






 本文介绍了如何在Windows上搭建环境,包括Python3.9、Git、Docker等,然后使用Milvus搭建向量数据库,集成新闻数据集并通过HuggingFace模型进行搜索。步骤详细,适合初学者入门。
本文介绍了如何在Windows上搭建环境,包括Python3.9、Git、Docker等,然后使用Milvus搭建向量数据库,集成新闻数据集并通过HuggingFace模型进行搜索。步骤详细,适合初学者入门。
前言【基于chatbot】
厌倦了商业搜索引擎搜索引擎没完没了的广告,很多时候,只是需要精准高效地检索信息,而不是和商业广告“斗智斗勇”。以前主要是借助爬虫工具,而随着技术的进步,现在有了更多更方便的解决方案,向量数据库就是其中之一【chatGPT也需要它的支撑】。
环境搭建【工作环境为windows10,数据库环境为centos7】
1. 安装python3.9【具体参考以下文章】
2. 安装git【网上教程太多了,就不写了。有需要的可以留言】
3. 安装docker和docker-compose【网上教程太多了,就不写了。有需要的可以留言】
4. 安装milvus
在centos系统中,执行以下命令
wget https://github.com/milvus-io/milvus/releases/download/v2.2.11/milvus-standalone-docker-compose.yml -O docker-compose.yml启动向量数据库
sudo docker-compose up -d 【-d是后台启动,第一次启动可以不加,有报错的话直接在命令行能看到】ip和端口号,根据自己的实际情况做调整
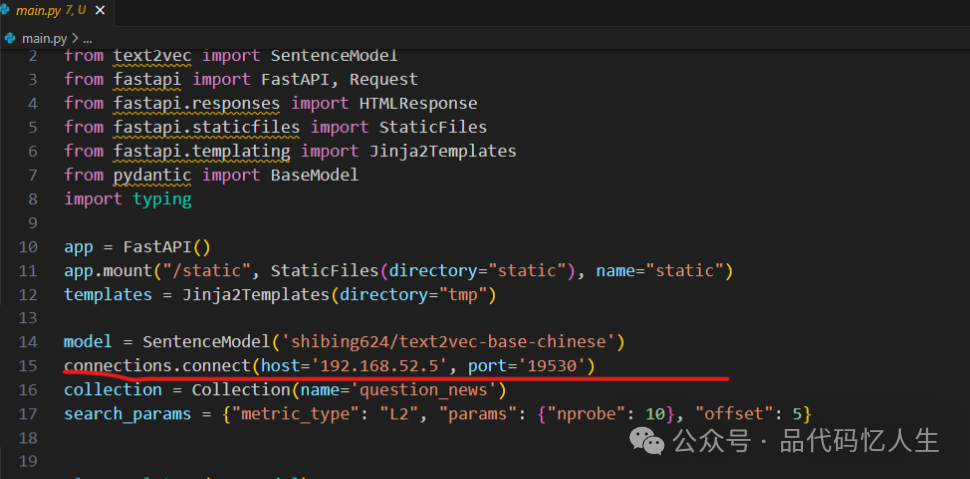
下载代码
git clone https://github.com/gitksqc/chatbot.git安装python虚拟环境
python -m venv venvtest安装模块
# 配置国内镜像pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple# 命令行进入到代码所在目录pip install -r requirements.txt
准备数据集【可以自己用爬虫做数据集】
# 我这里选的是新闻数据集做测试,可以根据自己情况选择https://www.kaggle.com/datasets/ceshine/yet-another-chinese-news-dataset
下载模型
# 需要合理的上网工具,将模型及配置文件拷贝到项目根目录下的shibing624/text2vec-base-chinese目录中https://huggingface.co/shibing624/text2vec-base-chinese
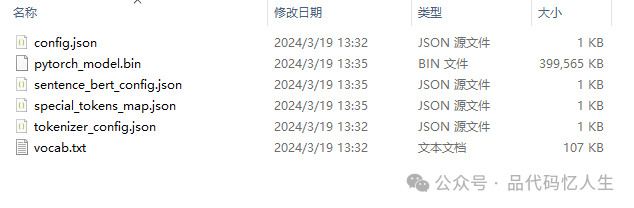
导入数据
# 将下载的新闻数据集拷贝到项目根目录下news_collection.csv# 在项目根目录下执行insert.py脚本,等待执行结束python insert.py
运行项目
# 激活虚拟环境.\venvtest\Scripts\Activate.ps1# 启动服务uvicorn main:app --reload
搜索
-
打开浏览器 访问http://127.0.0.1:8000【端口号可以自己在代码中设置】
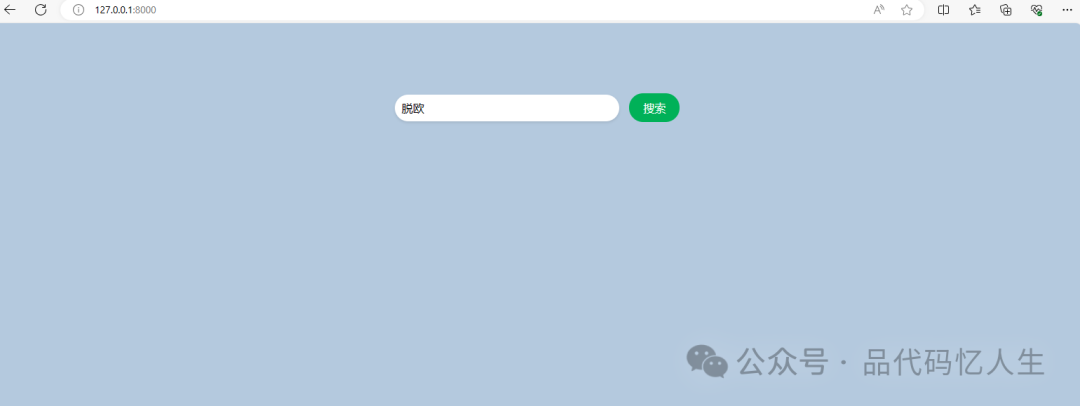
-
输入要搜索的文字,点击搜索【页面没有做排版,主要演示功能】
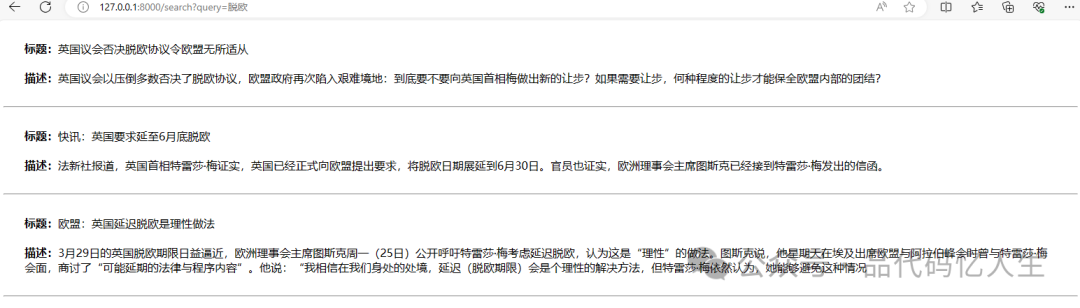
到此就结束了,有问题可以留言或私信。

















 648
648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









