







【CSDN 编者按】在数字通信的世界里,人们经常使用表情符号来让对话变得更加生动有趣。但你是否曾想过,这些看似简单的表情符号背后可能隐藏着一些秘密数据?本文作者听闻这一可能性后,亲测发现:在普通文本或表情符号中,真的可以嵌入不可见的数据,实现信息的隐蔽传输。
作者 | Paul Butler 翻译 | 郑丽媛
出品 | CSDN(ID:CSDNnews)
最近,有个网友在 Hacker News 上的评论引起了我的兴趣:
“理论上,使用零宽度连接符(ZWJ)序列,你可以在一个表情符号中编码无限量的数据。”
那么,真的可以在一个表情符号中编码任意数据吗?
我试了一下,真的可以——只不过我用的方法并不需要 ZWJ,而且在任何 Unicode 字符中都可以编码数据。

背景介绍
Unicode 以代码点的序列形式表示文本,每个代码点基本上只是一个数字,由 Unicode 联盟为其赋予特定含义。通常来说,一个具体的代码点会写成 U+XXXXXXXX,其中 XXXXXXXX 是用大写的十六进制表示的数字。
对于简单的拉丁字母文本,Unicode 代码点和屏幕上显示的字符之间存在一一对应的关系。例如,U+0067 代表字符“g”。
对于其他书写系统,某些屏幕上显示的字符可能由多个代码点表示。例如,印地语中的 की 字符就是由连续的两个代码点 U+0915 和 U+0940 组合而成。

变体选择器
Unicode 指定了 256 个代码点作为“变体选择器”,从 VS-1 到 VS-256。这些选择器本身没有屏幕显示的表现形式,而是用于修改前一个字符的显示效果。
大多数 Unicode 字符并没有与之关联的变体。由于 Unicode 是一个不断发展的标准,并且旨在保持未来兼容性,因此即使代码处理程序不了解其含义,也应保留变体选择器。例如,代码点“g”(U+0067)后面跟着 VS-2(U+FE01)时,显示为小写的“g”,与单独的“g”(U+0067)完全相同。但如果你复制并粘贴它,变异选择器会随之一起被复制。
既然 256 正好是一个字节的变体数量,这就为我们提供了一种方法,可以在任何其他 Unicode 代码点中“隐藏”一个字节的数据。
实际上,Unicode 规范中并未明确提到多个变体选择器的序列,只是暗示在渲染过程中应该忽略它们——所以,你明白我的意思了吗?
我们可以将一系列变体选择器连接起来,表示任意的字节字符串。
例如,假设我们想要编码数据“hello”,它对应的字节值是 [0x68, 0x65, 0x6c, 0x6c, 0x6f]。我们可以通过将每个字节转换为对应的变体选择器,然后将它们串联起来。
变体选择器的代码点被分为两段:最初的 16 个在 U+FE00 到 U+FE0F 之间,其余的 240 个在 U+E0100 到 U+E01EF 之间。
为了将一个字节转换为变体选择器,我们可以使用如下的 Rust 代码:
fn byte_to_variation_selector(byte: u8) -> char {
if byte < 16 {
char::from_u32(0xFE00 + byte as u32).unwrap()
} else {
char::from_u32(0xE0100 + (byte - 16) as u32).unwrap()
}
}然后,要编码一系列字节,我们可以在一个基础字符后面连接多个这样的变体选择器:
fn encode(base: char, bytes: &[u8]) -> String {
let mut result = String::new();
result.push(base);
for byte in bytes {
result.push(byte_to_variation_selector(*byte));
}
result
}为了编码字节 [0x68, 0x65, 0x6c, 0x6c, 0x6f],我们可以运行以下代码:
fn main() {
println!("{}", encode('😊', &[0x68, 0x65, 0x6c, 0x6c, 0x6f]));
}这将输出:
😊󠅘󠅕󠅜󠅜󠅟乍看之下,它就像一个普通的表情符号,但试着将其粘贴到解码器中看看。
如果我们改用调试格式化器,就可以看到发生了什么:
fn main() {
println!("{:?}", encode('😊', &[0x68, 0x65, 0x6c, 0x6c, 0x6f]));
}输出为:
"😊\u{e0158}\u{e0155}\u{e015c}\u{e015c}\u{e015f}"很显然,这揭示了在原始输出中“隐藏”的字符。

如何解码?
解码过程同样也非常简单:
fn variation_selector_to_byte(variation_selector: char) -> Option<u8> {
let variation_selector = variation_selector as u32;
if (0xFE00..=0xFE0F).contains(&variation_selector) {
Some((variation_selector - 0xFE00) as u8)
} else if (0xE0100..=0xE01EF).contains(&variation_selector) {
Some((variation_selector - 0xE0100 + 16) as u8)
} else {
None
}
}
fn decode(variation_selectors: &str) -> Vec<u8> {
let mut result = Vec::new();
for variation_selector in variation_selectors.chars() {
if let Some(byte) = variation_selector_to_byte(variation_selector) {
result.push(byte);
} else if !result.is_empty() {
return result;
}
// note: we ignore non-variation selectors until we have
// encountered the first one, as a way of skipping the "base
// character".
}
result
}使用示例如下:
use std::str::from_utf8;
fn main() {
let result = encode('😊', &[0x68, 0x65, 0x6c, 0x6c, 0x6f]);
println!("{:?}", from_utf8(&decode(&result)).unwrap()); // "hello"
}请注意,基础字符不一定是表情符号——变体选择器的处理方式对于常规字符也是一样的,只不过用表情符号看起来更有趣。

这种方法会被滥用吗?
准确来说,这确实是对 Unicode 的一种滥用——如果你的脑海中正在考虑这种技术的实际用途,请打消这个念头。
话虽如此,我还是想到了几种可能的恶意用途:
(1)绕过人工内容审核过滤器:由于这种方式编码的数据在渲染后不可见,人工审核员将无法察觉这些数据的存在。
(2)给文本添加水印:有些技术可以利用文本中的微妙变化给消息添加“水印”,以便在消息被发送给多人后泄露时,可以追踪到原始接收者。变体选择器序列提供了一种持久化的方式,能够经受住大多数复制/粘贴操作,且允许存储任意密度的数据。如果你愿意,甚至可以对每个字符进行标记。

LLM 能解码吗?
自从这篇文章出现在 Hacker News 后,有些人开始问 LLM(大语言模型)能否处理这种隐藏数据。
一般来说,分词器确实似乎会将变体选择器作为标记保留下来,因此理论上模型是可以访问它们的。OpenAI 的分词器就是一个很好的例子:
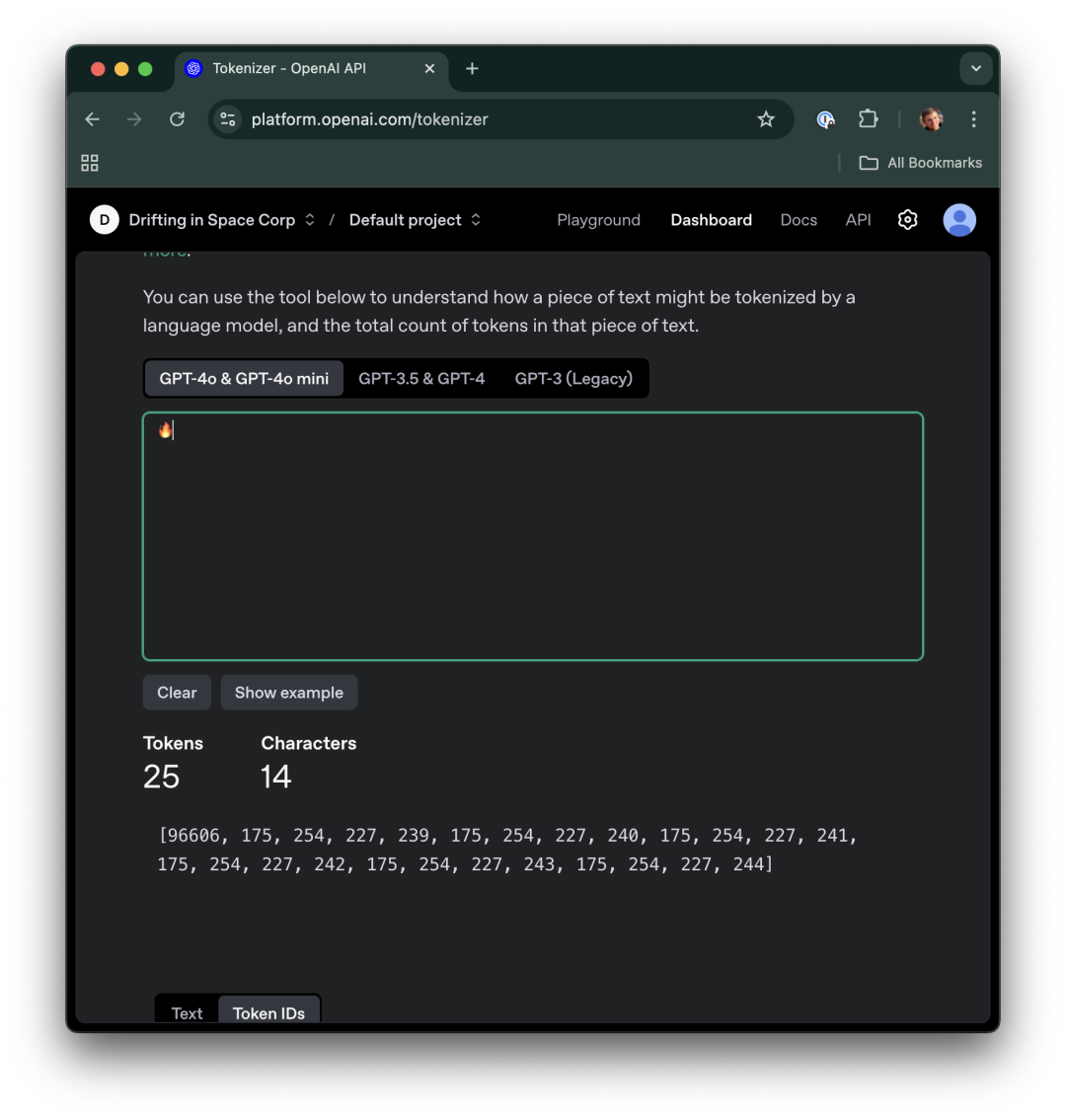
可总体来说,模型并不会主动解码这些数据——不过当与代码解释器结合使用时,有一些模型能够成功解码它们。以下是 Gemini 2 Flash 在 7 秒内成功解码的示例,使用了 Codename Goose 和 foreverVM(免责声明:我在 foreverVM 团队中工作)。
原文链接:https://paulbutler.org/2025/smuggling-arbitrary-data-through-an-emoji/
推荐阅读:
▶6MB PDF竟能运行Linux?这名高中生在PDF里玩DOOM后,再“整活”!
▶974亿美元!马斯克欲收购OpenAI,遭Altman吐槽:不如我97.4亿美元买下推特?
▶六年诈骗6000万美元!知名AI初创公司前CEO被捕:公司账户“只剩37美分”,或面临60+年监禁



















 24万+
24万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











