









本文来源公众号“大模型智能”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/U4usYj5bbizGfstqIOfETg
话不多说,先放数据下载链接。
HF: https://huggingface.co/datasets/Congliu/Chinese-DeepSeek-R1-Distill-data-110k
MS: https://modelscope.cn/datasets/liucong/Chinese-DeepSeek-R1-Distill-data-110k
该数据集为中文开源蒸馏满血R1的数据集,数据集中不仅包含math数据,还包括大量的通用类型数据,总数量为110K。
为什么开源这个数据?
R1的效果十分强大,并且基于R1蒸馏数据SFT的小模型也展现出了强大的效果,但之前群里问,貌似中文数据较少,基本上开源的R1蒸馏数据集都是英文数据,或者是非满血蒸馏数据。
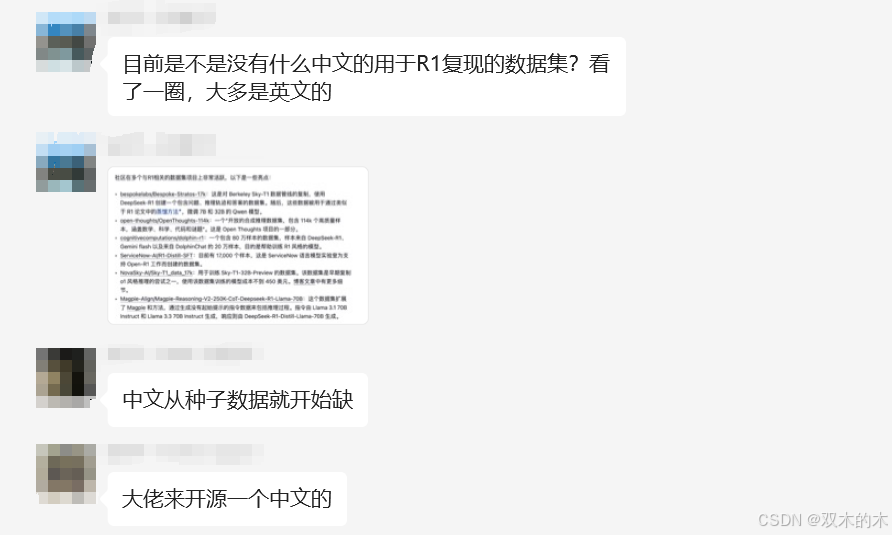
这不就来了嘛!!!
其实对于有机器人的人来说,其实110K数据蒸馏也蛮快的,但巧妇难为无米之炊,大多数人可能是没有那么多资源自己本地部署一个满血版R1,这也是为什么很多蒸馏数据用的32B、7B等进行蒸馏的原因。
开这个数据,就是希望对大家有用,反正无论是做纯SFT,还是复现R1,都要有数据嘛!!
但要说的一点是,因为有很多通用数据(R1的报告中展示,蒸馏模型中同时也使用了部分通用场景数据集),所以数据的整体长度可能没那么长,大家见谅哈!等有机会,我再开点超长数据的(机器在哭~)。
该中文数据集中的数据分布如下:
-
Math:共计36987个样本,
-
Exam:共计2440个样本,
-
STEM:共计12000个样本,
-
General:共计58573,包含弱智吧、逻辑推理、小红书、知乎、Chat等。
01 数据集蒸馏细节
数据的prompt源来自:
-
Haijian/Advanced-Math
-
gavinluo/applied_math
-
meta-math/GSM8K_zh
-
EduChat-Math
-
m-a-p/COIG-CQIA
-
m-a-p/neo_sft_phase2
-
hfl/stem_zh_instruction
同时为了方便大家溯源,在每条数据的repo_name字段中都加入的原始数据源repo。

在蒸馏过程中,按照DeepSeek-R1官方提供的细节,进行数据蒸馏。
-
不增加额外的系统提示词
-
设置temperature为0.6
-
如果为数学类型数据,则增加提示词,“请一步步推理,并把最终答案放到 \boxed{}。”
-
防止跳出思维模式,强制在每个输出的开头增加"\n",再开始生成数据
由于个人资源有限,所有数据的蒸馏均调用无问芯穹的企业版满血R1 API生成,在此由衷的感谢无问芯穹。
任务期间,保持稳定地运行300并发,持续运行近12个小时,性能稳定,推理速度最快25 tokens/s。没给我垃圾的并行代码带来太大的负担,哈哈哈~~~感恩!
其实数据蒸馏之前就常用,之前蒸馏GPT4,现在改成蒸馏DeepSeek-R1了。
DS就像是一条鲇鱼,搅浑了开源和闭源这摊死水,前两天百度先宣布免费,再宣布开源。OpenAI同时也是坐不住了,先开发o1的思维链(总结版),后面也不挤牙膏了,说马上来GPT4.5和GPT5。Grok3明天也来了,所以开源越来越好啦~~
02 写在最后
开的这个数据集会有些不完善的地方,毕竟没搞那么久,但希望大家不喜勿喷!
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 268
268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









