







整理 | 郑丽媛
出品 | CSDN(ID:CSDNnews)
在 AI 计算资源日益紧张的今天,如何在资源受限的设备上运行大语言模型(LLM)成为了许多开发者关注的焦点,也是他们探索的方向:Exo 工具可以在日常使用的设备上运行自己的 AI 集群、Radxa 也发布了在单板计算机上运行 DeepSeek R1 的教程……这些尝试都表明,将 LLM 部署到轻量级硬件上并非不可能。
于是在这种背景下,近来技术爱好者 Binh Pham 开始了新一轮“硬核改造”:他成功在树莓派 Zero W 上实现了本地运行 LLM,并将其封装进了一个 USB 设备,命名为 LLMStick。

某种程度上,你也可以把它看作是一款“AI U 盘”:用户只需将其插入电脑,就可以通过创建文本文件的方式与 LLM 交互,无需任何技术背景。

树莓派 Zero W:在极限环境下的 LLM 挑战
大体来说,这款自制的 AI U 盘外壳由 3D 打印而成,内部搭载了一块树莓派 Zero W 单板计算机,并配备了一块扩展板,以增加 USB 接口,使其能够直接插入主机使用。
其中,树莓派 Zero W 诞生于 2017 年,距今已有 8 年历史,其硬件规格十分有限:
● CPU:Broadcom BCM2835(ARMv6 架构,单核 1GHz)
● RAM:512MB
● 802.11n WiFi + 蓝牙 4.1(BLE)

相比之下,如今许多主流 LLM 依赖于 ARMv8-A 架构,并且通常需要 GPU 或 NPU(神经网络处理单元) 来加速推理计算——很显然,Binh Pham 选择的树莓派 Zero W 完全没有这些硬件优化。

源码魔改:llama.zero 诞生
为了让 LLM 在极限硬件上运行,Binh Pham 最初选择了 llama.cpp 作为推理引擎。
llama.cpp 是一个专为资源受限设备优化的开源 LLM 推理框架,能够在 CPU 上运行 Meta Llama 等大语言模型。可即便如此,在树莓派 Zero W 上运行 llama.cpp 依然困难重重,其中最大的障碍是:由于树莓派 Zero W 使用的是 ARMv6 架构,而 llama.cpp 的代码优化仅针对 ARMv8-A 及以上——这种架构差异会导致编译错误,因为 llama.cpp 依赖于特定的 Arm Neon 指令集,而这在树莓派 Zero W 的处理器上不可用。
面对这一挑战,Binh Pham 选择了一条十分硬核的解决方案——直接修改 llama.cpp 的源码,手动删除或调整所有不兼容 ARMv6 的部分。这意味着:
● 逐行审查源码,替换或移除了所有依赖于 ARMv8 架构的优化部分;
● 调整数据处理逻辑,使代码适配 ARMv6 指令集,确保在老旧架构上依然可以正常编译和运行;
● 优化编译流程,确保树莓派 Zero W 有限的内存不会导致编译崩溃。
这项工作不仅需要深厚的 ARM 架构知识,还要求对 llama.cpp 的底层实现极度熟悉。整个修改过程耗时数周,最终,Binh Pham 成功编写了一个适用于 ARMv6 的精简版 llama.cpp,并将其命名为 llama.zero。
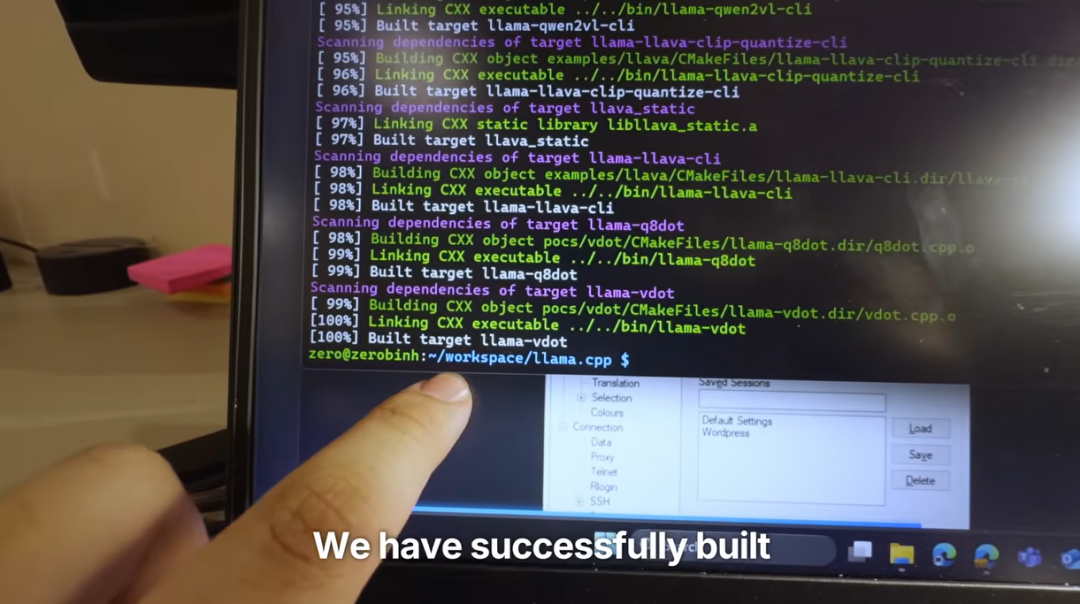

打造 LLMStick:即插即用的 USB AI 设备
解决架构兼容问题后,Pham 进一步优化了 LLM 交互方式。他选择让树莓派 Zero W 运行在 USB Gadget Mode(USB 设备模式)下,这样设备可以被识别为一个 USB 存储设备,实现无缝交互。
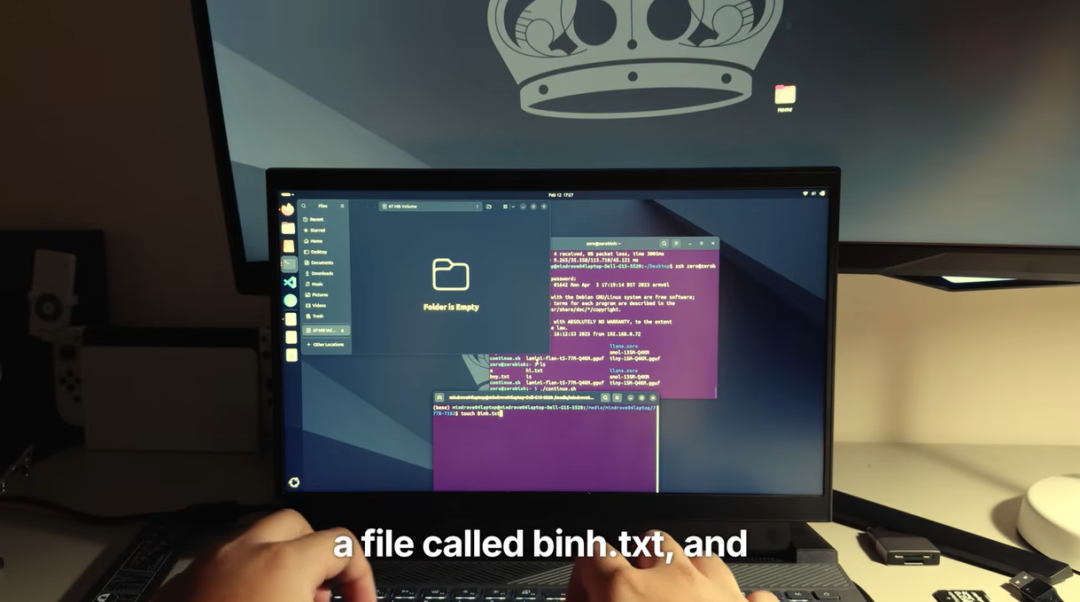
具体来说,LLMStick 的使用方式非常简单:
(1)将 LLMStick 插入电脑的 USB 端口,它会显示为一个存储设备。
(2)用户在 USB 盘中创建一个文本文件,输入 prompt(提示词)。
(3)LLMStick 运行 llama.zero 进行推理计算,然后将生成的文本写回文件。
这种设计有效地将树莓派 Zero W 转变为一个便携式即插即用的 AI USB 设备,用户可以随时随地进行离线推理,而不需要专门的软件界面。

运行效果:性能堪忧,远未达到实用标准
不过,尽管 Binh Pham 确实成功地在树莓派 Zero W 上运行了LLM,但其性能表现仍然存在局限性。在实际测试中,Binh Pham 使用 15M 到 136M 等参数规模不同的 LLM 模型,并设定 64 tokens 为生成上限,最终测试结果如下:
● Tiny15M 模型:每个 token 生成时间为 223ms;
● Lamini-T5-Flan-77M 模型:每个 token 生成时间为 2.5s;
● SmolLM2-136M 模型:每个 token 生成时间为 2.2s。
从这些数据可以看出,即使是最小的模型,其生成速度仍然难以支撑实际应用,而规模较大的模型其速度则几乎慢得无法接受——Binh Pham 的实验虽然具有探索意义,但对于许多实际应用场景来说,在老旧、低功耗硬件上运行 LLM 并不现实。
许多开发者注意到了 Binh Pham 的这个项目,并提出了一个值得思考的问题:为什么不直接使用树莓派 Zero 2W 呢?显然,如果目标仅是实现 LLM 运行,树莓派 Zero 2W 是更好的选择:采用 ARMv8 架构,能直接运行 llama.cpp,无需大幅修改源码;四核 Cortex-A53 性能更强,能够运行更大的 LLM,提升推理速度;两者尺寸相同,Zero 2W 可作为 Zero W 的近乎无缝替代品。
然而,Binh Pham 依然坚持使用树莓派 Zero W,不少人猜测他可能是为了增加挑战性,也可能是想向开发者证明:即使是 8 年前的硬件,也能在合理优化后运行 LLM。
目前,Binh Pham 已经在 GitHub 上开源了 llama.zero 项目,并提供了完整的 llama.zero 编译教程和如何将树莓派 Zero W 作为 USB 设备使用的指南,感兴趣的开发者可前往查看:https://github.com/pham-tuan-binh/llama.zero。
参考链接:
https://www.tomshardware.com/raspberry-pi/raspberry-pi-zero/pi-zero-llm-usb-stick
https://www.cnx-software.com/2025/02/20/llmstick-an-ai-and-llm-usb-device-based-on-raspberry-pi-zero-w-and-optimized-llama-cpp/
推荐阅读:
▶离职5个月,OpenAI前CTO“自立门户”,疯狂挖角老东家:29人团队中,2/3是ChatGPT骨干!
▶20万张GPU!号称“地球上最聪明的AI”Grok-3来了,斩获多个Top1,网友:算力消耗是DeepSeek V3的263倍



















 893
893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











