







本文来源公众号“集智书童”,仅用于学术分享,侵权删,干货满满。
原文链接:同济提出简化 Transformer结构:在RTX3090上实现CLIP的轻量级训练 !

对比语言图像预训练(CLIP)因其卓越的零样本性能和优秀的迁移能力而受到了广泛关注。然而,训练这样的大型模型通常需要大量的计算和存储,这对一般用户(拥有消费级计算机)来说是一个障碍。
为了应对这一观察,本文探讨了如何在仅使用一块Nvidia RTX3090 GPU和一兆字节存储空间的情况下实现竞争性能。
一方面,作者简化了 Transformer 块结构,并将权重继承与多阶段知识蒸馏(WIKD)相结合,从而减少了参数并提高了训练和部署期间的推理速度。另一方面,面对小数据集带来的收敛挑战,作者为每个样本生成合成字幕作为数据增强,并设计了一种新颖的配对匹配(PM)损失,以充分利用正负图像文本对之间的区分。
大量实验表明,作者的模型可以在数据量-参数-精度之间实现新的最先进权衡,这可能进一步在相关研究社区中普及CLIP模型。
1 Introduction
预训练的大型图像文本基础模型,如对比语言图像预训练(CLIP)模型[28],最近在计算机视觉和自然语言处理领域引起了广泛关注。这些模型在广泛的下游任务上表现出出色的零样本性能和鲁棒性,例如图像文本检索和分类(朱等,2023年)。然而,CLIP类模型的巨大计算和存储成本阻碍了它们的进一步普及。例如,MobileCLIP [33]在256xA100 GPU上训练,全局批量为65,536,相应的数据集 DataCompDR-1B需要140 TB的本地存储空间。此外,巨大的参数大小(例如,CLIP-B/16模型[28]包含86.2M个图像编码器参数和63.4M个文本编码器参数)导致了推理延迟的增加,这为部署在计算资源有限的设备上带来了挑战。这些缺陷为没有足够计算资源和数据集的一般用户参与大规模模型的训练和部署设置了障碍。
在实际应用中,消费级计算机的GPU内存通常不超过24GB(例如,Nvidia RTX 3090),存储容量可能小于1TB。在这样资源限制的背景下训练CLIP类似的模型,需要解决两个主要问题。首先,必须尽可能减少需要训练的参数数量,同时保留尽可能多的现有模型知识。其次,小型数据集需要适当扩充,并需要开发更有效的方法,充分利用图像文本对在有限样本内的内部关联。
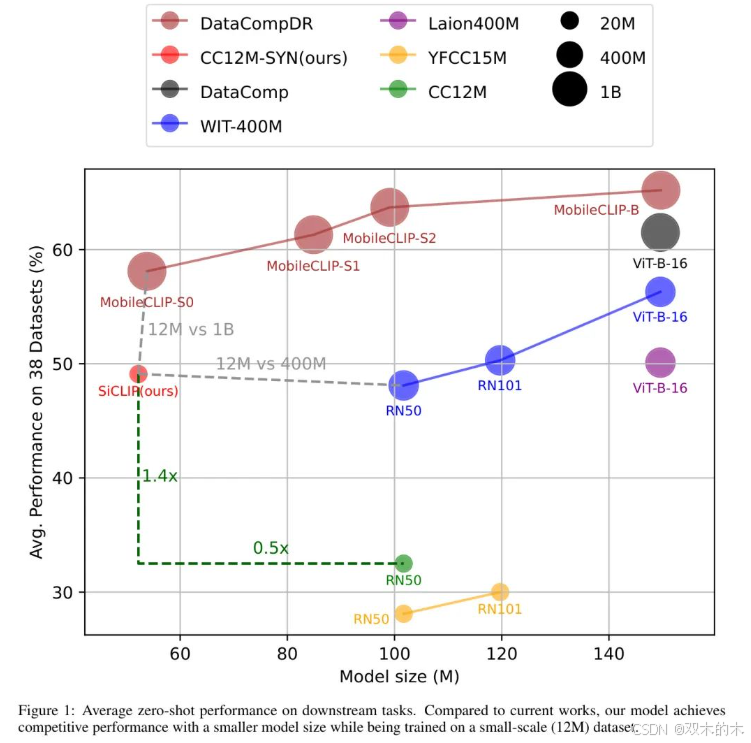
在这篇论文中,作者研究了如何使用仅有一个RTX3090显卡和1TB存储的轻量级CLIP模型训练方法,从而普及在消费级计算机上的CLIP类模型研究。为此,作者首先提出将传统的Transformer块简化为SAS-P块,并采用权重共享策略。然后,通过继承现有模型的权重并提取知识,可以进一步减少训练所需的参数数量。在数据集方面,作者选择广泛使用的CC12M [1]作为基础。该数据集不仅规模较小,而且标签质量低,这都为模型训练过程的收敛带来了困难。为了解决这个问题,作者对CC12M中的每个图像样本添加多个文本标签,创建了新的CC12M-SYN。此外,为了从这样的小数据集中提取有价值的信息,作者引入了Pair Matching (PM)损失,以帮助模型捕捉正负图像-文本对之间的区分。这些方法在作者的广泛实验中显著提高了模型训练的收敛速度。最后,通过在38个数据集上的性能比较(如图1所示),作者的提出的SiCLIP框架实现了新的数据量-参数-准确率权衡的最先进水平。
作者的贡献:本工作的贡献可以概括如下:
作者提出了一个系统性的框架,用于在消费级计算机上训练轻量级CLIP模型,包括数据集构建和相应的训练
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









