






Dify:一站式LLM应用开发平台,加速你的AI落地之旅
摘要
随着大型语言模型(LLM)技术的飞速发展,AI 应用的开发正成为技术前沿。然而,从模型选择到数据处理、再到应用部署与迭代,整个开发链路仍面临诸多挑战。Dify 作为一款开源的 LLM 应用开发平台,致力于通过其直观的界面和强大的功能,帮助开发者快速构建、测试和部署各种 AI 应用。本文将深入探讨 Dify 的核心功能、与其他平台的异同,并通过丰富的实践案例、部署指南和最佳实践,为中国 AI 开发者提供一份全面的 Dify 使用手册,助您高效地将创意转化为生产力。
目录
- 第一章:Dify 核心功能深度解析
- 第二章:Dify 与其他平台的对比
- 第三章:Dify 实战案例
- 第四章:Dify 部署与最佳实践
- 第五章:常见问题与注意事项
- 第六章:项目实施计划
- 第七章:知识体系梳理
- 总结
- 参考资料
第一章:Dify 核心功能深度解析
Dify 的设计理念是将复杂的 LLM 应用开发过程模块化、可视化,让开发者能够更专注于业务逻辑和创新。本章将详细介绍 Dify 的七大核心功能。
1.1 工作流:可视化构建AI应用逻辑
工作流是 Dify 的核心亮点之一,它允许开发者通过拖拽组件的方式,在画布上构建复杂的 AI 应用流程。无论是简单的问答机器人,还是多步骤的智能助手,都能通过工作流清晰地展现和执行。
实践示例:构建一个基础的RAG问答工作流
假设我们要构建一个企业内部知识库问答系统,用户提问后,系统能从预设文档中检索相关信息并结合LLM生成答案。
graph TD
A[用户提问] --> B{Dify工作流入口}
B --> C[文档检索 (RAG)]
C -- 检索结果 --> D{LLM生成答案}
D -- 答案 --> E[返回用户]
C -- 未检索到/低置信度 --> F[LLM尝试自由问答]
F -- 答案 --> E
subgraph Dify Workflow
C
D
F
end
注意事项:
- 工作流的设计应遵循模块化原则,每个节点职责明确
- 善用条件判断和并行处理,提高流程的灵活性
- 合理设置超时和重试机制,提高系统稳定性
1.2 全面的模型支持:自由选择LLM的强大引擎
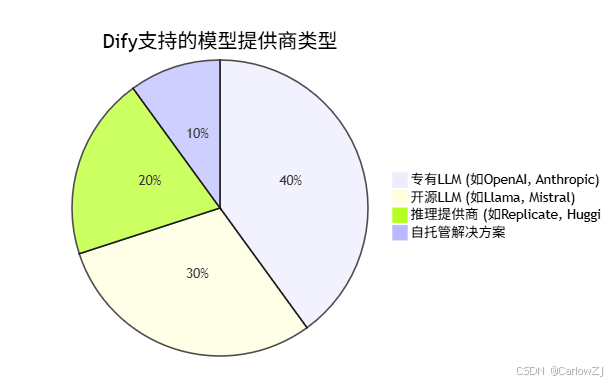
Dify 提供了对数百种专有和开源 LLMs 的无缝集成,涵盖 GPT、Mistral、Llama3 以及任何与 OpenAI API 兼容的模型。这意味着开发者可以根据应用场景、成本预算和性能需求,灵活选择最适合的底层模型。
模型提供商分布
最佳实践:模型选择策略
-
原型开发阶段
- 优先选择高通用性、易于访问的专有模型(如 GPT 系列)
- 快速验证想法和功能可行性
-
生产部署阶段
- 结合成本、性能、数据隐私等因素
- 考虑切换到更经济或可控的开源模型
- 通过推理提供商优化部署
1.3 Prompt IDE:提示工程利器,精雕细琢AI表达
Prompt IDE 提供了一个直观的界面,用于制作提示(Prompt)、比较不同模型的性能,并为基于聊天的应用程序添加额外功能,如文本转语音。
实践示例:优化RAG问答的提示
在 Prompt IDE 中,你可以通过调整系统提示(System Prompt)、用户提示(User Prompt)和上下文(Context)来优化模型输出。
# 示例:通过Dify API调用RAG应用
import requests
import json
def chat_with_dify_rag_app(query: str, app_id: str, api_key: str) -> dict:
"""
与Dify RAG应用进行交互的Python示例
:param query: 用户查询内容
:param app_id: Dify应用的ID
:param api_key: Dify应用的API Key
:return: 包含聊天响应的字典
"""
url = f"https://api.dify.ai/v1/workflows/{app_id}/run"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
payload = {
"inputs": {
"query": query
},
"response_mode": "streaming",
"user": "user-123"
}
try:
response = requests.post(url, headers=headers, data=json.dumps(payload), stream=True)
response.raise_for_status()
full_response = ""
for line in response.iter_lines():
if line:
decoded_line = line.decode('utf-8')
if decoded_line.startswith('data:'):
try:
event_data = json.loads(decoded_line[5:])
if event_data.get("event") == "text":
print(f"收到文本: {event_data.get('answer')}")
full_response += event_data.get('answer', '')
elif event_data.get("event") == "message_end":
print(f"会话结束。Token使用: {event_data.get('metadata',{}).get('usage','')}")
break
except json.JSONDecodeError as e:
print(f"JSON解析错误: {e}")
return {"success": True, "answer": full_response}
except requests.exceptions.RequestException as e:
print(f"API请求失败: {e}")
return {"success": False, "error": str(e)}
提示工程最佳实践:
-
系统提示设计
- 明确定义AI助手的角色和能力范围
- 设置适当的语气和风格指南
- 包含必要的安全限制和道德准则
-
用户提示优化
- 使用清晰、具体的指令
- 提供必要的上下文信息
- 设置合理的输出格式要求
-
上下文管理
Dify 提供了广泛的 RAG (Retrieval Augmented Generation) 功能,涵盖从文档摄入到检索的所有环节,开箱即用地支持 PDF、PPT 等常见文档格式的文本提取。RAG 显著提高了 LLM 在特定领域知识上的准确性和可靠性。
文档上传与知识库构建
# 示例:通过Dify API上传文档到知识库
import requests
import json
def upload_document_to_dify_dataset(file_path: str, dataset_id: str, api_key: str) -> dict:
"""
将文档上传到Dify数据集(知识库)的Python示例
:param file_path: 本地文档文件路径
:param dataset_id: Dify数据集的ID
:param api_key: Dify应用的API Key
:return: 包含上传结果的字典
"""
url = f"https://api.dify.ai/v1/datasets/{dataset_id}/documents/upload"
headers = {
"Authorization": f"Bearer {api_key}"
}
try:
with open(file_path, 'rb') as f:
files = {'file': (file_path.split('/')[-1], f, 'application/octet-stream')}
response = requests.post(url, headers=headers, files=files)
response.raise_for_status()
return response.json()
except FileNotFoundError:
print(f"错误: 文件 {file_path} 未找到。")
return {"success": False, "error": "文件未找到"}
except requests.exceptions.RequestException as e:
print(f"API请求失败: {e}")
return {"success": False, "error": str(e)}
RAG 最佳实践
-
文档预处理
- 文本清洗和标准化
- 智能分块策略
- 元数据提取和标记
-
向量化策略
- 选择合适的嵌入模型
- 优化向量维度
- 实现增量更新机制
-
检索优化
- 混合检索策略
- 相关性评分优化
- 上下文窗口管理
1.5 Agent 智能体:赋予AI行动力
Dify 支持基于 LLM 函数调用或 ReAct 框架定义 Agent,并允许添加预构建或自定义工具。Dify 提供了 50 多种内置工具,如谷歌搜索、DALL·E、Stable Diffusion 和 WolframAlpha 等。
Agent 工作流程
自定义工具开发示例
# 示例:自定义数据分析工具
from typing import Dict, Any
import pandas as pd
import matplotlib.pyplot as plt
class DataAnalysisTool:
def __init__(self):
self.name = "data_analysis"
self.description = "执行数据分析和可视化"
def execute(self, params: Dict[str, Any]) -> Dict[str, Any]:
"""
执行数据分析工具
:param params: 包含数据路径、分析类型等参数
:return: 分析结果
"""
try:
# 读取数据
df = pd.read_csv(params.get('data_path'))
# 根据分析类型执行不同操作
analysis_type = params.get('analysis_type')
if analysis_type == 'trend':
result = self._analyze_trend(df, params)
elif analysis_type == 'correlation':
result = self._analyze_correlation(df, params)
else:
raise ValueError(f"不支持的分析类型: {analysis_type}")
return {
"success": True,
"result": result
}
except Exception as e:
return {
"success": False,
"error": str(e)
}
def _analyze_trend(self, df: pd.DataFrame, params: Dict[str, Any]) -> Dict[str, Any]:
"""分析趋势"""
# 实现趋势分析逻辑
pass
def _analyze_correlation(self, df: pd.DataFrame, params: Dict[str, Any]) -> Dict[str, Any]:
"""分析相关性"""
# 实现相关性分析逻辑
pass
1.6 LLMOps:持续迭代与优化
Dify 提供了监控和分析应用程序日志与性能的功能。你可以根据生产数据和标注持续改进提示、数据集和模型,形成闭环的 LLMOps 流程。
LLMOps 工作流程
关键指标监控
-
性能指标
- 响应时间
- Token 使用量
- 并发处理能力
- 资源利用率
-
质量指标
- 答案准确率
- 用户满意度
- 错误率统计
- 异常模式识别
-
成本指标
- API 调用成本
- 计算资源消耗
- 存储使用量
- 带宽消耗
1.7 后端即服务:无缝集成
Dify 的所有功能都带有相应的 API,这意味着你可以轻松地将 Dify 的强大 AI 能力集成到自己的业务逻辑中。
系统架构图
API 集成最佳实践
Dify 在 LLM 应用开发领域独树一帜,它结合了多种开发模式的优势,提供了更全面的解决方案。让我们通过详细的对比表格来了解 Dify 与其他主流平台的差异。
2.1 功能对比表
| 功能 | Dify.AI | LangChain | Flowise | OpenAI Assistant API |
|---|---|---|---|---|
| 编程方法 | API + 应用程序导向 | Python 代码 | 应用程序导向 | API 导向 |
| 支持的 LLMs | 丰富多样 | 丰富多样 | 丰富多样 | 仅限 OpenAI |
| RAG 引擎 | ✅ | ✅ | ✅ | ✅ |
| Agent | ✅ | ✅ | ❌ | ✅ |
| 工作流 | ✅ | ❌ | ✅ | ❌ |
| 可观测性 | ✅ | ✅ | ❌ | ❌ |
| 企业功能(SSO/访问控制) | ✅ | ❌ | ❌ | ❌ |
| 本地部署 | ✅ | ✅ | ✅ | ❌ |
2.2 平台特性分析
Dify 的优势
-
全栈解决方案
- 提供从开发到部署的完整工具链
- 内置企业级功能
- 支持多种部署方式
-
开发效率
- 可视化工作流设计
- 丰富的预置组件
- 完善的 API 支持
-
运维能力
- 内置监控和日志
- 性能分析工具
- 版本管理功能
其他平台特点
-
LangChain
- 优势:高度灵活,可定制性强
- 劣势:需要较多编码工作,缺乏可视化界面
-
Flowise
- 优势:可视化工作流,易于上手
- 劣势:功能相对简单,缺乏企业级特性
-
OpenAI Assistant API
- 优势:与 OpenAI 生态深度集成
- 劣势:仅支持 OpenAI 模型,功能相对局限
2.3 选择建议
根据不同场景选择合适的平台:
-
快速原型开发
- 推荐:Dify 或 Flowise
- 原因:可视化界面,快速实现想法
-
企业级应用
- 推荐:Dify
- 原因:完整的企业功能,支持私有部署
-
高度定制化需求
- 推荐:LangChain
- 原因:提供最大的灵活性
-
OpenAI 生态应用
- 推荐:OpenAI Assistant API
- 原因:与 OpenAI 服务深度集成
第三章:Dify 实战案例
本章将通过几个具体的实践案例,展示 Dify 在不同场景下的应用潜力。
3.1 智能客服机器人
场景描述
某电商平台希望通过 Dify 构建一个智能客服机器人,自动回答用户关于订单、商品、售后等常见问题,并能根据需要引导用户联系人工客服。
实现方案
-
知识库构建
# 示例:批量上传客服知识库文档 def upload_customer_service_docs(): docs = [ "order_policy.md", "return_policy.md", "product_guide.md", "faq.md" ] for doc in docs: result = upload_document_to_dify_dataset( file_path=f"docs/{doc}", dataset_id="customer_service_kb", api_key=API_KEY ) print(f"上传 {doc}: {'成功' if result['success'] else '失败'}") -
工作流设计
-
Prompt 优化
# 系统提示示例 system_prompt = """ 你是一个专业的电商客服助手,你的职责是: 1. 准确回答用户关于订单、商品、售后等问题 2. 使用友好、专业的语气 3. 当无法确定答案时,主动引导用户联系人工客服 4. 保持回答简洁明了 """
3.2 内容生成与编辑助手
场景描述
某内容创作团队希望利用 AI 辅助文章撰写、摘要生成、内容润色等。
实现方案
-
多模型工作流
-
自定义工具集成
# 示例:内容质量检查工具 class ContentQualityChecker: def __init__(self): self.name = "content_quality_check" def check(self, content: str) -> dict: return { "readability_score": self._calculate_readability(content), "grammar_errors": self._check_grammar(content), "seo_score": self._analyze_seo(content) }
3.3 数据分析 Agent
场景描述
数据分析师希望有一个 AI 助手,能够理解自然语言的数据分析需求,并自动执行数据查询、图表生成等操作。
实现方案
-
Agent 定义
# 示例:数据分析 Agent 配置 data_analysis_agent = { "name": "data_analyst", "description": "智能数据分析助手", "tools": [ "sql_query", "data_visualization", "statistical_analysis", "report_generation" ], "model": "gpt-4", "temperature": 0.3 } -
工作流程
第四章:Dify 部署与最佳实践
本章将详细介绍 Dify 的部署方法和最佳实践,帮助您快速搭建和优化 Dify 环境。
4.1 快速启动:Docker Compose 部署
系统要求
- CPU >= 2 Core
- RAM >= 4 GiB
- 已安装 Docker 和 Docker Compose
部署步骤
-
准备环境
# 克隆仓库 git clone https://github.com/langgenius/dify.git cd dify/docker # 复制环境变量文件 cp .env.example .env -
配置环境变量
# .env 文件关键配置 # 数据库配置 DB_HOST=localhost DB_PORT=5432 DB_USERNAME=postgres DB_PASSWORD=your_secure_password DB_DATABASE=dify # Redis配置 REDIS_HOST=localhost REDIS_PORT=6379 REDIS_PASSWORD=your_redis_password # API密钥配置 API_KEY_SECRET=your_api_key_secret -
启动服务
# 启动所有服务 docker compose up -d # 查看服务状态 docker compose ps -
访问控制台
- 打开浏览器访问
http://localhost/install - 按照引导完成初始化设置
- 打开浏览器访问
4.2 生产环境部署
Kubernetes 部署
-
使用 Helm Chart
# 添加 Helm 仓库 helm repo add dify https://charts.dify.ai # 安装 Dify helm install dify dify/dify \ --namespace dify \ --create-namespace \ --set global.domain=your-domain.com -
使用 YAML 文件
# dify-deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: dify-web namespace: dify spec: replicas: 3 selector: matchLabels: app: dify-web template: metadata: labels: app: dify-web spec: containers: - name: dify-web image: langgenius/dify-web:latest ports: - containerPort: 3000
云平台部署
-
AWS 部署
-
Azure 部署
4.3 最佳实践
1. 系统配置优化
-
数据库优化
-- PostgreSQL 优化配置 ALTER SYSTEM SET max_connections = '200'; ALTER SYSTEM SET shared_buffers = '2GB'; ALTER SYSTEM SET effective_cache_size = '6GB'; ALTER SYSTEM SET maintenance_work_mem = '512MB'; -
Redis 优化
# redis.conf maxmemory 2gb maxmemory-policy allkeys-lru appendonly yes -
Nginx 配置
# nginx.conf worker_processes auto; worker_rlimit_nofile 65535; events { worker_connections 65535; multi_accept on; } http { keepalive_timeout 65; keepalive_requests 100; client_max_body_size 50M; }
2. 安全配置
-
API 安全
# API 认证中间件示例 from functools import wraps from flask import request, abort def require_api_key(f): @wraps(f) def decorated(*args, **kwargs): api_key = request.headers.get('X-API-Key') if not api_key or not validate_api_key(api_key): abort(401) return f(*args, **kwargs) return decorated -
数据加密
# 敏感数据加密示例 from cryptography.fernet import Fernet class DataEncryption: def __init__(self): self.key = Fernet.generate_key() self.cipher_suite = Fernet(self.key) def encrypt(self, data: str) -> bytes: return self.cipher_suite.encrypt(data.encode()) def decrypt(self, encrypted_data: bytes) -> str: return self.cipher_suite.decrypt(encrypted_data).decode()
3. 监控与告警
-
Prometheus 配置
# prometheus.yml global: scrape_interval: 15s scrape_configs: - job_name: 'dify' static_configs: - targets: ['dify-web:3000'] -
Grafana 仪表板
4. 备份策略
-
数据库备份
# 自动备份脚本 #!/bin/bash BACKUP_DIR="/backup/postgres" TIMESTAMP=$(date +%Y%m%d_%H%M%S) pg_dump -U postgres dify > "$BACKUP_DIR/dify_$TIMESTAMP.sql" -
文件备份
# 文件备份脚本 #!/bin/bash BACKUP_DIR="/backup/files" TIMESTAMP=$(date +%Y%m%d_%H%M%S) tar -czf "$BACKUP_DIR/dify_files_$TIMESTAMP.tar.gz" /data/dify
4.4 性能优化
1. 缓存策略
-
Redis 缓存配置
# Redis 缓存示例 import redis from functools import lru_cache class CacheManager: def __init__(self): self.redis_client = redis.Redis( host='localhost', port=6379, password='your_password' ) @lru_cache(maxsize=1000) def get_cached_data(self, key: str) -> dict: return self.redis_client.get(key) -
内存缓存
# 内存缓存示例 from cachetools import TTLCache cache = TTLCache(maxsize=100, ttl=300) # 5分钟过期 @cache.memoize() def expensive_operation(param): # 耗时操作 return result
2. 负载均衡
-
Nginx 负载均衡配置
upstream dify_backend { server dify-web-1:3000; server dify-web-2:3000; server dify-web-3:3000; } server { listen 80; server_name your-domain.com; location / { proxy_pass http://dify_backend; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; } } -
健康检查
# 健康检查示例 from healthcheck import HealthCheck health = HealthCheck() def check_database(): try: # 数据库连接检查 return True, "数据库连接正常" except Exception as e: return False, f"数据库连接异常: {str(e)}" health.add_check(check_database)第五章:常见问题与注意事项
本章将解答使用 Dify 过程中的常见问题,并提供重要的注意事项。
5.1 常见问题 (FAQ)
1. 基础问题
Q1: Dify 适合哪些类型的开发者?
A1: Dify 特别适合以下开发者:
- 希望快速构建和部署 LLM 应用的全栈工程师
- 需要可视化开发工具的产品经理
- 想要尝试 AI 应用开发的初学者
- 需要企业级 AI 解决方案的技术团队
Q2: Dify 对硬件要求高吗?
A2: Dify 的硬件要求相对灵活:
- 开发环境:最低 2 核 CPU,4GB RAM
- 生产环境:根据并发量和模型调用量动态调整
- 建议配置:4 核 CPU,8GB RAM 以上
Q3: 我可以贡献代码给 Dify 吗?
A3: 当然可以!Dify 欢迎社区贡献:
- 提交 Bug 报告
- 新功能建议
- 代码贡献
- 文档翻译
- 社区支持
2. 技术问题
Q4: 如何处理 API 调用超时?
A4: 建议采用以下策略:
# API 调用重试示例
from tenacity import retry, stop_after_attempt, wait_exponential
@retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=4, max=10))
def call_dify_api(endpoint: str, data: dict) -> dict:
try:
response = requests.post(endpoint, json=data, timeout=30)
response.raise_for_status()
return response.json()
except requests.exceptions.Timeout:
print("请求超时,正在重试...")
raise
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
raise
Q5: 如何优化 RAG 检索效果?
A5: 可以从以下几个方面优化:
- 文档预处理
- 分块策略
- 向量化方法
- 检索算法
- 结果重排序
# RAG 优化示例
class RAGOptimizer:
def __init__(self):
self.chunk_size = 1000
self.chunk_overlap = 200
def preprocess_document(self, text: str) -> str:
# 文本清洗
text = self._clean_text(text)
# 分块
chunks = self._split_text(text)
# 向量化
vectors = self._vectorize(chunks)
return vectors
def _clean_text(self, text: str) -> str:
# 实现文本清洗逻辑
pass
def _split_text(self, text: str) -> list:
# 实现文本分块逻辑
pass
def _vectorize(self, chunks: list) -> list:
# 实现向量化逻辑
pass
5.2 注意事项
1. 安全注意事项
- API 密钥管理
# API 密钥管理示例
import os
from dotenv import load_dotenv
class APIKeyManager:
def __init__(self):
load_dotenv()
self.api_key = os.getenv('DIFY_API_KEY')
def validate_key(self) -> bool:
if not self.api_key:
raise ValueError("API 密钥未设置")
return True
def rotate_key(self) -> None:
# 实现密钥轮换逻辑
pass
- 数据安全
# 数据加密示例
from cryptography.fernet import Fernet
class DataSecurity:
def __init__(self):
self.key = Fernet.generate_key()
self.cipher_suite = Fernet(self.key)
def encrypt_sensitive_data(self, data: str) -> bytes:
return self.cipher_suite.encrypt(data.encode())
def decrypt_sensitive_data(self, encrypted_data: bytes) -> str:
return self.cipher_suite.decrypt(encrypted_data).decode()
2. 性能注意事项
- 资源监控
# 资源监控示例
import psutil
import time
class ResourceMonitor:
def __init__(self):
self.threshold = 80 # 资源使用率阈值
def check_resources(self) -> dict:
return {
'cpu_percent': psutil.cpu_percent(),
'memory_percent': psutil.virtual_memory().percent,
'disk_percent': psutil.disk_usage('/').percent
}
def is_overloaded(self) -> bool:
resources = self.check_resources()
return any(v > self.threshold for v in resources.values())
- 并发控制
# 并发控制示例
from threading import Semaphore
import asyncio
class ConcurrencyManager:
def __init__(self, max_concurrent: int = 10):
self.semaphore = Semaphore(max_concurrent)
async def execute_with_limit(self, coro):
async with self.semaphore:
return await coro
3. 成本控制
- Token 使用监控
# Token 使用监控示例
class TokenMonitor:
def __init__(self):
self.token_usage = {}
def track_usage(self, model: str, tokens: int):
if model not in self.token_usage:
self.token_usage[model] = 0
self.token_usage[model] += tokens
def get_usage_report(self) -> dict:
return self.token_usage
- 成本估算
# 成本估算示例
class CostEstimator:
def __init__(self):
self.token_costs = {
'gpt-4': 0.03, # 每千个token的成本
'gpt-3.5-turbo': 0.002
}
def estimate_cost(self, model: str, tokens: int) -> float:
if model not in self.token_costs:
raise ValueError(f"未知模型: {model}")
return (tokens / 1000) * self.token_costs[model]
5.3 故障排除指南
1. 常见错误处理
# 错误处理示例
class DifyErrorHandler:
def __init__(self):
self.error_log = []
def handle_error(self, error: Exception) -> dict:
error_info = {
'type': type(error).__name__,
'message': str(error),
'timestamp': time.time()
}
self.error_log.append(error_info)
return self._get_error_response(error_info)
def _get_error_response(self, error_info: dict) -> dict:
# 根据错误类型返回适当的响应
error_handlers = {
'ConnectionError': self._handle_connection_error,
'TimeoutError': self._handle_timeout_error,
'ValueError': self._handle_value_error
}
handler = error_handlers.get(error_info['type'], self._handle_unknown_error)
return handler(error_info)
2. 日志管理
# 日志管理示例
import logging
from logging.handlers import RotatingFileHandler
class LogManager:
def __init__(self, log_file: str = 'dify.log'):
self.logger = logging.getLogger('dify')
self.logger.setLevel(logging.INFO)
handler = RotatingFileHandler(
log_file,
maxBytes=10*1024*1024, # 10MB
backupCount=5
)
formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
handler.setFormatter(formatter)
self.logger.addHandler(handler)
def log_error(self, error: Exception):
self.logger.error(f"错误: {str(error)}", exc_info=True)
def log_info(self, message: str):
self.logger.info(message)
5.4 升级与维护
1. 版本升级
# 升级脚本示例
#!/bin/bash
# 备份数据
backup_data() {
echo "开始备份数据..."
# 实现备份逻辑
}
# 更新代码
update_code() {
echo "开始更新代码..."
git pull origin main
}
# 更新依赖
update_dependencies() {
echo "开始更新依赖..."
pip install -r requirements.txt
}
# 重启服务
restart_services() {
echo "开始重启服务..."
docker compose down
docker compose up -d
}
# 主流程
main() {
backup_data
update_code
update_dependencies
restart_services
echo "升级完成!"
}
main
2. 定期维护
# 维护任务示例
from apscheduler.schedulers.background import BackgroundScheduler
class MaintenanceManager:
def __init__(self):
self.scheduler = BackgroundScheduler()
def schedule_maintenance(self):
# 每天凌晨2点执行清理任务
self.scheduler.add_job(
self.cleanup_old_logs,
'cron',
hour=2,
minute=0
)
# 每周日凌晨3点执行备份
self.scheduler.add_job(
self.backup_data,
'cron',
day_of_week='sun',
hour=3,
minute=0
)
self.scheduler.start()
def cleanup_old_logs(self):
# 实现日志清理逻辑
pass
def backup_data(self):
# 实现数据备份逻辑
pass
第六章:项目实施计划
本章将提供一个完整的 Dify 项目实施计划,帮助您更好地规划和管理项目。
6.1 项目时间线
6.2 资源分配
1. 人力资源
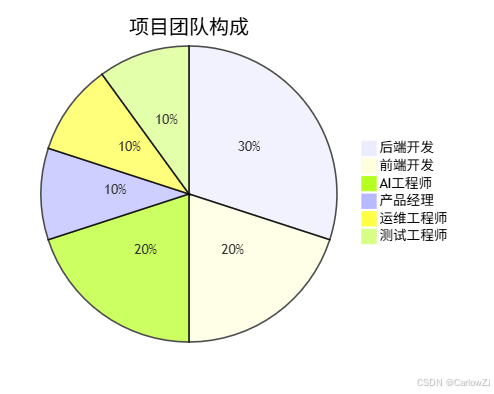
2. 硬件资源
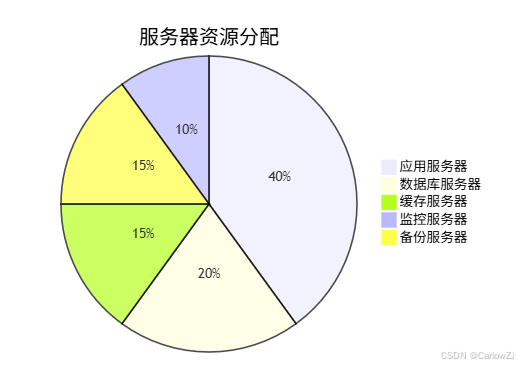
6.3 风险管理
1. 风险识别与应对
| 风险类型 | 风险描述 | 影响程度 | 应对策略 |
|---|---|---|---|
| 技术风险 | LLM API 不稳定 | 高 | 实现降级方案,准备备用模型 |
| 安全风险 | 数据泄露 | 高 | 实施加密,访问控制 |
| 成本风险 | Token 使用超预算 | 中 | 设置使用限制,监控告警 |
| 性能风险 | 响应时间过长 | 中 | 优化缓存,负载均衡 |
2. 风险监控
# 风险监控示例
class RiskMonitor:
def __init__(self):
self.risk_metrics = {
'api_stability': 0,
'security_incidents': 0,
'cost_usage': 0,
'performance_metrics': {}
}
def monitor_api_stability(self):
# 监控 API 稳定性
pass
def monitor_security(self):
# 监控安全事件
pass
def monitor_costs(self):
# 监控成本使用
pass
def monitor_performance(self):
# 监控性能指标
pass
6.4 质量保证
1. 测试计划
2. 测试用例示例
# 测试用例示例
import unittest
class DifyAPITestCase(unittest.TestCase):
def setUp(self):
self.api_client = DifyAPIClient()
def test_chat_completion(self):
response = self.api_client.chat_completion(
messages=[{"role": "user", "content": "Hello"}]
)
self.assertIsNotNone(response)
self.assertIn('content', response)
def test_rag_retrieval(self):
response = self.api_client.rag_retrieval(
query="测试查询",
top_k=5
)
self.assertIsNotNone(response)
self.assertIsInstance(response, list)
self.assertLessEqual(len(response), 5)
6.5 部署策略
1. 部署流程
2. 部署检查清单
# 部署检查清单
class DeploymentChecklist:
def __init__(self):
self.checklist = {
'pre_deployment': [
'代码审查完成',
'测试用例通过',
'性能测试达标',
'安全扫描通过'
],
'deployment': [
'备份数据',
'更新配置',
'部署代码',
'验证服务'
],
'post_deployment': [
'监控告警',
'日志检查',
'用户反馈'
]
}
def run_checklist(self, phase: str) -> bool:
if phase not in self.checklist:
raise ValueError(f"未知阶段: {phase}")
for item in self.checklist[phase]:
if not self._check_item(item):
return False
return True
def _check_item(self, item: str) -> bool:
# 实现具体检查逻辑
pass
6.6 运维支持
1. 监控系统
# 监控系统示例
class MonitoringSystem:
def __init__(self):
self.metrics = {}
def collect_metrics(self):
# 收集系统指标
self.metrics.update({
'cpu_usage': self._get_cpu_usage(),
'memory_usage': self._get_memory_usage(),
'disk_usage': self._get_disk_usage(),
'api_latency': self._get_api_latency()
})
def check_alerts(self):
# 检查告警条件
for metric, value in self.metrics.items():
if self._is_alert_condition(metric, value):
self._send_alert(metric, value)
def _is_alert_condition(self, metric: str, value: float) -> bool:
# 实现告警条件判断
pass
def _send_alert(self, metric: str, value: float):
# 实现告警发送
pass
2. 日志管理
# 日志管理示例
class LogManagement:
def __init__(self):
self.log_handlers = {}
def setup_logging(self):
# 设置日志处理器
self.log_handlers.update({
'application': self._setup_app_logger(),
'access': self._setup_access_logger(),
'error': self._setup_error_logger()
})
def rotate_logs(self):
# 日志轮转
for handler in self.log_handlers.values():
handler.doRollover()
def analyze_logs(self):
# 日志分析
pass
6.7 项目文档
1. 文档结构
2. 文档管理
# 文档管理示例
class DocumentationManager:
def __init__(self):
self.docs = {}
def update_doc(self, doc_type: str, content: str):
self.docs[doc_type] = content
self._save_doc(doc_type)
def get_doc(self, doc_type: str) -> str:
return self.docs.get(doc_type, '')
def _save_doc(self, doc_type: str):
# 实现文档保存逻辑
pass
第七章:知识体系梳理
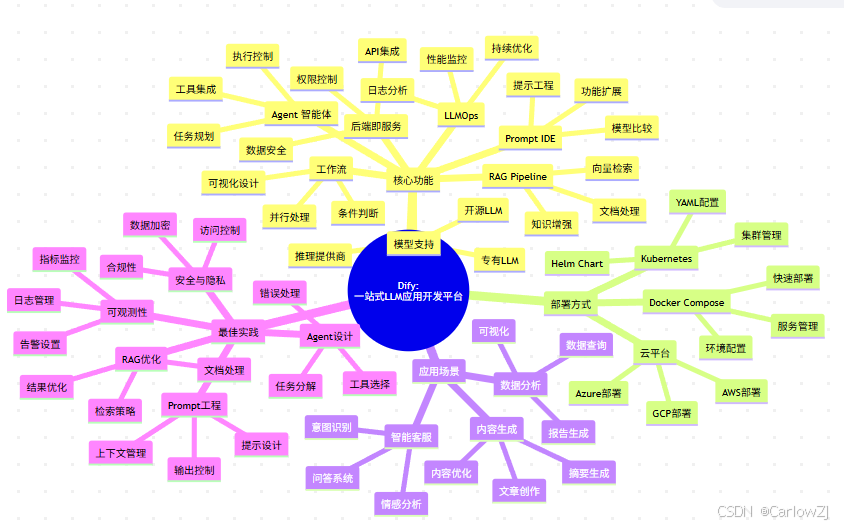
本章将通过思维导图、架构图等方式,帮助读者更好地理解 Dify 的知识体系。
7.1 核心概念思维导图
mindmap
root((Dify: 一站式LLM应用开发平台))
核心功能
工作流
可视化设计
条件判断
并行处理
模型支持
专有LLM
开源LLM
推理提供商
Prompt IDE
提示工程
模型比较
功能扩展
RAG Pipeline
文档处理
向量检索
知识增强
Agent 智能体
工具集成
任务规划
执行控制
LLMOps
性能监控
日志分析
持续优化
后端即服务
API集成
权限控制
数据安全
部署方式
Docker Compose
快速部署
环境配置
服务管理
Kubernetes
Helm Chart
YAML配置
集群管理
云平台
AWS部署
Azure部署
GCP部署
应用场景
智能客服
问答系统
意图识别
情感分析
内容生成
文章创作
摘要生成
内容优化
数据分析
数据查询
可视化
报告生成
最佳实践
Prompt工程
提示设计
上下文管理
输出控制
RAG优化
文档处理
检索策略
结果优化
Agent设计
工具选择
任务分解
错误处理
可观测性
指标监控
日志管理
告警设置
安全与隐私
数据加密
访问控制
合规性
7.2 系统架构图
7.3 技术栈图谱
7.4 学习路径图
总结
Dify 作为一款开源的 LLM 应用开发平台,通过其强大的功能和直观的界面,极大地降低了 AI 应用的开发门槛。本文从核心功能、平台对比、实战案例、部署实践、常见问题、项目规划到知识体系,全面介绍了 Dify 的使用方法和最佳实践。
关键要点回顾
-
核心功能
- 可视化工作流设计
- 全面的模型支持
- 强大的 RAG 能力
- 灵活的 Agent 系统
- 完善的 LLMOps 功能
-
部署方案
- Docker Compose 快速部署
- Kubernetes 生产部署
- 云平台一键部署
-
最佳实践
- Prompt 工程优化
- RAG 系统调优
- Agent 设计原则
- 安全与性能保障
-
项目规划
- 清晰的时间线
- 合理的资源分配
- 完善的风险管理
- 系统的质量保证
未来展望
-
技术演进
- 更多模型支持
- 更强大的工作流
- 更智能的 Agent
- 更完善的工具链
-
生态发展
- 社区贡献
- 插件系统
- 应用市场
- 企业服务
-
应用场景
- 垂直领域深化
- 新场景探索
- 跨领域融合
- 创新应用开发
参考资料
-
官方资源
-
技术文档
-
社区资源
-
学习资源



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











