





Going Deeper in Spiking Neural Networks: VGG and Residual Architectures

郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!
[Front. Neurosci., 07 March 2019]
文章目录
Abstract
在过去的几年里,脉冲神经网络已经成为实现低功率事件驱动神经形态硬件的一种可能途径。然而,它们在机器学习中的应用很大程度上局限于用于简单问题的非常浅的神经网络体系结构。在本文中,我们提出了一种新的算法技术来生成一个具有深度结构的SNN,并证明了它在复杂的视觉识别问题上的有效性,如 CIFAR-10 和 ImageNet。我们的技术适用于 VGG 和残差网络架构,其精确度明显优于现有技术。最后,我们对稀疏事件驱动计算进行了分析,以证明在脉冲域中运行时降低了硬件开销。
1 Introduction
脉冲神经网络是人工神经网络标准操作方式的重大转变(Farabet et al., 2012)。在复杂模式识别任务中,神经网络深度学习模型的大部分成功是基于接收、处理和传输模拟信息的神经单元。然而,这种模拟神经网络(ANNs)了这样一个事实,即大脑中的生物神经元(受其启发的计算框架)处理基于二进制脉冲的信息。在这一观察的推动下,过去几年在神经网络的建模和训练方案制定方面取得了重大进展,神经网络是一种新的计算范式,有可能取代人工神经网络成为下一代神经网络。除了SNN本质上在生物学上更合理的事实之外,它们还提供了事件驱动的硬件操作的前景。脉冲神经元仅在接收到输入的二进制脉冲信号时处理输入信息。给定稀疏分布的输入脉冲序列,这种脉冲或基于事件的硬件开销(功耗)将显著降低,因为不受输入脉冲驱动的网络的大部分可以被功率门控(Chen et al., 1998)。然而,对 SNNs 的绝大多数研究局限于在相对简单的数字识别数据集(如MNIST (LeCun et al., 1998)上的非常简单和浅的网络体系结构,而只有少数作品报告了它们在更复杂的标准视觉数据集(如CIFAR-10 (Krizhevsky和Hinton,2009)和ImageNet ( Rusakovsky et al,2015 ) 上的性能。其有限性能背后的主要原因是,由于其时间信息处理能力,人工神经网络是人工神经网络操作的一个重大转变。这就需要重新思考脉冲神经网络网络的训练机制。
2 Releated Work
大体上,有两个主要类别用于训练SNN——监督的和非监督的。尽管无监督学习机制,如脉冲时序相关可塑性(STDP)对实现低功耗片内局部学习很有吸引力,但它们的性能仍然不如监督网络,即使是在简单的数字识别平台上,如MNIST数据集(Diehl and Cook, 2015)。受这一事实的驱动,一类特殊的监督 SNN 学习算法试图使用标准训练方案来训练人工神经网络,如反向传播(以利用ANN标准训练技术的卓越性能),并随后转换为事件驱动的SNNs (Pérez-Carrasco et al., 2013; Cao et al., 2015; Diehl et al., 2015;Zhao et al., 2015)。这对于在专门用于神经网络的低功率神经形态硬件中实现神经网络特别有吸引力((Merolla et al., 2014; Akopyan et al.,2015)或与硅耳蜗或事件驱动传感器接口(Posch et al., 2011, 2014)。我们的工作属于这一类,并基于作者在Diehl et al.(2015)提出的人工神经网络-SNN转换方案。然而,虽然先前的工作只考虑了转换过程中的人工神经网络操作,但我们表明,考虑转换步骤中的实际SNN操作对于实现分类精度的最小损失至关重要。为此,我们提出了一种新的权重归一化技术,以确保实际的SNN操作在转换阶段处于环路中。请注意,这项工作试图通过将网络转换到脉冲域来利用神经激活稀疏性,以实现节能的硬件实现,并且是对旨在探索突触连接稀疏性的补充 (Han et al.,2015a)。
3 Main Contributions
我们工作的具体贡献如下:
(i)如后面部分所述,训练人工神经网络涉及各种体系结构约束,这些约束可以以接近无损的方式转换为人工神经网络。因此,目前还不清楚所提出的技术是否可以扩展到更大更深的体系结构中,用于更复杂的任务。我们提供概念实验证明,深度 SNN(从16层扩展到34层)可以提供比 CIFAR-10 和 ImageNet 等复杂数据集更具竞争力的精度。
(ii)我们提出了一种新的 ANN -SNN 转换技术,在统计上优于最先进的技术。我们在特定的 CIFAR-10 数据集上报告了8.45%的分类错误,这是迄今为止任何SNN网络报告的最佳性能结果。我们首次报告了整个ImageNet 2012验证集的SNN性能。对于VGG-16架构,我们实现了30.04%的Top-1错误率和10.99%的Top-5错误率。
(补充)
Top-5错误率:一个图片经过网络,得到预测类别的概率,如果概率前五(top-5)中包含正确答案,即认为正确。top-5错误率就是Top-5 = (正确标记 不在 模型输出的前5个最佳标记中的样本数)/ 总样本数。
Top-1错误率:
一个图片,如果概率最大的是正确答案,才认为正确。Top-1 = (正确标记 不是 模型输出的最佳标记的样本数)/ 总样本数。
参考博文:(https://blog.csdn.net/qq_36415932/article/details/83029564?utm_source=app&app_version=4.9.1)
(iii)我们探索残差网络(ResNet)架构,作为实现更深层次SNN的潜在途径。我们提出了确保ANN-SNN转换所需的见解和设计限制。在CIFAR-10数据集上,我们的分类错误率为12.54%,在ImageNet验证集上,34.53% 的Top-1错误率和13.67%的Top-5错误率。这是第一个试图探索具有ResNet架构的SNN的工作。
(iv)我们证明了SNN网络稀疏性随着网络深度的增加而显著增加。这进一步推动了将人工神经网络转换为事件驱动操作的人工神经网络以降低计算开销的探索。
4 Preliminaries
4.1 Input and Output Representation
ANN 和 SNN 操作的主要区别是时间的概念。虽然 ANN 输入是静态的,但 SNN 是基于作为时间函数的动态二进制脉冲输入来运行的。神经节点还在神经网络中接收和传输二进制脉冲输入信号 ,这与 ANN 不同,神经网络中神经节点的输入和输出是模拟值。在这项工作中,我们考虑一个速率编码的网络操作,其中在足够大的时间窗口内作为输入传输到网络的脉冲的平均数量与原始 ANN 输入的大小(在这种情况下是像素强度)近似成比例。时间窗口的持续时间由网络输出层所需的网络性能(例如,分类精度)决定。泊松事件生成过程用于产生网络的输入脉冲序列 。SNN运算的每个时间步长都与随机数的生成相关联,随机数的值与相应输入的幅度进行比较。如果生成的随机数小于相应像素强度的值,则触发脉冲事件。 该过程确保 SNN 中输入脉冲的平均数量与相应的 ANN 输入的像素值成比例,并且通常用于基于静态图像的数据集来模拟用于识别任务的 SNN (Diehl等人,2015)。图1描述了从 CIFAR-10 数据集传输到 SNN 的特定图像的输入峰值的特定定时快照。请注意,由于我们考虑的是每像素平均减去图像,输入层接收到的脉冲信号的速率与输入幅度成比例,符号等于输入符号。然而,对于随后的层,所有脉冲的符号都是正的,因为网络中有脉冲神经元产生。这种网络的 SNN 操作是“伪同时的”,即,特定层立即对来自前一层的输入脉冲进行操作,并且不必等待来自前一层神经元的信息的多个时间步长来累积。假设泊松产生的脉冲序列被馈送到网络,尖峰将在网络输出端产生。推理则是基于给定时间窗口内网络输出层神经元的累积脉冲计数。

最左边的面板描绘了从CIFAR-10数据集减去每个像素平均值(在训练集上)的特定输入图像,该图像被提供作为原始神经网络的输入。中间面板表示从模拟输入图像生成的泊松脉冲序列的特定实例。向SNN提供的超过1000个时间步长的累积事件在最右边的面板中描述。这证明了这样一个事实,即对于SNN操作,输入图像是随时间进行速率编码的。
4.2 ANN and SNN Neural Operation
ANN到SNN的转换方案通常将Rectified Linear Unit(ReLU)作为ANN的激活函数。对于通过突触权重
w
i
w_i
wi的神经元接收输入,ReLU神经元输出 y 由下式给出
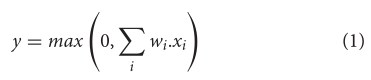
虽然 ReLU 神经元目前通常用于大量的机器学习任务,但是它们用于 ANN-SNN 转换方案背后的主要原因是它们具有与 (IF) 脉冲神经元的功能等效性,而没有任何泄漏和不应期 (Cao et al., 2015; Diehlet al., 2015)。注意,这是一种特殊类型的脉冲神经元模型。让我们考虑将 ANN 输入
x
i
x_i
xi 在时间上编码为脉冲序列
X
i
X_i
Xi (t),其中
X
i
X_i
Xi (t)、E[Xi(t)] ∝
x
i
x_i
xi (对于本文中考虑的速率编码网络)的平均值。IF 脉冲神经元跟踪它的膜电位
V
m
e
n
V_{men}
Vmen,它整合传入的脉冲电位,并在膜电位超过特定阈值
V
t
h
V_{th}
Vth 时产生输出脉冲。在产生输出脉冲时,膜电位被重置为零。每当出现对应于新图像/图案的脉冲序列时,所有神经元都被重置。作为时间步长 t 的函数的 IF 脉冲神经元动力学可以用下面的方程来描述,
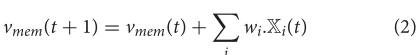
请注意,神经元动力学与时间步长的实际大小无关。让我们首先考虑神经元由单输入
X
(
t
)
X(t)
X(t) 和正突触权重
w
w
w 驱动的简单情况。由于神经动力学中没有任何泄露项,因此直观地证明神经元的相应发放速率由
E
[
Y
(
t
)
]
∝
E
[
X
(
t
)
]
E[Y(t)]∝E[X(t)]
E[Y(t)]∝E[X(t)] 给出,比例因子取决于
w
w
w 和
V
t
h
V_{th}
Vth 的比率。在突触权重为负值的情况下,IF 神经元的输出脉冲活动为零,因为该神经元永远不能越过放电电位
V
t
h
V_{th}
Vth,这反映了ReLU的功能。阈值相对于权重的比率越高,神经元产生脉冲所需的时间就越长,从而降低了神经元脉冲发放速率
E
[
Y
(
t
)
]
E[Y(t)]
E[Y(t)],或者等效地增加了神经元产生脉冲的时间延迟。相对较高的放电阈值可能会导致神经元产生输出脉冲的巨大延迟。 对于深度架构,这样的延迟会迅速积累,并导致网络在相对较长的时间内不会产生任何脉冲输出。另一方面,相对较低的阈值会导致 SNN 脉冲输入累积到膜电位中,导致SNN在不同的阈值之间失去可识别性(公式2中的
∑
i
=
0
ω
i
.
X
i
(
t
)
\sum_{i=0}\omega_i.X_i(t)
∑i=0ωi.Xi(t) ),导致它在膜电位整合过程中失去证据 。(不太理解这句)这又会导致转换后的网络的精度降低。因此,适当选择神经元阈值与突触权重的比率对于确保在ANN-SNN转换过程中将分类精度的损失降至最低至关重要(Diehl et.al,2015年)。因此,这一领域的大部分研究工作都集中在设计合适的阈值平衡算法,或等效地,对网络的不同层进行加权归一化,以实现近无损的ANN-SNN转换。
4.3. Architectural Constraints
4.3.1. Bias in Neural Units
通常, 用于ANN-SNN转换方案的神经单元的训练没有任何偏差项 (Diehl et.al,2015年)。这是因为除了脉冲神经元阈值之外,对偏置项的优化扩大了参数空间的探索,从而使得ANN-SNN转换过程更加困难。 对无偏置神经单元的要求还要求使用 BN (Ioffe and Szegedy,2015) 不能在训练过程中用作正则化,因为它使网络的每一层的输入产生偏差,以确保每一层都具有零均值的输入。相反,我们使用 dropout (Sriastava等人,2014)作为正则化技术。该技术通过利用来自伯努利分布的样本来简单地掩蔽对每一层的输入的一部分,在该分布中,对每一层的每一输入都具有特定的丢弃概率。
4.3.2. Pooling Operation
深层卷积神经网络结构通常由中间池化层组成,以减小卷积输出映射的大小。虽然存在用于执行池化机制的各种选择,但两个流行的选择要么是最大池化(池化窗口上的最大神经元输出),要么是空间平均(池化窗口上的二维平均池化操作)。因为神经元激活值是二进制的,而不是模拟值,执行最大池化在更深的SNN网络中将导致下一层的重大信息损失。因此,我们选用平均池化(Diehl et.al,2015年)。
5. DEEP CONVOLUTIONAL SNN ARCHITECTURES: VGG
如前所述,我们的工作是基于 Diehl et.al,(2015) 其中特定层的神经元阈值被设置为等于对应层中所有ReLU的最大激活(通过在训练完成之后使整个训练集通过训练的ANN一次)。这种“数据归一化”技术在 MNIST 数据集上针对三层完全连接和卷积架构进行了评估(Diehl等人,2015年)。注意,这个过程在本文中被交替地称为“权重归一化”和“阈值平衡”。 如前所述,这项工作的目标是优化突触重量与神经元放电阈值 V t h V_{th} Vth的比率。因此,或者将神经层之前的所有突触权重按等于最大神经激活的归一化因子进行缩放,并且将阈值设置为等于1(“权重归一化”),或者将阈值 V t h V_{th} Vth 设置为等于对应层的最大神经元激活,而突触权重保持不变(“阈值平衡”)。这两种运算在数学上是完全等价的。
5.1 Proposed Algorithm: Spike-Norm
然而,上述算法给我们带来了一个问题:ANN激活是否代表SNN激活?让我们考虑单个 Relu 的最大激活情况的特定示例。神经元接收两个输入,即 0.5 和 1 。在这个场景中,让我们考虑一下单位突触权重。由于最大Relu激活为1.5,因此神经元阈值将被设置为等于1.5。然而,当该网络转换为SNN模式时,两个输入都将传播二进制脉冲信号。等于1的ANN输入将被转换为在每个时间步发送脉冲信号,而另一输入将在足够大的时间窗口的持续时间的50%发送脉冲信号。因此,对于大量样本,神经元每个时间步接收的脉冲输入的实际总和为2,高于阈值(1.5)。显然,由于缺乏证据整合, (证据整合到底啥意思??? )可能会发生一些信息丢失。
根据这一观察,**我们提出了一种权重归一化技术,通过考虑 ANN-SNN 转换过程中SNN的实际操作来平衡每一层的阈值。该算法按顺序对每一层的网络权重进行归一化。 给定一个特定的训练好的神经网络,第一步是在一个足够大的时间窗内,通过训练集为网络生成输入泊松脉冲序列。泊松脉冲序列允许我们记录加权脉冲输入的最大总和。( 等式 2 中的
∑
i
ω
i
.
X
i
(
t
)
\sum_i \omega _i.X_i(t)
∑iωi.Xi(t),下文中称为最大SNN激活 )将被神经网络的第一层接收。为了最小化神经元的时间延迟,同时确保神经元放电阈值不太低,我们根据第一层接收的最大基于脉冲的输入对第一层进行权重归一化。在设置了第一层的阈值之后,在第一层的输出端为我们提供了一个代表性的脉冲序列,这使得我们能够为下一层生成输入脉冲序列。 该过程在网络的所有层上依次继续。我们的做法与以前的工作(Diehl et.al,2015年)之间的主要区别在于,建议的权重标准化方案考虑了转换过程中的实际SNN操作。正如我们将在结果部分显示的那样,该方案对于确保深度显著的体系结构和复杂识别问题的近无损ANN-SNN转换至关重要。我们评估了VGG-16网络(Simonyan 和 Zisserman,2014)的建议,这是一种标准的深度卷积网络架构 ,由3 × 3卷积滤波器组成的16层深度网络组成(具有中间池化层,以随着maps数量的增加降低输出 map 的维数)。算法的伪代码如下。

6. EXTENSION TO RESIDUAL ARCHITECTURES
残差网络结构被提出为将卷积神经网络扩展到非常深一种尝试 (He et。al,2016a) 。虽然已经探索了基本功能单元的不同变体,但在本文中我们将仅考虑 indentity shortcut connections (shortcut type-A according to the paper; He et al. 2016a )。 每个单元由两条并行路径组成。non-identity 路径由具有中间ReLU层的两个空间卷积层组成。虽然原始ResNet公式考虑了并行 non-identity 路径和 identity 路径交界处的ReLU(He等人,2016a),但最近的公式没有考虑网络体系结构中的连接ReLU(He et .al 2016b)。在 non-identity 路径和 identity 路径的交界处没有 ReLU 被观察到,从而在CIFAR-10数据集上产生了分类精度的轻微改善。由于存在 identity连接,需要考虑重要的设计考虑因素,以确保近无损的ANN-SNN转换。我们从基本单元开始,如图2A所示,然后逐点施加各种有理由的架构约束。注意:本节中的讨论基于阈值平衡 (突触权重保持不变) ,即神经元的阈值被调整以减少 ANN-SNN 转换损失。

(A) ResNet基本功能单元。(B)在功能单元中引入设计约束,以确保ANN-SNN近似无损转换。©典型的最大SNN激活的ResNet连接ReLU层,但non-identity 和 identy 输入路径没有相同的脉冲阈值。虽然这并不能代表两个路径中阈值相等的情况,但它确实证明了在初始层数之后,最大SNN激活值由于 **identity mappings(恒等映射)**而衰减到接近统一的值。
6.1. ReLUs at Each Junction Point
正如我们将在结果部分展示的那样,将我们提出的 Spike-norm 算法应用于这样的残差结构导致转换后的SNN与原始训练的ANN相比表现出精度下降。 我们假设这种退化主要归因于交界点没有任何ReLU。每个ReLU转换为IF脉冲神经元时,施加特定数量的特征时间延迟 (由于证据整合,传入脉冲和传出脉冲之间的时间间隔 ) 。由于 shortcut connection,来自初始层的脉冲信息会立即传播到后面的层。网络的两条平行路径中的不平衡时间延迟可能导致通过网络传播的脉冲信息的失真。 因此,如图 2B 所示,我们在每个连接点增加 ReLU,以便为平行路径提供时间平衡效果(当转换为IF脉冲神经元时)。理想的解决方案是在并行路径中包含 ReLU,但这会破坏 identity mappings 的优势。
6.2. Same Threshold of All Fan-In Layers
如下一节所示,与基线 ANN 精度相比,直接应用我们提出的阈值平衡方案仍然会导致一定的精度损失。然而,请注意,连接神经元层接收来自前一连接神经元层以及 non-identity 神经元路径的输入。由于特定神经元的输出脉冲活动还取决于阈值平衡因子,因此所有扇入神经元层应该以相同的量进行阈值平衡,以确保对下一层的输入脉冲信息进行适当的速率编码。然而,non-identity 通路中神经元层的放电阈值依赖于前一个结合处的神经元层的活动。对未使用此约束的网络的典型阈值平衡因素的观察 ( 如图2C所示 ) 显示,阈值平衡因素主要在几个初始层之后保持一致。这主要是由于identity mappings 造成的。交界层神经元接收到的尖峰输入的最大总和由同一性映射(接近于统一)控制。由此,我们试探性地选择了non-identity ReLU层和 identity-ReLU 层的阈值均等于1。然而,精度仍然不能接近基线ANN的精度,这就引出了第三个设计约束。
6.3. Initial Non-residual Pre-processing Layers
图 2C 的观察显示,初始连接神经元层的阈值平衡因子明显高于 1 。这可能是转换后的SNN的分类精度降低的主要原因。我们注意到作者在 ( He et al. 2016a)中使用的残差体系结构。在 ImageNet 数据集上使用具有非常宽的接收范围 ( 7×7,步长为2) 的初始卷积层。这种体系结构背后的主要动机是显示其残差体系结构中不断增加的深度对分类准确性的影响。受 VGG 结构的启发,我们用一系列三个 3×3 的卷积来代替最初的 7×7 卷积层,其中前两层没有任何捷径连接。这些初始的非残差预处理层的加入使得我们可以在初始层应用我们提出的阈值平衡方案,而对后续的残留层使用一个统一的阈值平衡因子。如结果部分所示,该方案显著地有助于实现接近基线ANN精度的分类精度,因为在初始层之后,由于 identity mappings,最大神经元激活衰减到接近于1的值。
7. EXPERIMENTS
7.1. Datasets and Implementation
我们在标准视觉对象识别库评估了我们的想法,即 CIFAR-10 和 ImageNet 数据集。在网络上对CIFAR-10数据集进行的实验是在训练集图像上训练的,每个像素的均值被减去,并在测试集上进行评估。我们还展示了更为复杂的ImageNet 2012数据集的结果,该数据集包含128万个训练图像和50,000个验证集的报告评估(TOP1和TOP5错误率)。本实验使用了输入图像中的224×224个像素。
我们对这两个数据集都使用 VGG-16 架构(Simonyan和Zisserman,2014)。他等人概述的RESNET-20配置。(2016a)用于CIFAR-10数据集,而ResNet-34用于在ImageNet数据集上进行实验。**如前所述,我们不使用任何BN(Batch-Normalization )层。对于VGG网络,除了后面跟着池化层的那些层之外,在每个ReLU层之后都使用dropout层。对于ResNet,我们仅对 non- identity 并行路径处的 ReLU 使用 dropout,而不在结合层使用 dropout。我们发现这对于实现训练收敛至关重要。**请注意,我们只针对上述体系结构和数据集测试了我们的框架。报道的结果中没有选择偏差。
我们的实现源自 Facebook 的 ResNet实现代码和公开提供的 CIFAR 和 ImageNet 数据集。我们使用与2中相同的图像预处理步骤以及比例和纵横比增强技术(例如,CIFAR-10数据集的随机裁剪、水平翻转和颜色归一化转换)。我们报告了单一种类测试结果,而使用10种做测试可以进一步降低错误率(Krizhevsky et.al,2012年)。用于CIFAR-10数据集的网络在2个GPU上训练,batchsize 大小为 256,用于200个 epochs,而 ImageNet 训练在8个GPU上执行,用于100个epochs,batchsize 大小相似。初始学习率为0.05。对于 CIFAR-10 数据集,学习率,在 81 和 122 epochs 时分别被除以10两次 ,对于ImageNet数据集,在 30 和 60 个 epochs 时,所有实验都使用 0.0001 的权重衰减和 0.9 的动量。在这种不需要批量归一化的深层网络中,适当的权值初始化是实现收敛的关键。**对于具有kernel size 为 k×k 且具有 n 个输出通道的非残差卷积层 (对于 VGG 和 ResNet 架构两者),根据正态分布和标准差
2
k
2
n
\sqrt{\frac{2}{k^2n}}
k2n2 初始化权重。然而,对于剩余卷积层,用于正态分布的标准差为
2
k
2
n
\frac{\sqrt2}{k^2n}
k2n2。**我们观察到这对于实现训练收敛很重要,Hardt and Ma(2016)也概述了类似的观察结果,尽管他们的网络是在没有 dropout 和批量归一化的情况下进行的训练。
7.2. Experiments for VGG Architectures
我们的 VGG-16 模型架构遵循 https://github.com/szagoruyko/cifar.torch 中概述的实现,不同之处在于我们没有使用BN层。我们使用从训练集中随机选择的 256个 batch 进行 CIFAR-10 数据集的权重归一化过程。虽然整个训练集可以用于权重归一化过程,但使用具有代表性的子集不会影响结果。我们通过对 CIFAR 和 ImageNet 数据集运行多个独立运行来确认这一点。2500个时间步后最终分类错误率的标准偏差为 ∼0.01% 。本节报告的所有结果代表脉冲网络5次独立运行的平均值(因为网络的输入是随机过程)。在2500个时间步长结束时,分类错误率没有显著差异,网络输出在随机输入的驱动下收敛到确定值。对于基于SNN模型的权重归一化方案 ( Spike-norm 算法),我们对每一层依次使用2500个时间步长来归一化权重 。
表1总结了我们对 CIFAR-10 数据集的结果。测试集上的基准 ANN 错误率为8.3%。**由于这项工作的主要贡献是最大限度地减少深层网络从 ANN到SNN 转换过程中的精度损失,而不是在 ANN 训练中推动最新的结果,所以我们没有进行任何超参数优化。**然而,请注意,尽管我们的 ANN 体系结构中存在几个体系结构限制,但我们能够使用上一小节中描述的训练机制来训练提供具有竞争力的分类精度的深层网络。通过适当调整学习参数,可以进一步降低基准ANN错误率。对于VGG-16体系结构,我们实现了 ( Diehl et.al 2015 ) 提出的基于人工神经网络模型的权重归一化技术。平均SNN错误率为8.54%,误差增量为0.24%。应用我们提出的Spike-norm 算法,误差增量最小为0.15%。

注意,我们考虑了一个严格的基于模型的权重归一化方案,以隔离考虑ANN和我们的SNN模型对阈值平衡的影响。在权重归一化过程中考虑最大突触权重的进一步优化仍然是可能的(Diehl et.al,2015)。
以往的工作主要集中在浅得多的卷积神经网络结构上。尽管(Hunsberger and Eliasmith 2016 )报告了精确度损失0.18%的结果,但他们的基线ANN遭受了一定程度的精确度下降,因为他们的网络是用噪声(除了前面提到的架构限制)训练的,以解释由于传入的脉冲序列而导致的神经元反应可变性(Hunsberger and Eliasmith,2016)。**目前也不清楚有噪音的训练机制是否会扩大到更深层次的网络。**到目前为止,我们的工作报告了尖峰神经网络在CIFAR-10数据集上的最佳性能。
我们提出的算法在更复杂的 ImageNet 数据集上的影响要明显得多。ImageNet 验证集 top-1 (top-5) 错误的比率汇总在表2 中。请注意,这些是单一作用结果。通过考虑基于 SNN 模型的权重归一化方案,ANN-SNN 转换过程中的精度损失最小,降幅为 0.57%。因此,当模式识别问题变得更加复杂时,我们所提出的 spike-norm 算法将显著优于基于神经网络模型的转换方案,因为它考虑了转换过程中的实际 SNN 操作。请注意,Hunsberger and Eliasmith(2016)报告说,在ImageNet 2012数据集的第一个3072图像测试batch 上的性能为 48.2%(23.8%)。

在我们开发这项工作时,我们不知道并行努力扩大 SNNs对更深的网络和大规模机器学习任务的性能。这项工作最近在(Rueckauer et.al, 2017)。但是,他们的工作与我们的方法不同:
(i)他们的工作改善了(Diehl et.al 2015) , 的先前概述的方法。通过提出删除 ANN 训练所涉及的约束的转换方法(第4.3节讨论)。我们通过缩放 ( Diehl et.al 2015 ) 的方法来改善现有技术。通过包括限制为 ANN-SNN转换。 (ii)我们正在展示考虑转换过程中的SNN操作有助于最小化转换损失。 Rueckauer et.al(2017)使用(Diehl et.al 2015)使用的基于ANN基准转化方案。
虽然消除了 ANN 训练中的限制,(Rueckauer et.al, 2017)作者这样做是为了以更好的精度训练神经网络,但是它们在转换过程中遭受严重的精度损失。**这是由于 bias/ BN归一化因子和权重的比例不是最优造成的。这也是我们探索无偏和BN归一化ANN-SNN转换的主要原因。**例如,他们在CIFAR-10数据集上表现最好的网络的转换损失为 1.06%,而我们提出的更深层次网络的转换损失 为 0.15%。他们的 VGG-16 网络在ImageNet数据集上的精度损失要大得多14.28%,而我们的则是0.56%。尽管(Rueckauer et.al, 2017)报告了 Inception-V3 网络的 TOP-1 SNN 错误率为25.40%,他们的 ANN 训练错误率为 23.88%。由此产生的转换损失为1.52%,远远高于我们提出的。Inception-V3网络转换也通过限制电压阈值的方法进行了优化,发现这种方法是特定于 Inception -V3网络的,并不适用于VGG网络,(Rueckauer et.al, 2017)。请注意,(Rueckauer et.al, 2017)在ImageNet上报告的结果,是针对InceptionV3网络的1,382 个图像样本和针对 VGG-16 网络的 2,570 个样本的子集。因此,整个数据集的性能尚不清楚。我们的贡献在于,我们证明了神经网络可以在上述约束下进行训练,在大规模任务中具有竞争精度,并以几乎无损的方式转换为神经网络。
这是第一个在整个 50,000 个 ImageNet 2012 验证集上 报告脉冲神经网络具有竞争力的性能的工作。
7.3. Experiments for Residual Architectures
我们的 CIFAR-10 和 ImageNet 数据集的残差网络遵循 (He et,al. 2016a) 的实现 。在图3中,我们首先尝试通过按顺序对网络施加每个约束并显示它们对网络性能的相应影响来解释我们对ResNet的设计选择。“基本架构”包括没有任何连接 ReLU 的残差网络。“约束1”包括连接ReLU,而对于所有扇入的神经层没有相同的脉冲阈值。“约束2”为所有层施加了相等的统一阈值,而“约束3”在网络开始时使用两个预处理的简单卷积层 (3×3) 执行得最好。 在CIFAR-10数据集上训练基线ANN ResNet-20,误差为10.9%。请注意,尽管我们使用的术语与 (He et,al. 2016a) 的术语一致。对于网络架构,我们的 ResNet 包含两个额外的普通预处理层。根据我们的试验,转换后的SNN的分类错误率为12.54%。使用基于神经网络模型的权重归一化方案对初始两层进行加权归一化,平均误差为12.87%,进一步验证了权重归一化技术的有效性。
在ImageNet数据集上,我们使用 (He et,al. 2016a) 概述的更深层次的 ResNet-34模型。最初的 7×7 卷积层被三个 3×3 卷积层取代,其中最初的两层是非残差单元。在 2500 个时间步结束时,基准神经网络的训练误差为29.31%,而转换后的SNN误差为34.53% 。表3总结了结果,图4提供了我们所有网络的收敛图。这里值得注意的是,探索残差网络的主要动机是更深入地研究尖脉冲神经网络。我们探索相对简单的 ResNet 体系结构,就像使用 (He et,al. 2016a) 的体系结构一样。其参数比标准VGC架构少一个数量级。进一步的超参数优化或更复杂的架构仍然是可能的。虽然在ANN-SNN转换过程中,ResNet 比普通卷积结构的精度损失更大,但仍然可以探索进一步的优化,如包括更多的预处理初始层或为剩余单元提供更好的阈值平衡方案。这项工作是探索残差网络的ANN-SNN转换方案的第一项工作,并试图突出转换过程中最小损耗所需的重要设计约束。

图3:架构限制对残差网络的影响。“基本架构” 不涉及任何Relu连接层。“约束1”涉及结合部ReLU,而“约束2”对所有剩余单元施加相等的单位阈值。“约束3”的加入显著提高了网络精度,“约束3”涉及在网络输入阶段对权重归一化的简单卷积层进行预处理。


图4:上图显示了 CIFAR-10 和 ImageNet 数据集的 VGG 和 ResNet SNN 架构的收敛图。随着时间步长的增加,放电神经元中收敛的证据越多,分类误差就越小。请注意,虽然CIFAR-10数据集的网络深度相似,但ResNet-20的收敛速度比VGG架构快得多。由于层数是VGG网络的两倍,因此ImageNet数据集上的ResNet-34的延迟理论上来说会更高。
7.4. Computation Reduction Due to Sparse Neural Events
用于预测特定输入的输出类别的 ANN 操作需要每幅图像的单个前馈传递。对于 SNN 操作,必须对网络进行多个时间步骤的评估。然而,考虑到事件驱动的神经操作并“仅在需要时才计算”的专用硬件可能会利用这种网络操作的替代机制。例如,图5表示,VGG 和ResNet 体系结构中神经元产生的输出尖峰的平均总数作为 ImageNet 数据集的层的函数。随机选择的小批次用于平均化过程。我们使用 500 个时间步累积 VGG 网络的峰值计数,而将 2000 个时间步用于 ResNet 架构。这与图4所示的收敛图一致。从图5中获得的一个重要见解是,神经元放电活动随着网络深度的增加而变得稀疏。因此,事件驱动的硬件带来的好处预计会随着网络深度的增加而增加。虽然对SNN操作模式的实际能耗降低的估计超出了当前工作的范围,但我们通过提供在 ANN 和 SNN 中执行的每个突触操作的计算次数来提供直观的洞察力。
对于 ANN,可以根据卷积层和线性层的体系结构容易地估计网络每层的突触操作的数量。对于 ANN ,每次突触操作都要进行乘法累加 (MAC) 计算。另一方面,专门的 SNN 硬件只有在接收到传入的脉冲时才会对每个突触操作执行累加计算 (AC) 。因此,在 SNN 中发生的 AC 操作的总数将由特定层的平均累积神经脉冲计数和相应的突触操作数量的点积来表示。此指标的计算显示对于 VGG 网络,SNN 的AC 操作与 ANN的 MAC 操作的比率为 1.975,而对于ResNet,该比率为 2.4.( 该度量仅包括网络中的 RELU/IF 脉冲神经元激活)。然而,请注意,MAC 操作涉及的能量消耗比 AC 操作多一个数量级。(2015B)。因此,与最初的 ANN 实现相比,我们的 SNN 实现的能耗预计会显著降低。值得一提的是,值得一提的是,每个神经元放电的真实度量对比每个神经元的脉冲电位数。只有当推理定时窗口上每个神经元的平均脉冲数目<1( 因为在SNN中,突触操作是基于前一层中神经元产生尖峰的条件 )时,才能获得能量效益。因此,为了在 SNN 中获得能量降低的好处,由于神经元脉冲稀疏性,人们应该瞄准更深层次的网络。
尽管与 ANN的单个前馈通路相比,SNN操作需要多个时间步骤,但在神经形态结构中实现 SNN 的单个时间步骤所需的实际时间可能显著低于ANN 实现的前馈通路(由于事件驱动的硬件操作)。延迟比较的准确估计超出了本文的范围。然而,尽管存在延迟开销,如上所述,与 ANN 相比,事件驱动 SNN 的功率优势可以显著提高深度 SNN 的能量(功率x延迟)效率。

在 ImageNet 数据集上,VGG 和ResNet 架构中的神经元产生的平均累积脉冲计数作为层数的函数。500个时间步用于累积 VGG 网络的峰值计数,而2000个时间步用于ResNet体系结构。随着网络深度的增加,神经元放电稀疏度显著增加。
8. CONCLUSIONS AND FUTURE WORK
这项工作为SNN 表现出与 ANN 对应的计算能力相似的事实提供了证据。这可能会为 SNN 在大规模视觉识别任务中的使用铺平道路,这可以通过低功耗的神经形态硬件来实现。然而,在提高 SNN 性能方面仍有一些开放的探索领域。深度NNS目前的成功的一个重要贡献归功于批量标准化(Ioffe and Szegedy,2015)。当使用无偏神经单元约束我们在没有批量归一化的情况下训练网络时,应该探索实现带偏项的神经元放电的算法技术。此外,希望训练 ANN 并将其转换为 SNN 而不会造成任何精度损失。虽然所提出的转换技术试图在很大程度上使转换损失最小化,但除了重新刺激神经元之外,还可以潜在地探索其他神经功能的变体来进一步缩小这一差距。此外,应进一步优化以最小化ResNet 体系结构的 ANN-SNN 转换中的精度损失,以将 SNN 性能扩展到更深层次的体系结构。















 5402
5402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









