









本文来源公众号“Zilliz”,仅用于学术分享,侵权删,干货满满。
原文链接:风口|继MoE、MCP与A2A之后,下一个模型协作风口是MoA
前言
真的存在所谓的SOTA模型吗?
答案是,如果针对榜单而言,那答案是确定的。
如果针对现实的落地场景,那么基于不同的数据集训练的大模型必定是各有所长的。
有些大语言模型擅长解决数学问题,有些适合创作,而另一些则更适合编码。
面对一些涉及多领域应用场景时,相比所谓的SOTA模型,更重要的是如何让各有擅长的大模型之间,更好的协作配合。
而针对这一命题:从MoE到MoA,从MCP到A2A,多专家协作、多模型协作、模型与工具协作、智能体之间的协作,已经成为决定大模型落地质量的重要一环。
在本文中,我们将解读:混合 Agent(MoA),如何将多个具有不同专长的 LLM 整合到一个系统中。
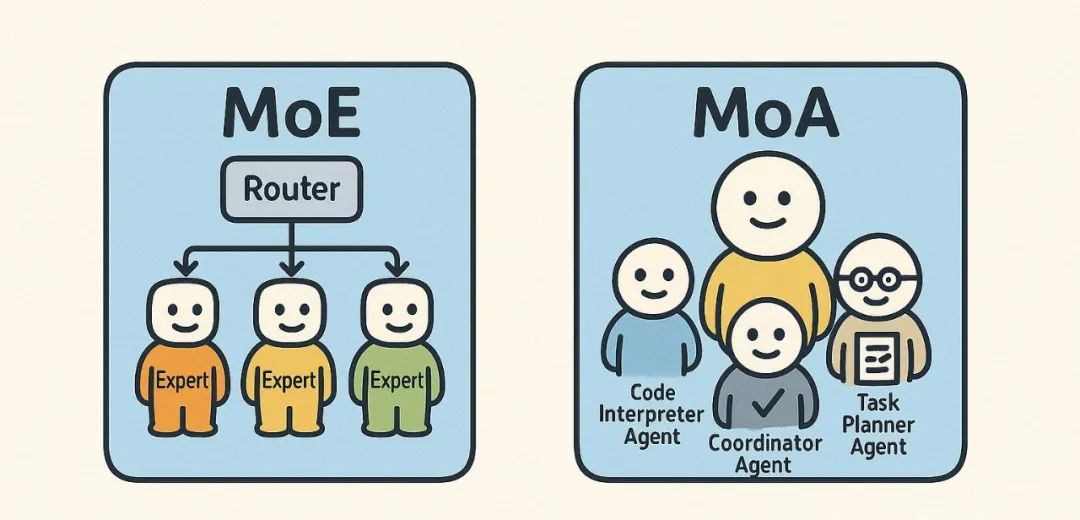
01 什么是 MoA,它与 MoE的区别是什么?
相比 MoA,可能更多人会对另一个相似概念——MOE更加熟悉。
什么是 MoE(Mixture of Experts)?
MoE 是一种稀疏激活的大模型架构,旨在在提升模型容量的同时保持计算效率。
其大致原理是:
-
模型包含多个子网络(称为 “专家” expert)。
-
每次推理时,并不是激活所有专家,而是由一个 路由器(router) 选择其中一小部分专家参与计算(比如激活2个专家中的16个)。
优势在于
-
计算效率高:只用部分专家参与计算,节省算力。
-
模型容量大:可以扩展到数千亿参数,但计算量相对可控。
-
支持个性化学习:不同专家可专精不同任务或输入类型。
那什么是 MoA(Mixture of Agents)?
MoA 是一种基于协作智能体的架构设计,强调多个具备不同能力的 AI Agent 协同工作,解决复杂任务。
其大致原理是
-
每个 Agent 是一个具备特定能力的小模型或工具,比如代码解释器、知识检索器、任务规划器等。
-
这些 Agent 之间通过一个中控协调(或互相协商)完成大型任务。
-
类似于一个 AI 团队,协作完成推理、规划、执行等子任务。
优势在于
-
模块化:每个 Agent 可独立开发和优化。
-
可解释性更强:任务流程可拆解为多个可追踪的决策点。
-
多模态/多任务友好:可集成文本、图像、搜索等不同能力。
简而言之,MoA 是一个框架,在这个框架中,多个专门的 LLM,即“Agent”,通过利用各自独特的优势协作+赛马式解决任务。
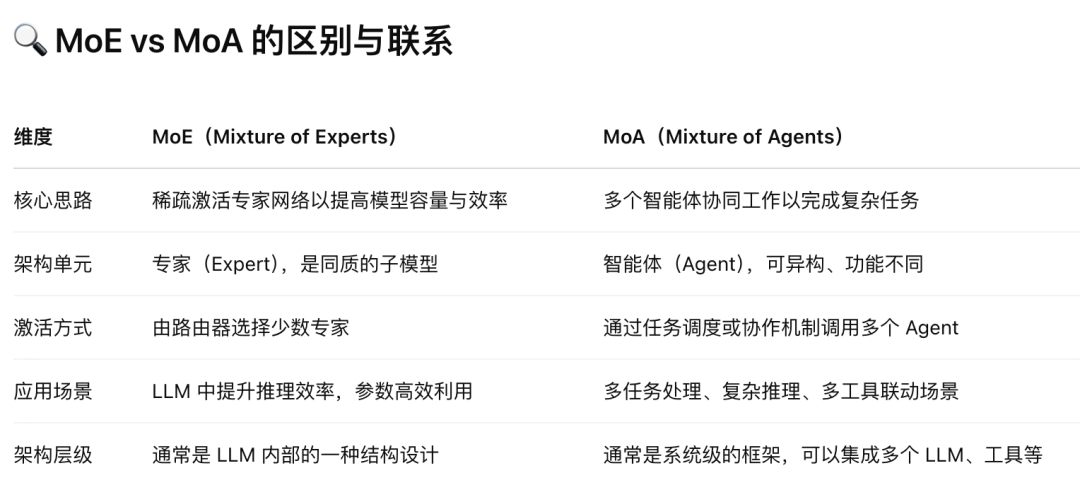
通过将几个具有不同优势和能力的 LLM 整合到一个系统中。当用户提交一个查询时,MoA系统中的每个大语言模型都会生成一个响应。然后,最后由一个指定的 LLM 将所有这些响应综合成一个连贯的答案提供给用户,如下图所示:
图:MoA 概念
尽管 MoA 概念很简单,但其效果却出奇地好。MoA 论文的作者发现,当一个 LLM 看到其他 LLM 的回复时,往往能生成质量更高的输出。
论文作者使用六种 LLM (Qwen、Wizard、Mixtral、Llama 3、dbrx )在 AlpacaEval 2.0 数据集上进行基准测试后,得到了确认。作者比较了 LLM 在两种条件下的回复质量:使用直接输入提示、使用其他模型的回复。他们使用长度控制(LC)胜率指标来衡量质量,该指标能独立于回复长度等可能显著影响评估结果的因素来评估输出质量。
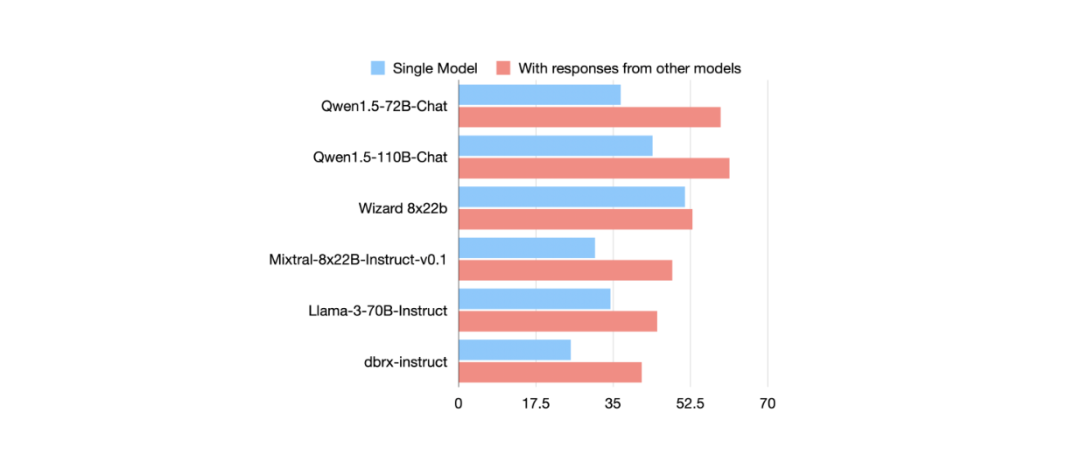
图:AlpacaEval 2.0 中各 LLM 基于两种不同输入的长度控制(LC)胜率对比:一种是直接来自用户提示,另一种是来自其他模型的输出。
在所有六个 LLM 中,结果都是一致的:与直接处理输入提示相比,当使用其他 LLM 的输出作为下一次的输入时,它们获得了更高的长度控制胜率得分。基于这些发现,作者提出了 MoA 概念。
02 MoA 的基本原理
MoA 将多个 LLM 整合到一个系统中,以迭代方式提高回复生成质量。
该系统由多个层组成,每层包含几个不同规模和能力的 LLM。第一层 LLM 针对输入提示独立生成回复。然后,这些回复作为输入呈现给第二层的 LLM,第二层的模型再独立生成自己的回复。这个循环在后续层中持续进行,直到到达最后一层。最后,一个 LLM 将最后一层的回复综合成最终回复提供给用户。
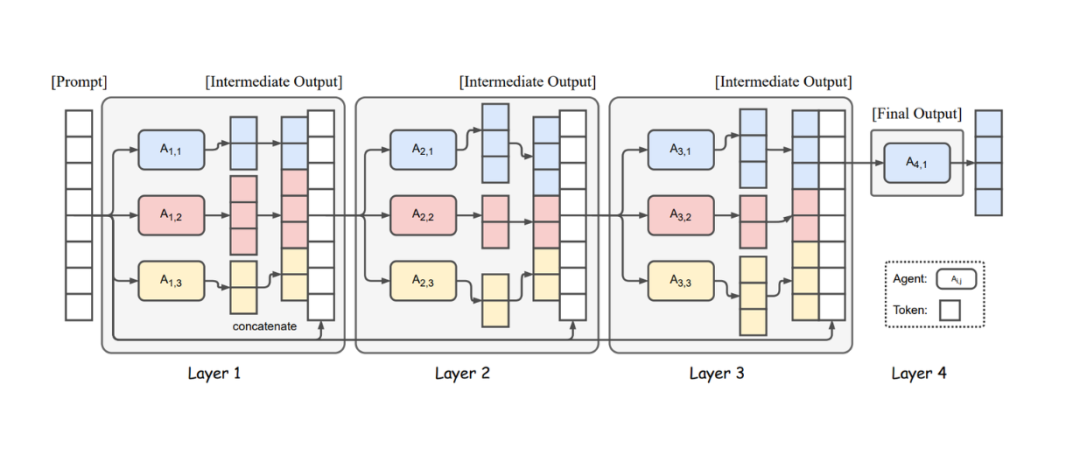
图:MoA 结构示意图
基于这一概念,MoA 中使用的 LLMs 可分为两类:提议者(Proposers)和聚合者(Aggregators)。
-
提议者在 MoA 系统的每一层中生成回复,为最终回复的质量做出贡献。
-
聚合者收集最后一层中所有大语言模型的回复,并将它们整合为一个高质量回复提供给用户。
鉴于不同 LLM 的能力和专长各异,在选择哪些模型作为提议者和聚合者时需区别考虑。有些 LLM 作为提议者表现出色,而另一些则更适合作为聚合者,还有一些能有效地承担这两种角色。
由于 MoA 包含多个层级,同一个 LLM 既可以在同一层中,也可以在不同层中重复使用。例如,我们可以构建一个有 5 层的 MoA 系统,每层包含 5 个 LLM,并在所有层中都使用 Llama3 70B 模型作为单一提议者。
一旦最后一层的提议者生成了回复,所有输出将被组织成一个连贯的提示,供聚合者生成最终回复。
以下是这样一个提示的示例:

图:用于合成和汇总多个 LLM 回复的提示示例
虽然这一概念与传统神经网络中使用的专家混合(MoE)方法类似,但存在一个关键区别。在传统神经网络中,MoE 层是作为单个模型架构内的几个子网络来实现的。因此,一旦遇到与训练数据差异较大的新数据,我们就需要微调每个 MoE 层的权重来优化性能。
MoA 完全依赖提示,因此,无需对 LLM 进行微调来提升系统的整体性能。这提供了更大的灵活性,因为我们可以自由选择不同的 LLM 作为提议者或聚合者,不用考虑规模和架构。这也意味着,如果未来出现新的顶尖模型,我们可以直接将该模型作为提议者或聚合者应用到我们的 MoA 系统中。
MoA 还有很多有独特优势的地方,例如:
-
LLM 排序器:此方法使用多个 LLM 作为提议者,独立生成回复。然后由一个独立的 LLM 从这些回复中选择最佳回复。
-
路由 LLM:此方法使用经过训练的路由函数来分析查询的复杂程度,并确定应由哪些 LLM 来处理输入。
03 基准数据集上的评估结果
MoA 已在三个基准数据集上进行了评估:AlpacaEval 2.0、MT-Bench、FLASK。
测试了 MoA 的三种不同变体:
-
MoA:一个三层系统,每层有六个提议者(Qwen1.5-110B-Chat, Qwen1.5-72B-Chat, WizardLM-8x22B, LLaMA-3-70B-Instruct, Mixtral-8x22B-v0.1, dbrx-instruct),并以 Qwen1.5-110B-Chat 作为聚合者。
-
带 GPT - 4o 的 MoA:设置与上述相同,但使用 GPT-4o 作为聚合者。
-
MoA-lite:一个两层系统,使用与标准 MoA 相同的六个提议者和聚合者。
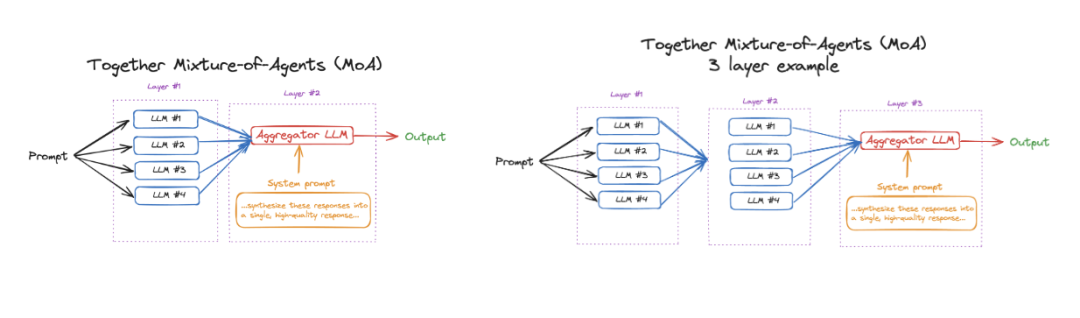
图:两层 MoA(左图)与三层 MoA(右图)对比
在 AlpacaEval 2.0 数据集上,三种 MoA 变体的表现均比当前最先进的模型 GPT-4 Omni 高出 8.2% 。以 GPT-4o 作为聚合器的 MoA 在这些变体中获得了最高的长度控制(LC)胜率。
这三种 MoA 变体在 MT-Bench 数据集上也展现出了颇具竞争力的性能。尽管当前最先进的模型 GPT-4 Turbo 表现极为出色,但以 GPT-4o 作为聚合器的 MoA 变体超越了它。MoA 变体与其他最先进模型之间的性能对比见下图:
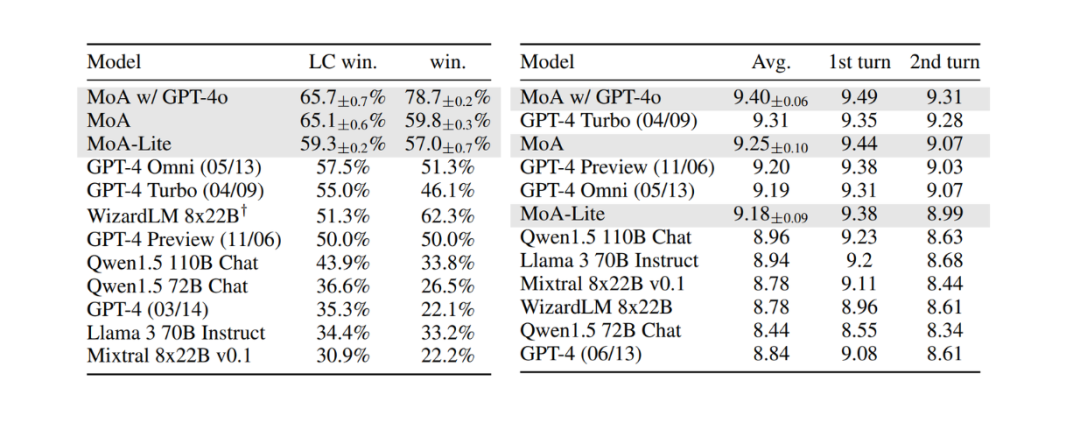
图:AlpacaEval 2.0(左)和 MT-Bench(右)的结果
FLASK 数据集相比 AlpacaEval 2.0 和 MT-Bench 提供了更细致的评估,涵盖 12 个方面:稳健性、正确性、效率、真实性、常识性、理解能力、深刻性、完整性、元认知、可读性、简洁性以及无害性。
以 Qwen1.5-110B-Chat 作为聚合器的 MoA 在五个方面的表现优于 GPT-4 Omni:正确性、真实性、深刻性、完整性和元认知。与此同时,除了简洁性之外,其他指标的表现与 GPT-4 Omni相当。如下所示,MoA 在简洁性方面有明显下降:
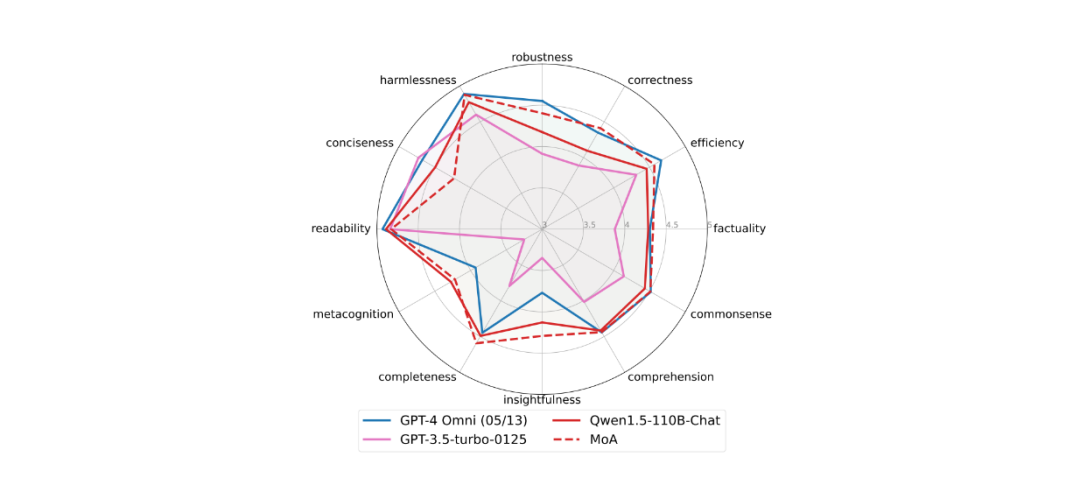
图:FLASK 数据集上的结果
既然我们已经了解了它与 GPT-4 系列等顶尖模型相比的性能,那么看看它与其他相关的 MoA 方法相比的性能也很有意思。
如前所述,另一种类似 MoA 的方法示例是 LLM 排序器,它使用多个 LLM(提议者)针对输入提示独立生成回复。LLM 排序器并不使用聚合器,而是从提议者生成的回复中选择最佳回复。
在评估中,MoA 和 LLM 排序器使用了相同的六个提议者:Qwen1.5-110B-Chat, Qwen1.5-72B-Chat, WizardLM-8x22B, LLaMA-3-70B-Instruct, Mixtral-8x22B-v0.1, and dbrx-instruct。每个提议者都作为 MoA 的聚合器进行了测试,而 LLM 排序器仅使用 Qwen1.5-110B-Chat 来选择最佳回复。
在 AlpacaEval 2.0 数据集的评估中,无论使用哪个模型作为聚合器,MoA 的表现始终优于 LLM 排序器。这显示了 MoA 方法的潜力,即最终的聚合器并非简单地从提议者的回复中选择其一,而是对所有提议者的回复进行汇总整合,从而生成一个更强大、更可靠的最终回复。
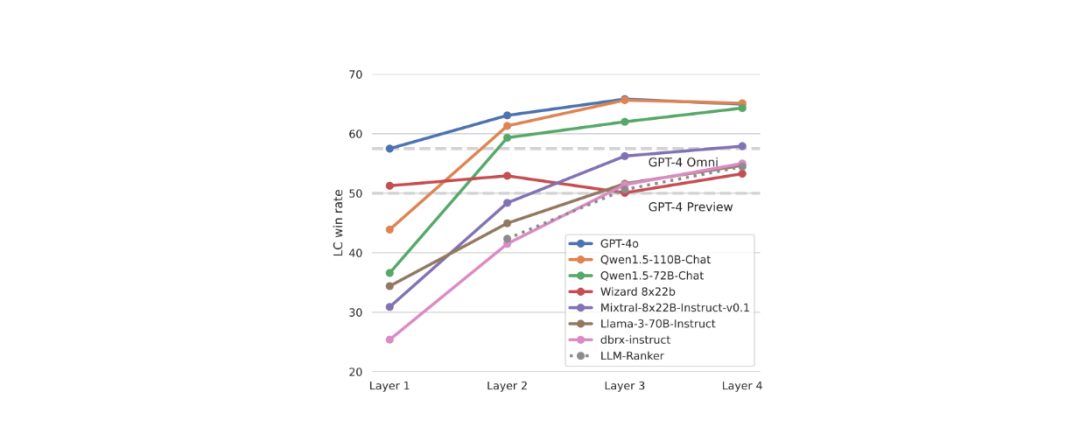
图:在由 6 个提议者构成的 MoA 中,使用不同聚合器时在 AlpacaEval 2.0 上的长度控制(LC)胜率比较
04 MoA 设置建议
我们已经看到了使用三种变体、每种变体包含六个不同提议者的 MoA,他们与 GPT-4 系列模型的性能比较,这里就衍生出了两个关键问题:
-
提议者的数量如何影响 MoA 的整体性能?
-
如果我们使用多个相同的 LLM 作为提议者,而非不同的大语言模型,会发生什么情况?
为了确定提议者数量的影响,MoA 论文的作者在 AlpacaEval 2.0 上对不同数量提议者的 MoA 进行了评估。他们测量了使用 6 个、3 个、2 个和 1 个不同提议者的两层 MoA 配置的长度控制胜率。结果表明,更多的提议者有助于聚合器生成更可靠的回复。
此外,使用单一提议者(相同的 LLM 作为提议者)的 MoA,其性能比多提议者配置更差。这表明,MoA 得益于拥有一组具有不同专长的多样化 LLM,而非使用同一个 LLM。
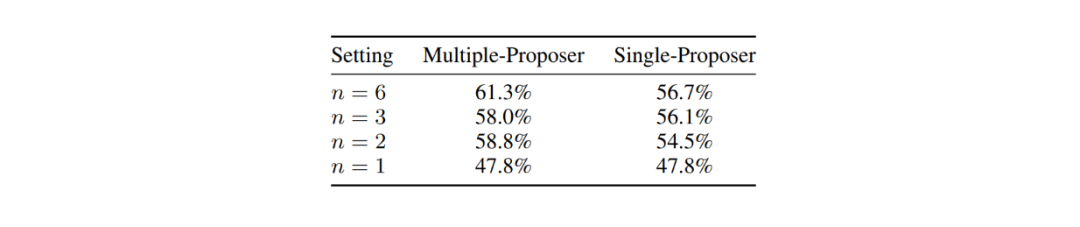
图:提议者数量对 AlpacaEval 2.0 评估结果的影响
鉴于多提议者设置的优势,了解哪些 LLM 在这些配置中效果最佳也很重要。在 AlpacaEval 2.0 上对六种不同 LLM 的测试表明,像 GPT-4o、Qwen、Llama 3 这类模型通用性很强,既可以充当提议者,也能作为聚合者。然而,像 WizardLM 这样的模型,作为提议者的表现要明显优于作为聚合者。
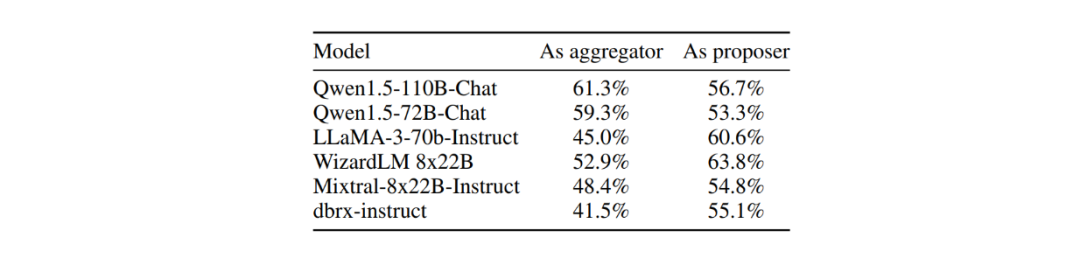
图:不同 LLM 分别作为提议者与聚合者时的影响
在成本方面,MoA 依赖多个 LLM,这使得它与 GPT-4o 和 GPT-4 Turbo 等顶尖模型相比,性价比情况尤为引人关注。实验表明,MoA-Lite 在 AlpacaEval 2.0 上的表现比 GPT-4 Turbo 高出约 4%,同时成本降低一半以上。此处 MoA-Lite 的成本是根据 TogetherAI 提供的定价信息计算得出的。
然而,如果我们在成本支出上没有顾虑,希望最大化性能,那么三层的 MoA 会是更好的选择。
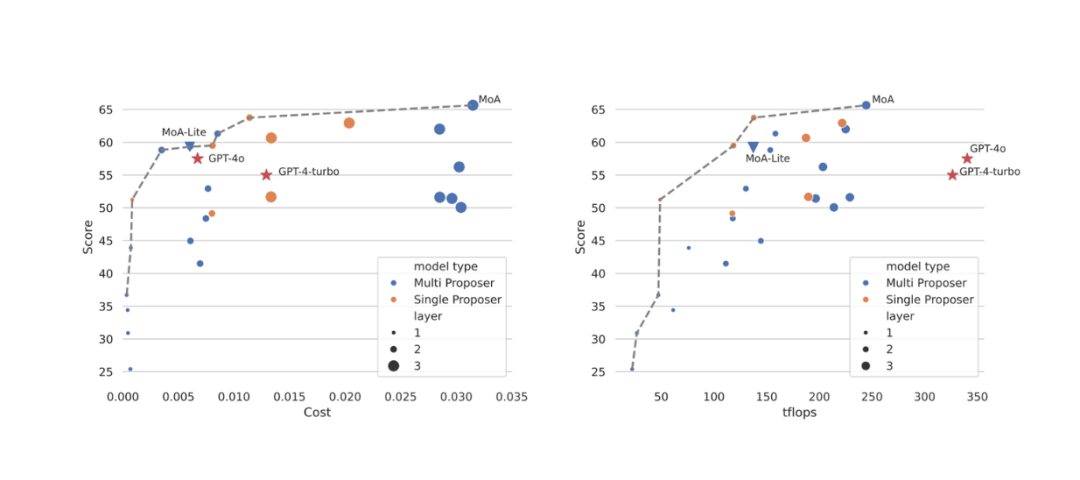
图:性能与成本的权衡(左)以及性能与 TFLOPS 的权衡(右)
在延迟评估方面,作者使用每秒万亿次浮点运算(TFLOPS)作为衡量指标。TFLOPS 指的是系统在一秒内执行一万亿次浮点运算的能力。尽管 TFLOPS 与延迟并非完全等同,但由于延迟会因推理系统的不同而有所变化,作者便以 TFLOP 作为延迟的替代指标。实验结果表明,三层的 MoA 设置通过优化其 TFLOPS 可以最大化长度控制(LC)胜率,如上图中的帕累托虚线所示。
然而,GPT-4 系列与 MoA 设置相比,TFLOPS值更高。这并不意外,因为 MoA 在生成最终输出之前,必须处理多个 LLM 的回复。
这导致了它的主要局限性:首 token 生成时间(TTFT)过长,这可能会对用户体验产生负面影响。未来的工作旨在通过实施分块回复聚合而非完整回复聚合来解决这一问题,有望在保持性能的同时缩短 TTFT。
05 结论
MoA 方法给利用 LLM 的多样性和专业性提供了一个很有前景的解决方案。通过提议者和聚合者系统,运用多个各有所长的大语言模型,MoA 能够生成更强大、更可靠的最终回复。它的灵活性以及对提示工程而非微调的依赖,使其成为一种经济高效且适应性强的方法,尤其适用于多领域应用场景。
在 AlpacaEval 2.0 和 MT-Bench 等数据集上的基准评估表明,MoA 的性能优于 GPT-4 系列等先进模型。为了进一步优化性能,建议使用多提议者而非单一提议者设置。
然而,MoA 并非毫无局限性。对多个大语言模型的依赖增加了延迟,较高的首 token 生成时间(TTFT)会影响用户体验。因此,有必要进行进一步改进,如分块回复聚合,以优化其效率。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









