









文献地址:https://arxiv.org/abs/2003.11282。
该文是ECCV2020 oral。
目录
一、概述
该文章基于深度学习的端到端视频编解码框框架DVC(https://blog.csdn.net/cs_softwore/article/details/87006743)的后续研究,同样出自DVC的研究团队,主要为了解决基于学习的视频编解码的错误传播和视频内容自适应问题。错误传播的问题通过在训练阶段考虑连续多帧的压缩来解决,是一个训练策略的改进;本文提出的内容自适应方案,可以根据视频内容在线更新编码器,区别于传统的手工编码模式。
二、本文贡献
1、提出EPA(error propagation aware,错误传播感知)训练机制;
2、在线更新策略,可以使解码器在推理阶段对视频内容自适应;
3、不增加解码端的模型复杂度和计算时间,且相对于其它基于学习的方法,还能达到state-of-the-art编解码效果。
三、论文思想
1、动机
(1)错误传播。由于帧间预测的原因,当前帧编解码依赖前一个解码帧,在一个GOP内,随着时间的推移,误差会逐渐累计,传统算法和基于学习的方法都会遇到错误扩散的问题。
(2)内容自适应。传统方法为了能够达到最佳压缩,在图像平滑区域采用大的块,在内容复杂(纹理丰富)的区域采用较小的块;基于学习的方法,在训练阶段通过优化率失真(rate-distortion optimization -RDO)对网络进行指导,然而训练样本与测试样本存在domain gap,训练得到的参数可能对测试集并不是最优的。
2、本文提出的方法
(1)回顾一下DVC编解码框架。
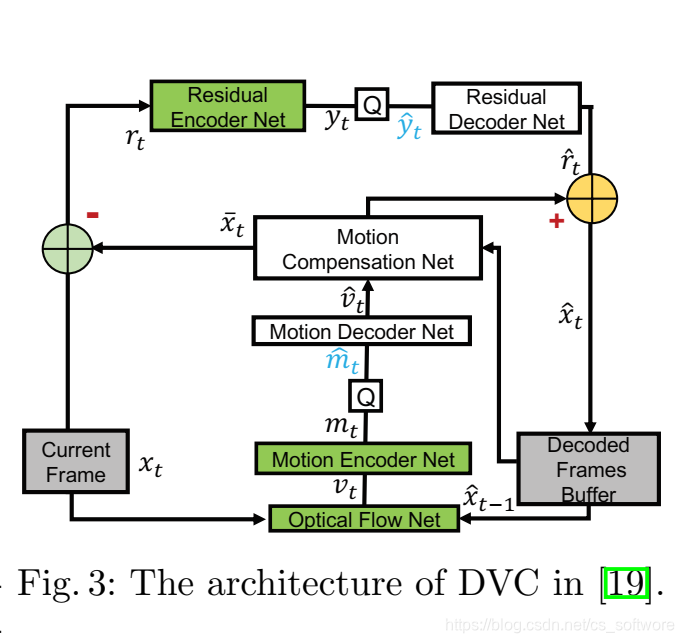
框架里有两个问题:(a)忽略重构时存在重构误差,对重构
有内在影响,从而导致误差扩散;(b)编码器参数固定,不依赖当前帧
,势必会影响推理阶段的编解码性能。
(2)针对错误传播问题,在训练阶段对率失真损失进行改进:
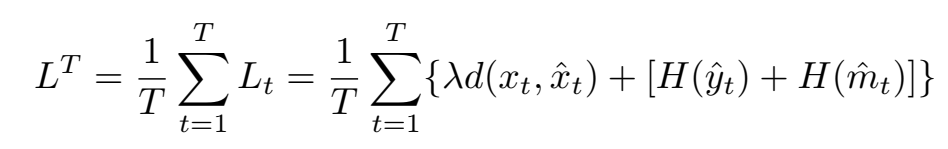
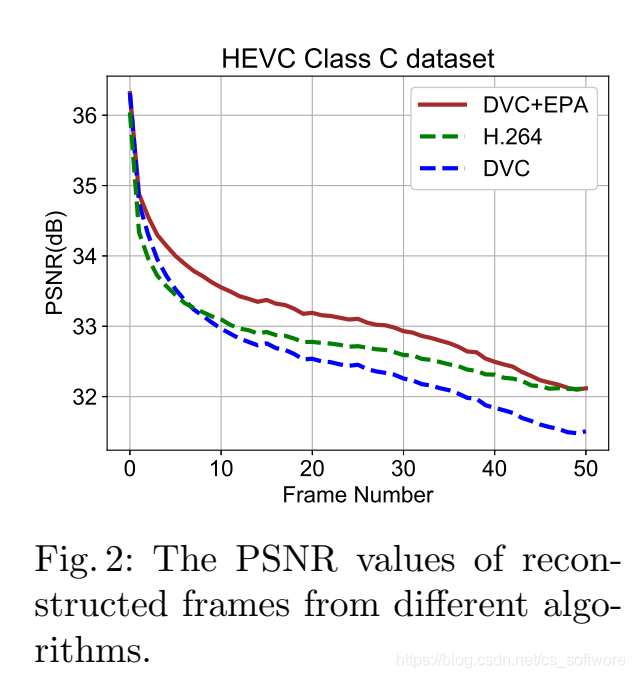
T指时间间隔,就是训练时选用T帧的平均率失真作为损失,本文选用5。从Fig2中可以看到,DVC+EPA的方法可以缓解错误传播。
提出的内容自适应和错误传播感知方法示意图如下
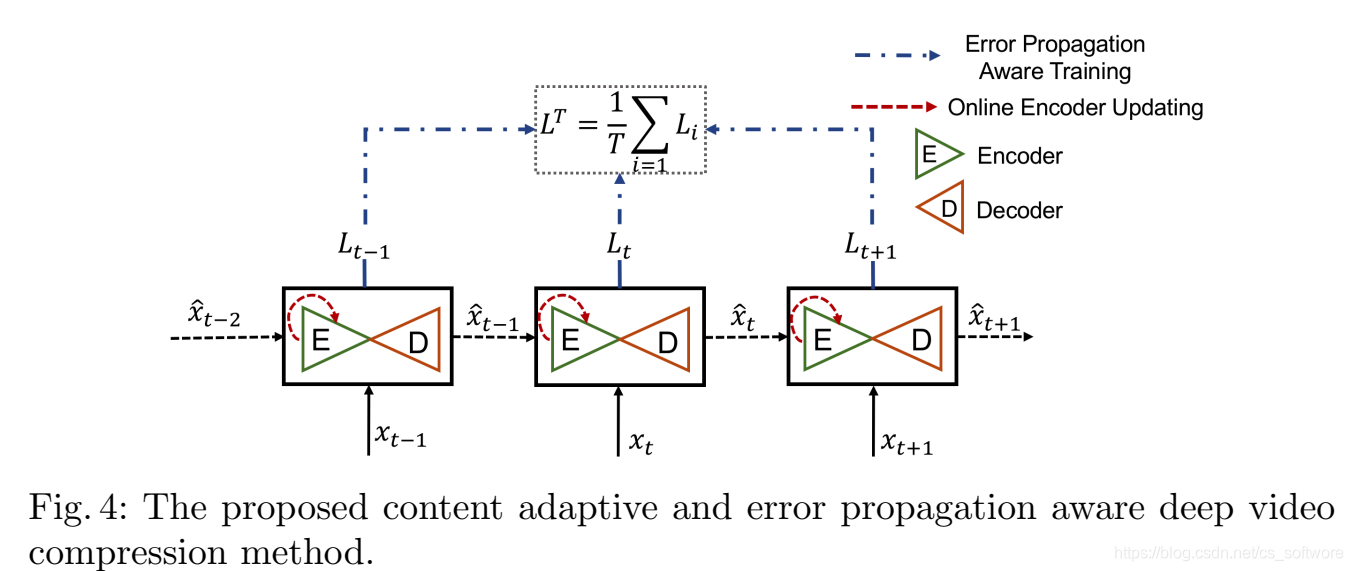
(3)编码器在线更新策略
编码端的CNN参数会根据帧的内容进行在线更新,保持解码端参数不变。在线更新算法:

本文最大迭代次数设置为10。这个算法就是固定解码器的参数,然后编码器的参数根据实际内容(测试集)进行更新。这样如果参数量比较大,进行10次前传和反向传播+参数更新,势必会增加很多编码端的负担,文献后面也提到,编码端的速度慢了5倍。
在线更新策略前后一些可视化对比,c和d是残差编码器参数在线更新前后的输出结果比对,e和f是光流结果比对,g和h是熵编码的结果比对。
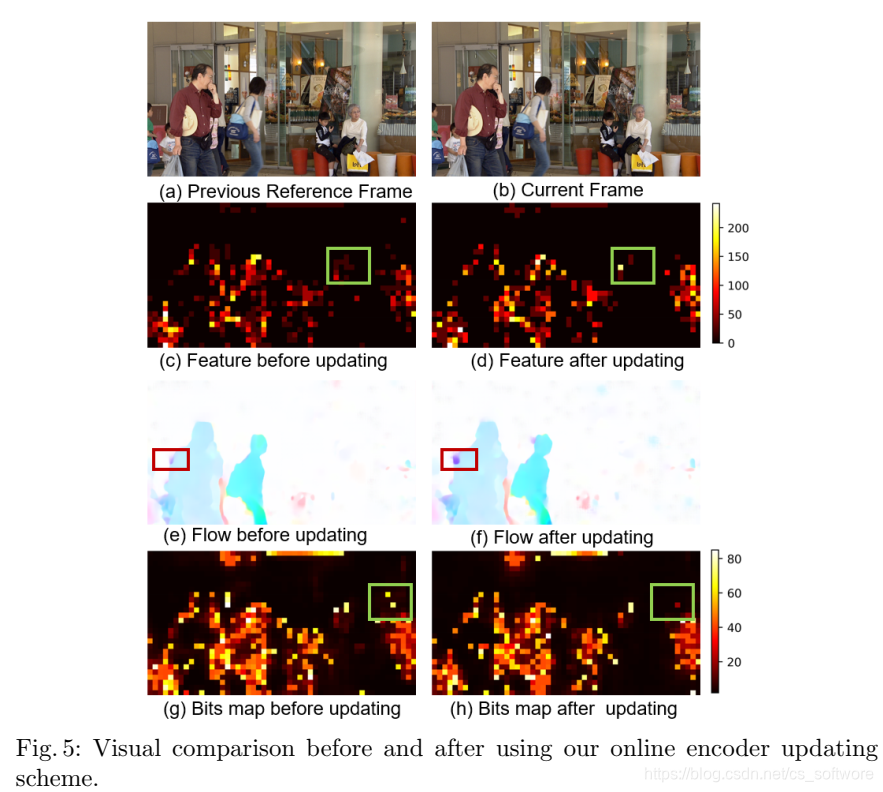
四、实验
1、一些细节
训练了四个码率的模型,即
率失真公式中的
采用256,512, 1024, 2048。主帧采用经典的Ball´e的算法。个人觉得,DVC和主帧模型都还没有码率控制版本,即一个模型通过调参进行码率控制,目前已经有部分文献开始研究图片和视频编解码的码率控制问题,我们在实践中也复现了一些码率控制的文献,但是都达不到单码率版本的编解码效果。
训练阶段图像分辨率采用256*256,学习率1e-4,采用Adam优化器。
2、比较
本文方法在MS-SSIM和PSNR指标与其他方法的比对如下:
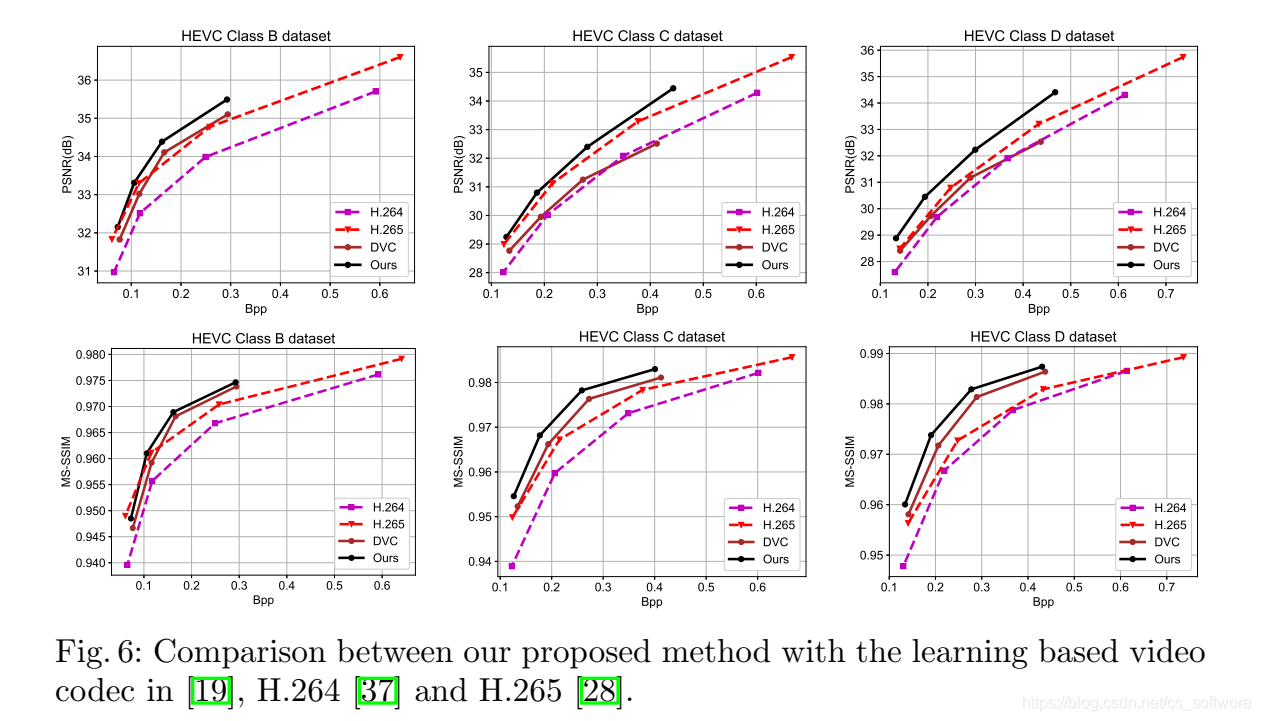
相对与H264算法,BDBR和BD-PSNR对比表现如下:
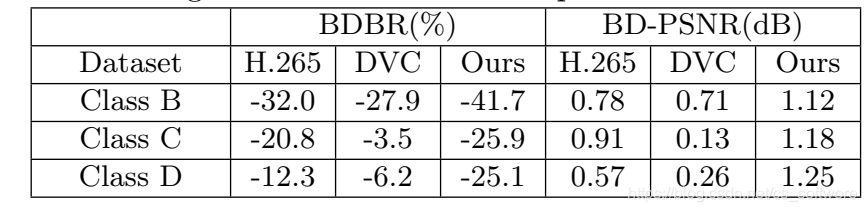
3、消融实验
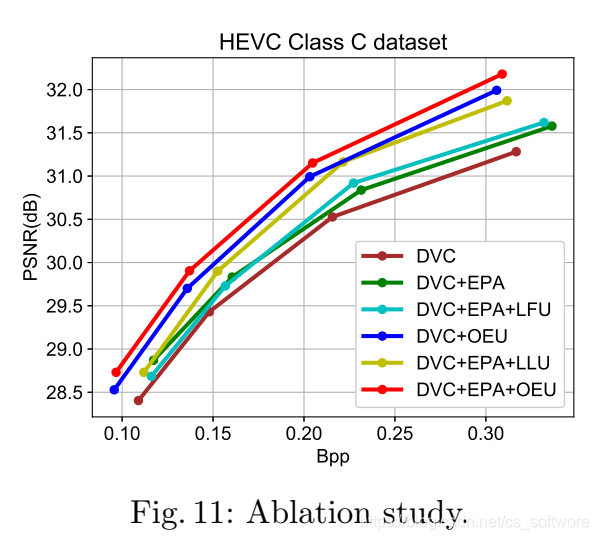
EPA表示训练阶段的错误传播感知策略,OEU表示在线更新策略,LFU表示latent features updating,文献‘Content adaptive optimization for neural image compression’中的策略。
五、结论
提出的错误传播感知策略可以有效缓解帧间预测的错误传播问题,编码端的在线更新策略可以自适应视频内容。本文提出的方法简单而有效。
六、我的一些想法
文献理解中间的一些想法已经穿插到了上文中。下面是一些总结性的想法:
本文的方法是对baseline算法DVC的改进,只是策略上的一些改进,而且结果上看只是对DVC有小幅提升(本身越到后面,提升难度越大),改进后在两个指标上全面超越了H265算法,在一篇文献中看到,H266算法比H265算法编解码性能提高了31.36%,诚然DVC已经比较优秀,但是可以看到,离H266还有很长的路要走。
DVC(包括本文的改进策略)是将传统混合编解码框架的各个部分都用深度学习替换,经过几天的学习,已经可以超越H265算法,深度学习在视频编解码任务上体现出了优势,但是DVC的上限能否达到或超过H266呢?想要大幅提高baseline的编码解码水平,应该要引入其它模块或对DVC架构的策略进行调整。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









