






 文章通过对比Llama-2-70B和GPT-3.5在两个A100GPU上的性能,发现Llama在补齐token任务上的成本和延迟高于GPT-3.5,但在提示任务上成本更低。作者通过数学计算展示了模型的FLOPS需求和内存带宽,并指出Llama更适合处理提示任务,而GPT-3.5在生成任务上更优。
文章通过对比Llama-2-70B和GPT-3.5在两个A100GPU上的性能,发现Llama在补齐token任务上的成本和延迟高于GPT-3.5,但在提示任务上成本更低。作者通过数学计算展示了模型的FLOPS需求和内存带宽,并指出Llama更适合处理提示任务,而GPT-3.5在生成任务上更优。

【CSDN 编者按】本文作者发现在两个 A100 的机器上,使用 Llama 补齐 token 的成本比 GPT-3.5 更高。这是为何?他以长度为 N,批次大小为 B 的序列为例展开真实评测,不妨一起看下。
原文链接:https://www.cursor.so/blog/llama-inference
未经允许,禁止转载!
作者 | Aman Sanger 译者 | 弯月
责编 | 夏萌
出品 | CSDN(ID:CSDNnews)
Llama-2-70B 是一款很不错的 GPT-3.5 的替代品,但如果你想寻找廉价的语言模型,则始终无法摆脱 OpenAI 的 API。
从价格和延迟方面考虑,你不应该让 Llama-2 承担以自动补齐为主的工作负载。
相反,Llama 最适合以提示为主的任务,例如分类任务。遇到下列情况,也可以考虑使用 Llama-2:
工作负载没有提示token(稍后我们会详细解释);
执行批处理作业。
除此之外,使用 gpt-3.5 会更便宜、更快。
免责声明,人们选择 Llama 而不是 GPT-3.5 的原因之一是,这个模型可以进行微调。但在这篇文章中,我们只探讨成本和延迟。我不打算比较 Llama-2 与 GPT-4,因为前者更接近 GPT-3.5。这个说法有基准性能测试结果的支持:
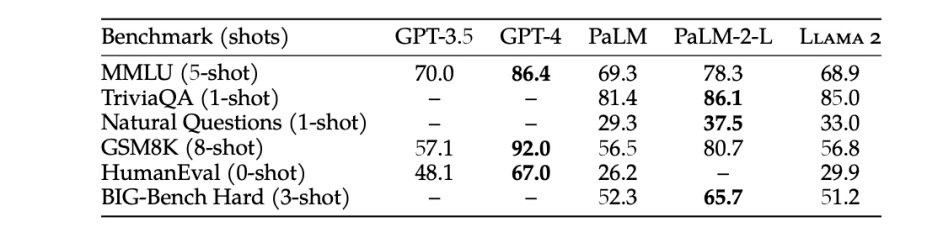
图1:GPT-3.5 在所有基准测试中均优于 llama 2
在文本中,我会在延迟大致相似的情况下,比较 Llama-2-70B 与 gpt-3.5-turbo 的服务成本。我们的 Llama 搭建在两个 80 GB A100 GPU 之上——这是 Llama 进入内存的最低需求。
我们发现在两个 A100 的机器上,使用 Llama 补齐 token 的成本比 GPT-3.5 更高。我们推测在 8 个 A100 的机器上,Llama 的价格更具竞争力,但代价是难以接受的高延迟。
相反,对于有提示 token 的任务,Llama 的成本不到 GPT-3.5 的三分之一。

Transformer 的基础数学知识
本节,我们将通过一些简单的数学计算来展示下述结果。对于一个长度为 N,批次大小为 B 的序列:
每个 token 所需的 FLOPS(每秒浮点运算次数)= 140 ⋅ 109FLOPs
内存带宽 / token = 140 GB/s + 320 ⋅ N ⋅ B KB/s
140 这个数字是模型参数数量的两倍,而 320 KB/s 是通过一些数学计算得出的。我们将在下一节中解释如何得出这些数字。
为了验证这些数字,首先我们介绍一下 Llama 架构的详细信息。隐藏维度为 4096,attention head 为 64,层数为 80,每个 attention head 的维度为 128:


计算模型需要的 FLOPs
前向传递所需的 FLOPs ≈ 2P,其中 P 是模型中参数的个数。我们模型中的每个参数都属于某个权重矩阵 M ∈ R m×n,而 对于每个输入 token,每个矩阵在与表示该 token 的向量矩阵乘法中仅被使用一次。
每个 M ,我们用一个维度为 m 的向量 x 与之左乘。此向量矩阵乘法的总 FLOP 为 2mn,即权重矩阵中元素个数的两倍。transformer 所有权重矩阵中的元素个数总和就是参数的总数 P,因此 FLOPs 等于 2P。
对于 Llama 这种大型模型,相对较短的序列的 attention 消耗的 FLOP 数量可以忽略不计。对于每个层的每个 attention head,attention 操作为:
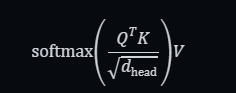
QTK 需要计算向量 dhead 和 dhead x N 的矩阵乘法,需要 2dheadN FLOPs。缩放因子和 softmax 可以忽略不计。最后,将 attention 向量乘以 V,还需要 2dheadN FLOPs。将所有 attention head 和所有层上加起来,就得到 4 · dmodel · n · N = 1.3 · N MFLOPs。对于最大的序列长度 8192,attention 仍然只需要 10.5 GFLOPs,与整体的 140 GFLOPs相比非常小,可以忽略不计。

补齐任务比提示任务需要的内存更多
在生成 token 时,我们需要重新读取所有模型的权重和 KV 缓存。这就意味着,任何矩阵乘法都需要将每个矩阵的权重从内存加载到 CPU 的寄存器中。如果有大量不同的矩阵,那么瓶颈就会变成加载权重的操作,而不再是矩阵乘法。所以,我们来比较一下在提示任务和补齐任务中 token 在模型中的行进路径。
Transformer 中生成 token 的内存路径
为了方便说明,我们用一个简单的单层 transformer 生成一个批次的 token:
首先读入输入嵌入矩阵 We,然后对批次中的每个输入,计算相应的嵌入向量。
从内存中读入 Wq、Wk、Wv 矩阵,对每个输入计算 qi、ki、vi 向量。
执行 attention 操作,这一步需要读取缓存中的键和值,然后针对每个输入返回一个向量。
从内存中读取 Wo,然后乘以上一步的输出。
读取第一步的输出,将其与第四步的输出相加,然后执行 layernorm。
读取 Wff1 并执行乘法操作,获取第一个 feedforward 层的输出。
读取 Wff2 并执行乘法操作,获取第二个 feedforward 层的输出。
读取第五步的输出,与第七步的输出相加,然后执行 layernorm。
读取未嵌入的层 WeT,然后执行矩阵与矩阵的乘法,获得批次中每个输入的 token 的 logprobs。
针对下一个 token 进行采样,然后将其传输回第一步。
我们来计算一下内存的需求量。在第1、2、4、6、7 和 9 步中,我们读取了一次模型的所有参数。在第 3 步中,我们读取了每个批次元素的 KV 缓存。在所有步骤中,我们读取了中间的 activation,尽管这一步相对于模型大小而言可以忽略不计。所以,总体的内存带宽需求为模型权重 + KV 缓存。随着批次大小的增加,除了 KV 缓存会变化,其他部分的内存需求基本上不变!我们稍后再讨论这一点。现在需要注意,这里计算的只是每个 token 的内存需求。
Transformer 中处理提示 token 的内存路径
在处理提示时,我们需要读取一次所有的模型权重,但 attention 的内存需求可以忽略不计。我们来考虑通过 transformer 处理一个批次的序列的过程:
首先,读入输入嵌入矩阵 We,然后针对批次中的每个序列,计算相应的嵌入向量。
从内存中读入 Wq、Wk、Wv 矩阵,针对每个输入计算 qi、ki、vi 向量。
执行 attention 操作。
从内存中读取 Wo,然后乘以上一步的输出。
读取第一步的输出,与第四步的输出相加,然后执行 layernorm。
读取 Wff1 并执行乘法操作,获取第一个 feedforward 层的输出。
读取 Wff2 并执行乘法操作,获取第二个 feedforward 层的输出。
读取第五步的输出,与第七步的输出相加,然后执行 layernorm。
读取未嵌入的层 Wu = WeT,然后相乘,获得提示序列中每个输入的 token 的 logprobs。
在第1、2、4、6、7步中,我们读入了模型的所有参数。在第3步中执行了 attention 操作,其中使用了 FlashAttention,需要的内存量远远小于模型权重的大小(对于合理的批次大小和序列长度而言)。在所有步骤中,我们读取了中间的 activation,尽管这一步相对于模型大小而言可以忽略不计(同样对于合理的批次大小和序列长度而言)。注意,这是所有 token 内存需求。
所以,提示处理的每 token 的内存需求要远远小于生成 token 的内存需求,因为在提示处理中,我们会在序列的维度上批量进行矩阵乘法!
模型权重所需的内存带宽
16比特精度的模型权重需要占用 2 x 70 = 140 GB内存。
KV 缓存所需的内存带宽
在神经网络中,KV 缓存的大小等于所有之前见过的 token 在所有层上、所有 head 中的所有键值的大小,对于每个 token、每个批次元素,大约是 320MB。
Llama 2 决定删除 multi-head attention,但会使用 grouped query attention,这能大大提升性能。结果是每个键和值 ng 多了 8 个 head。相比而言,正常的 multi-head 需要 128 个 head,multi-hquery 需要 1 个 head。
对于 N 个 token,KV 缓存的大小为 2ngnldheadN = 1.6N · 105。对于 16 比特精度,这等于 320N KB。对于批次大小 B,结果为 320·NB KB。
对于补齐任务,每个 token 的内存需求为:
内存 / token = 140GB + 320 · N · B KB
在较短的序列或较小的批次中,第一项占主导地位。否则,第二项会更大。但是,由于我们只有 160GB 内存,模型本身就占用了 140GB,所以在我们的实验中,KV缓存占用的内存带宽较小。
对于提示任务,内存带宽大约为:
内存 / token = 140 / N GB
通信的额外开销
为了简单起见,我们忽略了通信的开销,因为统计模型并行化会让计算变得非常复杂。可以合理地假设,通信不会让上述任何计算结果大幅度变慢(特别是我们只把 Llama 分布到了两个 GPU 上)。

提示处理非常廉价
提示处理(或者说是ii得出第一个 token 所花费的时间)是 transformer 的推断过程中效率最高的部分,其价格应该不到 GPT-3.5 的三分之一。
对于一个拥有 P 个参数的模型和一个长度为 N 的提示,处理提示的内存需求大约为 2P 字节,而计算需求大约为 2PN FLOPs。由于 A100 能够处理 312 TFLOPs 的矩阵乘法和 2TB/s 的内存带宽,只有当 N > 156 时才会成为计算为主的任务。
在 A100上,FLOP 的最大利用率大致为略微不到 70% MFU。这个值大约为 200TFlops。两个 80GB 的 A100 的成本约为 4.42 美元/小时,折合 0.0012 美元/秒。在两个 A100 上,Llama 需要的 FLOPs 为 140TFLOPs/token,可以算出每秒的 token 数大约为:
2 · 200 · 1012 / 140 · 109 = 2.86·103 tokens/秒
价格为:
0.00042美元 / 1K token
与GPT-3.5的 0.0015 美元相比简直就是白菜价!准确地说,只有其大约四分之一的价格!
而且延迟也非常好!在两个 GPU、批次大小为 1 时,处理 512 个 token 只需要 170 毫秒,处理 1536 个 token 只需 530 毫秒。
我们使用实际数字来验证一下。我们使用 huggingface 的 text-generation-inference 库的一个内部分叉来测量 Llama-2 的成本和延迟。
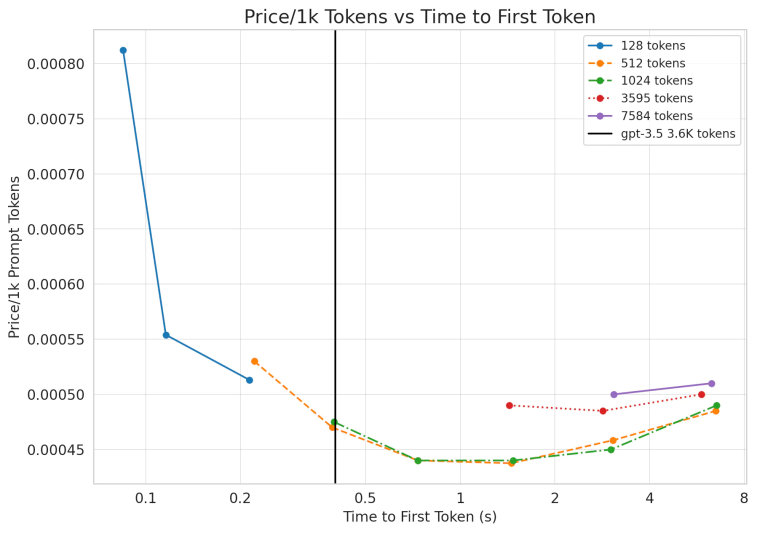
图2:每个数据点表示不同的批次大小。对于提示 token 来说,其价格远低于 gpt-3.5,但在延迟略逊于 gpt-3.5(3.6K token 花费了 0.4秒)。
如上图所示,Llama的 价格远低于 GPT-3.5(0.0015美元/1K token)!对于较长的序列,我们的模型得出第一个 token 的延迟要高一些,但解决起来也很容易。在 8 个 GPU 上并行运行 Llama,就可以将速度提高大约四倍,也就是说在提示任务上 llama-2 会超过 GPT-3.5!

生成token非常慢且非常贵
理论上,在补齐任务中 Llama 的价格也能接近 GPT-3.5,但实际上效果会差很多。
生成 token 的任务不是计算密集,而是内存密集。假设批次大小为 1,我们来计算一下吞吐量为多少。
每个 80GB A100 的最大内存带宽为每个 GPU 2TB/s。但是,与 FLOPs 的使用率一样,在推断负载的情况下,实际的最大值大约为 60~70%(1.3TB/s)。由于在小批次中,KV 缓存可以忽略不计,所以两个 A100 的吞吐量为:
(2 x 1.3 x 1012B/s) / (140 x 109 B/token) = 18.6 tokens/s
这个价格可不理想。按照 0.0012美元/秒来计算,成本为:
0.06 美元 / 1K tokens
对于一个 gpt-3.5 级别的模型来说,这个价格和速度都非常糟糕!但别忘了前面关于批次大小的假设。这里的瓶颈在内存上,所以我们可以增加批次大小,而不会影响生成速度。批次大小越大,成本就越低。
但是,批次无法无限扩展,因为 KV 缓存最终会占用所有显存。幸运的是,grouped-query attention 可以缓解这个问题。对于 N 个 token、批次大小 B、16 比特精度,缓存大小为 3.2 x N x B x 105 字节。如果有 4096 个token,批次大小为 1,则需要 1.3GB 内存。两个 A100 的机器共有 160 GB内存。模型本身占用 135 GB,还剩 25GB 给 KV 缓存。考虑到内存存储的低效,我们可以算出对于较长的序列,最大批次约为 8。
有了 8 倍的提速,成本大约为 0.00825 美元/ 1K token,虽然还是比不上 gpt-3.5-turbo,但已经接近了。对于较短的序列长度(总计 1k token),我们可以将序列大小增加到 32,相当于 0.00206 美元/ 1K token。理论上可以媲美 gpt-3.5-turbo 了。
另一个解决方案是增加 GPU 的个数。我们租用了 8 个 80GB A100,总计 1.28TB 内存。去掉模型的权重,留给 KV 缓存的内存依然超过了 1TB,这意味着批次大小可以超过 512。注意,成本并不会降低到 1/512,因为 KV 缓存现在占用的内存带宽超过了模型大小的 8 倍,意味着实际的成本约为 1/64。
更多的计算力也能解决延迟问题。GPT-3.5 的计算力大约为 70 TPS。将模型分割到 8 个 CPU 上,可以达到约 74.4 token/s。
在实验期间,我们没能使用 8 个 A100,但我们来看看在两个 80GB A100上的实际结果:
测量得到的生成任务性能
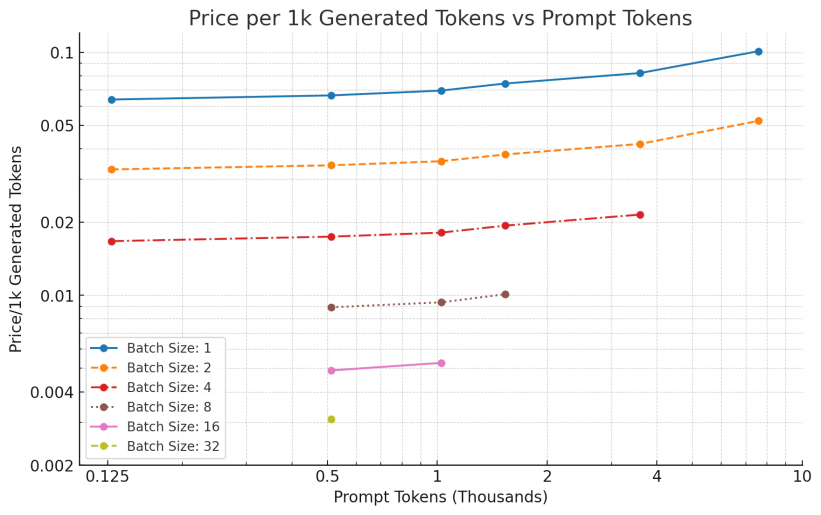
图3:数据点测量生成 512 个 token 的生成任务得到的价格
这些数字与前面内存带宽计算得到的数字很相近。
可见,增大批次大小可以近似线性地降低 每 1K token 的成本。但是,我们的成本依然赶不上 GPT-3.5 的 0.002 美元/1K token,特别是对于更长的序列。
大批次意味着不可接受的延迟
在更大的批次上运行生成任务虽然能在成本上与 GPT-3.5 竞争一下,但生成第一个 token 所需的时间会大幅度增加。随着批次增大,成本会线性下降,但生成第一个 token 的时间也会线性增加。
批次大小 64 可以将成本降到比 gpt-4 更低,但同时也会带来问题:
对于仅生成 512 个 token 的任务,生成第一个 token 就需要将近 3 秒!批次大小为 64 时,生成 3596 个 token 需要 20.1 秒。所以,与 OpenAI 的 API 相比,适合 Llama-2 的负载如下:
较大的提示任务,很少或不需要生成 token——仅处理提示会非常容易。
通过很小的提示或没有提示来生成 token ——我们可以微调批次大小直到略微超过 64,从而在不牺牲性能的前提下获得媲美 gpt-3.5-turbo 的价格。
对延迟没有要求的离线批量处理。
微调批次大小需要非常大的负载,这是绝大部分创业公司无法承担的!对于多数用户和多数负载来说,使用量的变化非常激烈。当然,一种解决方案是采用按需使用的 GPU 并进行伸缩,但即使如此,每个 GPU 的最大使用率也不会超过 50%,特别是考虑到冷启动时间。
我们建议,对于以提示为主的任务,可以采用开源模型,而以生成为主的任务还是采用 GPT-3.5 等闭源模型。
量化
许多量化方法都会带来一定的损失,就是说会导致一部分性能下降。通过 8 比特量化应该能获得有竞争力的性能,而成本不到一半。量化和不完美的使用率会互相抵消,意味着如果同时考虑两者,成本应该不会与上面测量到的结果有太大出入。
但是,大多数开源量化方法的目标都是降低在更少或更小的 GPU 上部署的难度,而不是优化大规模下的吞吐量。
有几个开源库在保证性能的前提下对低精度量化进行了优化。但是,这些库的目标也是在更小或更少的 GPU 上进行部署,而不是在大规模下的吞吐量。具体来说,它们优化的是低批次下的推断(主要是批次大小为 1)。尽管能带来(最多)3~4倍的提速,但成本依然是 0.017美元/1K token 左右。
bits and bytes
bits and bytes能提供无损量化,也就是说性能上没有区别。但是,它的主要优势是降低内存需求,而不是提升速度。例如,最近的 NF4 表示法只能提高矩阵乘法的速度,而无法提高推断的速度。人们似乎并没有测量推断的速度。
至于这种方法在较大的批次下表现如何,目前尚无定论。
llama.cpp
我相信 llama.cpp 的主要优化目标是苹果的硬件。它也支持 Cuda,也支持 4 比特精度下更快的推断,但我怀疑,这种朴素的量化方法会导致明显的性能下降。
此外,这个库的优化目标是较低的批次大小。
GPT-Q
GPT-Q 是另一个优化库。我没有测试过 GPT-Q,但准备测试一下。希望能看到价格能降低至少一半。
同样,这个实现面向的是较低的批次大小。此外,论文里提到的三倍提速只适用于 3 比特量化,对于我们的情况来说,损失太大了。

闭源模型有多便宜?
有几种闭源模型使用的方法能大幅度提升推断的性能:
量化
前面提到有几个开源量化方法,但我认为 OpenAI 的量化实现对于较大批次的优化更好。
mixture of experts
有人怀疑 GPT-4 使用了mixture of experts(MOE)。如果 gpt-3.5-turbo 也使用了 MOE,那么你可以运行一个很小的模型(也更快),但获得同样的性能。
Speculating sampling
Speculating sampling 是另一种技巧,通过让更小的模型同时处理多个 token 来降低语言模型的解码时间。注意,这不会带来吞吐量的显著提升,但可以大幅度降低延迟。
大规模部署下的技巧
也许 OpenAI 在大规模部署下运行推断时 使用了许多技巧,例如分配多个 8 GPU 节点来预填充一系列请求,然后分配一个 8 GPU 节点为这一系列请求生成 token。这样可以同时享受两方面的好处,不仅可以使用大于 64 的批次大小,还可以大幅度降低生成第一个 token 的时间。

总结
希望本文对于如何使用开源模型有一定的启发。
总的来说,我们认为开源模型最适合以提示为主的任务,比如分类任务或排名任务。
推荐阅读:
▶防游戏玩家作弊、限制广告机器人,Google 最新提案遭抨击:杀死开放 Web,绝对不道德!
▶Java 成 Oracle 摇钱树,使用成本翻5倍!网友:“这是一人使用,全员买单?”
▶被骂 2 年后,Windows 11 任务栏终于要改:「从不合并」功能即将回归!
粉丝福利:




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











