







大家好,我是皮先生!!
今天给大家分享一些关于大模型面试常见的RAG(检索增强生成)相关面试题,希望对大家的面试有所帮助。
目录
1.什么是RAG,它有什么特点?
1.1初识RAG
- RAG(Retrieval Augmented Generation)为生成式模型与外部世界互动提供了一个很有前景的解决方案。
- RAG的主要作用类似搜索引擎,找到用户提问最相关的知识或者是相关的对话历史,并结合原始提问(查询),创造信息丰富的prompt,指导模型生成准确输出。
- 其本质上应用了情境学习(In-Context Learning)的原理。
- 总结:RAG(检索增强生成)=检索技术+LLM 提示
1.2 RAG的特点
- 依赖大语言模型来强化信息检索和输出:RAG需要结合大型语言模型(LLM)来进行信息的检索和生成,但如果单独使用RAG它的能力会受到限制。也就是说,RAG需要依赖强大的语言模型支持,才能更有效地生成和提供信息。
- 能与外部数据有效集成:RAG能够很好地接入和利用外部数据库的数据资源。这一特性弥补了通用大模型在某些垂直或专业领域的知识不足,比如行业特定的术语和深度内容,能提供更精确的答案。
- 数据隐私和安全保障:通常,RAG所连接的私有数据库不会参与到大模型的数据集训练中。因此,RAG既能提升模型的输出表现,又能有效地保护这些私有数据的隐私性和安全性,不会将敏感信息暴露给大模型的训练过程。
- 表现效果因多方面因素而异:RAG的效果受多个因素的影响,比如所使用的语言模型的性能、接入数据的质量、AI算法的先进性以及检索系统的设计等。这意味着不同的RAG系统之间效果差异较大,不能一概而论。
2.详细介绍一下RAG的5个基本流程
RAG可分为5个基本流程:(1)知识文档的准备;(2)嵌入模型(embedding model);(3)向量数据库;(4)查询检索(5)生成回答。
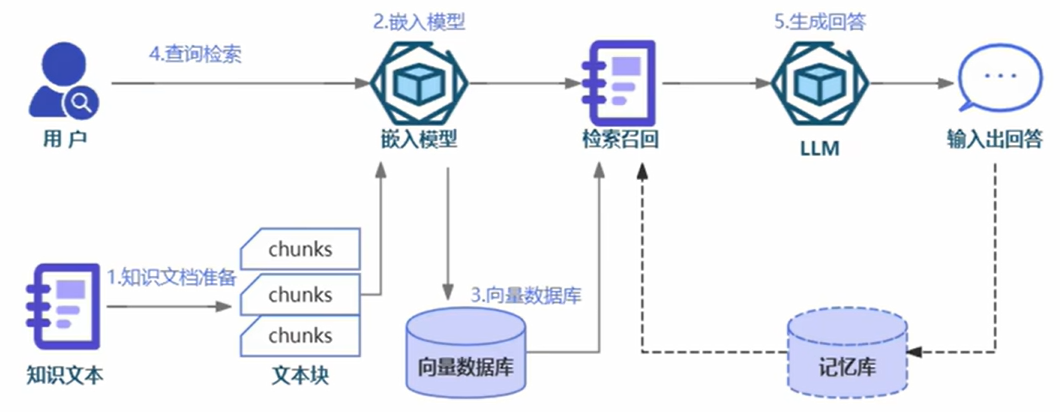
1.知识文档的准备
- 在构建一个高效的RAG系统时,首要步骤是准备知识文档。
- 现实场景中,我们面对的知识源可能包括多种格式,如Word文档、TXT文件、CSV数据表、Excel表格,甚至是PDF文件、图片和视频等。
- 因此,第一步需要使用专门的文档加载器(例如PDF提取器)或多模态模型(如OCR技术),将这些丰富的知识源转换为大语言模型可理解的纯文本数据。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 941
941

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









