检索来增强 LLM 的思路。
接着,介绍一下: RAG(检索增强生成) 的大致优点
针对以上问题,RAG(检索增强生成)技术提供了一种有效的优化方法。
RAG通过结合检索和生成两个过程,利用检索到的外部信息来增强生成模型的表现。
以下是一些RAG优化的大致优点:
1、优化检索器:
- 采用先进的检索技术:如密集向量检索、稀疏向量检索等,这些技术能够更好地捕捉文本之间的语义相似性,从而提高检索的准确性和效率。
- 多向量表示:使用多个向量来表示同一个文档或查询,以捕捉不同方面的信息,从而增加检索的全面性。
- 实时检索:对于需要处理最新信息的任务,实时检索是必不可少的。这要求检索系统能够快速响应并更新索引数据。
2、 增强生成器的可控性和推理能力:
- 监督训练:通过监督训练信号或模型反馈来微调生成器,使其能够更准确地利用检索到的信息来生成响应。
- 情境调节:使用专用的交叉注意力转换器层或具有自我监督目标的预训练语言模型来加强生成器对上下文信息的理解和利用。
3、 结合检索与生成的过程优化:
- 重排序模型:在检索到相关信息后,使用重排序模型对结果进行重新排序,以进一步提高生成响应的准确性和相关性。
- 多模态融合:对于需要处理多模态信息的任务(如图像、视频等),可以将RAG技术与多模态检索和生成技术相结合,以充分利用不同模态之间的互补信息。
4、 提高系统透明度和可解释性:
- 设计模型架构:以结构化链/图的形式明确跟踪证据和解释,使生成过程更加透明和可解释。
- 生成推理路径:在生成响应时,同时生成推理路径或证据链,以便用户了解生成过程的决策依据。
接下来,深入说说: 检索增强RAG的 三大关键模块
ChatGPT 的出现,让我们看到了大语言模型 ( Large Language Model, LLM ) 在语言和代码理解、人类指令遵循、基本推理等多方面的能力,但幻觉问题 Hallucinations 仍然是当前大语言模型面临的一个重要挑战。简单来说,幻觉问题是指 LLM 生成不正确、荒谬或者与事实不符的结果。
此外,数据新鲜度 ( Data Freshness )也是 LLM 在生成结果时出现的另外一个问题,即 LLM 对于一些时效性比较强的问题可能给不出或者给出过时的答案。
而通过检索外部相关信息的方式来增强 LLM 的生成结果是当前解决以上问题的一种流行方案,这里把这种方案称为 检索增强 LLM ( Retrieval Augmented LLM ),有时候也被称为 检索增强生成 ( Retrieval Augmented Generation, RAG )。
为了构建检索增强 LLM 系统,RAG关键模块包括:
-
数据和索引模块:如何处理外部数据和构建索引
-
查询和检索模块:如何准确高效地检索出相关信息
-
响应生成模块:如何利用检索出的相关信息来增强 LLM 的输出
RAG模块一: 数据和索引模块
(一)RAG 的 数据获取
数据获取模块的作用一般是将多种来源、多种类型和格式的外部数据转换成一个统一的文档对象 ( Document Object ),便于后续流程的处理和使用。
文档对象除了包含原始的文本内容,一般还会携带文档的元信息 ( Metadata ),可以用于后期的检索和过滤。元信息包括但不限于:
- 时间信息,比如文档创建和修改时间
- 标题、关键词、实体(人物、地点等)、文本类别等信息
- 文本总结和摘要
既可以采用传统的 NLP 模型和框架,也可以基于 LLM 实现。
有些元信息可以直接获取,有些则可以借助 NLP 技术,比如关键词抽取、实体识别、文本分类、文本摘要等。
外部数据的来源可能是多种多样的,比如可能来自
- Google 套件里各种 Doc 文档、Sheet 表格、Slides 演示、Calendar 日程、Drive 文件等
- Slack、Discord 等聊天社区的数据
- Github、Gitlab 上托管的代码文件
- Confluence 上各种文档
- Web 网页的数据
- API 返回的数据
- 本地文件
外部数据的类型和文件格式也可能是多样化的,比如
- 从数据类型来看,包括纯文本、表格、演示文档、代码等
- 从文件存储格式来看,包括 txt、csv、pdf、markdown、json 等格式
外部数据可能是多语种的,比如中文、英文、德文、日文等。除此之外,还可能是多模态的,除了上面讨论的文本模态,还包括图片、音频、视频等多种模态。
在构建数据获取模块时,不同来源、类型、格式、语种的数据可能都需要采用不同的读取方式。
(二)文本分块
文本分块是将长文本切分成小片段的过程,比如将一篇长文章切分成一个个相对短的段落。
那么为什么要进行文本分块?一方面当前 LLM 的上下文长度是有限制的,直接把一篇长文全部作为相关信息放到 LLM 的上下文窗口中,可能会超过长度限制。
另一方面,对于长文本来说,即使其和查询的问题相关,但一般不会通篇都是完全相关的,而分块能一定程度上剔除不相关的内容,为后续的回复生成过滤一些不必要的噪声。
文本分块的好坏将很大程度上影响后续回复生成的效果,切分得不好,内容之间的关联性会被切断。因此设计一个好的分块策略十分重要。
分块策略包括具体的切分方法 ( 比如是按句子切分还是段落切分 ),块的大小设为多少合适,不同的块之间是否允许重叠等。
Pinecone 的这篇博客 Chunking Strategies for LLM Applications 中就给出了一些在设计分块策略时需要考虑的因素。
- 原始内容的特点:原始内容是长文 ( 博客文章、书籍等 ) 还是短文 ( 推文、即时消息等 ),是什么格式 ( HTML、Markdown、Code 还是 LaTeX 等 ),不同的内容特点可能会适用不同的分块策略;
- 后续使用的索引方法:目前最常用的索引是对分块后的内容进行向量索引,那么不同的向量嵌入模型可能有其适用的分块大小,比如 sentence-transformer 模型比较适合对句子级别的内容进行嵌入,OpenAI 的 text-embedding-ada-002 模型比较适合的分块大小在 256~512 个标记数量;
- 问题的长度:问题的长度需要考虑,因为需要基于问题去检索出相关的文本片段;
- 检索出的相关内容在回复生成阶段的使用方法:如果是直接把检索出的相关内容作为 Prompt 的一部分提供给 LLM,那么 LLM 的输入长度限制在设计分块大小时就需要考虑。
文本分块 的 实现方法
那么文本分块具体如何实现?
一般来说,实现文本分块的整体流程如下:
(1) 将原始的长文本切分成小的语义单元,这里的语义单元通常是句子级别或者段落级别;
(2) 将这些小的语义单元融合成更大的块,直到达到设定的块大小 ( Chunk Size ),就将该块作为独立的文本片段;
(3) 迭代构建下一个文本片段,一般相邻的文本片段之间会设置重叠,以保持语义的连贯性。
那如何把原始的长文本切分成小的语义单元?
最常用的是基于分割符进行切分,比如句号 ( . )、换行符 ( \n )、空格等。除了可以利用单个分割符进行简单切分,还可以定义一组分割符进行迭代切分,比如定义 ["\n\n", "\n", " ", ""] 这样一组分隔符,切分的时候先利用第一个分割符进行切分 ( 实现类似按段落切分的效果 ),第一次切分完成后,对于超过预设大小的块,继续使用后面的分割符进行切分,依此类推。
这种切分方法能比较好地保持原始文本的层次结构。
对于一些结构化的文本,比如代码,Markdown,LaTeX 等文本,在进行切分的时候可能需要单独进行考虑:
- 比如 Python 代码文件,分割符中可能就需要加入类似
\nclass,\ndef这种来保证类和函数代码块的完整性; - 比如 Markdown 文件,是通过不同层级的 Header 进行组织的,即不同数量的 # 符号,在切分时就可以通过使用特定的分割符来维持这种层级结构。
文本块大小的设定也是分块策略需要考虑的重要因素,太大或者太小都会影响最终回复生成的效果。
文本块大小的计算方法,最常用的可以直接基于字符数进行统计 ( Character-level ),也可以基于标记数进行统计 ( Token-level )。
至于如何确定合适的分块大小,这个因场景而异,很难有一个统一的标准,可以通过评估不同分块大小的效果来进行选择。
上面提到的一些分块方法在 LangChain 中都有相应的实现。
比如下面的代码示例
from langchain.text_splitter import CharacterTextSplitter
from langchain.text_splitter import RecursiveCharacterTextSplitter, Language
// text split
text_splitter = RecursiveCharacterTextSplitter(
// Set a really small chunk size, just to show.
chunk_size = 100,
chunk_overlap = 20,
length_function = len,
add_start_index = True,
)
// code split
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON,
chunk_size=50,
chunk_overlap=0
)
// markdown split
md_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.MARKDOWN,
chunk_size=60,
chunk_overlap=0
)
(三)数据索引
经过前面的数据读取和文本分块操作后,接着就需要对处理好的数据进行索引。
索引是一种数据结构,用于快速检索出与用户查询相关的文本内容。
它是检索增强 LLM 的核心基础组件之一。
下面介绍几种常见的索引结构。
为了说明不同的索引结构,引入节点(Node)的概念。
在这里,节点就是前面步骤中对文档切分后生成的文本块(Chunk)。
(1)链式索引
链式索引通过链表的结构对文本块进行顺序索引。
在后续的检索和生成阶段,可以简单地顺序遍历所有节点,也可以基于关键词进行过滤。



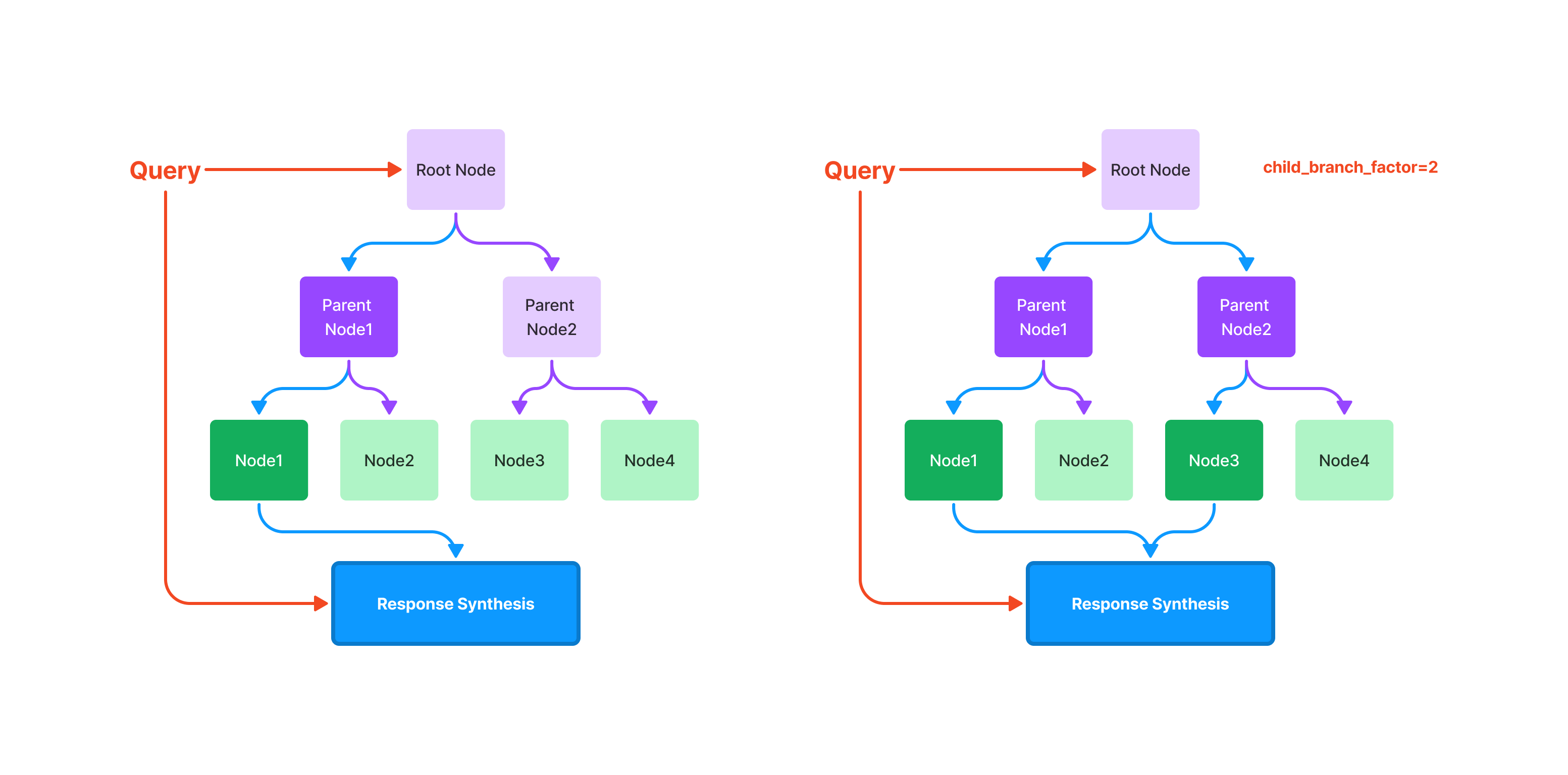
(2)树索引
树索引将一组节点 ( 文本块 ) 构建成具有层级的树状索引结构,其从叶节点 (原始文本块) 向上构建,每个父节点都是子节点的摘要。
在检索阶段,既可以从根节点向下进行遍历,也可以直接利用根节点的信息。树索引提供了一种更高效地查询长文本块的方式,它还可以用于从文本的不同部分提取信息。
与链式索引不同,树索引无需按顺序查询。

(3)关键词表索引
关键词表索引从每个节点中提取关键词,构建了每个关键词到相应节点的多对多映射,意味着每个关键词可能指向多个节点,每个节点也可能包含多个关键词。
在检索阶段,可以基于用户查询中的关键词对节点进行筛选。


(4)向量索引
向量索引是当前最流行的一种索引方法。这种方法一般利用文本嵌入模型 ( Text Embedding Model ) 将文本块映射成一个固定长度的向量,然后存储在向量数据库中。
检索的时候,对用户查询文本采用同样的文本嵌入模型映射成向量,然后基于向量相似度计算获取最相似的一个或者多个节点。


上面的表述中涉及到向量索引和检索中三个重要的概念: 文本嵌入模型、相似向量检索和向量数据库。下面一一进行详细说明。
4.1 文本嵌入模型
文本嵌入模型 ( Text Embedding Model ) 将非结构化的文本转换成结构化的向量 ( Vector ),目前常用的是学习得到的稠密向量。

当前有很多文本嵌入模型可供选择,比如
- 早期的 Word2Vec、GloVe 模型等,目前很少用。
- 基于孪生 BERT 网络预训练得到的 Sentence Transformers 模型,对句子的嵌入效果比较好
- OpenAI 提供的 text-embedding-ada-002 模型,嵌入效果表现不错,且可以处理最大 8191 标记长度的文本
- Instructor 模型,这是一个经过指令微调的文本嵌入模型,可以根据任务(例如分类、检索、聚类、文本评估等)和领域(例如科学、金融等),提供任务指令而生成相对定制化的文本嵌入向量,无需进行任何微调
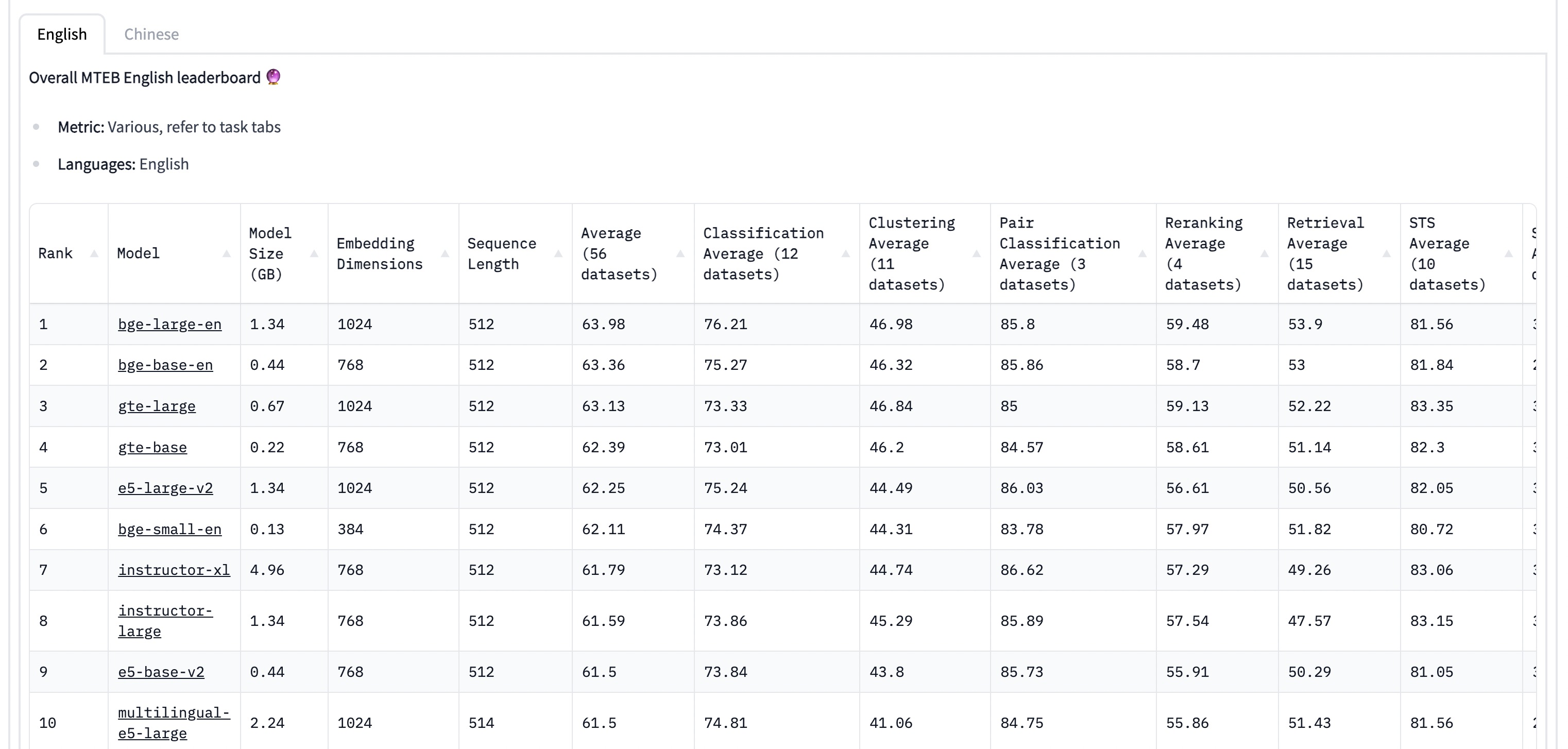
- BGE模型: 由智源研究院开源的中英文语义向量模型,目前在MTEB中英文榜单都排在第一位。
下面就是评估文本嵌入模型效果的榜单 MTEB Leaderboard (截止到 2023-08-18 )。
值得说明的是,这些现成的文本嵌入模型没有针对特定的下游任务进行微调,所以不一定在下游任务上有足够好的表现。
最好的方式一般是在下游特定的数据上重新训练或者微调自己的文本嵌入模型。
4.2 相似向量检索
相似向量检索要解决的问题是给定一个查询向量,如何从候选向量中准确且高效地检索出与其相似的一个或多个向量。
首先是相似性度量方法的选择,可以采用余弦相似度、点积、欧式距离、汉明距离等,通常情况下可以直接使用余弦相似度。其次是相似性检索算法和实现方法的选择,候选向量的数量量级、检索速度和准确性的要求、内存的限制等都是需要考虑的因素。
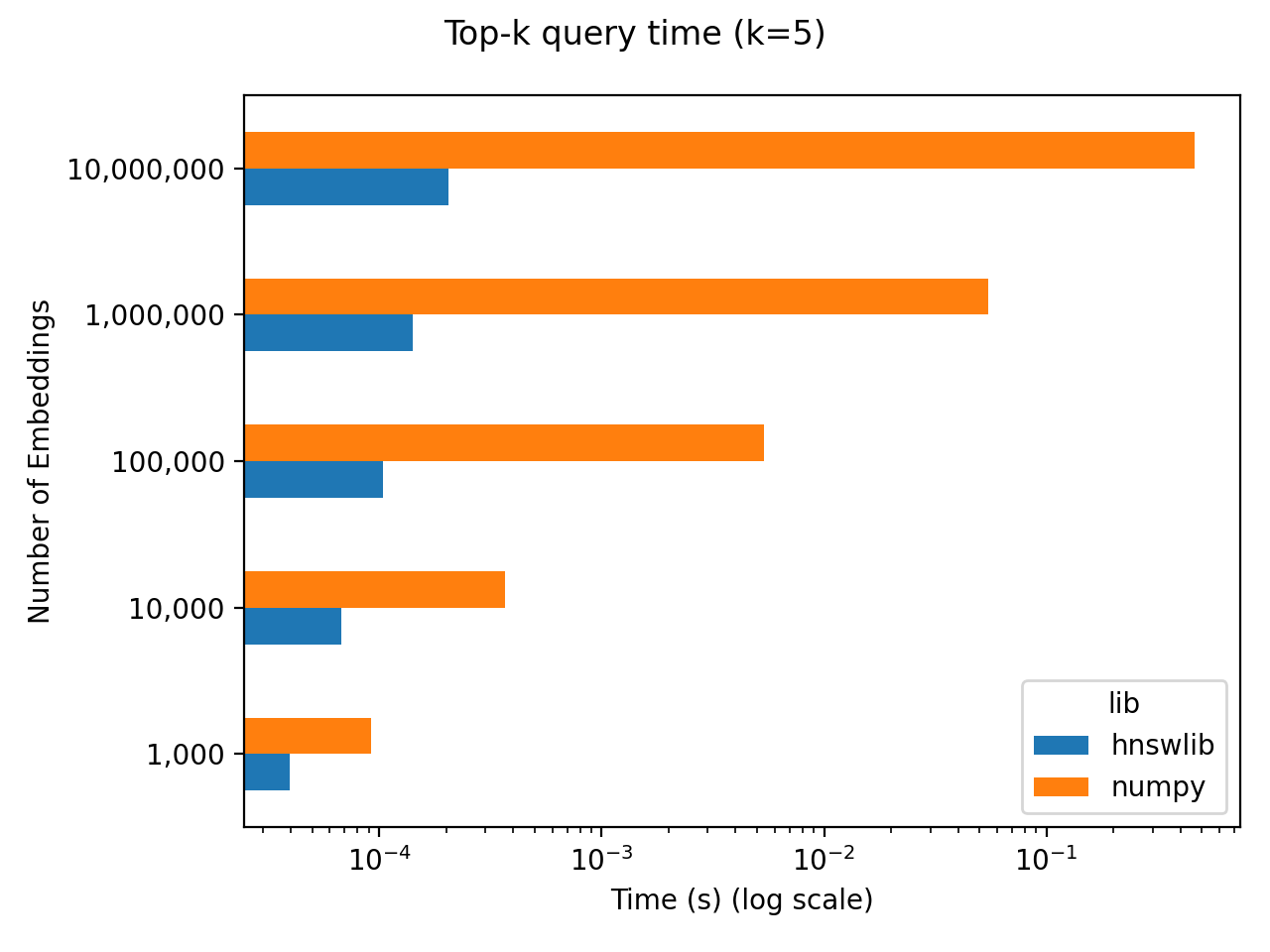
当候选向量的数量比较少时,比如只有几万个向量,那么 Numpy 库就可以实现相似向量检索,实现简单,准确性高,速度也很快。
国外有个博主做了个简单的基准测试发现 Do you actually need a vector database ,当候选向量数量在 10 万量级以下时,通过对比 Numpy 和另一种高效的近似最近邻检索实现库 Hnswlib ,发现在检索效率上并没有数量级的差异,但 Numpy 的实现过程更简单。
下面就是使用 Numpy 的一种简单实现代码:
import numpy as np
// candidate_vecs: 2D numpy array of shape N x D
// query_vec: 1D numpy array of shape D
// k: number of top k similar vectors
sim_scores = np.dot(candidate_vecs, query_vec)
topk_indices = np.argsort(sim_scores)[::-1][:k]
topk_values = sim_scores[topk_indices]
对于大规模向量的相似性检索,使用 Numpy 库就不合适,需要使用更高效的实现方案。Facebook团队开源的 Faiss 就是一个很好的选择。Faiss 是一个用于高效相似性搜索和向量聚类的库,它实现了在任意大小的向量集合中进行搜索的很多算法,除了可以在CPU上运行,有些算法也支持GPU加速。Faiss 包含多种相似性检索算法,具体使用哪种算法需要综合考虑数据量、检索频率、准确性和检索速度等因素。
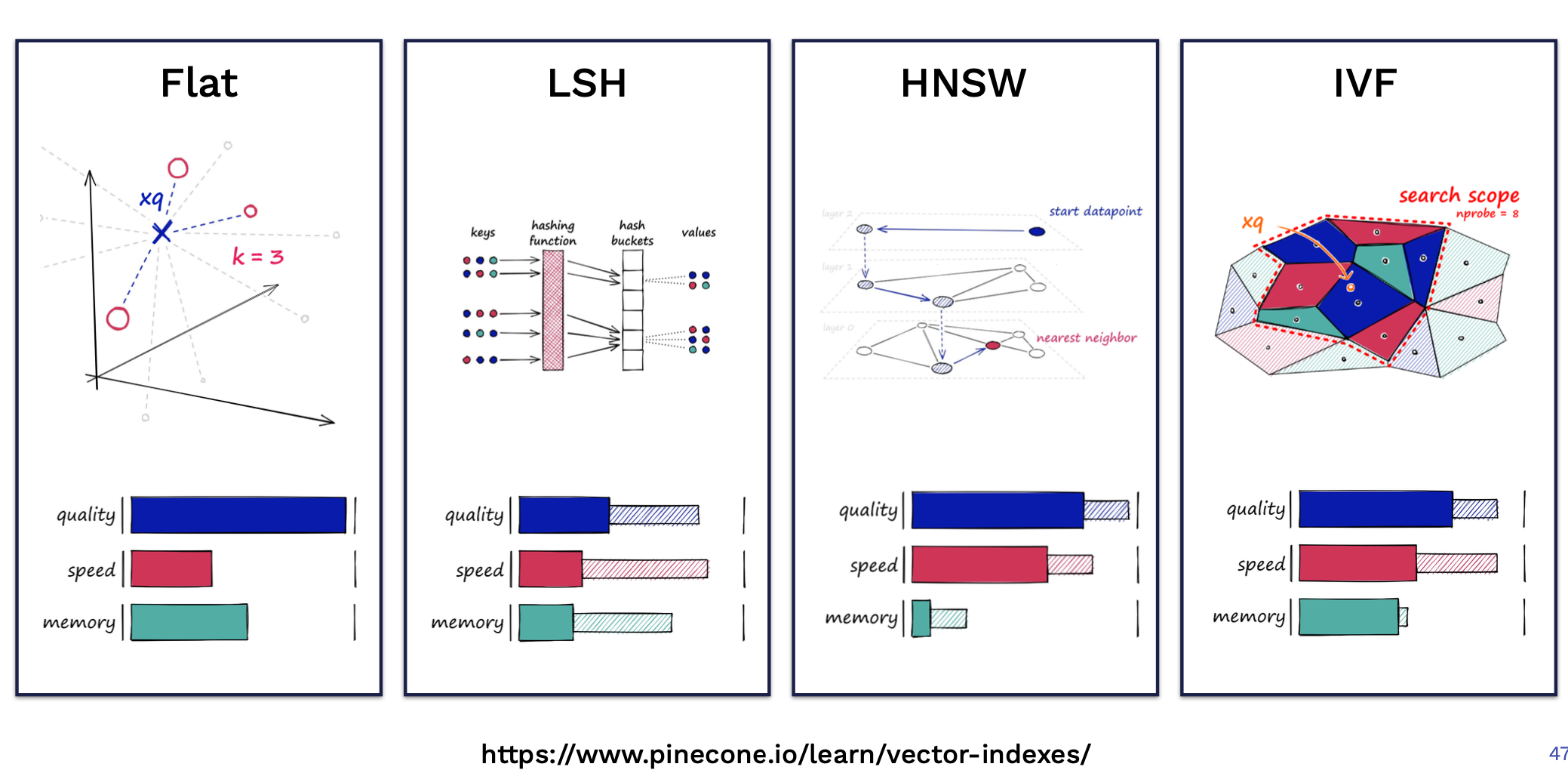
Pinecone 的这篇博客 Nearest Neighbor Indexes for Similarity Search 对 Faiss 中常用的几种索引进行了详细介绍,下图是几种索引在不同维度下的定性对比:
4.3 向量数据库
上面提到的基于 Numpy 和 Faiss 实现的向量相似检索方案,如果应用到实际产品中,可能还缺少一些功能,比如:
- 数据托管和备份
- 数据管理,比如数据的插入、删除和更新
- 向量对应的原始数据和元数据的存储
- 可扩展性,包括垂直和水平扩展
所以向量数据库应运而生。
简单来说,向量数据库是一种专门用于存储、管理和查询向量数据的数据库,可以实现向量数据的相似检索、聚类等。
目前比较流行的向量数据库有 Pinecone、Vespa、Weaviate、Milvus、Chroma 、Tencent Cloud VectorDB等,大部分都提供开源产品。
Pinecone 的这篇博客 What is a Vector Database 就对向量数据库的相关原理和组成进行了比较系统的介绍,下面这张图就是文章中给出的一个向量数据库常见的数据处理流程:

第一步:索引:
使用乘积量化 ( Product Quantization ) 、局部敏感哈希 ( LSH )、HNSW 等算法对向量进行索引,这一步将向量映射到一个数据结构,以实现更快的搜索。
第2步:查询:
将查询向量和索引向量进行比较,以找到最近邻的相似向量。
第3步:后处理:
有些情况下,向量数据库检索出最近邻向量后,对其进行后处理后再返回最终结果。
向量数据库的使用比较简单,下面是使用 Python 操作 Pinecone 向量数据库的示例代码:
// install python pinecone client
// pip install pinecone-client
import pinecone
// initialize pinecone client
pinecone.init(api_key="YOUR_API_KEY", environment="YOUR_ENVIRONMENT")
// create index
pinecone.create_index("quickstart", dimension=8, metric="euclidean")
// connect to the index
index = pinecone.Index("quickstart")
// Upsert sample data (5 8-dimensional vectors)
index.upsert([
("A", [0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1]),
("B", [0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2]),
("C", [0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3]),
("D", [0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4]),
("E", [0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5])
])
// query
index.query(
vector=[0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3],
top_k=3,
include_values=True
)
// Returns:
// {'matches': [{'id': 'C',
// 'score': 0.0,
// 'values': [0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3]},
// {'id': 'D',
// 'score': 0.0799999237,
// 'values': [0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4]},
// {'id': 'B',
// 'score': 0.0800000429,
// 'values': [0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2]}],
// 'namespace': ''}
// delete index
pinecone.delete_index("quickstart")
RAG模块二:查询和检索模块
(1)查询变换
查询文本的表达方法直接影响着检索结果,微小的文本改动都可能会得到天差万别的结果。
直接用原始的查询文本进行检索在很多时候可能是简单有效的,但有时候可能需要对查询文本进行一些变换,以得到更好的检索结果,从而更可能在后续生成更好的回复结果。
下面列出几种常见的查询变换方式。
1)变换一: 同义改写
将原始查询改写成相同语义下不同的表达方式,改写工作可以调用 LLM 完成。
比如对于这样一个原始查询: What are the approaches to Task Decomposition?,可以改写成下面几种同义表达:
How can Task Decomposition be approached?
What are the different methods for Task Decomposition?
What are the various approaches to decomposing tasks?
对于每种查询表达,分别检索出一组相关文档,然后对所有检索结果进行去重合并,从而得到一个更大的候选相关文档集合。通过将同一个查询改写成多个同义查询,能够克服单一查询的局限,获得更丰富的检索结果集合。
2)变换二: 查询分解
有相关研究表明 ( self-ask,ReAct ),LLM 在回答复杂问题时,如果将复杂问题分解成相对简单的子问题,回复表现会更好。这里又可以分成单步分解和多步分解。
单步分解将一个复杂查询转化为多个简单的子查询,融合每个子查询的答案作为原始复杂查询的回复。
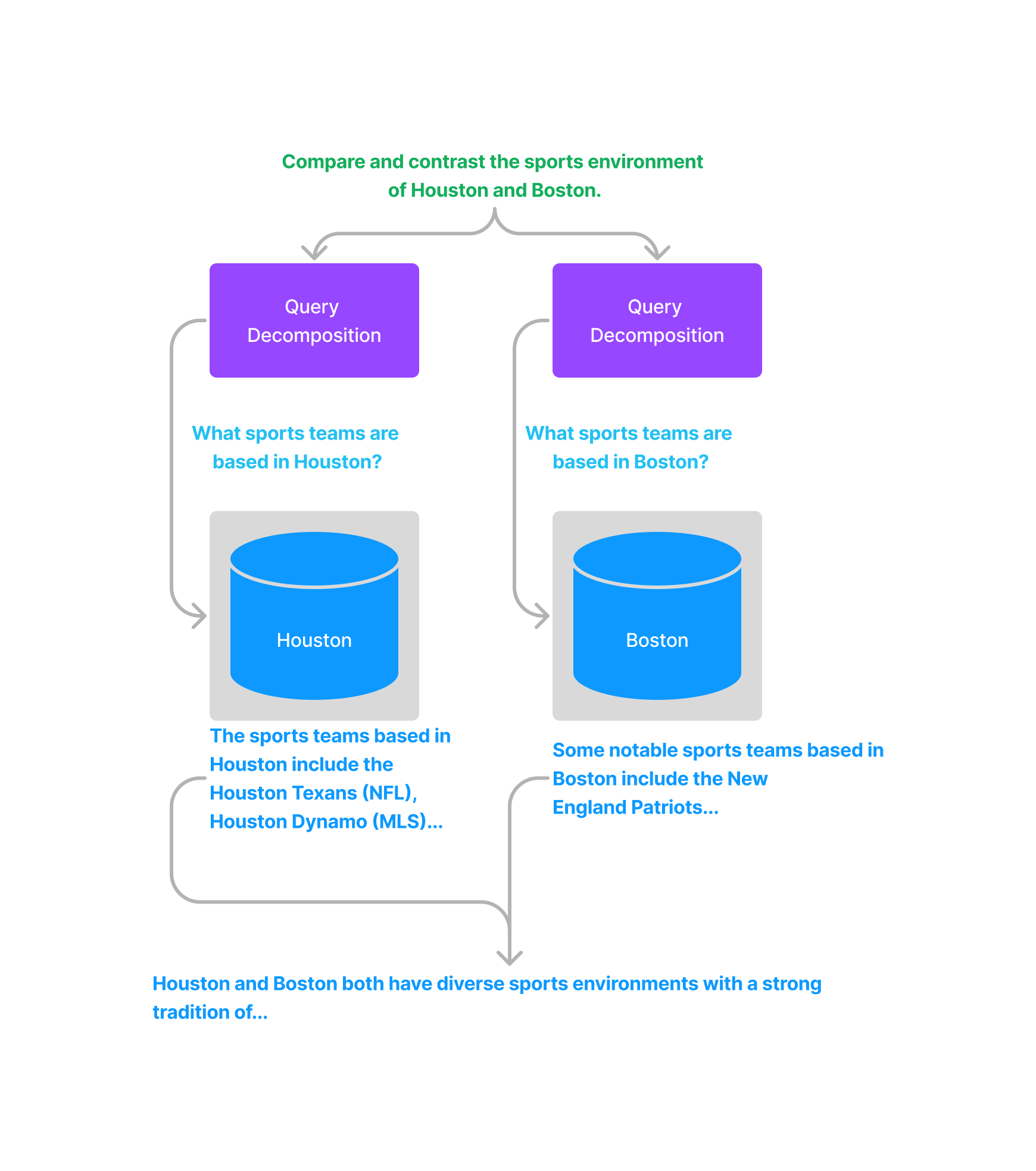
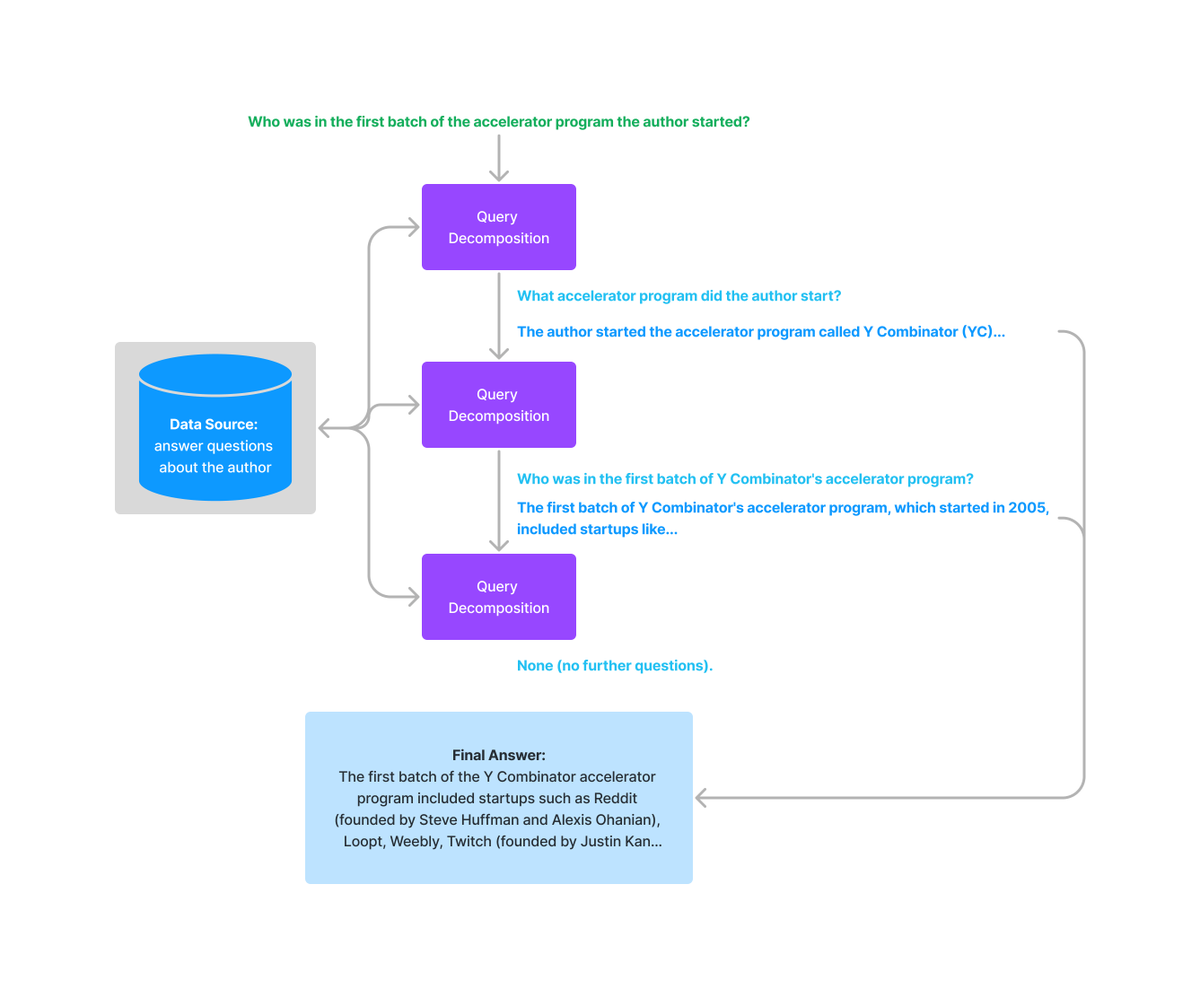
对于多步分解,给定初始的复杂查询,会一步一步地转换成多个子查询,结合前一步的回复结果生成下一步的查询问题,直到问不出更多问题为止。最后结合每一步的回复生成最终的结果。
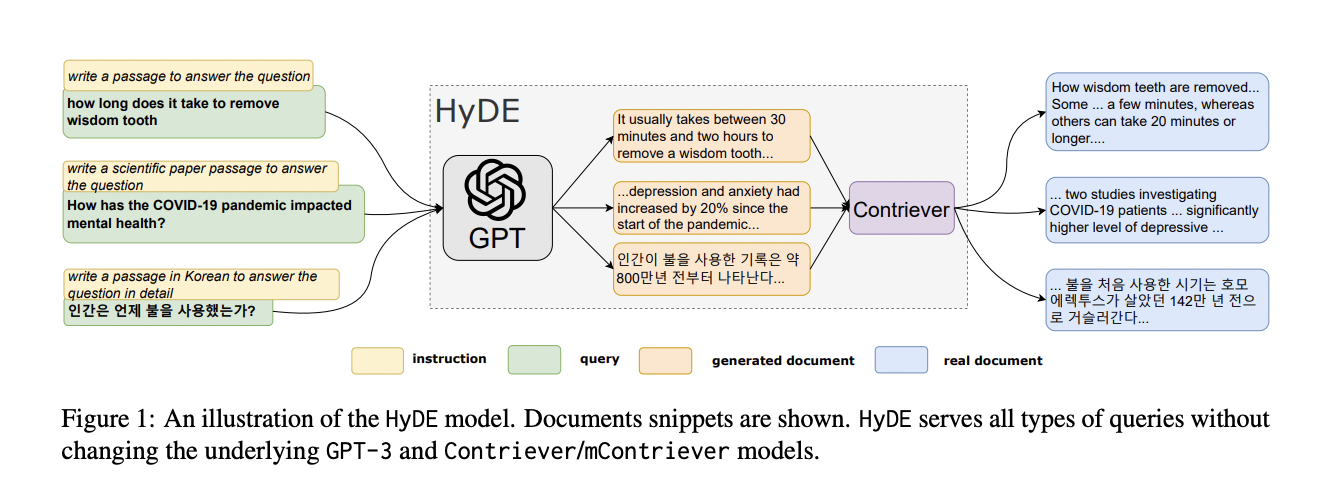
3)变换三: HyDE
HyDE,全称叫 Hypothetical Document Embeddings,给定初始查询,首先利用 LLM 生成一个假设的文档或者回复,然后以这个假设的文档或者回复作为新的查询进行检索,而不是直接使用初始查询。
这种转换在没有上下文的情况下可能会生成一个误导性的假设文档或者回复,从而可能得到一个和原始查询不相关的错误回复。
下面是论文中给出的一个例子:
(2)排序和后处理
经过前面的检索过程可能会得到很多相关文档,就需要进行筛选和排序。常用的筛选和排序策略包括:
- 基于相似度分数进行过滤和排序
- 基于关键词进行过滤,比如限定包含或者不包含某些关键词
- 让 LLM 基于返回的相关文档及其相关性得分来重新排序
- 基于时间进行过滤和排序,比如只筛选最新的相关文档
- 基于时间对相似度进行加权,然后进行排序和筛选
(3)混合检索(Hybird Search)
什么是混合检索?
混合检索(Hybrid Search)是一种将多种不同检索技术或数据源相结合的搜索方法,旨在提高检索的准确性、全面性和效率,以更好地满足用户的搜索需求。
在实际生产中,传统的关键字检索(稀疏表示,例如淘宝的搜索框)与向量检索(稠密表示)各有优劣,举个具体的例子,比如文档中包含很长的专有名字,关键字检索往往更精准而向量检索容易引入概念混淆。
混合检索的方式
- 结合不同的检索技术:例如将基于关键词的检索与基于语义的检索相结合。基于关键词的检索速度快,但可能会因关键词匹配的局限性而遗漏一些相关信息;基于语义的检索能够理解文本的含义,更好地处理语义相关但关键词不完全匹配的情况,但计算成本较高。混合使用这两种技术,可以在保证一定检索速度的同时,提高检索结果的准确性和相关性。
- 融合多种数据源:可以整合来自不同数据库、不同类型文档或不同领域的信息。比如在一个企业的信息检索系统中,将内部的文档管理系统、客户关系管理系统以及外部的行业报告数据库等多个数据源进行混合检索,使用户能够在一个统一的界面下获取到全面的信息,而无需分别在不同的系统中进行查询。
使用Elasticsearch实现 混合检索
Elasticsearch(ES)作为一款强大的开源搜索引擎,提供了多种检索方式,其中混合检索(Hybrid Search)结合了传统的关键词检索和向量检索的优点,实现了更高效、准确的信息检索。
以下,结合ES的knn向量检索和关键词检索,实现混合检索。
创建混合索引
首先,我们需要在ES中创建一个包含关键词字段和向量字段的混合索引,例如一个包含新闻文章标题、内容以及内容向量的索引:
PUT /news_index
{
"mappings": {
"properties": {
"title": {
"type": "text"
},
"content": {
"type": "text"
},
"content_vector": {
"type": "dense_vector",
"dims": 768,
"index": true,
"similarity": "cosine"
}
}
}
}
这里的content_vector字段用于存储内容的向量表示,title和content是传统的关键词字段。
插入示例数据
假设我们有以下新闻数据:
PUT /news_index/_doc/1
{
"title": "人工智能在医疗领域的应用",
"content": "人工智能技术正在改变医疗行业,通过机器学习模型辅助医生进行疾病诊断...",
"content_vector": [0.1, 0.2, ..., 0.768] // 假设这里是768维的向量表示
}
PUT /news_index/_doc/2
{
"title": "AI技术的最新进展",
"content": "最新的AI技术在自然语言处理、计算机视觉等方面取得了重要突破...",
"content_vector": [0.2, 0.3, ..., 0.768]
}
PUT /news_index/_doc/3
{
"title": "医疗行业的挑战与机遇",
"content": "医疗行业正面临着技术革新带来的挑战,同时也迎来了新的发展机遇...",
"content_vector": [0.4, 0.5, ..., 0.768]
}
混合检索查询
现在,我们可以构建一个结合knn向量检索和关键词检索的查询,以“人工智能在医疗行业的发展”为查询语句:
GET /news_index/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"content": "人工智能在医疗行业的发展"
}
},
{
"knn": {
"content_vector": {
"query_vector": [0.15, 0.25, ..., 0.768], // 这里是查询语句的向量表示
"k": 3
}
}
}
]
}
}
}
DSL 解释:
bool查询用于组合多个条件。should子句表示满足其中任意一个条件的文档都会被返回,并且它们的得分会累加。match查询部分是传统的关键词检索,会根据关键词匹配情况对文档进行打分。knn查询部分则是向量检索,会找到与查询向量最近邻的文档。
结果排序与融合
还需要对knn和关键词检索的结果进行进一步的排序和融合,以提高检索结果的准确性。
可以使用Elasticsearch的混合搜索 结合 凸组合(Convex Combination)或倒数秩融合(Reciprocal Rank Fusion, RRF)等方式来融合两种检索的结果。
例如,使用RRF进行排序融合:
GET /news_index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"match": {
"content": "人工智能在医疗行业的发展"
}
}
}
},
{
"knn": {
"field": "content_vector",
"query_vector": [0.15, 0.25, ..., 0.768], // 这里是查询语句的向量表示
"k": 3
}
}
],
"window_size": 50,
"rank_constant": 20
}
}
}
在这个查询中,rrf作为排序方式,对关键词检索和向量检索的结果进行融合排序,从而得到更优的检索结果。
通过这种混合检索的方式,我们可以充分利用关键词检索的精确性和向量检索的语义理解能力,提高信息检索的效率和质量。
关键点解释
- retriever.rrf.retrievers:指定要融合的检索器。这里包括一个标准的BM25关键词检索器和一个kNN向量检索器。关键词检索器会对文档的
content字段进行关键词匹配,kNN检索器则会找到与查询向量在向量空间中最邻近的文档。 - window_size:确定每个查询单个结果集的大小。较高的值可以提高结果相关性,但会以性能为代价。它必须大于或等于
size且大于或等于1,默认为100。 - rank_constant:确定每个查询的单个结果集中的文档对最终排名结果集的影响程度。较高的值表示排名较低的文档具有更大的影响力,默认为60。
- RRF计算:对于每个文档,其最终排名分数由以下公式计算:
1.0 / (1 + rank),其中rank是指定查询结果集中该文档的排名(从1开始计数)。如果一个文档出现在多个查询结果集中,则其最终排名分数是各个查询结果集中计算得到的分数之和。然后根据这些最终排名分数对文档进行排序,得到融合后的结果。
通过这种结合关键词检索、向量检索以及RRF二次排序的方法,可以充分利用关键词检索的精确性和向量检索的语义理解能力,同时利用RRF对结果进行优化排序,提高信息检索的效率和质量。
RAG模块三:回复生成模块
(1)回复生成策略
检索模块基于用户查询检索出相关的文本块,回复生成模块让 LLM 利用检索出的相关信息来生成对原始查询的回复。LlamaIndex 中有给出一些不同的回复生成策略。
一种策略是依次结合每个检索出的相关文本块,每次不断修正生成的回复。这样的话,有多少个独立的相关文本块,就会产生多少次的 LLM 调用。另一种策略是在每次 LLM 调用时,尽可能多地在 Prompt 中填充文本块。如果一个 Prompt 中填充不下,则采用类似的操作构建多个 Prompt,多个 Prompt 的调用可以采用和前一种相同的回复修正策略。
(2)回复生成 Prompt 模板
下面是 LlamaIndex 中提供的一个生成回复的 Prompt 模板。从这个模板中可以看到,可以用一些分隔符 ( 比如 ------ ) 来区分相关信息的文本,还可以指定 LLM 是否需要结合它自己的知识来生成回复,以及当提供的相关信息没有帮助时,要不要回复等。
template = f'''
Context information is below.
---------------------
{context_str}
---------------------
Using both the context information and also using your own knowledge, answer the question: {query_str}
If the context isn't helpful, you can/don’t answer the question on your own.
'''
下面的 Prompt 模板让 LLM 不断修正已有的回复。
template = f'''
The original question is as follows: {query_str}
We have provided an existing answer: {existing_answer}
We have the opportunity to refine the existing answer (only if needed) with some more context below.
------------
{context_str}
------------
Using both the new context and your own knowledege, update or repeat the existing answer.
'''
补充说说:RAG vs. SFT 的区别?
| RAG | SFT传统方法 | |
|---|---|---|
| 数据 | 动态数据。 RAG 不断查询外部源,确保信息保持最新,而无需频繁的模型重新训练。 | (相对)静态数据,并且在动态数据场景中可能很快就会过时。 SFT 也不能保证记住这些知识。 |
| 外部知识库 | RAG 擅长利用外部资源。通过在生成响应之前从知识源检索相关信息来增强 LLM 能力。 它非常适合文档或其他结构化/非结构化数据库。 | SFT 可以对 LLM 进行微调以对齐预训练学到的外部知识,但对于频繁更改的数据源来说可能不太实用。 |
| 模型定制 | RAG 主要关注信息检索,擅长整合外部知识,但可能无法完全定制模型的行为或写作风格。 | SFT 允许根据特定的语气或术语调整LLM 的行为、写作风格或特定领域的知识。 |
| 缓解幻觉 | RAG 本质上不太容易产生幻觉,因为每个回答都建立在检索到的证据上。 | SFT 可以通过将模型基于特定领域的训练数据来帮助减少幻觉。 但当面对不熟悉的输入时,它仍然可能产生幻觉。 |
| 透明度 | RAG 系统通过将响应生成分解为不同的阶段来提供透明度,提供对数据检索的匹配度以提高对输出的信任。 | SFT 就像一个黑匣子,使得响应背后的推理更加不透明。 |
| 相关技术 | RAG 需要高效的检索策略和大型数据库相关技术。另外还需要保持外部数据源集成以及数据更新。 | SFT 需要准备和整理高质量的训练数据集、定义微调目标以及相应的计算资源。 |
与预训练或微调基础模型等传统方法相比,RAG 提供了一种经济高效的替代方法。
RAG 从根本上增强了大语言模型在响应特定提示时直接访问特定数据的能力。
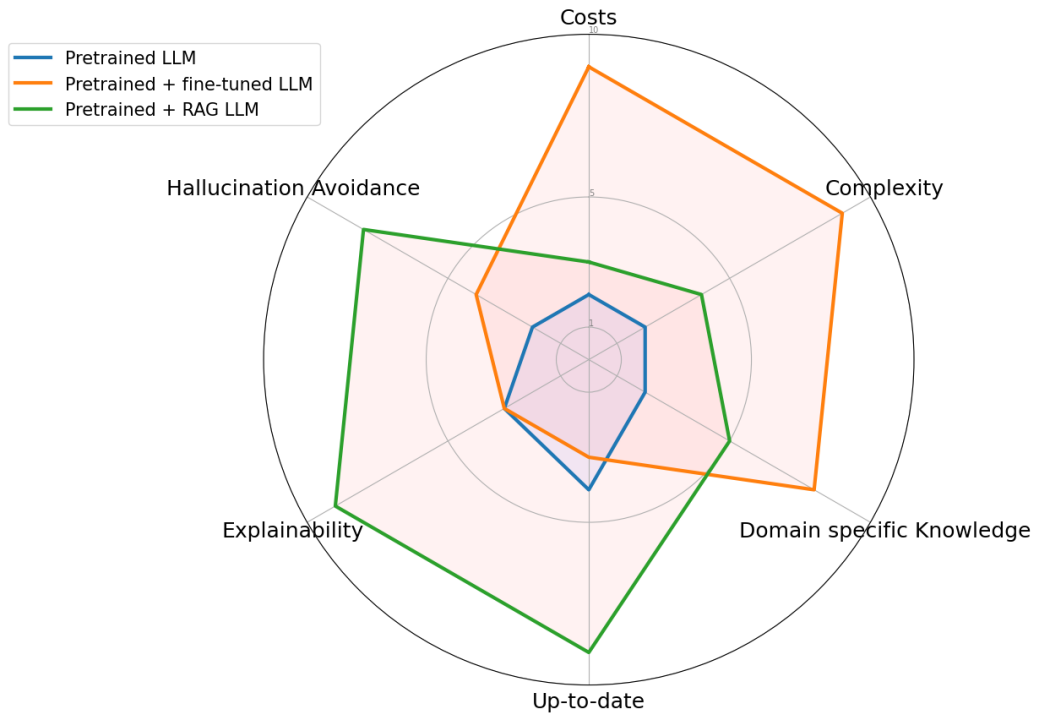
为了说明 RAG 与其他方法的区别,请看下图。
雷达图具体比较了三种不同的方法:预训练大语言模型、预训练 + 微调 LLM 、预训练 + RAG LLM。
遇到问题,找老架构师取经
借助此文,尼恩给解密了一个高薪的 秘诀,大家可以 放手一试。保证 屡试不爽,涨薪 100%-200%。
后面,尼恩java面试宝典回录成视频, 给大家打造一套进大厂的塔尖视频。
通过这个问题的深度回答,可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”,然后实现”offer直提”。
在面试之前,建议大家系统化的刷一波 5000页《尼恩Java面试宝典PDF》,里边有大量的大厂真题、面试难题、架构难题。
很多小伙伴刷完后, 吊打面试官, 大厂横着走。
在刷题过程中,如果有啥问题,大家可以来 找 40岁老架构师尼恩交流。
另外,如果没有面试机会,可以找尼恩来改简历、做帮扶。
遇到职业难题,找老架构取经, 可以省去太多的折腾,省去太多的弯路。
尼恩指导了大量的小伙伴上岸,前段时间,刚指导一个40岁+被裁小伙伴,拿到了一个年薪100W的offer。
狠狠卷,实现 “offer自由” 很容易的, 前段时间一个武汉的跟着尼恩卷了2年的小伙伴, 在极度严寒/痛苦被裁的环境下, offer拿到手软, 实现真正的 “offer自由” 。

















 1068
1068

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









