






Linux内核如何更好地结合和发挥硬件的能力
10月28日,由OPPO承办的第十八届“中国Linux内核开发者大会”拉开帷幕。作为中国 Linux 内核领域最具影响力的峰会之一,今年大会依然秉承以“自由、协作、创新”为理念,以推动和普及开源技术为使命。旨在促进国内 Linux 内核开发爱好者的相互学习与交流,促进共同成长。本届中国Linux内核开发者大会共设立了主论坛和包含内存管理、云和服务器、Arch&虚拟化&I/O、调试/eBPF/调度在内的四个分论坛。
Arch&虚拟化再发力,前沿技术动态速报
主论坛上,OPPO平台软件开发中心GM、软件系统优化技术专家许珉嘉就以《ColorOS夏基于用户体验改善的Linux内核优化》为题,率先掀开了Linux内核优化上进行的探索与思考。
那么,Linux内核如何更好地结合和发挥硬件的能力?在本次Arch&虚拟化&I/O分会场,众多领域大咖带来了Arch、虚拟化、I/O相关领域的前沿技术分享,其中不乏内核与硬件深度结合的内容。
LoongArch KVM虚拟化支持
龙芯中科系统软件研发工程师赵天瑞分享了LoongArch KVM虚拟化支持相关内容。
龙芯相关技术团队依据LoongArch CPU虚拟化硬件特性,在Linux内核中实现了KVM虚拟化软件处理流程。主要包含CPU虚拟化,内存虚拟化,中断控制器虚拟化,外设虚拟化以及KVM异常处理和实现内核态与用户态交互接口。
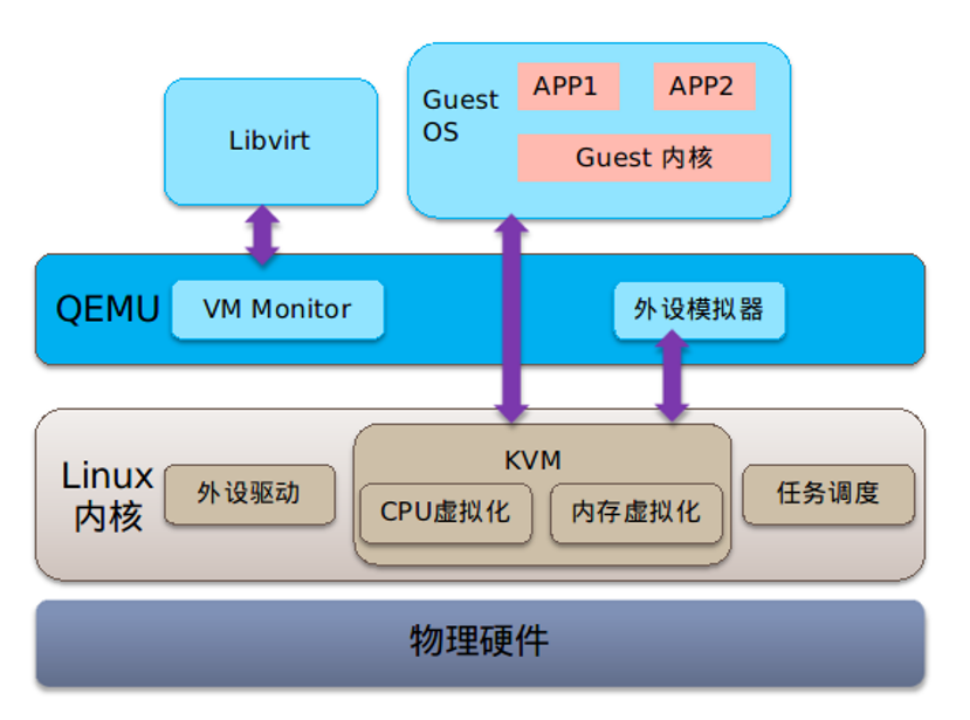
赵天瑞介绍了LoongArch KVM虚拟化组件构成及运行流程。“首先用户态QEMU创建KVM虚拟机并初始化运行
环境,进入内核态KVM后CPU在虚拟化模式下运行程序。当vCPU触发异常时,如果KVM能够处理,则处理完重新进入虚拟化模式运行;否则退出到用户态处理,处理完成后返回KVM进入虚拟机。”
相关团队目前在Linux内核中提交的补丁为LoongArch KVM的基础版本,包含CPU虚拟化和内存虚拟化。后续会进一步完善如中断控制器下移至内核态、向量指令支持、hypercall指令支持、硬件PMU支持等功能。
内存冷页识别再创新,精准跨 NUMA 数据访问监控
Linux对内存冷页识别一般通过对页表项不停扫描确定页表项标志位发生变化,进而确定页面是否被访问,但会损耗CPU资源且可能会产生大量page fault,并且识别精准度和效率不高。
为了实现基于硬件的页面访问采集框架,轻量级精确识别冷热页,用于提高应用性能以及调高整机的内存复用率。华为OS内核实验室操作系统工程师左泽分享了ARM64 SPE 在 numa balance 和 damon 中的实践,提出了使用 SPE 硬件采样替代传统页表扫描的方式,实现更精准的冷热页识别。一方面,通过NUMA balance机制结合SPE实现一种精准跨NUMA数据访问监控方法,在内核态实现进程跨NUMA内存页精准快速迁移,减少应用进程跨numa访问,提升性能。另一方面使用DAMON机制结合SPE实现一种精准的冷数据页识别方法,在内核态实现冷数据页的精准回收,减少refault,降低主动回收时对业务性能影响,提升整机性价比。
其核心技术点为以下四个方面:
•硬件抽象层:剥离perf硬件驱动,统一配置接口,适配各类硬件,使用优先级管理场景,perf优先使用
•数据抽象层:各场景创建回调函数,各场景按需使用采样数据,实现采样数据共享
•轻量级控制及采集:简化decode流程,进程切换时使能SPE能力,实现per-task级别的SPE控制
•数据管理套件:灵活的机制切换,基于业务指标,SPE参数自调节
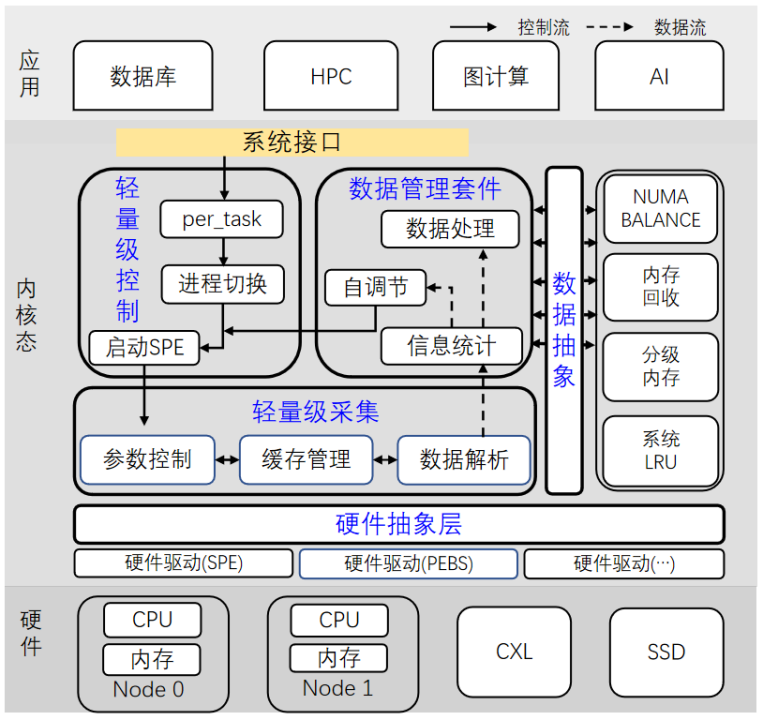
该方案在多场景实现高效稳定的内存回收,相较于原生方案,NUMA balance机制结合SPE方案采用过滤机制去除无效的中断采样,其性能相对于原生方案有较大的提升。DAMON结合SPE的内存回收在同等回收量下,对Mysql性能基本无影响,Mysql测试集性能存在5%左右波动,只写场景,SPE最高回收量约20%。
阿里平头哥 RISC-V 新32位 ABI 进展
新32位 ABI 并不是一个新鲜的话题,为了追求极致的 benchmarking,在过去的十几年间,各大架构都在 Linux 上做过尝试,譬如 x86-x32,mips-n32,和 arm64-ilp32,但没有一个获得生态上的成功。如今,市场上不断涌现基于 RV64 ISA 的小内存硬件产品,用户希望在这些硬件上运行 32位软件,以满足市场对性能和成本的双重需求。
本次阿里平头哥郭任分享了RISC-V 新32位 ABI 进展,郭任指出,相比过去的新32位 ABI 实践,rv64ilp32 有三个创新点:
1.首次实现了新32位内核态,而其他架构仅支持用户态。
2.提出新的栈布局方案,减半内存开销,并提高出入栈性能。
3.首次实现符号扩展寻址技术。
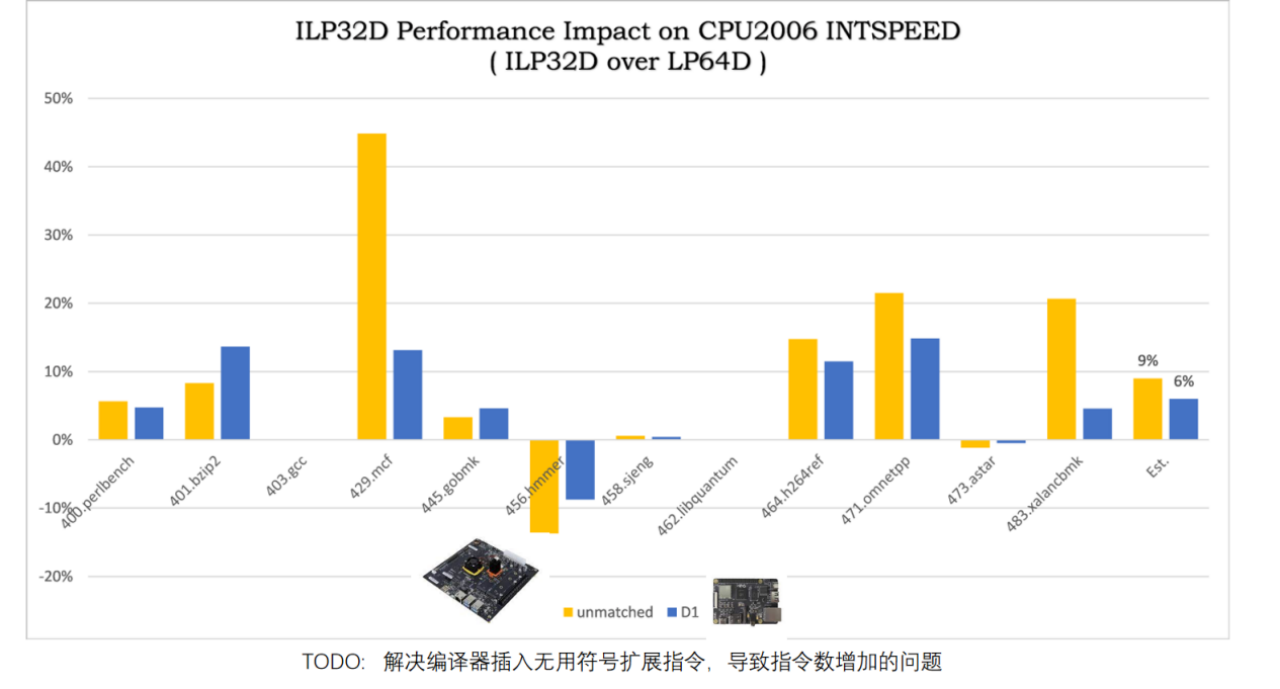
基于 RV64 ISA 的新32位内核拥有双字访存指令 LD/SD,而基于 RV32 ISA 的老32位内核仅有单字访存指令 LW/SW,导致老32位内核访存性能大幅落后新32位。内核访存能力直接决定网络性能,系统性能,和驱动性能
通过大量实验数据对比,ILP32D 相比SPEC CPU2006 可以实现 40%的最大提升。
软硬结合,驱动云和服务器创新场景
作为Linux内核优化的重要场景,云和服务器场景如何实现软硬协同,深度优化?这个问题困扰了很多资深工程师,而本次阿里云资深技术专家宋卓在主会场带来了操作系统软硬件协同和面向云场景深度优化的分享。
操作系统软硬件协同和面向云场景深度优化
宋卓主要分享了基于阿里云数据中心 ARMv9 处理器倚天 710, 从芯片 Pre-silicon 阶段到产品化和规模化的操作系统软硬件协同研发,联合芯片验证,包括操作系统产品化内核和编译优化等,同时围绕可靠性和性能,介绍和云场景深度结合的基础软件实践经验和体会。
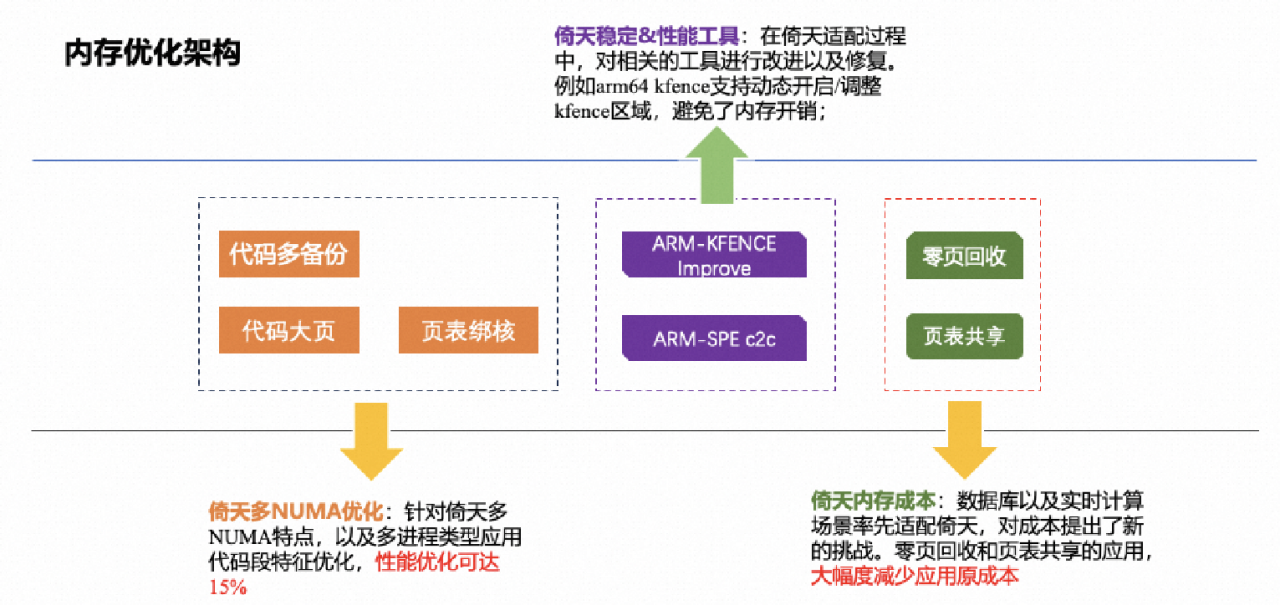
宋卓举例介绍,通过利用ARM RAS Extension和X86 MCA硬件特性,通过内核和Hypervisor支持虚拟机内存故障隔离,区分AR/AO错误,避免整机宕机,其他租户虚拟机通过热迁移无感知。利用PCIe通知式热插拔,单盘故障维修替换在线完成,避免整机线下导致的同一节点上应用影响和应用迁移。利用AEST支持ARM平台支持Kernel First故障上报,收集CE错误。利用DPC隔离PCIe AER错误,避免整机宕机,将单卡故障硬件范围缩小到单个租户等多种手段,结合云场景,芯片+BIOS+内核+虚拟化全栈针对 ARM 架构提升 RAS 能力,有效降低宕机率。

未来,相关团队会坚持拥抱开源,坚持开放,促进合作,持续通过内核、编译全面优化提升倚天平台。
面向领域加速器的通用内存管理
领域加速器往往都支持虚拟内存,这是为了可编程性以及资源隔离。尽管操作系统已经支持内存管理,由于Linux中的内存管理模块不能被轻易地重用于加速器。所以,新型加速器的驱动都在不停地重造轮子,这种现象使得OS中的内存管理代码不断增长,引入了大量代码冗余以及新的bug。
华为操作系统技术专家朱维希在《GMEM:面向领域加速器的通用内存管理》中,通过介绍GMEM的设计,讨论加速器驱动要怎样与GMEM集成,展示GMEM在已有的加速器上的应用,分享介绍了一种创新的通用内存管理机制,GMEM (Generalized Memory Management)。
GMEM可以将CPU相关的硬件处理与硬件无关的内存管理机制彻底解耦开,允许加速器驱动注册他们的硬件特有函数,从而允许OS管理加速器的内存。
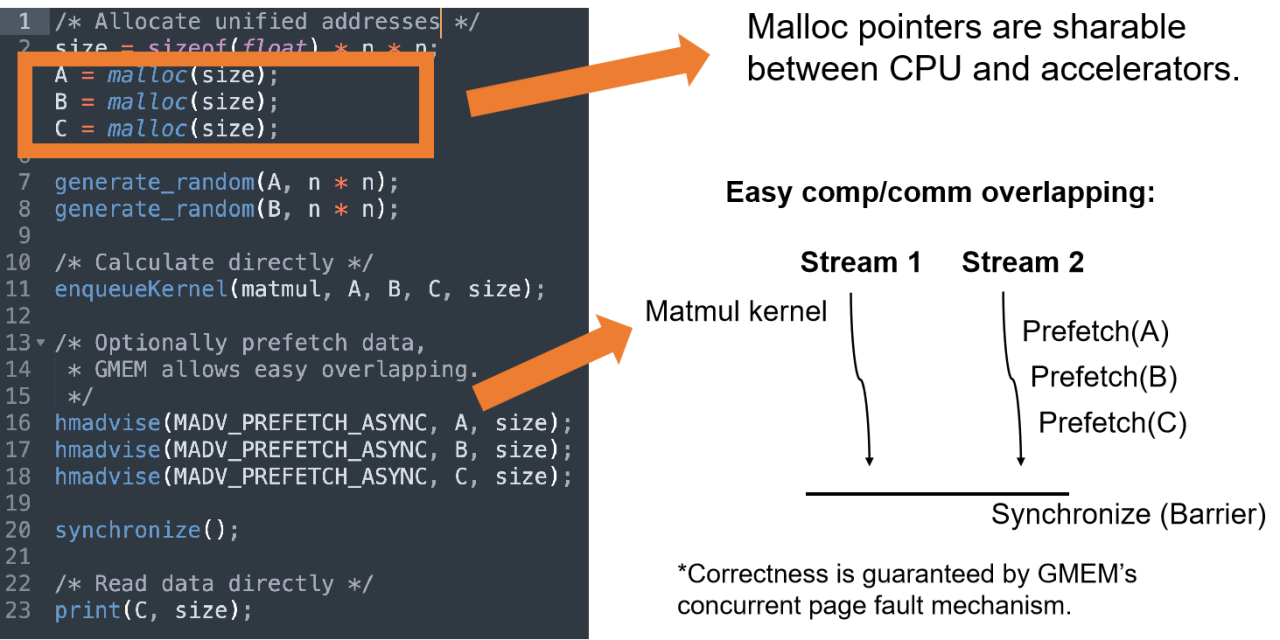
进一步地来讲,GMEM为加速器提供了更好的可编程性 – 允许开发者使用统一地址空间变成CPU级加速器。此外,开发者编程时无需受到加速器内存容量的限制,可以不加一行代码地使用CPU DRAM作为加速器的内存池。
Huge Page大页机制,深度优化内存效率
内存作为宝贵的系统资源,一般都采用延迟分配的方式,应用程序第一次向分配的内存写入数据的时候会触发 Page Fault,此时才会真正地分配物理页,并将物理页帧填入页表,从而与虚拟地址建立映射。
页的默认大小一般为 4K, 随着应用程序越来越庞大,使用的内存越来越多,内存的分配与地址翻译对性能的影响越加明显,Linux 内核提供了大页机制,可以大幅提升内存分配与地址翻译的速度。针对Huge Page大页机制优化,OPPO高级底层软件工程师韩传华、字节跳动系统部STE(System Technology & Engineering)团队路旭带来了相关技术分享。
移动场景动态大页优化,减少缺页异常
现有大页技术目前主要应用于服务器领域,HugeTLB、THP等大页方案在移动端的表现并不友好,换言之,Android手机领域没有成熟的可借鉴方案。
对于移动场景动态大页的必要性不言而喻,OPPO高级底层软件工程师韩传华在《动态大页:基于ARM64 contiguous PTE的64KB HugePage/Large Folios》课题中阐述了OPPO的动态大页方案。
OPPO的动态大页利用arm64平台上的CONT-PTE硬件特性,通过最后一级页表的16个连续的页表项来实现64k动态大页。16个pte只需要一个tlb表项。动态大小页混合,采用4KB的页粒度,CONT-PTE构建64KB大页的形式。
OPPO动态大页方案实现了大页整体swapin/swapout、异步回收/大小页平衡、大页池管理、双lru系统等优化措施,提高效率,并通过双zRAM系统,大小页独立压缩解压,大幅提升了压缩率,并且能较好地覆盖缺页异常处理。
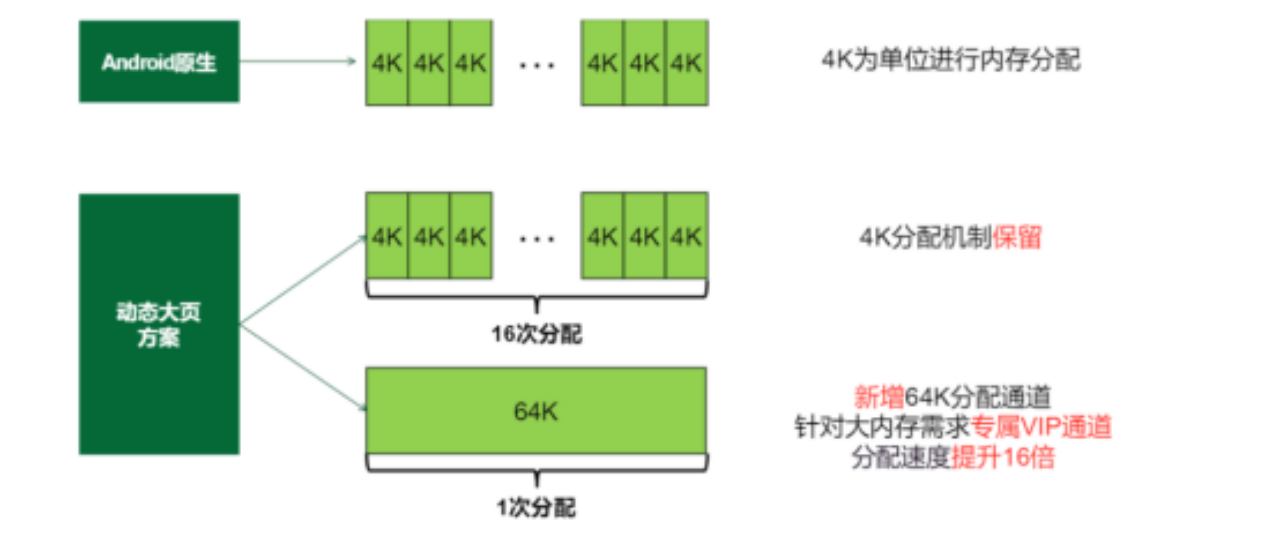
韩传华介绍,与4K页粒度相比,64K动态大页在内部实验室的性能表现非常优秀,其中dtlb miss率降50%+,缺页次数降低89%,缺页频率下降56%,执行指令数下降75.2%
对于用户角度,内存压缩率提升30%+,16GB机器多后台重载场景压缩节省800M+,丢帧减少提升35%+,连续启动应用效率提升10%+。
RISC-V 64K基础页的设计与实现
为了提升应用性能,提高TLB命中率,字节跳动系统部STE(System Technology & Engineering)团队路旭带来《RISCV 64K PAGE SIZE支持》课题分享。
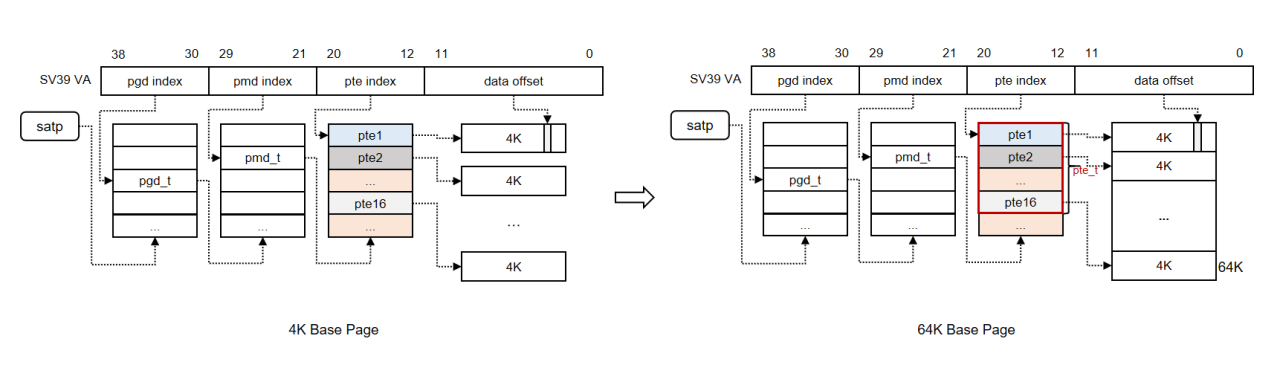
字节跳动STE团队在RISC-V现有的4K页的基础上,基于Svnapot机制,用软件方式模拟实现了64K基础业。Svnapot机制允许进程在映射某块连续物理内存时,若所有leaf pte权限均相同,可采用特殊编码方式,使用相同的pte值。针对该类型映射,TLB只需缓存一份PTE,MMU通过虚拟地址计算目的地址在连续内存中的偏移。该方案的64K基础页默认采用Svnapot机制进行基础页映射,以此节省TLB空间,减小TLB miss率。针对页表页,通过复用基础页弥补MMU 4K页表页与64K基础页之间的差距。
此外,本次大会主办方OPPO还公布了可编程内核技术方向,作为 OPPO 面向未来的技术,可编程内核是对底层技术的重大改造,这或将极大程度提升虚拟机运行效率,从底层解决安卓卡顿问题,引领安卓流畅体验细节比拼。未来ColorOS会持续在可编程内核上演进,聚焦可编程调度器、可编程内存管理、可编程IO调度、可编程同步机制等领域,持续深耕,对硬件做到极致的优化,值得期待。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











