




大模型全面迈入“长上下文、低成本、高推理”阶段。
MiniMax 正式开源其首个推理模型 M1,原生支持百万级上下文长度,在推理效率、计算成本和复杂任务能力上展现出与 DeepSeek R1、Qwen3-235B 等模型不同的技术路径与性能表现。
责编 | 梦依丹
出品丨AI 科技大本营(ID:rgznai100)
国内 AI 六小虎之一的 MiniMax 在其官方 X 平台宣布,正式开源其最新研发的大语言模型 MiniMax-M1。此举作为其“MiniMaxWeek”系列发布活动的首日亮点。
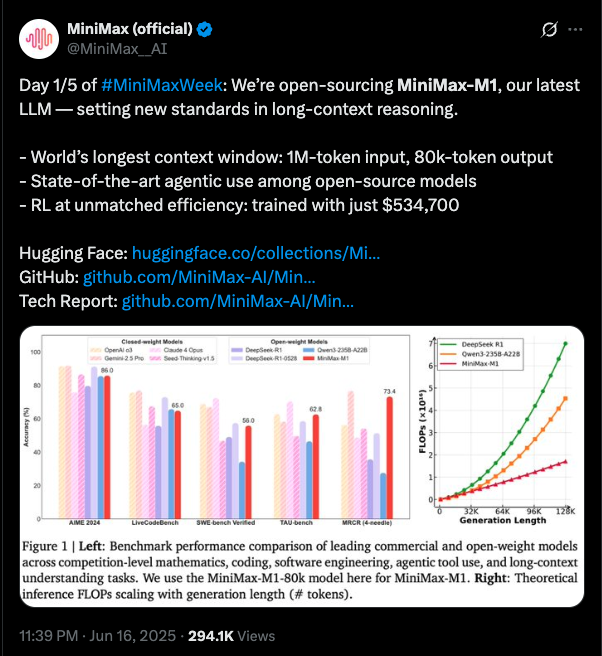
MiniMax-M1 被称为是全球首个开放权重的大规模混合注意力推理模型。凭借混合门控专家架构(Mixture-of-Experts,MoE)与 Lightning Attention 的结合,MiniMax-M1 在性能表现和推理效率方面实现了显著突破。
相关链接:
-
Hugging Face:https://huggingface.co/collections/MiniMaxAI/minimax-m1-68502ad9634ec0eeac8cf094
-
GitHub: https://github.com/MiniMax-AI/MiniMax-M1
-
Tech Report: https://github.com/MiniMax-AI/MiniMax-M1/blob/main/MiniMax_M1_tech_report.pdf

M1 上下文 8 倍 DeepSeek,计算量仅 1/4,性能与效率双杀
M1 是基于此前发布的 MiniMax-Text-01 模型打造,具备 4560 亿参数规模,其中每个 token 激活约 459 亿参数。模型原生支持最长 100 万 tokens 的上下文输入,是 DeepSeek R1 所支持长度的 8 倍。
此外,得益于其高效的 Lightning Attention 机制,在生成长度为 10 万 tokens 的场景下,MiniMax-M1 的计算量(FLOPs)仅为 DeepSeek R1 的 25%,在长文本处理任务中具备显著优势。
超 3000 人的「AI 产品及应用交流」社群,不错过 AI 产品风云!诚邀所有 AI 产品及应用从业者、产品经理、开发者和创业者,扫码加群:
进群后,您将有机会得到:

· 最新、最值得关注的 AI 产品资讯及大咖洞见
· 独家视频及文章解读 AGI 时代的产品方法论及实战经验
· 不定期赠送热门 AI 产品邀请码
在训练策略方面,MiniMax-M1 采用大规模强化学习(RL)方式,在数学推理、沙盒环境下的软件工程等多样任务中进行了全面优化。
除了混合注意力机制本身带来的 RL 训练效率提升外,MiniMax 还提出了名为 CISPO 的创新型强化学习算法。
与传统方法不同,CISPO 针对的是重要性采样权重而非 token 更新进行裁剪,有效提升了学习稳定性与性能表现,在对比实验中优于现有主流 RL 变体。
在实际训练中,MiniMax-M1 的完整强化学习训练在 512 块 H800 GPU 上仅耗时三周,成本控制在 53.47 万美元,展现了极高的效率与性价比。
目前,MiniMax-M1 提供两个版本,分别设定 40K 与 80K 的思维预算(thinking budget),其中 40K 版本为中间训练阶段的成果。
在标准基准测试中,MiniMax-M1 在复杂软件工程、工具使用与长上下文任务等方面表现突出,整体表现已达到甚至超越 DeepSeek-R1 与 Qwen3-235B 等代表性开源模型。

直接上手体验
MiniMax-M1 是开源即上线,大家进入 MiniMax 官网即可体验。

官网:https://chat.minimaxi.com/
笔者直接把 MiniMax-M1 技术报告发上去,让其翻译成通俗易懂的中文技术报告。
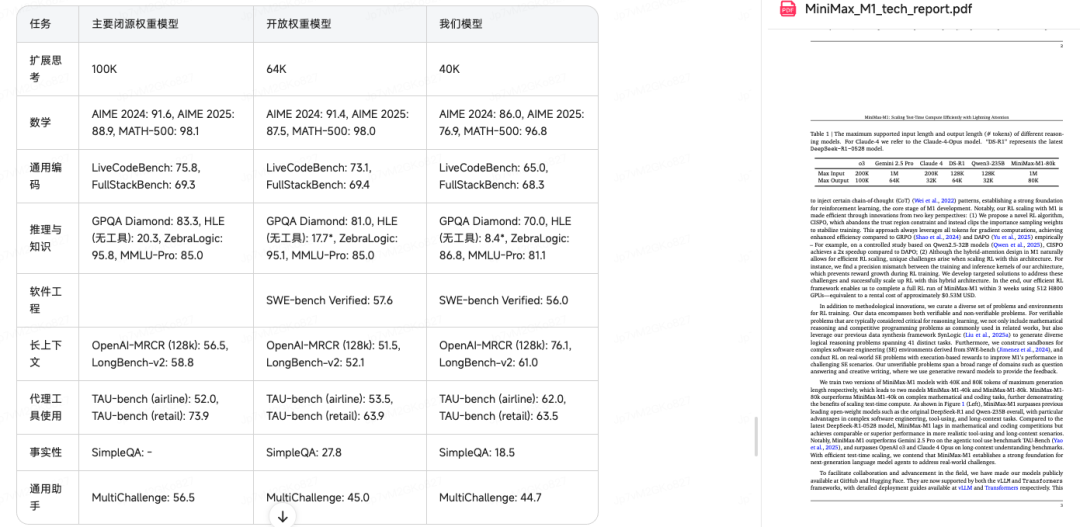
在不到 30 秒的时间,报告里的公式、表格全部放都翻译出来了。

感兴趣的同学可以直接上手体验起来。
📢 2025 全球产品经理大会
8 月 15–16 日
北京·威斯汀酒店
2025 全球产品经理大会将汇聚互联网大厂、AI 创业公司、ToB/ToC 实战一线的产品人,围绕产品设计、用户体验、增长运营、智能落地等核心议题,展开 12 大专题分享,洞察趋势、拆解路径、对话未来。
更多详情与报名,请扫码下方二维码。




















 243
243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











