






移动云代码大模型实现问答能力全面升级!通过成功复现DeepSeek-R1模型推理能力,移动云代码大模型现已具备深度思考与逻辑分析能力,和它交流就像跟学霸聊天,又智能又靠谱!
移动云代码大模型成功迁移DeepSeek推理能力
升级后的超能力有多牛?
这次升级,移动云代码大模型收获了好多厉害的技能点:
✦清晰展现模型推理路径,显著增强了模型对复杂问题的分析与解决能力,使决策过程更加透明、可解释。
✦提升模型复杂推理能力,复杂场景代码生成任务准确率提升5%,代码修复任务成功率提升3%,让广大码农开发效率up up!
✦小资源短时间内快速提升,依托移动云智算平台,仅用两天完成训练,实现问答能力提升,充分体现了模型训练的高效性与性价比。
纯干货来了!下面以移动云代码大模型为例,手把手教你如何让大模型,具备DeepSeek推理能力。
第一步
精心挑选 “学习资料”(Prompt 数据准备)
要想让大模型变聪明,得先给它找合适的 “学习资料”。开发团队专门挑了代码生成、代码修复这些场景的数据,这些都是大模型在实际工作中经常会遇到的 “难题”。
挑数据的时候也很讲究,开发团队用打分模型给每个样本 “打分评级”,把那些有难度、能锻炼大模型思维的样本选出来,这些可都是精华!
第二步
打造超棒的 “学习秘籍”(思维链数据合成)
有了好资料,还得把它们变成更好的“学习秘籍”。团队调用移动云智算平台上的 DeepSeek-R1 模型,用代码数据生成带有思维链的问答数据对。这就好比给大模型准备了详细的解题思路,告诉它遇到问题该怎么想。
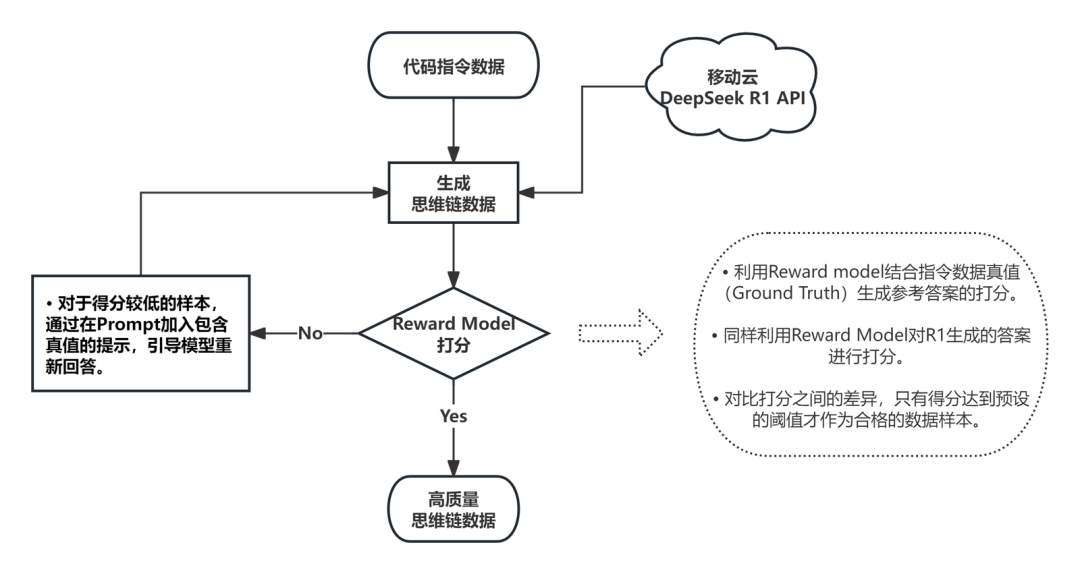
为了让 “秘籍” 更完美,他们还用 Reward Model 评估答案质量。要是答案不太对,就把这个问题当作 “高价值挑战题”,在提示里给大模型一些小线索,让它重新思考,直到给出正确答案。这样反复打磨,数据质量越来越好,大模型的学习能力也更强啦。
生成的数据也有统一格式,用标签把大模型的思考过程标出来,其他部分和原来的问题数据放在一起。这样后面学习的时候,大模型能更快理解,推理过程也能看得明明白白。
第三步
合理搭配 “营养套餐”(训练数据配比)
思维链数据虽然好,但很“吃” 算力资源。为了让大模型既能学到好东西,又更高效地利用资源,团队想了个巧妙的办法——把少量高质量的思维链数据和普通指令数据混在一起训练。
就像吃饭要营养均衡一样,不同场景的数据也要合理搭配。对于思维链数据,他们适当提高了采样比例,大概占总训练数据的10%,这样既能充分利用思维链数据的优势,又能提升训练效率。
第四步
开启 “特训模式”(模型训练)
一切准备就绪,大模型开始“特训”!团队采用指令微调的方法,就像给大模型开小灶,针对不同的数据用不同的提示词模板。
碰到思维链数据,就参考 DeepSeek-R1 的提示词模板,引导大模型深度思考;遇到普通指令数据,就用默认模板,保证大模型在常规任务上也能稳定发挥。
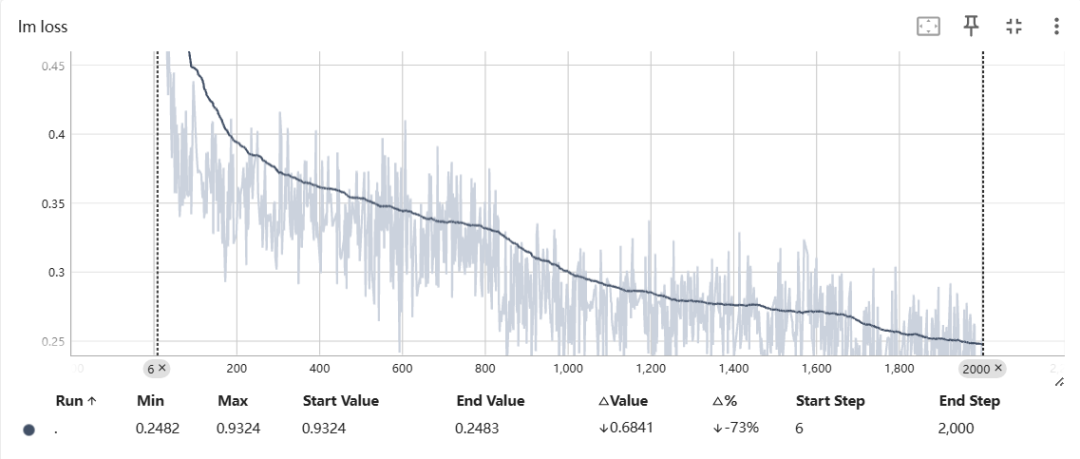
这个“特训”在移动云智算集群上进行,仅仅2天,大模型就完成了带有思维链的训练,成功 “毕业”,各项指标都达到预期!
第五步
“期末考试” 来检验(推理验证)
经过前面的学习,大模型到底有没有真的变聪明呢?来一场 “期末考试” 就知道啦!团队用“3.8 和3.11哪个大” 这个经典问题测试。
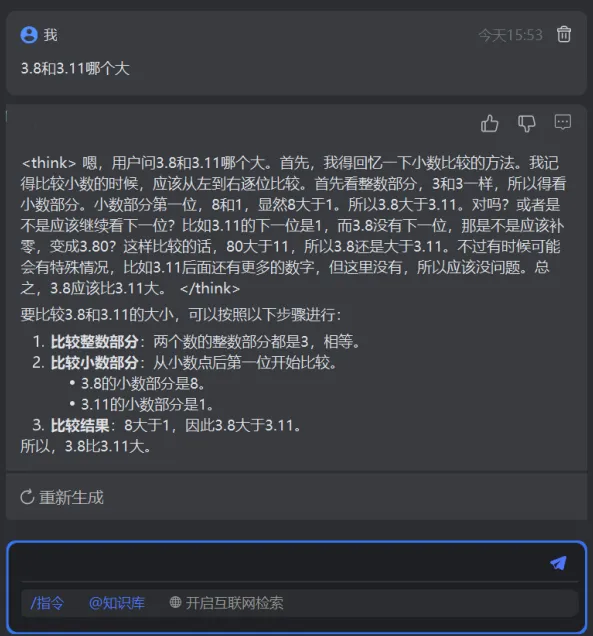
以前的非推理版本回答起来逻辑混乱,而现在学会推理的大模型,不仅思考过程严谨,还能一步步把比较大小的方法说清楚,轻轻松松就得出正确答案!
这次移动云代码大模型的升级,不仅显著提升了模型在核心任务上的性能,还将为后续模型优化与能力扩展奠定了坚实基础。未来,移动云将继续深耕AI技术创新,为用户提供更智能、更高效的代码解决方案。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











